RDD设计背景与概念
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
资料来源。1
RDD处理流程
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
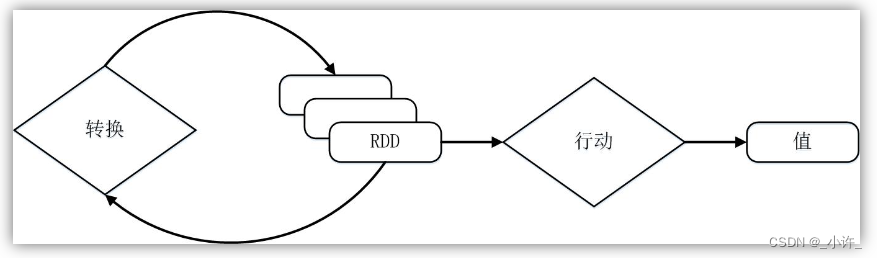
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中(如图9-8所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。



如图1,创建了word.txt文件,内容如上;图二加载文件,视频统计逻辑;图三打印生成RDD内容;图五显示了每一个生成的对象都为一个RDD。
可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。RDD之间依次延用,相互依赖。最后行动操作将RDD进行持久化,把它保存在内存或磁盘中。(内存为scala程序的沿用)。
总结:
Spark的核心是建立在统一的抽象RDD之上,使得Spark的各个组件可以无缝进行集成,在同一个应用程序中完成大数据计算任务。
用于计算一个RDD集合的执行过程如下:
- 创建这个Spark程序的执行上下文,即创建SparkContext对象;(scala种操作spark的上下文连接)。
- 从外部数据源中读取数据通过SparkContext创建RDD对象;
- RDD的转换(构建RDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;)
- 行动类型的操作,触发真正的计算,并把结果持久化到内存中。
RDD分区
分区的概念
分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个数,也是由RDD(准确来说是作业最后一个RDD)的分区数决定。
分区优势
RDD 是一种分布式的数据集,数据源多种多样,而且数据量也很大,在存储这些海量数据时,也是按照块来存的,当RDD读取这些数据进行操作时,实际上是对每个分区中的数据进行操作,每一个分区的数据可以并行操作,分区可以提高并行度。
RDD的分区原理
【spark】RDD的分区
RDD特性
-
数据集的基本组成单位是一组分片(Partition)或一个分区(Partition)列表。每个分片都会被一个计算任务处理,分片数决定并行度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值(默认值2)。
-
一个函数会被作用在每一个分区。Spark中RDD的计算是以分区为单位的,函数会被作用到每个分区上。
-
一个RDD会依赖于其他多个RDD。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。(Spark的容错机制)
-
K-V类型的RDD会有一个Partitioner函数。非key-value的RDD的Parititioner的值是None,Partitioner函数决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分区数量。
-
每个RDD维护一个列表,每个Partition的位置(preferred location)存储在一个列表中。
RDD转换(transformation)和行动(action)
RDD的操作分为两大类:转换(transformation)和行动(action)
转换:通过操作将一个RDD转换成另一个RDD
行动:将一个RDD进行求值或者输出
所有这些操作主要针对两种类型的RDD:
1)数值RDD(value型)
2)键值对RDD (K-V型)
RDD的所有转换操作都是懒执行的,只有当行动操作出现的时候Spark才会去真的执行
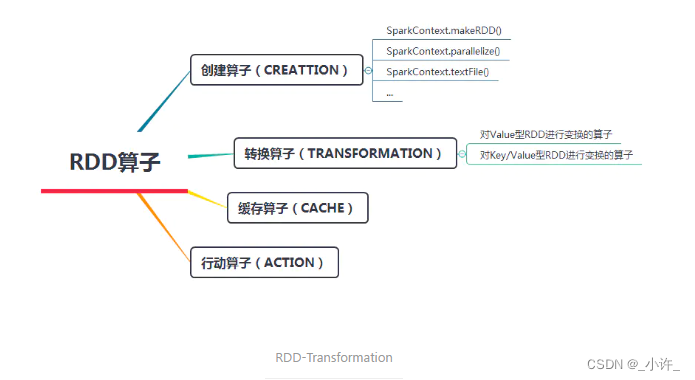
转换(Transformation)算子就是对RDD进行操作的接口函数,其作用是将一个或多个RDD变换成新的RDD。使用Spark进行数据计算,在利用创建算子生成RDD后,数据处理的算法设计和程序编写的最关键部分,就是利用变换算子对原始数据产生的RDD进行一步一步的变换,最终得到期望的计算结果。
动作(actions)是触发调度的算子,它会返回一个结果或者将数据写到外存中。
RDD API
创建RDD
- 由外部存储系统的数据集创建
//本地加载数据创建RDD
val baseRdd = sc.textFile("file:///wordcount/input/words.txt")
//加载hdfs文件
val textFile = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
- 通过已有的RDD经过算子转换生成新的RDD



- 已经存在的Scala集合创建
-
方法1 :
sc.parallelize(Array(1,2,3,4,5,6,7,8)) -
方法2 :
sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDD方法底层调用了parallelize方法,调用parallelize()方法的时候,不指定分区数的时候,使用系统给出的分区数,而调用makeRDD()方法的时候,会为每个集合对象创建最佳分区


- 通过消息队列(例如kafka,rabbitMQ)创建RDD
主要用于流式处理应用(小编还没学过哈)。
RDD转换



图片来源2
RDD行动

其他参考资料:
Spark之RDD算子-转换算子
spark和RDD的知识梳理与总结
RDD操作详解(三)Action操作
Spark之RDD动作算子(Action)大全
RDD持久化
RDD数据持久化什么作用?
1、对多次使用的rdd进行缓存,缓存到内存,当后续频繁使用时直接在内存中读取缓存的数据,不需要重新计算。
2、将RDD结果写入硬盘(容错机制),当RDD丢失数据时,或依赖的RDD丢失数据时,可以使用持久化到硬盘的数据恢复。
对于RDD最后的归宿除了返回为集合标量,也可以将RDD存储到外部文件系统或数据库中。Spark与Hadoop是完全兼容的,所以对于MapReduce所支持的读写文件或者数据库类型,Spark也同样支持。
写入HDFS



写入缓存
RDD通过cache()或者persist()将前面的计算结果缓存,默认情况下会把数据缓存在JVM的堆内存中。cache() 不需要传参,persist()需要设置持久化级别。
持久化级别有(先列在这,后面会详细讲):
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER;
- DISK_ONLY
- MEMORY_ONLY_2
- MEMORY_AND_DISK_2
cache()底层就是调用了persist(),并且将持久化级别设置成MEMORY_ONLY,也就是说 cache() 和 persist(StorageLevel.MEMORY_ONLY) 是一样的。
可以使用unpersist()方法手动地把持久化的RDD从缓存中移除。
写入HDFS(Spark自己方法)
将数据写入HDFS,利用HDFS永久存储。
操作过程:
-
设置持久化的存储路径
-
调用checkpoint()进行数据的保存
SparkContext.setCheckpointDir("HDFS的目录") -
调用持久化方法
RDD.checkpoint()
写入本地目录
wordCount1.saveAsTextFile("file:///home/master/hadoop/files/...")


总结:
-
Persist 和 Cache将数据保存在内存
-
Checkpoint将数据保存在HDFS
-
Persist 和 Cache 程序结束后会被清除或手动调用unpersist方法。
-
Checkpoint永久存储不会被删除。
相关参考:spark和RDD的知识梳理与总结
资料来源于厦门大学林子雨教授——Spark入门:RDD的设计与运行原理 ↩︎
Spark的RDD操作:转换(transformation)和行动(action) ↩︎











![[文件上传工具类] MultipartFile 统一校验](https://img-blog.csdnimg.cn/b98dda4f2a7d44a6bf487225c1a8e2a4.png)