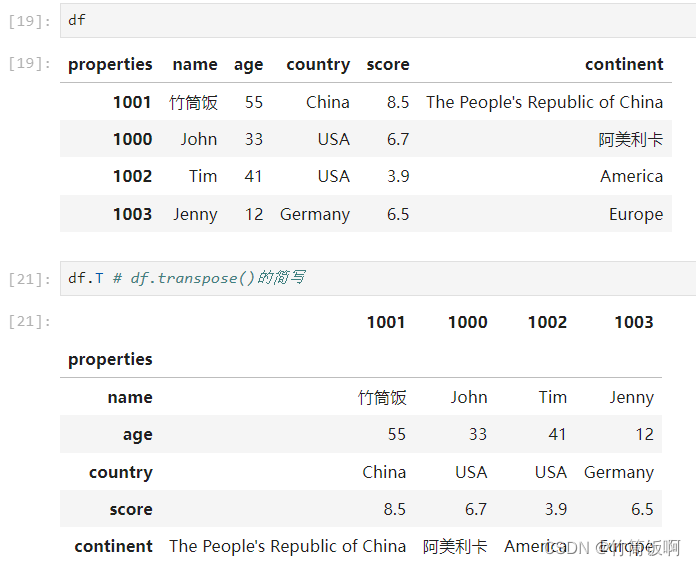
在系列2的章节中罗列了对RAG准确度的几个重要关键点,主要包括2方面,这一章就针对其中问题优化来做详细的讲解以及其解决方案。
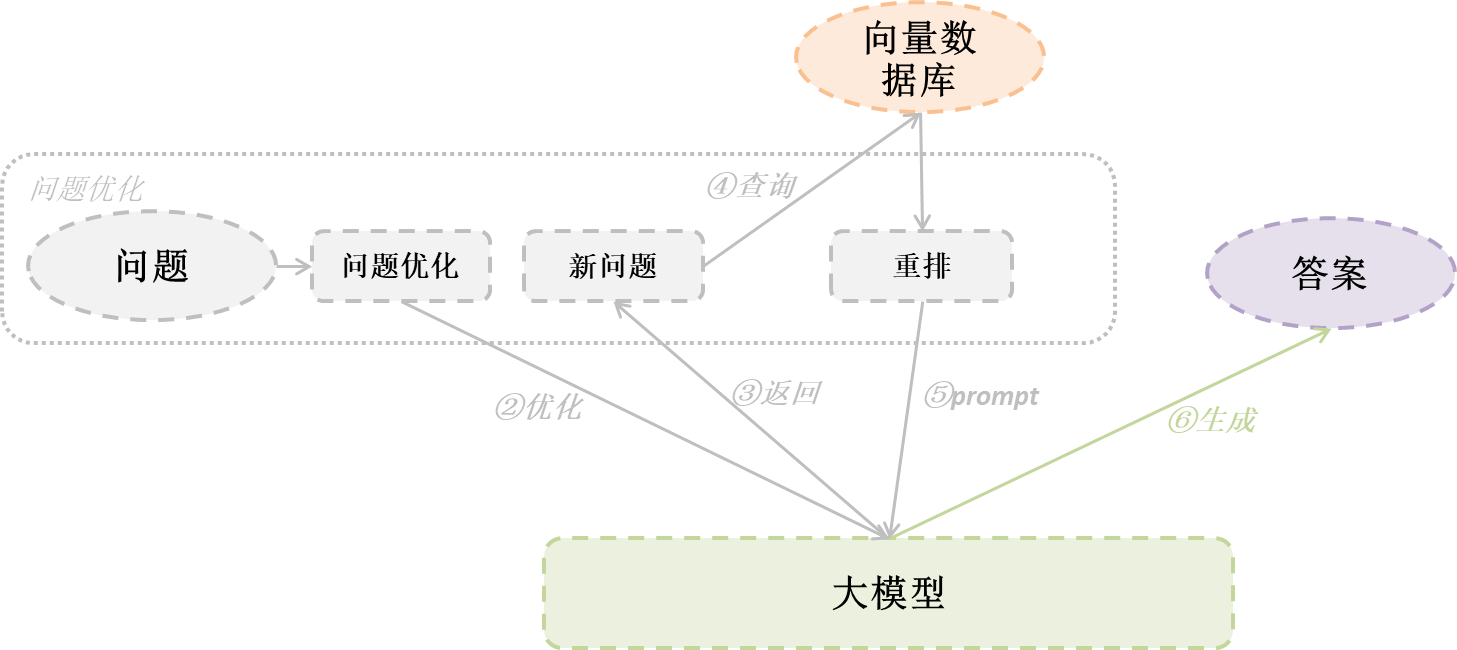
从系列2中,我们知道初始的问题可能对于查询结果不是很好,可能是因为问题表达模糊、语义与文档不一致等等,因此问题优化就是提高RAG准确率的关键节点,那么下面通过问题优化及结果重排等方法,来提供RAG的准确率(注意:其实方法不止以下几种,这里只是写了一些常见的方法技巧供大家参考)
目录
- 1 Multi-Query
- 1.1 基本思想
- 1.2 代码演示
- 2 RAG-Fusion
- 2.1 基本思想
- 2.2 代码
- 3 HyDE
- 3.1 基本思想
- 3.2 代码演示
- 4 Decomposition
- 4.1 基本思想
- 4.2 代码演示
- 5 Step-back prompting
- 5.1 基本思想
- 5.2 代码演示
- 6 总结
说明:以下所有方法实现的前置条件:
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 下载m3e-base的embedding模型
- 给一个文档目录,里面放一些你需要的文档,文档内容如下:
ChatGLM3 是北京智谱华章科技有限公司和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
北京智谱华章科技有限公司是一家来自中国的公司,致力于打造新一代认知智能大模型,专注于做大模型创新。
1 Multi-Query
1.1 基本思想
我们知道,在用户做问题提问的时候,有可能存在提问的问题模糊或者说提问的问题与文档的语义不符合,这时候有一种方法就是使用多个角度提问问题。
Multi Query的基本思想是当用户输入问题时,我们让大模型基于用户的问题再生成多个不同角度句子语句,这些问题句子是从不同的视角来补充用户的问题,然后每条问题都会从向量数据库中检索到一批相关文档,最后所有的相关文档都会扔给大模型,这样大模型就能生成更准确的结果。
1.2 代码演示
这里使用langchain的MultiQueryRetriever进行多问题检索。
import os
import logging
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain.retrievers import MultiQueryRetriever
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_community.document_loaders import DirectoryLoader
# 前置工作1:设置日志,可以让MultiQueryRetriever打印出中间生成的问题
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 前置工作2:文档存储,如果已经存储了文档,则不需要该步骤
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作3:创建llm
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:优化问题,这里使用langchain的MultiQueryRetriever,已经封装好获取多个问题并查询最终文档结果
question = "ChatGLM是什么?"
question_prompt = PromptTemplate(
input_variables=["question"],
template="""你是一个人工智能语言模型助手。你的任务是生成给定用户的3个不同版本从矢量数据库中检索相关文档的问题。
通过对用户问题产生多种视角,您的目标是帮助用户克服一些限制基于距离的相似度搜索。提供这些选择用换行符分隔的问题。原始问题:{question}""",
)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=database.as_retriever(), prompt=question_prompt, llm=llm, include_original=True
)
unique_docs = retriever_from_llm.invoke(question)
context = ''
for doc in unique_docs:
context = context+"\n"
context = context + doc.page_content
# 第二步:获得答案
template = """请根据以下内容回答问题:
{context}
问题: {question}
如果不知道,请回答“不知道”。
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | llm
response = chain.invoke({"question": question, "context": context})
print(response)
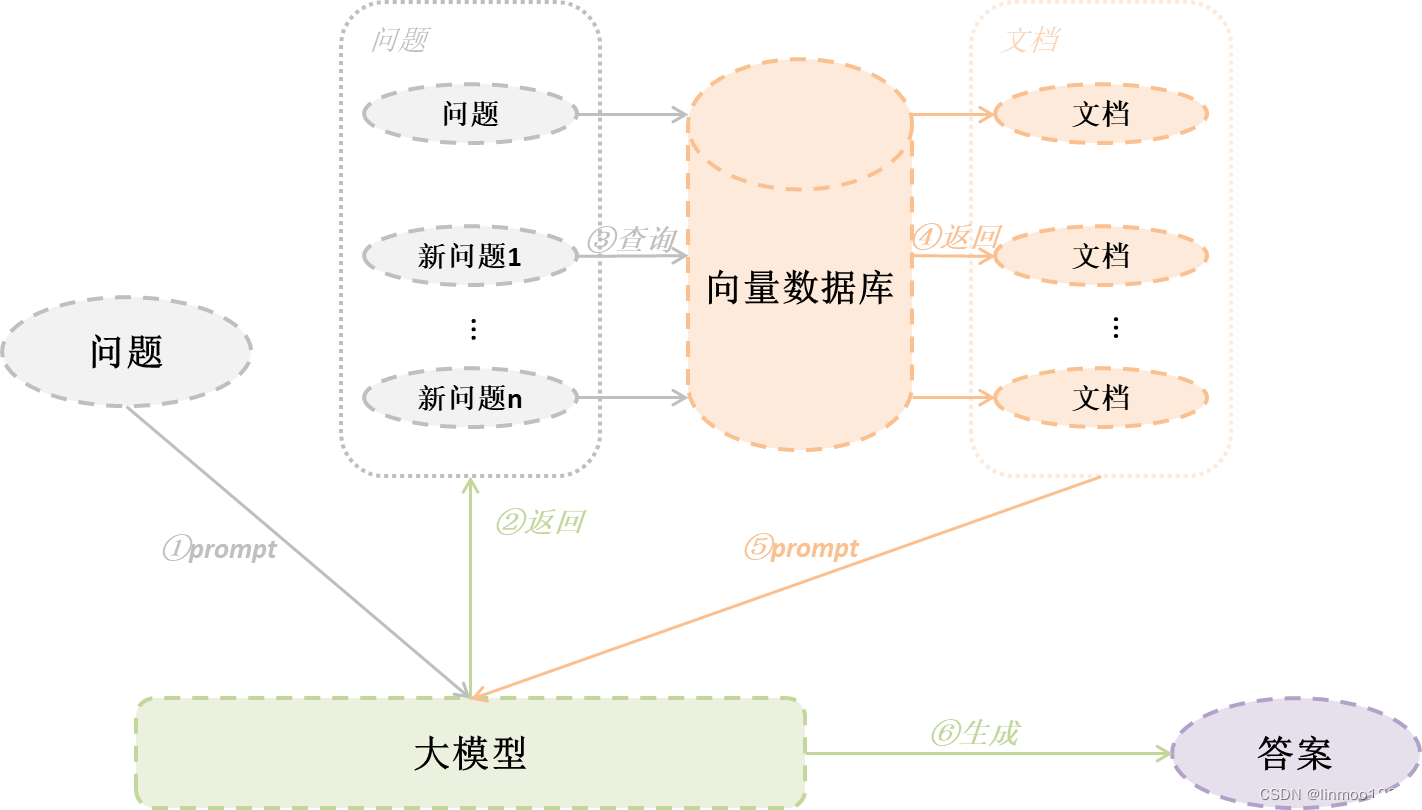
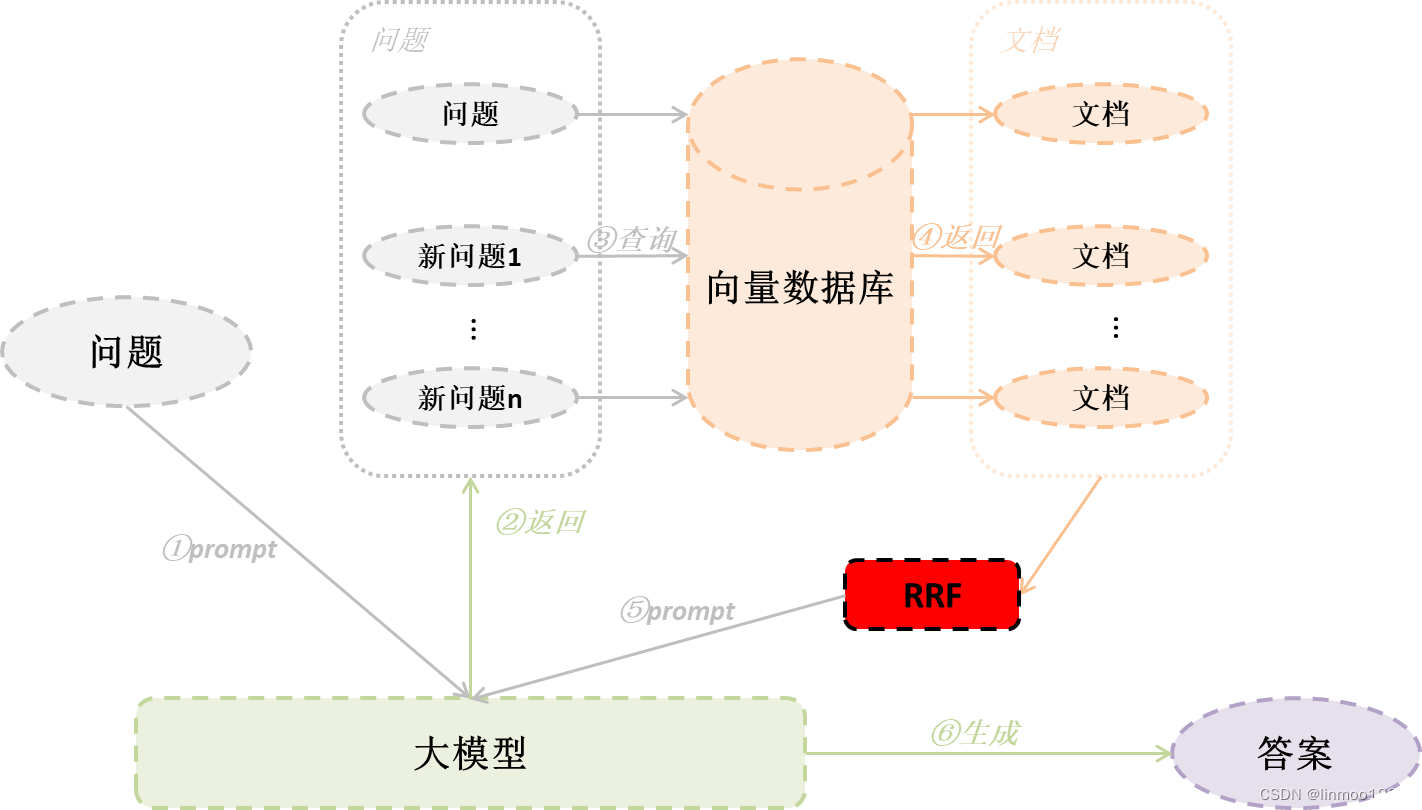
2 RAG-Fusion
2.1 基本思想
RAG-Fusion相对于Multi-Query其实就是增加一个RRF(逆向排名融合)技术。也就是同样通过原始问题,让大模型生成更多角度问题,再去查询结果,但是结果通过RRF重排,最终将重排结果给大模型生成答案。
2.2 代码
前置条件:
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 下载m3e-base的embedding模型
- 给一个文档目录,里面放一些你需要的文档
import os
from langchain.load import dumps, loads
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_community.document_loaders import DirectoryLoader
# 定义RRF算法函数,代码来自:https://github.com/langchain-ai/langchain/blob/master/cookbook/rag_fusion.ipynb
def reciprocal_rank_fusion(results: list[list], k=60):
fused_scores = {}
for docs in results:
# Assumes the docs are returned in sorted order of relevance
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# previous_score = fused_scores[doc_str]
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_results
# 前置工作1:文档存储,如果已经存储了文档,则不需要该步骤
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作2:创建llm
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:优化问题,这里使用langchain的管道,已经封装好获取多个问题并查询最终文档结果,并通过reciprocal_rank_fusion重排
question_prompt = PromptTemplate(
input_variables=["question"],
template="""你是一个人工智能语言模型助手。你的任务是生成给定用户的3个不同版本从矢量数据库中检索相关文档的问题。
通过对用户问题产生多种视角,您的目标是帮助用户克服一些限制基于距离的相似度搜索。提供这些选择用换行符分隔的问题。原始问题:{question}""",
)
question = "ChatGLM是什么"
generate_queries = (
question_prompt | llm | StrOutputParser() | (lambda x: x.split("\n"))
)
# 可以打印出生成不同角度的问题
# print(generate_queries.invoke({"question": question}))
chain = generate_queries | database.as_retriever().map() | reciprocal_rank_fusion
docs = chain.invoke({"question": question})
context = ''
for doc in docs:
context = context+"\n"
context = context + doc[0].page_content
# 第二步:获得答案
template = """请根据以下内容回答问题:
{context}
问题: {question}
如果不知道,请回答“不知道”。
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | llm
response = chain.invoke({"question": question, "context": context})
print(response)
3 HyDE
3.1 基本思想
我们知道有一类问题是用户的问题与文档的语义不一致,这个不一致会导致检索精度不够,因此可以采用HyDE的方法来解决。
HyDE的全称是hypothetical document embedding,使用大模型假设性回答问题,生成一个答案,再使用答案(注意:这里是使用大模型生成的答案,而非使用原始问题)去向量数据库中搜索相关性内容文档。
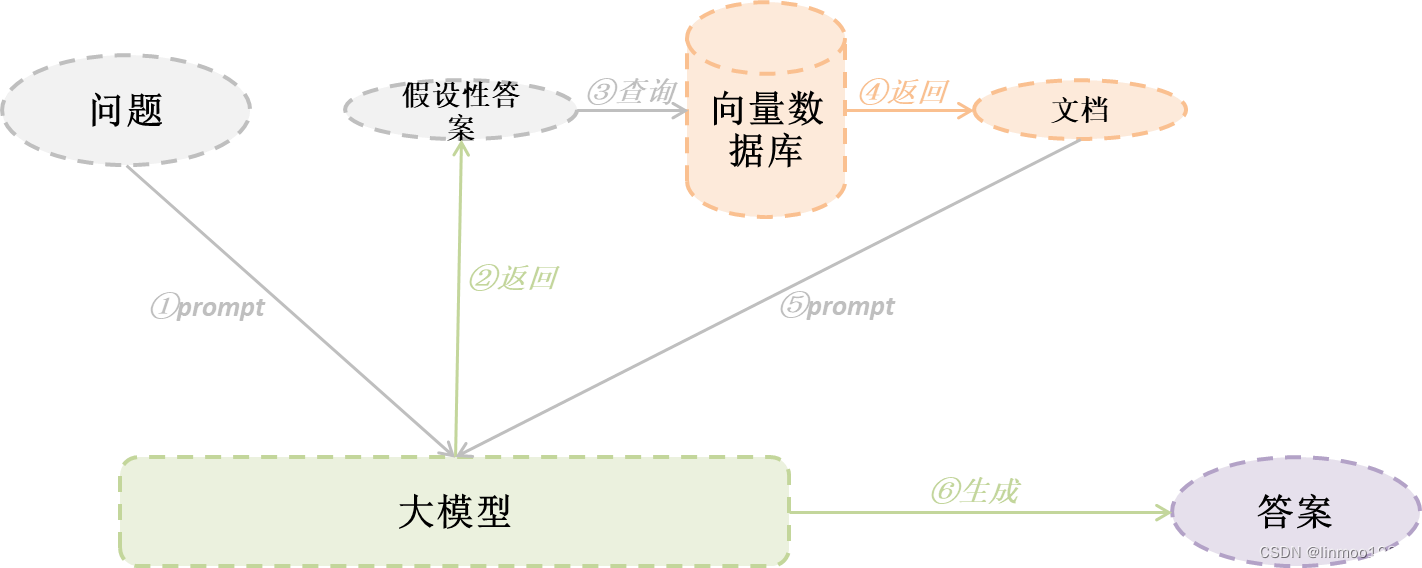
3.2 代码演示
前置条件:
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 下载m3e-base的embedding模型
- 给一个文档目录,里面放一些你需要的文档
import os
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_community.document_loaders import DirectoryLoader
# 前置工作1:文档存储,如果已经存储了文档,则不需要该步骤
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作2:创建llm
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="ec5c5980165386142d4d401976234a0a.xGWn3QfonQqfbJPg",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:优化问题,这里使用langchain的管道,让大模型生成问题的答案
question_prompt = PromptTemplate(
input_variables=["question"],
template="""请根据你已有的知识来回答这个问题,字数不超过100字。
问题:{question}""",
)
question = "ChatGLM是什么"
hyde_answer = (
question_prompt | llm | StrOutputParser()
)
answer = hyde_answer.invoke({"question": question})
# 打印一下大模型的回答
# print(answer)
# 第二步:通过大模型生成的答案查询向量数据库
retrieval_chain = hyde_answer | database.as_retriever()
docs = retrieval_chain.invoke({"question":question})
context = ''
for doc in docs:
context = context+"\n"
context = context + doc.page_content
# 第三步:获得答案
template = """请根据以下内容回答问题:
{context}
问题: {question}
如果不知道,请回答“不知道”。
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | llm
response = chain.invoke({"question": question, "context": context})
print(response)
4 Decomposition
4.1 基本思想
有时候一个问题较为复杂,按照人类的思维方式,会将其分解为子问题,然后一步步的推理,最终得到结果。这里有2种不同的方式:
第一种方式:
- 通过大模型将问题分解成多个子问题
- 将每个子问题分别检索,获得结果,将子问题与其分别对应的结果组成问题对扔给大模型解答
- 将子问题与得到的解答再组成问题对,连同原始问题一起扔给大模型,得到最终解答
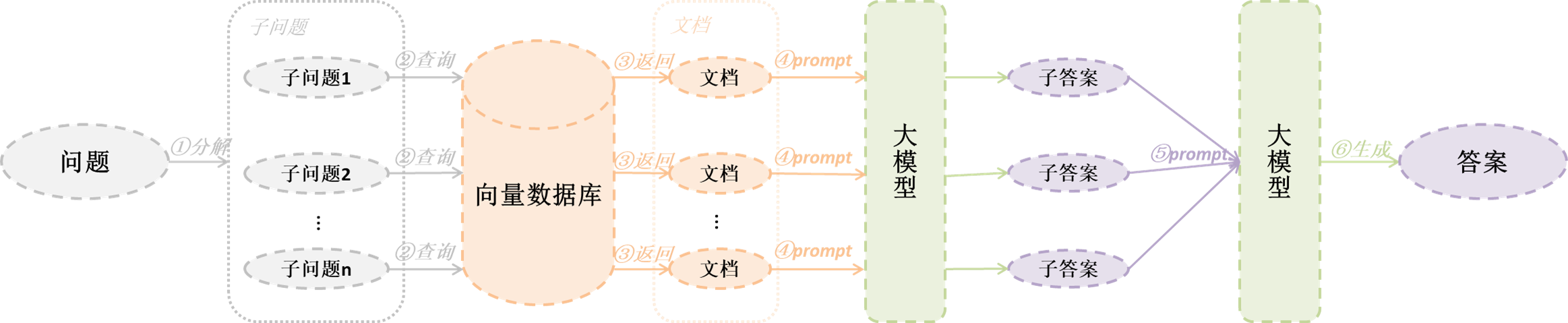
第二种方式:
- 1)通过大模型将问题分解成多个子问题
- 2)在将第一个子问题进行检索,获得结果
- 3)将第一个子问题与其分别对应的结果组成问题对,结果原始问题一起扔给大模型解答
- 4)重复2)和3)步骤,直到结果出来或者达到最大允许查询次数
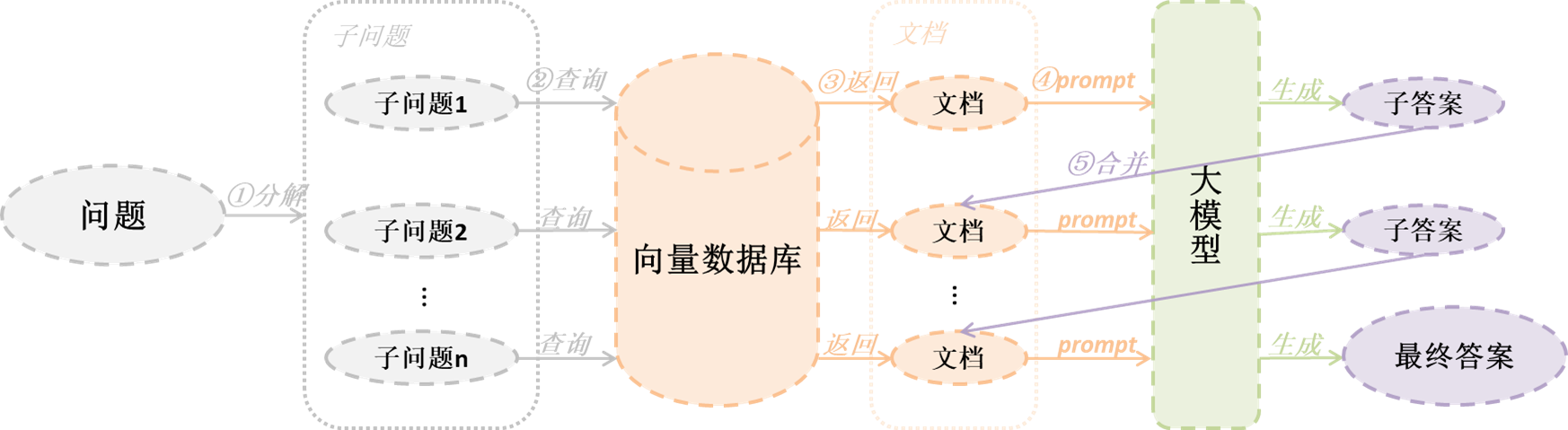
(注:其中第二种方式的思想来自2篇论文分别是IR-CoT和Least-to-Most prompting)
4.2 代码演示
第一种方式代码:
import os
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.document_loaders import DirectoryLoader
# 前置工作1:文档存储,如果已经存储了文档,则不需要该步骤
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作2:创建llm
llm = ChatOpenAI(
temperature=0.01,
model="glm-4",
openai_api_key="ec5c5980165386142d4d401976234a0a.xGWn3QfonQqfbJPg",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:分解问题
template = """您是一个有用的助手,可以生成与输入问题相关的多个子问题。\n
目标是将输入问题分解为一组子问题,这些子问题可以单独得到答案。\n
生成与{question} 相关的多个子问题,输出2个子问题:"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
generate_queries_decomposition = (prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))
final_question = "ChatGLM是哪个国家发布的?"
questions = generate_queries_decomposition.invoke({"question": final_question})
print(questions)
# 第二步:循环所有子问题,查询向量数据库获得文档内容,在一起扔给模型回答问题,将子问题和答案存储起来
RAG_prompt = '''你是负责回答问题的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。最多只用三句话,回答要简明扼要。\n
问题: {question}
上下文: {context}
答案:'''
prompt_rag = ChatPromptTemplate.from_template(RAG_prompt)
# 查询向量数据库并扔给大模型函数
def retrieve_and_rag(prompt_tmp):
# 存储结果
rag_results = []
# 循环获取结果
for sub_question in questions:
# 查询子问题的文档内容
retrieved_docs = database.as_retriever().get_relevant_documents(sub_question)
# 获得答案
answer = (prompt_tmp | llm | StrOutputParser()).invoke({"context": retrieved_docs, "question": sub_question})
# 打印子问题和子答案,可以更好看看其获取过程
# print("子问题: ", sub_question)
# print(len(retrieved_docs))
# print("子答案: ", answer)
rag_results.append(answer)
return rag_results, questions
answers, questions = retrieve_and_rag(prompt_rag)
# 组成问题对
def format_qa_pairs(sub_questions, sub_answers):
"""Format Q and A pairs"""
formatted_string = ""
for i, (question, answer) in enumerate(zip(sub_questions, sub_answers), start=1):
formatted_string += f"问题 {i}: {question}\n答案 {i}: {answer}\n\n"
return formatted_string.strip()
context = format_qa_pairs(questions, answers)
# Prompt
template = """下面是一组问题+答案对:
{context}
使用上述问题+答案对来生成问题的答案: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (prompt | llm | StrOutputParser())
response = final_rag_chain.invoke({"context": context, "question": final_question})
print(response)
第二种方式代码:
import os
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.document_loaders import DirectoryLoader
# 前置工作1:文档存储,如果已经存储了文档,则不需要该步骤
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作2:创建llm
llm = ChatOpenAI(
temperature=0.01,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:分解问题
template = """您是一个有用的助手,可以生成与输入问题相关的多个子问题。\n
目标是将输入问题分解为一组子问题,这些子问题可以单独得到答案。\n
生成与{question} 相关的多个子问题,输出2个子问题:"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))
question = "ChatGLM是哪个国家发布的?"
questions = generate_queries_decomposition.invoke({"question": question})
print(questions)
# 第二步:将前一个子问题及答案组成问题对,再将问题对与当前子问题组成template扔给大模型解答
template = """下面是你需要回答的问题:
\n——\n {question} \n——\n
以下是任何可用的背景问题+答案对:
\n——\n {q_a_pairs} \n——\n
以下是与该问题相关的其他背景:
\n——\n {context} \n——\n
使用上述上下文和任何背景问题+答案对回答问题:\n {question}
"""
decomposition_prompt = ChatPromptTemplate.from_template(template)
# 组装问题对函数
def format_qa_pair(question, answer):
formatted_string = ""
formatted_string += f"问题: {question}\n答案: {answer}\n\n"
return formatted_string.strip()
# 第三步:循环子问题,重复回到子问题
q_a_pairs = ""
answer = ""
for q in questions:
rag_chain = (
{"context": itemgetter("question") | database.as_retriever(),
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser())
answer = rag_chain.invoke({"question": q, "q_a_pairs": q_a_pairs})
# print("=====", answer) # 此处可以打印出每个子问题的回答,看到完整的推理过程
q_a_pair = format_qa_pair(q, answer)
q_a_pairs = q_a_pairs + "\n---\n" + q_a_pair
print(answer)
5 Step-back prompting
5.1 基本思想
在Decomposition中我们知道处理复杂问题需要分步解决,其实还有另外一种方法,就是面对复杂问题时,人们有时会后退一步,抽象到更高层面的概念和原则上指导过程。听起来也挺抽象的,简单来说就是通过原始问题生成更抽象的Step-back问题,检索向量数据库得到的Step-back问题包含了原理和背景信息,基于Step-back问题得到的答案,推理得到了正确答案。步骤如下:
- 抽象:首先让大模型提出一个更为抽象或者高级的问题(一般给几个few-shot),通过该问题检索向量数据库,得到答案
- 推理:基于抽象问题和答案,加上原始问题及查询的答案,一起扔给大模型进行回答,得到最终答案
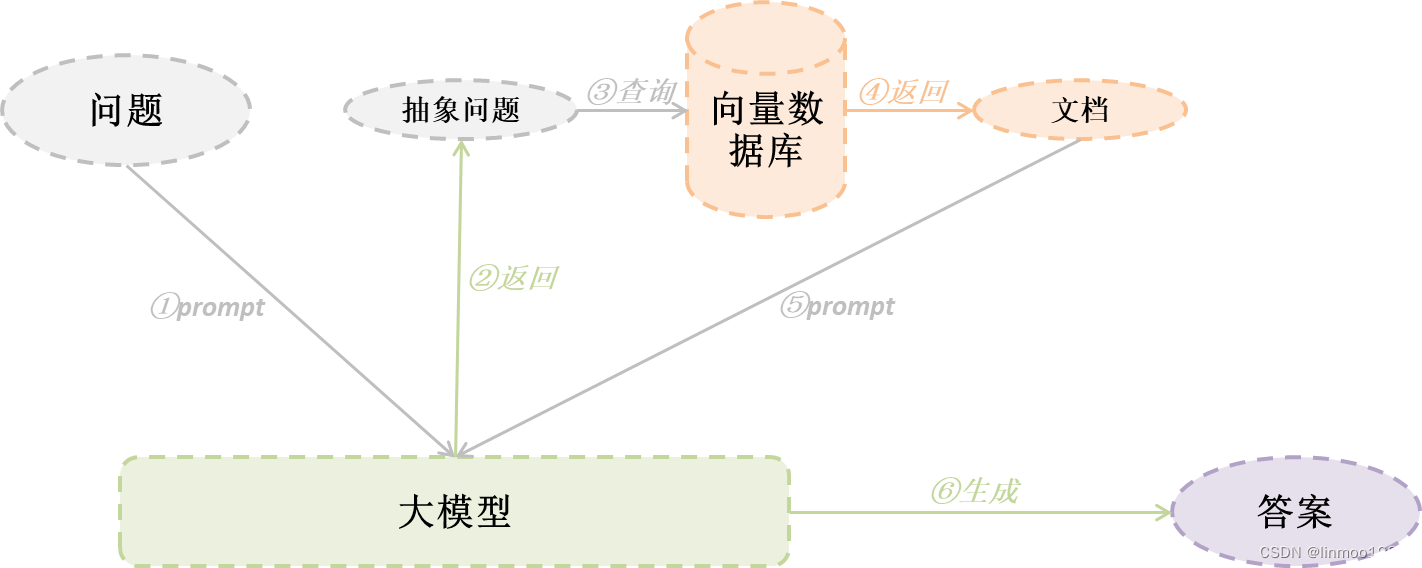
5.2 代码演示
import os
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.document_loaders import DirectoryLoader
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
# 前置工作1:文档存储,如果已经存储了文档,则不需要该步骤
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作2:创建llm
llm = ChatOpenAI(
temperature=0.01,
model="glm-4",
openai_api_key="ec5c5980165386142d4d401976234a0a.xGWn3QfonQqfbJPg",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:设置抽象问题的template和few-shot
examples = [
{
"input": "智谱AI是哪个国家?",
"output": "智谱AI的公司简介是什么?",
},
{
"input": "BYD是哪个国家?",
"output": "BYD的简介是什么?",
},
]
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""你是世界知识方面的专家。你的任务是通过退一步的方式把一个问题改写成一个更一般的问题,这样更容易回答。这里有几个例子:""",
),
few_shot_prompt,
("user", "{question}"),
]
)
generate_queries_step_back = prompt | llm | StrOutputParser()
question = "ChatGLM是哪个国家发布的?"
# 可以打印一下中间生成的抽象问题
# answer = generate_queries_step_back.invoke({"question": question})
# print(answer)
# 第二步:基于抽象问题和答案,加上原始问题及查询的答案,一起扔给大模型进行回答,得到最终答案
response_prompt_template = """你是世界知识方面的专家。你是世界知识的专家。
我要问你一个问题。你的回答应该是全面的,如果与下面上下文是相关的,则不要与下面上下文相矛盾。
如果与下面上下文是不相关的,就忽略下面上下文。你的任务是通过退一步的方式把一个问题改写成一个更一般的问题,这样更容易回答。这里有几个例子.
# {normal_context}
# {step_back_context}
# 原始问题: {question}
# 答案:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
{
"normal_context": RunnableLambda(lambda x: x["question"]) | database.as_retriever(),
"step_back_context": generate_queries_step_back | database.as_retriever(),
"question": lambda x: x["question"],
}
| response_prompt
| llm
| StrOutputParser()
)
response = chain.invoke({"question": question})
print(response)
6 总结
问题优化其实还有很多其它方法,这里先介绍常见的5种,以下表格做一个总结:
| 方法 | 描述 | 场景 |
|---|---|---|
| Multi-Query | 通过生成更多角度的问题 | 针对问题模糊时 |
| RAG-fusion | 在Multi-Query基础上,在检索文档结果后增加RRF重排 | 针对问题模糊时 |
| HyDE | 使用大模型生成假设性答案,再使用答案去查询相似度,而不是原始问题 | 用户问题和语义不在一个空间 |
| Decomposition | 将问题分解为子问题,再通过并行或串行方式获得答案 | 针对复杂问题或者需要逻辑推理问题 |
| Step-back | 使用few-shot方式,让大模型基于原始问题提出更为抽象问题 | 针对复杂问题 |