目录
- 1. 安装依赖
- 2. 安装Kylin(kylin1上操作)
- 2.1 下载解压
- 2.2 修改conf/kylin.properties
- 2.3 下载Mysql驱动包和创建Mysql数据库
- 2.4 hive-site.xml复制到spark的conf目录
- 2.5 配置环境变量(两台kylin服务器)
- 2.6 kylin运行环境检查
- 2.7 ConfigurationException问题(没有则忽略)
- 2.8 将Kylin目录分发到另外两台服务器
- 2.9 启动Kylin(两台kylin服务器)
- 2.10 访问Web UI
1. 安装依赖
| 组件 | 安装版本 | 官方推荐版本 | 设置环境变量 | 安装参考文档 |
|---|---|---|---|---|
| Java | 1.8 | 1.8 | JAVA_HOME | centos7同时安装java8和openJdk11、windows同时安装java8和openJdk11 |
| Zookeeper | 3.6.3 | 3.4.13 | https://blog.csdn.net/yy8623977/article/details/122555847 | |
| HDFS | 3.3.1 | 3.2.0 | HADOOP_HOME | https://blog.csdn.net/yy8623977/article/details/118972314 |
| Mysql | 8.0.25 | 5.1.8 | centos7安装mysql8.0.25版本 | |
| Hive | 3.1.2 | 2.3.9 | HIVE_HOME | 在Centos7上进行Hive 3.1.2集群安装 |
| Spark | 3.1.2 | 3.1.1 | SPARK_HOME | Spark3.1.2 Standalone高可用HA分布式部署(含pyspark) |
2. 安装Kylin(kylin1上操作)
在kylin1和kylin2两台服务器安装Kylin
2.1 下载解压
[root@kylin1 ~]# wget --no-check-certificate https://dlcdn.apache.org/kylin/apache-kylin-4.0.1/apache-kylin-4.0.1-bin-spark3.tar.gz
[root@kylin1 ~]#
[root@kylin1 ~]# tar -zxvf apache-kylin-4.0.1-bin-spark3.tar.gz
[root@kylin1 ~]#
[root@kylin1 ~]# cd apache-kylin-4.0.1-bin-spark3
[root@kylin1 apache-kylin-4.0.1-bin-spark3]#
2.2 修改conf/kylin.properties
修改内容如下:
kylin.metadata.url=kylin_metadata@jdbc,url=jdbc:mysql://kylin1:3306/kylin,username=root,password=Root_123,maxActive=10,maxIdle=10
# 第二层目录是mysql元数据表名,默认是kylin_metadata。第三层是project名
kylin.env.hdfs-working-dir=/kylin
kylin.env.zookeeper-is-local=false
kylin.env.zookeeper-connect-string=kylin1:2181,kylin2:2181,kylin3:2181
# all表示该kylin服务既做cube构建,也提供query
kylin.server.mode=all
# kylin集群服务器列表。客户端还是只能和单个节点通信,需要借助Nginx等实现负载均衡
kylin.server.cluster-servers=kylin1:7070,kylin2:7070,kylin3:7070
kylin.web.timezone=GMT+8
# 配置job scheduelr为CuratorScheculer,并添加kylin.server.self-discovery-enabled参数
kylin.job.scheduler.default=100
kylin.server.self-discovery-enabled=true
# 开启cube的Planner查看
kylin.cube.cubeplanner.enabled=true
kylin.cube.cubeplanner.enabled-for-existing-cube=true
kylin.env.hadoop-conf-dir=/root/hadoop-3.3.1/etc/hadoop
# 虽然Spark是高可用,但kylin的spark客户端连接不能做到高可用
kylin.engine.spark-conf.spark.master=spark://kylin1:7077
kylin.engine.spark-conf.spark.submit.deployMode=client
kylin.engine.spark-conf.spark.executor.memory=512M
# 构建engine的executor的堆外内存
kylin.engine.spark-conf.spark.executor.memoryOverhead=512M
kylin.engine.spark-conf.spark.driver.memory=512M
kylin.engine.spark-conf.spark.eventLog.dir=hdfs://nnha/kylin/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs://nnha/kylin/spark-history
kylin.query.spark-conf.spark.master=spark://kylin1:7077
kylin.query.spark-conf.spark.driver.memory=512M
kylin.query.spark-conf.spark.driver.memoryOverhead=512M
# 每个executor的使用cpu数
kylin.query.spark-conf.spark.executor.cores=1
kylin.query.spark-conf.spark.executor.memory=512M
kylin.query.spark-conf.spark.executor.memoryOverhead=512M
2.3 下载Mysql驱动包和创建Mysql数据库
下载Mysql驱动包
[root@kylin1 apache-kylin-4.0.1-bin-spark3]# mkdir ext
[root@kylin1 apache-kylin-4.0.1-bin-spark3]#
[root@kylin1 apache-kylin-4.0.1-bin-spark3]# wget -P /root/apache-kylin-4.0.1-bin-spark3/ext https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.25/mysql-connector-java-8.0.25.jar
[root@kylin1 apache-kylin-4.0.1-bin-spark3]#
创建Mysql数据库
mysql> create database kylin;
Query OK, 1 row affected (0.02 sec)
mysql>
2.4 hive-site.xml复制到spark的conf目录
为了spark能直接查询hive的各种数据,需要将hive-site.xml复制到spark集群所有服务器的conf目录下
[root@kylin1 ~]# scp /root/apache-hive-3.1.2-bin/conf/hive-site.xml root@kylin1:/root/spark-3.1.2-bin-hadoop3.2/conf
2.5 配置环境变量(两台kylin服务器)
添加KYLIN_HOME环境变量到/etc/profile
export KYLIN_HOME=/root/apache-kylin-4.0.1-bin-spark3
然后进行source生效
2.6 kylin运行环境检查
检查依赖的各个组件的版本、访问权限、CLASSPATH等是否符合要求
[root@kylin1 ~]# $KYLIN_HOME/bin/check-env.sh
Retrieving hadoop conf dir...
...................................................[PASS]
KYLIN_HOME is set to /root/apache-kylin-4.0.1-bin-spark3
Checking hive
...................................................[PASS]
Checking hadoop shell
...................................................[PASS]
Checking hdfs working dir
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
...................................................[PASS]
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
Checking environment finished successfully. To check again, run 'bin/check-env.sh' manually.
[root@kylin1 ~]#
2.7 ConfigurationException问题(没有则忽略)
如果启动Kylin,出现如下问题
2022-07-26 16:39:33,708 INFO [localhost-startStop-1] metrics.MetricsManager:142 : Kylin metrics monitor is not enabled
2022-07-26 16:39:33,963 WARN [localhost-startStop-1] support.XmlWebApplicationContext:550 : Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping': Invocation of init method failed; nested exception is java.lang.NoClassDefFoundError: org/apache/commons/configuration/ConfigurationException
2022-07-26 16:39:33,994 ERROR [localhost-startStop-1] context.ContextLoader:350 : Context initialization failed
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping': Invocation of init method failed; nested exception is java.lang.NoClassDefFoundError: org/apache/commons/configuration/ConfigurationException
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1619)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:553)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:481)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:312)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:308)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:757)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:867)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:542)
at org.springframework.web.context.ContextLoader.configureAndRefreshWebApplicationContext(ContextLoader.java:443)
at org.springframework.web.context.ContextLoader.initWebApplicationContext(ContextLoader.java:325)
at org.springframework.web.context.ContextLoaderListener.contextInitialized(ContextLoaderListener.java:107)
at org.apache.catalina.core.StandardContext.listenerStart(StandardContext.java:5197)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5720)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:183)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:1016)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:992)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:639)
at org.apache.catalina.startup.HostConfig.deployWAR(HostConfig.java:1127)
at org.apache.catalina.startup.HostConfig$DeployWar.run(HostConfig.java:2020)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoClassDefFoundError: org/apache/commons/configuration/ConfigurationException
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.getDeclaredMethods(Class.java:1975)
at org.springframework.util.ReflectionUtils.getDeclaredMethods(ReflectionUtils.java:612)
at org.springframework.util.ReflectionUtils.doWithMethods(ReflectionUtils.java:523)
at org.springframework.core.MethodIntrospector.selectMethods(MethodIntrospector.java:68)
at org.springframework.web.servlet.handler.AbstractHandlerMethodMapping.detectHandlerMethods(AbstractHandlerMethodMapping.java:230)
at org.springframework.web.servlet.handler.AbstractHandlerMethodMapping.initHandlerMethods(AbstractHandlerMethodMapping.java:214)
at org.springframework.web.servlet.handler.AbstractHandlerMethodMapping.afterPropertiesSet(AbstractHandlerMethodMapping.java:184)
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping.afterPropertiesSet(RequestMappingHandlerMapping.java:134)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1677)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1615)
... 25 more
Caused by: java.lang.ClassNotFoundException: org.apache.commons.configuration.ConfigurationException
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1951)
at org.apache.kylin.spark.classloader.TomcatClassLoader.loadClass(TomcatClassLoader.java:108)
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1794)
... 37 more
是因为Kylin开发时,使用的Hadoop 2.7.3。通过下载Kylin源码,然后用Maven命令mvn dependency:tree查看依赖树情况,得到Hadoop 2.7.3依赖commons-configuration:commons-configuration:1.6
而我们现在使用的是Hadoop 3.3.1,所以需要下载commons-configuration-1.6.jar到apache-kylin-4.0.1-bin-spark3/tomcat/webapps/kylin/WEB-INF/lib目录下,该目录需要启动kylin后才会创建
2.8 将Kylin目录分发到另外两台服务器
[root@kylin1 ~]# scp -r apache-kylin-4.0.1-bin-spark3 root@kylin2:/root
[root@kylin1 ~]# scp -r apache-kylin-4.0.1-bin-spark3 root@kylin3:/root
2.9 启动Kylin(两台kylin服务器)
[root@kylin1 ~]# $KYLIN_HOME/bin/kylin.sh start
Retrieving hadoop conf dir...
...................................................[PASS]
KYLIN_HOME is set to /root/apache-kylin-4.0.1-bin-spark3
Checking hive
...................................................[PASS]
Checking hadoop shell
...................................................[PASS]
Checking hdfs working dir
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
...................................................[PASS]
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
Checking environment finished successfully. To check again, run 'bin/check-env.sh' manually.
Retrieving hadoop conf dir...
Retrieving Spark dependency...
Skip spark which not owned by kylin. SPARK_HOME is /root/spark-3.1.2-bin-hadoop3.2 and KYLIN_HOME is /root/apache-kylin-4.0.1-bin-spark3.
Please download the correct version of Apache Spark, unzip it, rename it to 'spark' and put it in /root/apache-kylin-4.0.1-bin-spark3 directory.
Do not use the spark that comes with your hadoop environment.
If your hadoop environment is cdh6.x, you need to do some additional operations in advance.
Please refer to the link: https://cwiki.apache.org/confluence/display/KYLIN/Deploy+Kylin+4+on+CDH+6.
Start to check whether we need to migrate acl tables
Not HBase metadata. Skip check.
A new Kylin instance is started by root. To stop it, run 'kylin.sh stop'
Check the log at /root/apache-kylin-4.0.1-bin-spark3/logs/kylin.log
Web UI is at http://kylin1:7070/kylin
[root@kylin1 ~]#
停止kylin使用命令:$KYLIN_HOME/bin/kylin.sh start
2.10 访问Web UI
访问:http://kylin1:7070/kylin,输入用户名和密码:ADMIN/KYLIN,进行登录。如下所示:
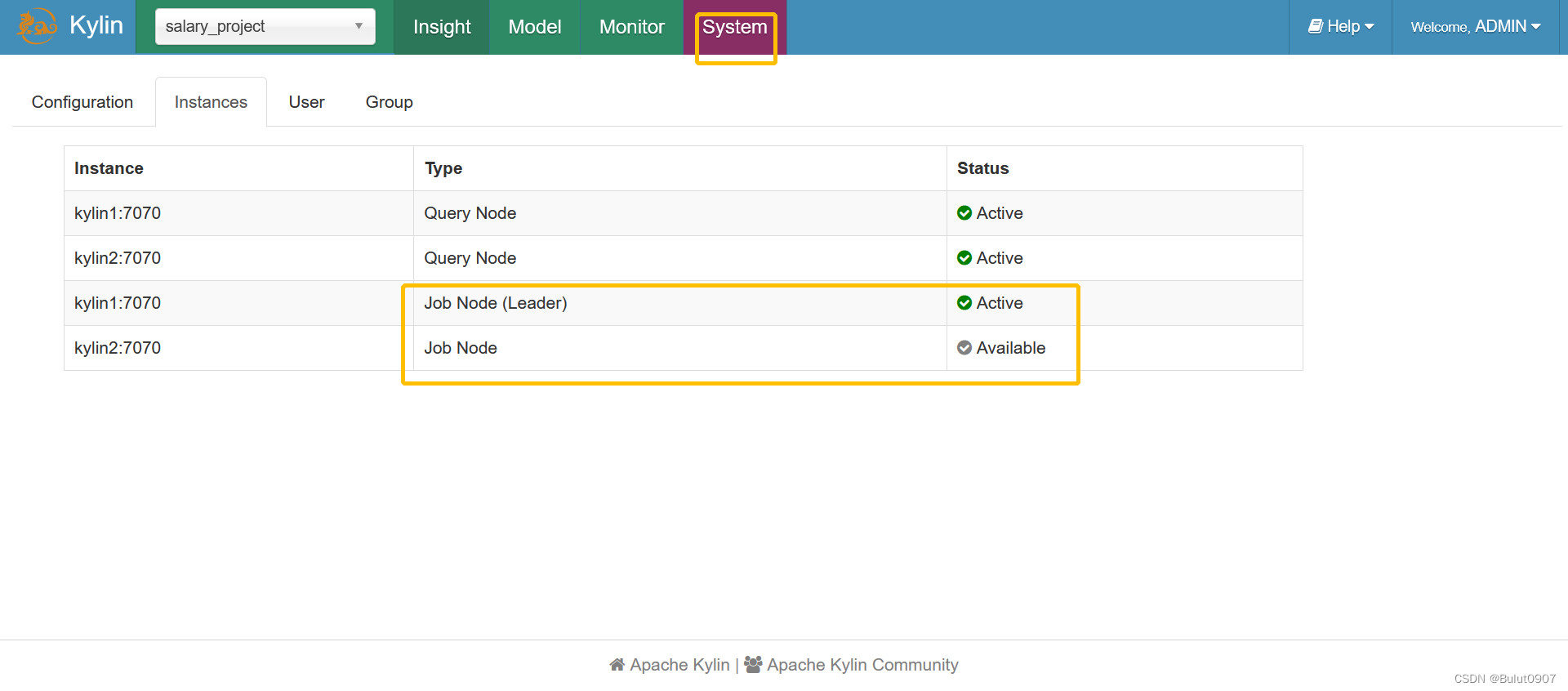
 查看集群信息,kylin1为主,kylin2为从。但是也可以从kylin2的Web界面进行cube的构建提交,相当于客户端
查看集群信息,kylin1为主,kylin2为从。但是也可以从kylin2的Web界面进行cube的构建提交,相当于客户端













![[文件上传工具类] MultipartFile 统一校验](https://img-blog.csdnimg.cn/b98dda4f2a7d44a6bf487225c1a8e2a4.png)
