文章目录
- lumbda的常用操作
- 将List<String>转List<Integer>
- filter 过滤
- max 和min
- 将List<Object>转为Map
- 将List<Object>转为Map(重复key)
- 将List<Object>转为Map(指定Map类型)
- 过滤List重复
lumbda的常用操作
将List转List
List<String> listString = Arrays.asList("1", "2");
List<Integer> listInteger = listString.stream().mapToInt(Integer::parseInt).boxed().collect(Collectors.toList());
filter 过滤
List<String> listString = Arrays.asList("1", "2", "a");
List<Integer> listInteger = listString.stream().filter(c -> {
return StringUtils.isNumeric(c);
}).mapToInt(Integer::parseInt).boxed().collect(Collectors.toList());
max 和min
List<Integer> integerList = Arrays.asList(5, 2, 8);
Integer max = integerList.stream().max((a, b) -> {
return a > b ? 1 : -1;
}).get();
Integer min = integerList.stream().min((a, b) -> {
return a > b ? 1 : -1;
}).get();
System.out.println(max);
System.out.println(min);
System.out.println("---------------------------");
Integer min2 = integerList.stream().min(Comparator.comparing(Integer::intValue)).get();
Integer max2 = integerList.stream().max(Comparator.comparing(Integer::intValue)).get();
System.out.println(min2);
System.out.println(max2);
将List转为Map
List<User> userList = new ArrayList<>();
userList.add(new User("1", "xiaowang"));
userList.add(new User("2", "xiaoming"));
Map<String, String> map = userList.stream().collect(Collectors.toMap(User::getId,User::getUserName));
map.forEach((k,v)->{
System.out.println(k);
System.out.println(v);
});
Map<String, User> map2 = userList.stream().collect(Collectors.toMap(a->{return a.getId();},b->{
return b;
}));
map2.forEach((k,v)->{
System.out.println(k);
System.out.println(v.getUserName());
});
Map<String, User> map3 = userList.stream().collect(Collectors.toMap(User::getId,Function.identity()));
map3.forEach((k,v)->{
System.out.println(k);
System.out.println(v.getUserName());
});
将List转为Map(重复key)
如果List转Map时,存在key的重复,则会报错,提示重复的key(java.lang.IllegalStateException: Duplicate key)
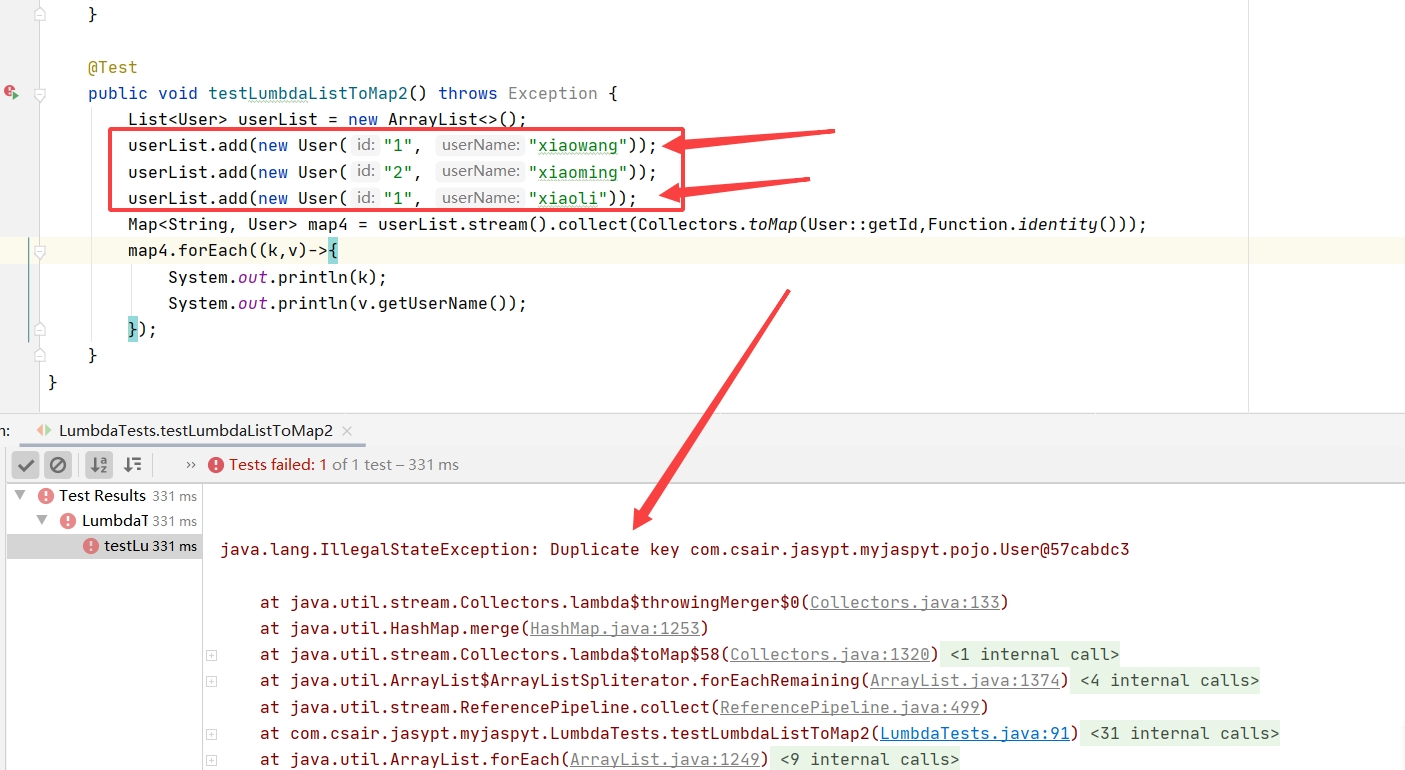 此时需要定义处理key重复时的舍留,我们可以定义是保留前者还是后者。(k1,k2)->k1 表示保留前者,(k1,k2)->k2表示保留后者
此时需要定义处理key重复时的舍留,我们可以定义是保留前者还是后者。(k1,k2)->k1 表示保留前者,(k1,k2)->k2表示保留后者
,当然我们也可以使用前面的filter过滤掉重复。
List<User> userList = new ArrayList<>();
userList.add(new User("1", "xiaowang"));
userList.add(new User("2", "xiaoming"));
userList.add(new User("1", "xiaoli"));
Map<String, User> map4 = userList.stream().collect(Collectors.toMap(User::getId,Function.identity(),(k1,k2)->{return k1;}));
map4.forEach((k,v)->{
System.out.println(k);
System.out.println(v.getUserName());
});
将List转为Map(指定Map类型)
有时候,我们希望得到其插入时的顺序,而不是无序的map,此时我们可以指定转换为LinkedHashMap
例如下图中,userList的顺序插入顺序是3,1,2,但是返回的顺序遍历结果是1,2,3,我们希望得到其原始顺序。
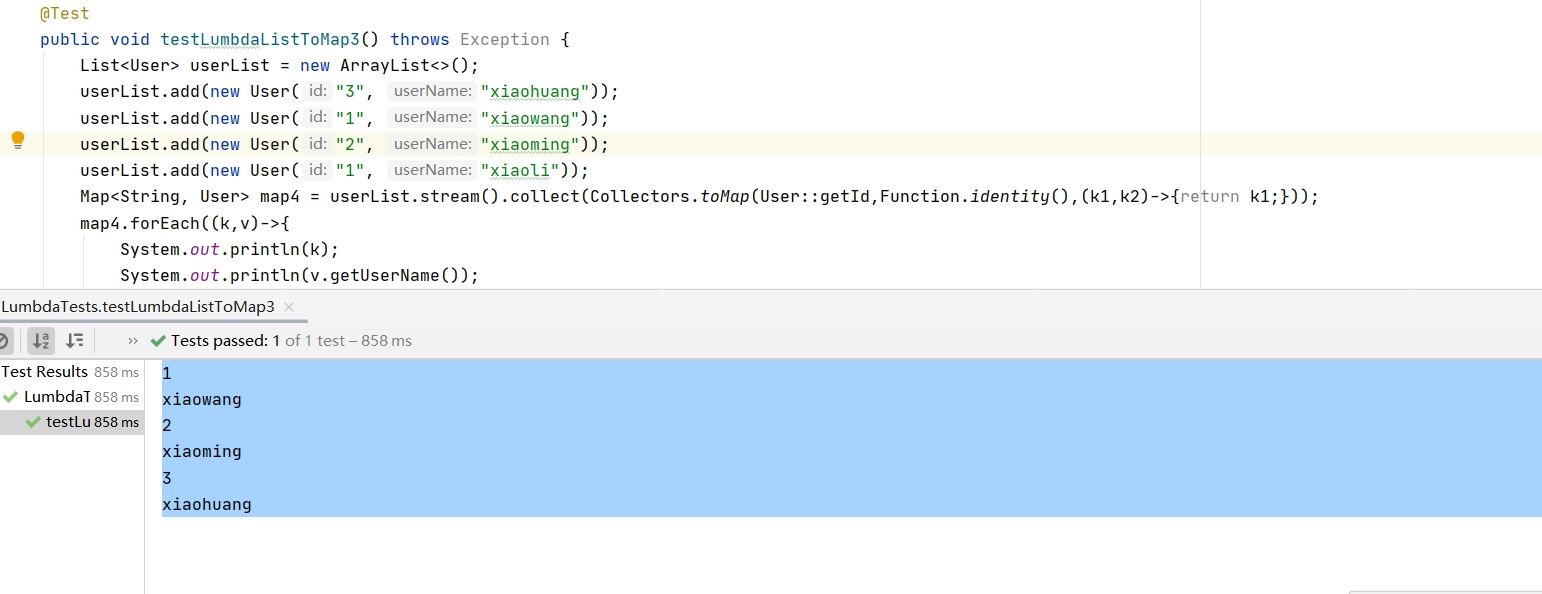 我们可以指定使用LinkedHashMap作为接收类型
我们可以指定使用LinkedHashMap作为接收类型
List<User> userList = new ArrayList<>();
userList.add(new User("3", "xiaohuang"));
userList.add(new User("1", "xiaowang"));
userList.add(new User("2", "xiaoming"));
userList.add(new User("1", "xiaoli"));
Map<String, User> map4 = userList.stream().collect(Collectors.toMap(User::getId, Function.identity(), (k1, k2) -> {
return k1;
}, LinkedHashMap::new));
map4.forEach((k, v) -> {
System.out.println(k);
System.out.println(v.getUserName());
});
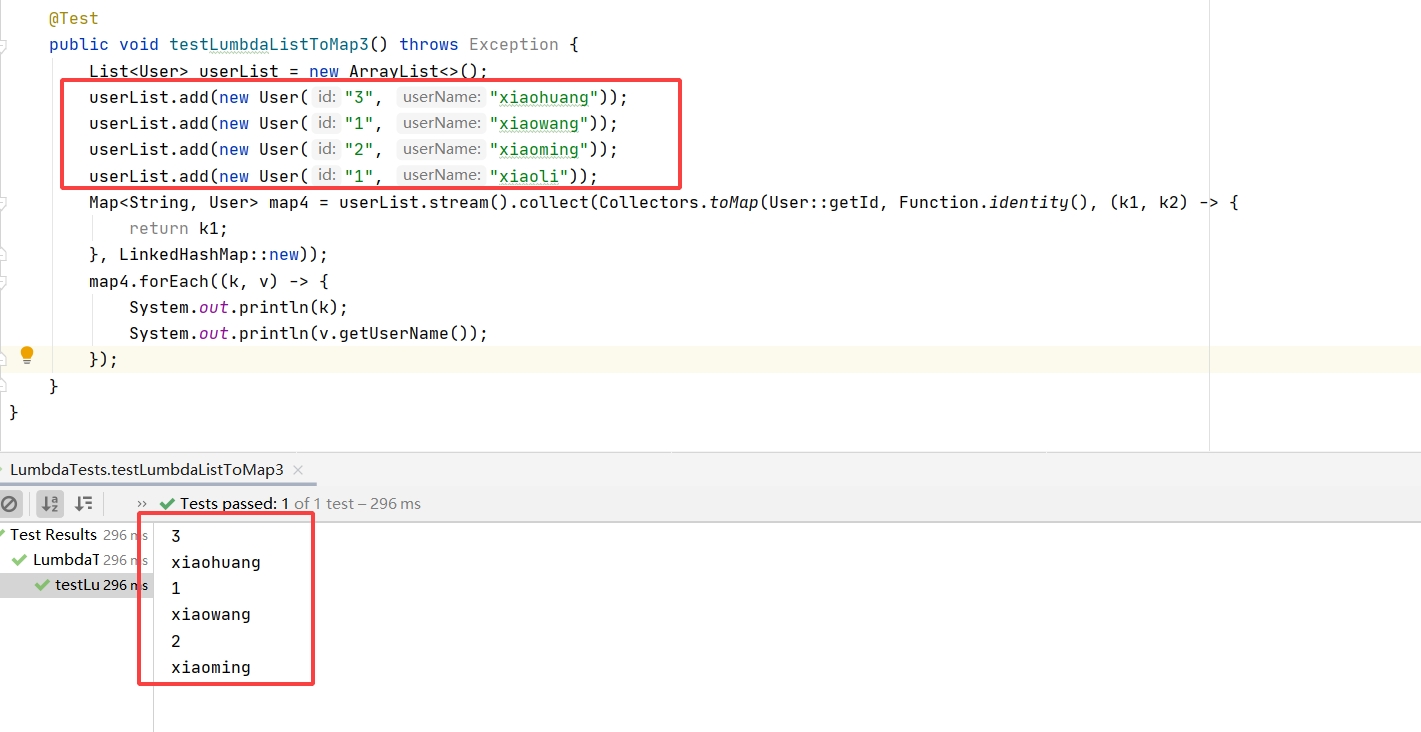
执行结果可以看到,此时结果的顺序与原来List添加顺序一致
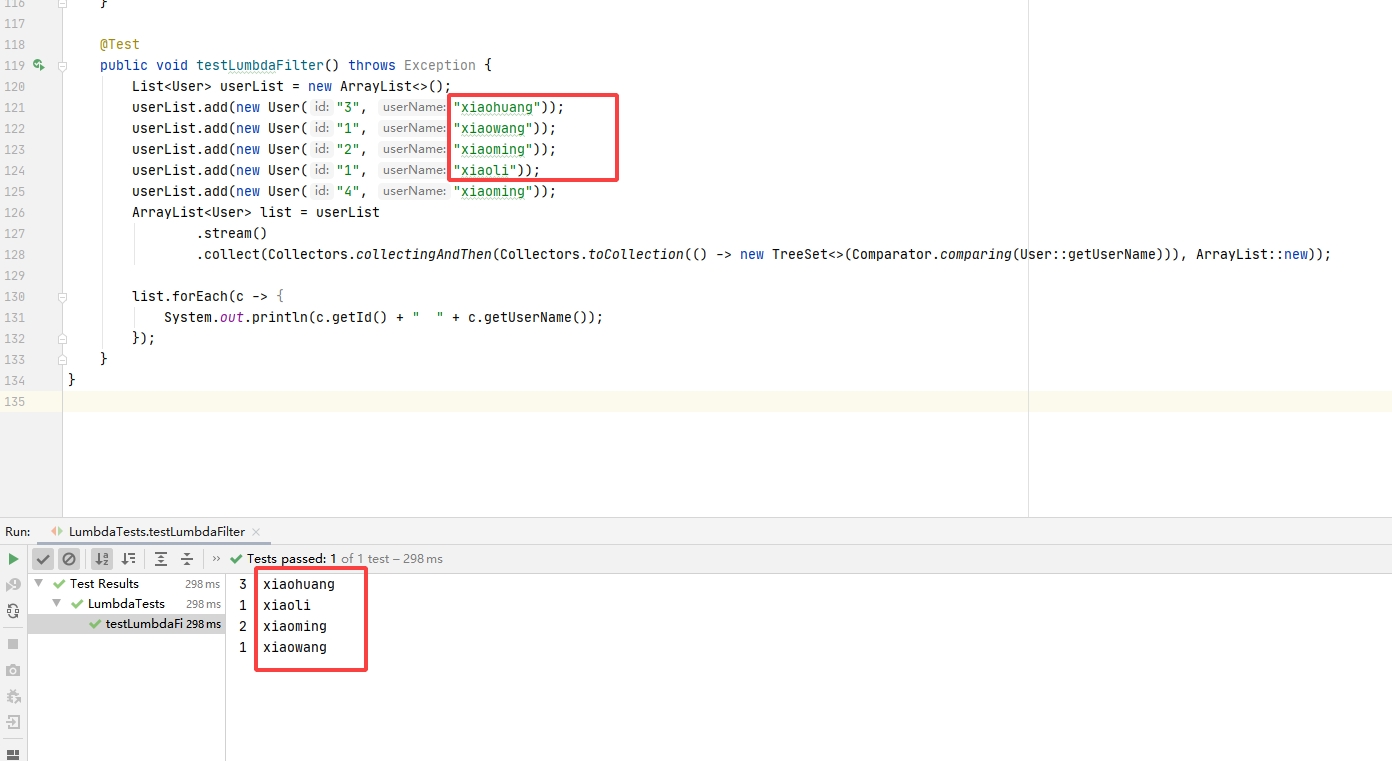
过滤List重复
示例为过滤userName重复
List<User> userList = new ArrayList<>();
userList.add(new User("3", "xiaohuang"));
userList.add(new User("1", "xiaowang"));
userList.add(new User("2", "xiaoming"));
userList.add(new User("1", "xiaoli"));
userList.add(new User("4", "xiaoming"));
ArrayList<User> list = userList
.stream()
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getUserName))), ArrayList::new));
list.forEach(c -> {
System.out.println(c.getId() + " " + c.getUserName());
});
执行结果