目录
- MySQL架构概述
- 语句执行步骤总览
- 连接管理与线程处理
- 语法解析
- 查询缓存
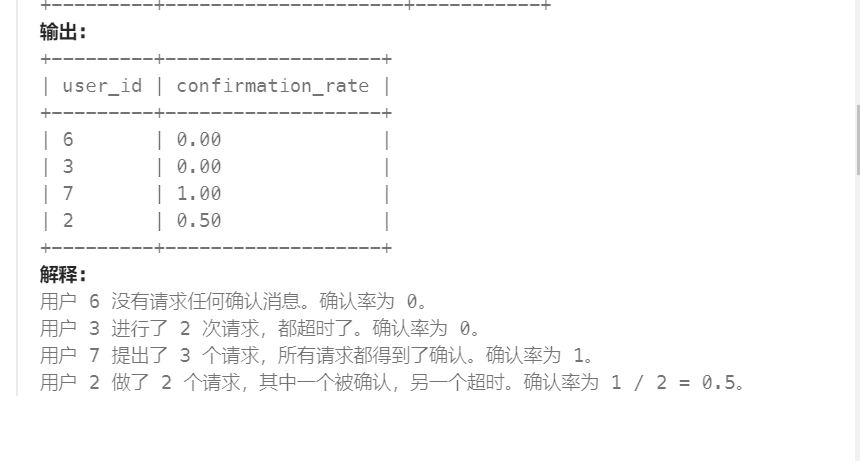
- 语义解析与预处理
- 查询优化
- 执行计划生成
- 存储引擎层执行
- 结果集返回
- 优化查询性能的技巧
- 结论
MySQL架构概述
在深入探讨MySQL语句执行的具体步骤之前,我们先来了解MySQL的整体架构。MySQL架构主要包括以下几个部分:
- 连接管理与安全性:负责管理客户端连接、验证用户身份及权限。
- 查询分析与优化:包括SQL解析器、查询优化器等组件。
- 执行引擎:负责执行SQL查询计划。
- 存储引擎:负责数据的存储和提取。MySQL支持多种存储引擎,如InnoDB、MyISAM、Memory等。

MySQL主要组件
- 连接管理:负责处理客户端连接请求,验证用户身份,并管理用户会话。
- SQL解析器:将SQL语句解析成语法树,进行语法检查。
- 查询优化器:生成最优的查询执行计划。
- 执行引擎:根据执行计划执行查询操作。
- 存储引擎:负责数据的存储和提取,提供事务、锁机制等功能。
了解MySQL的架构有助于理解其执行流程中的各个步骤。
语句执行步骤总览
一条MySQL语句从接收到返回结果,通常经历以下步骤:
- 连接管理与线程处理:接收客户端连接请求,分配线程处理请求。
- 语法解析:将SQL语句解析成语法树,并进行语法检查。
- 查询缓存检查:检查是否有对应的缓存结果,若有则直接返回缓存结果。
- 语义解析与预处理:进行语义检查,生成查询的逻辑执行计划。
- 查询优化:优化查询逻辑执行计划,生成物理执行计划。
- 执行计划生成:根据物理执行计划调用存储引擎进行数据操作。
- 存储引擎层执行:存储引擎执行具体的数据操作,并返回结果。
- 结果集返回:将结果集返回给客户端。
接下来我们详细解析每一个步骤。
连接管理与线程处理
当客户端向MySQL服务器发起连接请求时,MySQL会创建一个新的线程来处理该请求。这些线程由连接管理模块管理,主要包括以下几个步骤:
- 接收连接请求:MySQL服务器监听指定的端口,当客户端发起连接请求时,服务器接收该请求。
- 验证用户身份:MySQL通过用户提供的用户名和密码验证其身份,确保其具有访问权限。
- 分配线程:服务器为每个客户端连接分配一个线程,该线程负责处理该连接的所有请求。
# 示例代码:连接MySQL数据库
mysql -u root -p
在这个过程中,MySQL还会检查用户的权限,确保其只能访问被授权的数据和执行被授权的操作。
语法解析
通过连接管理后,MySQL会对收到的SQL语句进行语法解析。这个过程包括以下步骤:
- 词法分析:将SQL语句分解成多个标记(tokens),如关键字、操作符、标识符等。
- 语法分析:将标记组成语法树,检查语法是否正确。
# 示例代码:SQL语法
SELECT * FROM users WHERE id = 1;
语法解析的结果是一个语法树(Parse Tree),它表示SQL语句的结构。
词法分析
词法分析器将SQL语句分解成一个个标记,例如:
SELECT * FROM users WHERE id = 1;
将被分解成以下标记:
SELECT*FROMusersWHEREid=1
语法分析
语法分析器将这些标记组成语法树,并检查其语法是否正确。例如,以下是一个简单的语法树:
SELECT
|
* FROM users
|
WHERE
|
id = 1
如果语法正确,语法解析器会生成一个语法树供后续步骤使用。如果语法错误,MySQL会返回相应的错误信息。
查询缓存
在语法解析之后,MySQL会检查查询缓存。查询缓存是MySQL的一项优化功能,用于存储查询语句及其结果。如果相同的查询语句再次执行,MySQL可以直接返回缓存中的结果,而不需要重新执行查询。
# 示例代码:开启查询缓存
SET GLOBAL query_cache_size = 16777216;
如果查询缓存命中,MySQL会直接返回缓存结果,跳过后续步骤。如果查询缓存未命中,MySQL会继续执行后续步骤。
查询缓存的优势与局限
- 优势:提高查询性能,减少重复查询的时间。
- 局限:不适用于数据频繁更新的场景,缓存失效会导致性能下降。
语义解析与预处理
在查询缓存检查之后,MySQL会进行语义解析与预处理。这个过程包括以下步骤:
- 语义解析:检查SQL语句的语义是否正确。例如,检查表名和列名是否存在,数据类型是否匹配等。
- 预处理:生成查询的逻辑执行计划,包括选择表、列和条件等。
# 示例代码:检查表和列名是否存在
SELECT name, age FROM users WHERE id = 1;
语义解析
语义解析器检查SQL语句的语义是否正确,例如:
- 表
users是否存在? - 列
name和age是否存在? - 数据类型是否匹配?
如果语义正确,MySQL会生成查询的逻辑执行计划。如果语义错误,MySQL会返回相应的错误信息。
预处理
预处理器生成查询的逻辑执行计划,包括选择表、列和条件等。例如:
- 选择表
users - 选择列
name和age - 条件为
id = 1
查询优化
在预处理之后,MySQL会对查询进行优化。查询优化器的主要任务是生成最优的查询执行计划,以最小的代价返回结果。
查询优化器的工作流程
- 重写查询:将复杂的查询重写成等价的简单查询。
- 选择访问方法:选择最优的访问方法,例如使用索引扫描或全表扫描。
- 选择连接顺序:对于多表查询,选择最优的连接顺序。
- 生成执行计划:生成最优的查询执行计划。
# 示例代码:使用EXPLAIN分析查询
EXPLAIN SELECT name, age FROM users WHERE id = 1;
查询优化的常见策略
- 索引使用:选择合适的索引,提高查询速度。
- 连接优化:选择最优的连接顺序,减少连接代价。
- 子查询优化:将子查询重写成等价的连接,提高查询效率。
执行计划生成
查询优化器生成最优的查询执行计划后,MySQL会根据执行计划调用存储引擎执行具体的操作。执行计划包括访问方法、连接顺序等具体的执行步骤。
# 示例代码:查看执行计划
EXPLAIN FORMAT=JSON SELECT name, age FROM users WHERE id = 1;
执行计划是查询优化器生成的具体执行步骤,用于指导存储引擎如何执行查询操作。
存储引擎层执行
存储引擎负责具体的数据存储和提
取。不同的存储引擎具有不同的实现和特点,MySQL支持多种存储引擎,如InnoDB、MyISAM、Memory等。
InnoDB存储引擎
InnoDB是MySQL默认的存储引擎,支持事务、行级锁和外键等特性。以下是InnoDB的执行过程:
- 读取数据:根据执行计划读取数据。
- 锁机制:使用行级锁保护数据的一致性。
- 事务管理:支持ACID特性的事务管理。
# 示例代码:使用InnoDB存储引擎
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
) ENGINE=InnoDB;
MyISAM存储引擎
MyISAM是另一种常用的存储引擎,不支持事务,但查询性能较好。以下是MyISAM的执行过程:
- 读取数据:根据执行计划读取数据。
- 锁机制:使用表级锁保护数据的一致性。
- 索引管理:支持全文索引,提高查询性能。
# 示例代码:使用MyISAM存储引擎
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
) ENGINE=MyISAM;
存储引擎负责具体的数据操作,并将结果返回给执行引擎。
结果集返回
存储引擎执行查询操作并返回结果后,MySQL会将结果集返回给客户端。这包括以下步骤:
- 生成结果集:将查询结果组织成结果集。
- 返回结果集:将结果集通过网络返回给客户端。
# 示例代码:执行查询并返回结果
SELECT name, age FROM users WHERE id = 1;
MySQL会将查询结果通过网络返回给客户端,并关闭连接。
优化查询性能的技巧
理解MySQL语句的执行步骤有助于优化查询性能。以下是一些常见的优化技巧:
- 使用索引:合理使用索引,提高查询速度。
- 优化查询语句:重写复杂的查询,简化查询逻辑。
- 合理设计表结构:规范化设计表结构,减少冗余数据。
- 分区表:对于大表,使用分区表提高查询性能。
- 缓存机制:使用查询缓存和结果缓存,减少重复查询。
- 优化配置参数:调整MySQL配置参数,提高性能。
使用索引
索引是提高查询性能的重要手段。合理使用索引可以大幅提高查询速度。例如:
# 示例代码:创建索引
CREATE INDEX idx_users_name ON users (name);
优化查询语句
重写复杂的查询语句,简化查询逻辑。例如,将子查询重写为连接:
# 示例代码:重写子查询为连接
SELECT u.name, o.order_id
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.age > 30;
合理设计表结构
规范化设计表结构,减少冗余数据。例如,将重复的列拆分成独立的表:
# 示例代码:规范化设计表结构
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10, 2),
FOREIGN KEY (user_id) REFERENCES users(id)
);
分区表
对于大表,使用分区表可以提高查询性能。例如,将数据按日期分区:
# 示例代码:创建分区表
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10, 2),
order_date DATE
)
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023)
);
缓存机制
使用查询缓存和结果缓存,减少重复查询。例如,开启查询缓存:
# 示例代码:开启查询缓存
SET GLOBAL query_cache_size = 16777216;
优化配置参数
调整MySQL配置参数,提高性能。例如,调整InnoDB的缓冲池大小:
# 示例代码:调整InnoDB缓冲池大小
SET GLOBAL innodb_buffer_pool_size = 134217728;
通过这些优化技巧,可以显著提高MySQL的查询性能,提升系统的整体性能。
结论
本文详细介绍了一条MySQL语句从接收到返回结果的全过程,包括连接管理与线程处理、语法解析、查询缓存、语义解析与预处理、查询优化、执行计划生成、存储引擎层执行以及结果集返回。理解这些步骤有助于优化查询性能,解决潜在问题,并更好地掌握MySQL的工作机制。
通过合理使用索引、优化查询语句、合理设计表结构、使用分区表、应用缓存机制以及优化配置参数,可以显著提高MySQL的查询性能,提升系统的整体性能。希望本文对你深入理解MySQL语句的执行过程有所帮助。






![[HBM] HBM TSV (Through Silicon Via) 结构与工艺](https://img-blog.csdnimg.cn/direct/8d31fad7a28745eb81e253606f226423.png#pic_center)