欢迎关注博主 Mindtechnist 或加入【Linux C/C++/Python社区】一起探讨和分享Linux C/C++/Python/Shell编程、机器人技术、机器学习、机器视觉、嵌入式AI相关领域的知识和技术。
Python迭代器、生成器、装饰器、函数闭包
- 1. 迭代器 iterator
- ☞迭代器协议
- ☞Python中的for循环
- 2. 生成器 generator
- ☞什么是生成器
- ☞三元表达式
- ☞生成器表达式
- ☞生成器函数
- ☞生成器函数应用实例
- 3. 装饰器函数与函数闭包
- ☞装饰器
- ☞函数闭包
专栏:Python从入门到实战
1. 迭代器 iterator
☞迭代器协议
迭代合递归
- 递归:一层一层的调用,然后一层一层的返回,A调用B,B调用C,…,然后C返回给B,B返回给A;
- 迭代:每次循环得到一个结果,并且都依赖于上一次的结果,迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值;
迭代器协议与可迭代对象
- 迭代器协议是指,对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就引起一个StopIteration异常来终止迭代,即只能往后走,不能往回倒退。
- 可迭代对象是指实现了迭代器协议的对象,即对象内部提供了一个__iter__()方法。
- 协议是一种约定,可迭代对象实现了迭代器协议,python内部工具比如for循环、sum/min/max等函数通过使用迭代器协议来访问对象。
☞Python中的for循环
for循环的原理
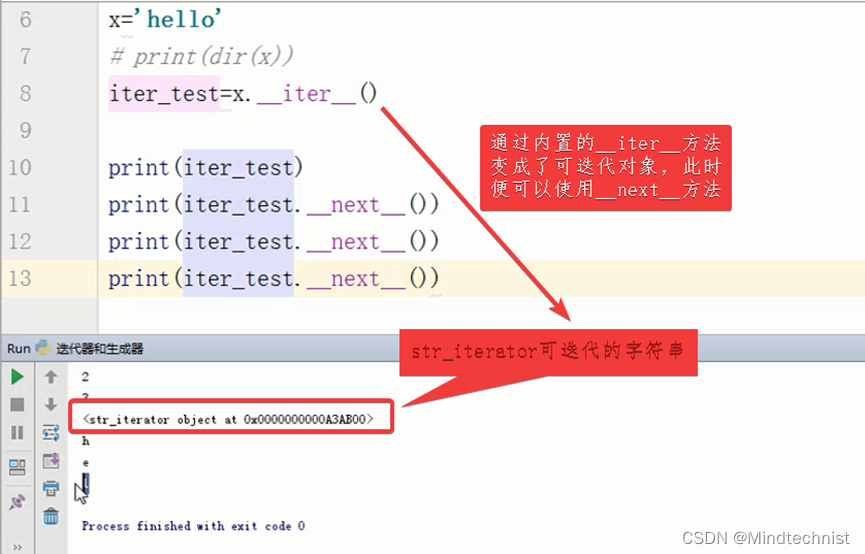
其实for循环的本质就是通过迭代器协议循环所有对象,需要说明的是,for循环的本质就是遵循迭代器协议去访问对象,也就是说for循环的对象都应该是可迭代对象。我们使用for循环可以遍历字符串、列表、元组、字典、集合、文件等等,但是这些数据类型内部并没有__next__()方法,这是为什么呢?实际上它们本身并不是可迭代对象,只不过是在for循环的时候,调用了它们内部的__iter__()方法,把它们变成了可迭代对象,然后for循环再去调用这些可迭代对象的__next__()方法去访问,并捕捉StopIteration异常来终止迭代。
我们定义的字符串、列表、元组、字典、集合、文件等对象,内部都含有一个__iter__()方法,通过调用这个方法可以把对象变成可迭代对象,变成可迭代对象之后就可以使用__next__()方法了。for循环就是通过这个过程去迭代上面这些对象的,当迭代到对象最后一个元素的时候,会自动捕捉StopIteration异常停止迭代。
#for i in list: → it = list.__iter__() → it.__next__()
#捕捉到异常StopIteration则停止迭代
for循环的实现
对列表取值的方式:一是索引:l[0],二是迭代器:it = l.iter() 、it.next()。
python中的for循环不是靠索引实现的,而是通过迭代器实现的。
对列表、元组、字符串这种有序的序列进行遍历的方式有:一是通过for循环迭代,即迭代器;二是通过while循环即索引 while index<len list[index]。
非序列类型(无序的)字典、集合、文件对象就不能通过索引去遍历了,只能通过for循环迭代,for循环基于迭代器协议提供了一个统一的可以遍历所有对象的方法,for循环总共做了三件事,首先,在遍历前调用对象的__iter__()方法把对象转换成一个迭代器,然后通过迭代器协议去实现循环访问也就是__next__()方法,最后捕捉StopIteration异常来结束循环。通过for循环实现了一个统一的迭代方法,不需要区分是否有索引/下标/有序,只要是含有__iter__()方法的对象,都是可以for循环的。注意,字典可迭代对象的__next__()方法返回的是字典的key值,所以for循环字典的时候默认是根据key值来的;文件的可迭代对象的__next__()方法是按照行去遍历,在for循环文件对象时,首先for循环根据文件对象转换一个iter_f,此时得到的是一个迭代器,每次执行iter_f.next()的时候只取了一行,也就是说每次循环只取了文件的一行内容放入内存,如果没有变量去保存这一行数据,那么执行完这次循环,这一块内存就立马被python释放了,然后进行下次循环,这样大大节省了内存提高了效率。
#用while模拟for循环
it_l = l.__iter__()
while True:
try:
print(it_l.__next__())
except StopIteration:
break
python提供的内置方法next()方法,实际上也是在调用可迭代对象内置的it.next()方法。总结来说,可迭代对象就是迭代器、即遵循迭代器协议、即包含内置方法__iter__()
2. 生成器 generator
☞什么是生成器
生成器可以理解为一种数据类型,这种数据类型自动实现了迭代器协议,而其它的数据类型需要调用自己内置的__iter__()方法来实现,所以说,生成器就是可迭代对象。
生成器分类及在python中的表现形式
python有两种方式提供生成器:
- 生成器函数:常规函数的定义,但是使用yield语句返回结果(常规函数使用return返回结果),yield语句一次返回一个结果,在每个结果中间挂起函数的状态以便下次从离开的地方重新执行。也就是说,只要是函数内部带有yield语句,那么这个函数得到的就是一个生成器。
- 生成器表达式:类似与列表推导,但是生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表。it = (‘string %s’ %i for i in range(10)),通过it.next()便可以在列表中取值了,该表达式生成的就是一个迭代器。
生成器的优点
python使用生成器对延迟操作提供了支持,所谓延迟操作就是指在需要的时候才产生结果,而不是立即产生结果。
总结
生成器是可迭代对象,它实现了延迟计算,节省内存,生成器的本质和其它数据类型一样,都实现了迭代器协议,只不过生成器附加了一个延迟计算来节省内存。
☞三元表达式
‘A’ if name == ‘name’ else ‘B’ # → 如果表达式结果为真,则返回’A’否则返回’B’
#列表解析 → 生成一个列表
[i for i in range(5)] #→ [0, 1, 2, 3, 4]
str_list=[]
for i in range(10)
str_list.append(‘string %s’ %i)
print(str_list)
# -----→ 相当于
[‘string %s’ %i for i in range(10)]
[‘string %s’ %i for i in range(10) if i > 5] # → 三元表达式
☞生成器表达式
把列表解析的[]换成()就是生成器表达式,生成器表达式得到的是一个迭代器。相对于列表解析,生成器表达式更节省内存(占用很少内存),因为列表解析是一下子就把整个列表生成了,列表中的全部元素都放在内存中;而生成器表达式是通过__next__()方法取值,每次调用只取一个值,也就是每次只取一个值放到内存中,所以更节省内存。
map、reduce、filter、sum、for、max、min等都是python中使用迭代器协议的例子。
为了节省内存,我们可以在这些函数的参数是[]列表的时候,用()生成器表达式来代替,也就是说如果一个方法的参数如果是可迭代对象,那么就可以使用生成器表达式来作为它的参数。
#比如说我们需要一个列表
[i for i in range(100000000)] # 直接就得到这个列表
#这个数据量非常大,非常耗时间耗内存,我们可以用生成器表达式来代替
(i for i in range(100000000)) # 得到一个迭代器,内部有__next__()方法
#生成器自动实现了迭代器协议
it = (i for i in range(100000000))
it. __next__()
#注意,__next__()只能不停的去取下一个值,当某个值已经被__next__()取过了,那么我们就无法再次取到这个值了。生成器只能遍历一次。
def test():
for i in range(4):
yield i
t = test()
t1 = (i for i in t)
t2 = (i for i in t1)
print(list(t1)) # 0 1 2 3
print(list(t2)) # 空
#生成器在产生的时候,不会进行任何操作,也无法知道列表里面都有什么
#值,只有运行__next__()才能获取一个值,不运行__next__()就无法知道里
#面有什么
#t1和t2都是由生成器表达式生成的生成器,但是他们只是生成器
#里面有什么是未知的(它们不是列表,只有执行next才会得到值)
#当print函数中对t1和t2进行list操作的时候,也就是for循环遍历
#此时,才会通过一次一次的__next__()不停的取值
#list(t1)就相当于取t的值,list之后t1就已经被遍历完一次了
#list(t2)就相当于取t1的值,t1已经被遍历过一次了,
#所以只能取到list最后的元素后面的位置,也就是空
#生成器只能被遍历一次,__next__()只能往下走,不能往回走
#遍历不只是__next__(),list、for、sum等都是遍历
☞生成器函数
在函数内用yield来代替return,return在函数内只能执行一次,因为执行一次就返回出去了,即便写了多个return,那么后面的return语句也没有机会执行了,而yield语句可以执行多次。
def func():
yield 1
yield 2
yield 3
yield 4
gen = func() # 得到一个generator
print(gen.__next__()) # 打印1 此时函数func停留在yield 1处
print(gen.__next__()) # 打印2 在yield 1的基础上执行
print(gen.__next__()) # 打印3 在yield 2的基础上执行
#迭代器每次都是在上一次执行结果的基础上执行并得到本次结果
#实际上,可以把yield来理解为一个断点,每次执行__next__()就相当于
#执行到下一个断点,并且执行完会停留在当前断点处
def func():
print('begin')
print('call __next__ : 1')
yield 1
print('call __next__ : 2')
yield 2
print('call __next__ : 3')
yield 3
print('end')
gen = func() #仅仅是拿到了一个生成器,函数内的语句一句都不会执行
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
#yield的作用:返回值、保留程序运行状态
使用生成器函数的好处:通过生成器函数取值,每次取到一个值就可以立即对这个值操作,不用等待函数执行后续操作,比如说你获取了num1就可以立即操作num1,并且yield会保留运行状态,当你操作完num1并且需要num2的时候,通过__next__获取num2。如果是普通函数,你需要等到100个数num1-num100全部生成才能对num1进行操作。
def get_num():
for i in range(100)
yield 'num%s' %i
it = get_num()
ret1 = it.__next__()
ret2 = it.__next__()
#可以直接对it进行for循环
for temp in it:
print(temp)
#相当于对一个函数进行for循环
生成器函数的特点
- 语法上和函数相似:生成器函数和常规函数都是使用def语句进行定义,区别在于生成器函数使用yield函数返回一个值,而常规函数使用return语句返回一个值。
- 自动实现迭代器协议:对于生成器来说,python会自动实现迭代器协议,所以我们可以直接调用它的__next__()方法,并且没有值返回的时候,生成器会自动产生StopIteration异常。
- 状态挂起:生成器使用yield语句返回一个值,yield语句挂起该生成器函数的状态,保留足够的信息,以便于之后从它离开的地方继续执行。
- 生成器函数只能遍历一次。
☞生成器函数应用实例
使用生成器函数来处理大量数据
'''
txt:
{'str':'str1', 'len':1}
{'str':'str2', 'len':3}
{'str':'str3', 'len':2}
...
'''
def get_file_line():
with open('txt', 'r', encoding = 'utf-8') as f:
for i in f:
yield i #每次返回文件的一行记录
it = get_file_line()
#print(it.__next__())-->it.__next__()得到的是一行字符串,而不是字典
#得到的是文件一行记录 "{'str':'str1', 'len':1}"
#要想把字符串中的字典提出来,使用函数eval
# "{'str':'str1', 'len':1}" -->eval-->{'str':'str1', 'len':1}
print(it.__next__())
dic = eval(it.__next__())
print(type(dic)
print(dic['len']) #取出'len'对应的value
'''
#如果想全部取出,可以使用for循环
for i in it:
temp = eval(i)
print(temp['len'])
#按'len'求和,所有len的长度之和
ret = sum(eval(i)['len'] for i in it)
print(ret)
ret2 = sum(eval(i)['len'] for i in it)
print(ret2)
#生成器对象不能迭代第二次,上面ret的时候,it已经被迭代完了
#ret2的时候只能得到文件最后一行的记录,因为yeild就停留在这里
#生成器只能for循环一次
'''
生成器的.send()方法
def producer():
print(‘first produce’)
first = yield 1 #send发送的值被yield接收并传递给first
print(‘second product’, first)
yield 2
print(‘third product’)
yield 3
#def consumer():
gen = producer()
ret = gen.__next__()
print(ret)
gen.send(None)
#gen.send(‘第一次yield完成’)
#send的作用:1.传递一个值给当前yield 2.触发执行到下一个yield
生产者消费者模型
#在一个进程中实现并行 → 协程
def producer():
c = consumer()
c.__next__()
for i in range(10):
time.sleep(1)
c.send(i)
def consumer():
print(‘consumer’)
while True:
temp = yield
time.sleep(1)
print(‘consumer %s’ %temp)
producer()
3. 装饰器函数与函数闭包
☞装饰器
什么是装饰器
- 装饰器
器的本质是一个函数,装饰是指修饰其他函数,为其他函数添加附加功能。
装饰器两个原则:一是不修改被修饰函数的源代码;二是不修改被修饰函数的调用方式。 (必须遵循)
装饰器 = 高阶函数 + 函数嵌套 + 闭包 - 高阶函数
高阶函数的定义主要有两个原则:一是函数接收的参数是一个函数名;二是函数的返回值是一个函数名。满足二者之一就是高阶函数。
示例
实现一个功能:统计函数foo的执行时间,并且不能修改foo的源代码,不能修改foo的调用方式。
import time
def foo():
time.sleep(3)
print(‘function foo’)
def timer(func)
start_time = time.time()
func()
stop_time = time.time()
print(‘func run time %s’ %(stop_time – start_time))
return func
#timer(foo) 修改了foo的调用方式,原调用方式为foo()
foo = timer(foo)
#再次强调:函数名是函数地址,函数名加括号才是函数调用
foo() #这样会执行两次foo函数
函数嵌套
在函数内部定义函数(在函数内部定义函数,而不是调用函数)
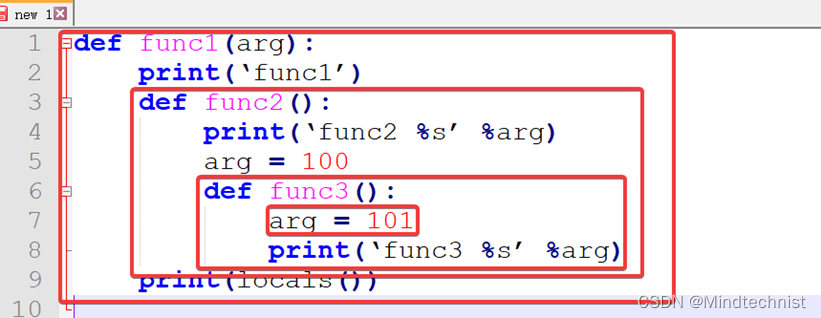
def func1(arg):
print(‘func1’)
def func2(): #作用域在func1内,只能在func1内调用,是局部变量
print(‘func2 %s’ %arg)
arg = 100
def func3():
print(‘func3 %s’ %arg) #本层未找到,则去上一层寻找
print(locals()) #函数即变量 func2 arg
☞函数闭包
闭即封装(变量),包即一层,闭包即作用域。
实现装饰器
实现一个功能:给test增加一个功能,统计函数test的执行时间,不修改test的源码,不改变test的调用方式
import time
def test():
time.sleep(3)
print(‘function test’)
def timmer(func)
def wrapper():
start_time = time.time()
func()
stop_time = time.time()
print(‘func run time %s’ %(stop_time – start_time))
return wrapper
test = timmer(test)
test()
#缺点:调用test之前需要一个赋值操作test = timmer(test)
改进,使用@语法糖
@timmer #相当于test = timmer(test)
def test():
time.sleep(3)
print(‘function test’)
test()
"""
只要把@timmer放在被装饰的函数前就行,它就相当于把被装饰函数的函数名test传递给timmer()并把返回值重新赋给test。
"""
改进1: 加上返回值,即被修饰函数有返回值
import time
def timmer(func)
def wrapper():
start_time = time.time()
ret = func()
stop_time = time.time()
print(‘func run time %s’ %(stop_time – start_time))
return ret #返回test的返回值
return wrapper
@temmer
def test():
time.sleep(3)
print(‘function test’)
return ‘test return’
ret = test() #表面上运行的是test实际上运行的是wrapper
#要想得到test()函数的返回值,就应该把test的返回值加在wrapper
#函数的return语句中
print(ret)
改进2: 给函数闭包加上参数,即被修饰函数有参数
可变参数
# *args – 接收全部位置参数
# **kwargs – 接收关键字参数key=value
def func(*args, **kwargs): #就相当于,把所有位置参数传给args组成一个元组,把所有关键字参数传给kwargs组成一个字典。
import time
def timmer(func)
def wrapper(*args, **kwargs): #可变参数
start_time = time.time()
ret = func(*args, **kwargs)
stop_time = time.time()
print('func run time %s' %(stop_time – start_time))
return ret #返回test的返回值
return wrapper
@temmer
def test(name, age):
time.sleep(3)
print('function test [%s - %s]' %(name, age))
return 'test return'
ret = test('su', age = 18)
"""
wrapper(*args, **kwargs): 接收到的参数
args – ('su')
kwargs – {'age':18}
所以,当wrapper传参给test的时候,必须是*('su') **{'age':18}才行,*就是把列表里面的东西拿出来
"""
print(ret)
为其他函数做装饰
@temmer
def test2(name, age, gender):
time.sleep(3)
print('function test2 [%s - %s - %s]' %(name, age, gender))
return 'test return'
ret = test2('su', 18, 'girl')
# ret = test2(*('su', 18), **{'gender':'girl'}) #传参方式2
"""
解压序列:
test2(name, age, gender) (*(‘su’, 18), **{‘gender’:‘girl’})
name, age = (‘su’, 18), gender = ‘girl’
一一对应去赋值
比如 a, b, c = (1, 2, 3) #a=1, b=2, c=3
a, b, c = (1, 2, 3, 4) #err
"""
序列解压
a, b, c = ‘hel’
a, b, c = (1, 2, 3)
a, b, c = [1, 2, 3]
只要后面是一个序列就行,并且必须要一一对应。
如果有一个很长很长的序列li,我们只想取出该序列的第一个和最后一个元素,应该怎么办呢?
first, *_, last = li ,这样就可以可,*表示中间所有的元素组成的子序列
first, *mid, last = li , mid = [ ] , 对li去头去尾后的子序列
交换a, b的值可以直接a, b = b, a
有参装饰器
在原来的装饰器外面再套一层函数,根据参数可以进行一些逻辑判断。
def timmer_type(type = '1'):
def timmer(func):
#原来的逻辑不变,可以加一些判断
if type == '1'
print('type1')
#逻辑1
else:
print('other')
#其他逻辑
return timmer
@timmer_type(type = '1') # timmer = timmer_type(type = '1')
def test():
print('test')
"""
这里的@timmer_type(type = '1') 就相当于
timmer = timmer_type(type = '1') 也就相当于
@timmer() 只不过在timmer的基础上增加了一个外层函数
通过这个外层函数可以传入参数,并在内部根据参数增加一些逻辑
"""
举例
def auth(driver='file'):
def auth2(func):
def wrapper(*args,**kwargs):
name=input("user: ")
pwd=input("pwd: ")
if driver == 'file':
if name == 'egon' and pwd == '123':
print('login successful')
res=func(*args,**kwargs)
return res
elif driver == 'ldap':
print('ldap')
return wrapper
return auth2
@auth(driver='file')
def foo(name):
print(name)
foo('egon')