-
建立一个高效的知识库对于个人和组织来说非常重要。无论是为了个人学习和成长,还是为了组织的持续创新和发展,一个完善的知识管理系统都是不可或缺的。那么,如何建立一个高效的知识库呢?
- 在建立知识库之前,首先需要确定清晰的目标。你想要将知识库用于什么目的?是为了提高团队的协作效率?还是为了更好地管理和传承组织内部的专业知识?或者是为了提供给客户和用户一个统一的知识查询平台?只有明确了目标,才能有针对性地选择和设计知识库系统。
- 根据你的目标和需求,选择一个适合的知识库工具非常重要。市面上有许多知识库管理工具,例如Confluence、SharePoint、Notion等,它们都有各自的特点和功能。你可以根据自己的需求进行比较和选择,确保选择一个易用且符合你要求的工具。
- 建立知识库的核心是收集和整理知识。你可以从多个渠道搜集知识,例如内部文档、培训资料、项目总结等。同时,你也可以鼓励团队成员贡献自己的知识和经验。在整理知识时,可以根据不同的主题和类别进行分类,采用标签、目录等方式进行组织,使得知识库结构清晰、易于查找。
- 在建立知识库时,设计一个合理的知识库结构非常重要。你可以根据知识的类型、领域、层级等因素进行分类和组织。同时,你也可以根据不同的用户需求,设计不同的访问权限和查看方式,以便用户能够根据自己的需求获取到所需的知识。
- 知识库的内容和知识是不断变化和更新的。为了保持知识库的有效性和及时性,你需要定期更新和维护知识库。你可以设立专门的知识库管理人员,负责对知识库的内容进行审核和更新。同时,你也可以鼓励团队成员积极参与到知识库的维护中来,使得知识库能够不断地完善和发展。
-
同样是存储和记录,也许有些人会问,现在搜索引擎这么发达,想要的知道的东西搜一下就有,为什么还要建一个自己的知识库呢?因为在搜索引擎中搜索到的,只是信息,而不是知识。知识是阅读信息后,经过思考和理解的产物。搜索引擎里搜索到的信息,你依旧需要进行阅读处理,而不能直接使用。下图描述了从信息到知识的变化过程,信息是零散的点,而知识是经过处理后的产物。
-

-
在知识库里,过往积累的知识将变得容易追溯,每次读到自己过去的思考,都如同和自己过去的思想对话,思考后,或许又有新的发现。有时会发现自己的进步,修正过去的思想;有时又会惊讶于过去的思考,即便现在也让自己有启发,这种草稿拾遗的感觉很奇妙如何搭建知识库 - 少数派 (sspai.com)。
-
-
在RAG(Retrieval Augmented Generation,检索增强生成)方面词向量的优势主要有两点:
- 词向量比文字更适合检索。当我们在数据库检索时,如果数据库存储的是文字,主要通过检索关键词(词法搜索)等方法找到相对匹配的数据,匹配的程度是取决于关键词的数量或者是否完全匹配查询句的;但是词向量中包含了原文本的语义信息,可以通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度;
- 词向量比其它媒介的综合信息能力更强,当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;但是词向量却可以通过多种向量模型将多种数据映射成统一的向量形式。
-
在搭建 RAG 系统时,我们往往可以通过使用嵌入模型来构建词向量,我们可以选择:使用各个公司的 Embedding API;在本地使用嵌入模型将数据构建为词向量。
-
词向量(Embeddings)是一种将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。在机器学习和自然语言处理(NLP)中,词向量嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
-
我们可以使用词嵌入(word embeddings)来表示文本数据。在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,“king” 和 “queen” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的含义相似。而 “apple” 和 “orange” 也会很接近,因为它们都是水果。而 “king” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
-
向量数据库是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
-
向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索。向量数据库通过计算与目标向量的余弦距离、点积等获取与目标向量的相似度。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
-
Chroma:是一个轻量级向量数据库,拥有丰富的功能和简单的 API,具有简单、易用、轻量的优点,但功能相对简单且不支持GPU加速,适合初学者使用。
-
Weaviate:是一个开源向量数据库。除了支持相似度搜索和最大边际相关性(MMR,Maximal Marginal Relevance)搜索外还可以支持结合多种搜索算法(基于词法搜索、向量搜索)的混合搜索,从而搜索提高结果的相关性和准确性。
-
Qdrant:Qdrant使用 Rust 语言开发,有极高的检索效率和RPS(Requests Per Second),支持本地运行、部署在本地服务器及Qdrant云三种部署模式。且可以通过为页面内容和元数据制定不同的键来复用数据。
-
使用OpenAI API,本文对应源代码在[此处](https://github.com/datawhalechina/llm-universe/blob/main/notebook/C3 搭建知识库/2.使用 Embedding API.ipynb),如需复现可下载运行源代码。
-
import os from openai import OpenAI from dotenv import load_dotenv, find_dotenv # 读取本地/项目的环境变量。 # find_dotenv()寻找并定位.env文件的路径 # load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中 # 如果你设置的是全局的环境变量,这行代码则没有任何作用。 _ = load_dotenv(find_dotenv()) # 如果你需要通过代理端口访问,你需要如下配置 os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890' os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890' def openai_embedding(text: str, model: str=None): # 获取环境变量 OPENAI_API_KEY api_key=os.environ['OPENAI_API_KEY'] client = OpenAI(api_key=api_key) # embedding model:'text-embedding-3-small', 'text-embedding-3-large', 'text-embedding-ada-002' if model == None: model="text-embedding-3-small" response = client.embeddings.create( input=text, model=model ) return response response = openai_embedding(text='要生成 embedding 的输入文本,字符串形式。') -
API返回的数据为
json格式,除object向量类型外还有存放数据的data、embedding model 型号model以及本次 token 使用情况usage等数据,具体如下所示: -
{ "object": "list", "data": [ { "object": "embedding", "index": 0, "embedding": [ -0.006929283495992422, ... (省略) -4.547132266452536e-05, ], } ], "model": "text-embedding-3-small", "usage": { "prompt_tokens": 5, "total_tokens": 5 } } -
我们可以调用response的object来获取embedding的类型。
-
print(f'返回的embedding类型为:{response.object}') # 返回的embedding类型为:list print(f'embedding长度为:{len(response.data[0].embedding)}') print(f'embedding(前10)为:{response.data[0].embedding[:10]}') print(f'本次embedding model为:{response.model}') print(f'本次token使用情况为:{response.usage}')
-
-
数据处理:为构建我们的本地知识库,我们需要对以多种类型存储的本地文档进行处理,读取本地文档并通过前文描述的 Embedding 方法将本地文档的内容转化为词向量来构建向量数据库。在本节中,我们以一些实际示例入手,来讲解如何对本地文档进行处理。
-
我们选用 Datawhale 一些经典开源课程作为示例,具体包括:《机器学习公式详解》PDF版本;《面向开发者的LLM入门教程、第一部分Prompt Engineering》md版本。我们将知识库源数据放置在…/data_base/knowledge_db 目录下。
-
可以使用 LangChain 的 PyMuPDFLoader 来读取知识库的 PDF 文件。PyMuPDFLoader 是 PDF 解析器中速度最快的一种,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
-
from langchain.document_loaders.pdf import PyMuPDFLoader # 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径 loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf") # 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载 pdf_pages = loader.load() -
文档加载后储存在
pages变量中: page 的变量类型为 List;打印 pages 的长度可以看到 pdf 一共包含多少页 -
print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页") -
page中的每一元素为一个文档,变量类型为langchain_core.documents.base.Document, 文档变量类型包含两个属性;page_content包含该文档的内容。meta_data为文档相关的描述性数据。 -
pdf_page = pdf_pages[1] print(f"每一个元素的类型:{type(pdf_page)}.", f"该文档的描述性数据:{pdf_page.metadata}", f"查看该文档的内容:\n{pdf_page.page_content}", sep="\n------\n") -
可以以几乎完全一致的方式读入 markdown 文档:
-
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader loader = UnstructuredMarkdownLoader("../../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md") md_pages = loader.load()
-
-
数据清洗:期望知识库的数据尽量是有序的、优质的、精简的,因此我们要删除低质量的、甚至影响理解的文本数据。可以看到上文中读取的pdf文件不仅将一句话按照原文的分行添加了换行符
\n,也在原本两个符号中间插入了\n,我们可以使用正则表达式匹配并删除掉\n。-
import re pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL) pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content) print(pdf_page.page_content) -
进一步分析数据,我们发现数据中还有不少的
•和空格,我们的简单实用replace方法即可。 -
pdf_page.page_content = pdf_page.page_content.replace('•', '') pdf_page.page_content = pdf_page.page_content.replace(' ', '') print(pdf_page.page_content) md_page.page_content = md_page.page_content.replace('\n\n', '\n') print(md_page.page_content)
-
-
文档分割:由于单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此,在构建向量知识库的过程中,我们往往需要对文档进行分割,将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。在检索时,我们会以 chunk 作为检索的元单位,也就是每一次检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的。Langchain 中文本分割器都根据
chunk_size(块大小)和chunk_overlap(块与块之间的重叠大小)进行分割。- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
-
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
-
RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
-
CharacterTextSplitter(): 按字符来分割文本。
-
MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
-
TokenTextSplitter(): 按token来分割文本。
-
SentenceTransformersTokenTextSplitter(): 按token来分割文本
-
Language(): 用于 CPP、Python、Ruby、Markdown 等。
-
NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
-
SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
-
''' * RecursiveCharacterTextSplitter 递归字符文本分割 RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]), 这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置 RecursiveCharacterTextSplitter需要关注的是4个参数: * separators - 分隔符字符串数组 * chunk_size - 每个文档的字符数量限制 * chunk_overlap - 两份文档重叠区域的长度 * length_function - 长度计算函数 ''' #导入文本分割器 from langchain.text_splitter import RecursiveCharacterTextSplitter # 知识库中单段文本长度 CHUNK_SIZE = 500 # 知识库中相邻文本重合长度 OVERLAP_SIZE = 50 # 使用递归字符文本分割器 text_splitter = RecursiveCharacterTextSplitter( chunk_size=CHUNK_SIZE, chunk_overlap=OVERLAP_SIZE ) text_splitter.split_text(pdf_page.page_content[0:1000]) split_docs = text_splitter.split_documents(pdf_pages) print(f"切分后的文件数量:{len(split_docs)}") print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}") -
注:如何对文档进行分割,其实是数据处理中最核心的一步,其往往决定了检索系统的下限。但是,如何选择分割方式,往往具有很强的业务相关性——针对不同的业务、不同的源数据,往往需要设定个性化的文档分割方式。因此,在本章,我们仅简单根据 chunk_size 对文档进行分割。
-
-
数据准备好了之后,就可以搭建并使用向量数据库
-
import os from dotenv import load_dotenv, find_dotenv # 读取本地/项目的环境变量。 # find_dotenv()寻找并定位.env文件的路径 # load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中 # 如果你设置的是全局的环境变量,这行代码则没有任何作用。 _ = load_dotenv(find_dotenv()) # 如果你需要通过代理端口访问,你需要如下配置 # os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890' # os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890' # 获取folder_path下所有文件路径,储存在file_paths里 file_paths = [] folder_path = '../../data_base/knowledge_db' for root, dirs, files in os.walk(folder_path): for file in files: file_path = os.path.join(root, file) file_paths.append(file_path) print(file_paths[:3]) from langchain.document_loaders.pdf import PyMuPDFLoader from langchain.document_loaders.markdown import UnstructuredMarkdownLoader # 遍历文件路径并把实例化的loader存放在loaders里 loaders = [] for file_path in file_paths: file_type = file_path.split('.')[-1] if file_type == 'pdf': loaders.append(PyMuPDFLoader(file_path)) elif file_type == 'md': loaders.append(UnstructuredMarkdownLoader(file_path)) # 下载文件并存储到text texts = [] for loader in loaders: texts.extend(loader.load()) -
载入后的变量类型为
langchain_core.documents.base.Document, 文档变量类型同样包含两个属性:page_content包含该文档的内容。meta_data为文档相关的描述性数据。 -
text = texts[1] print(f"每一个元素的类型:{type(text)}.", f"该文档的描述性数据:{text.metadata}", f"查看该文档的内容:\n{text.page_content[0:]}", sep="\n------\n") from langchain.text_splitter import RecursiveCharacterTextSplitter # 切分文档 text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50) split_docs = text_splitter.split_documents(texts)
-
-
构建Chroma向量库:Langchain 集成了超过 30 个不同的向量存储库。我们选择 Chroma 是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。LangChain 可以直接使用 OpenAI 和百度千帆的 Embedding,同时,我们也可以针对其不支持的 Embedding API 进行自定义,例如,我们可以基于 LangChain 提供的接口,封装一个 zhipuai_embedding,来将智谱的 Embedding API 接入到 LangChain 中。
-
# 使用 OpenAI Embedding # from langchain.embeddings.openai import OpenAIEmbeddings # 使用百度千帆 Embedding # from langchain.embeddings.baidu_qianfan_endpoint import QianfanEmbeddingsEndpoint # 使用我们自己封装的智谱 Embedding,需要将封装代码下载到本地使用 from zhipuai_embedding import ZhipuAIEmbeddings # 定义 Embeddings # embedding = OpenAIEmbeddings() embedding = ZhipuAIEmbeddings() # embedding = QianfanEmbeddingsEndpoint() # 定义持久化路径 persist_directory = '../../data_base/vector_db/chroma' # !rm -rf '../../data_base/vector_db/chroma' # 删除旧的数据库文件(如果文件夹中有文件的话),windows电脑请手动删除 from langchain.vectorstores.chroma import Chroma vectordb = Chroma.from_documents( documents=split_docs[:20], # 为了速度,只选择前 20 个切分的 doc 进行生成;使用千帆时因QPS限制,建议选择前 5 个doc embedding=embedding, persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上 ) -
在此之后,我们要确保通过运行 vectordb.persist 来持久化向量数据库,以便以后使用!
-
vectordb.persist() print(f"向量库中存储的数量:{vectordb._collection.count()}")
-
-
向量检索
-
当你需要数据库返回严谨的按余弦相似度排序的结果时可以使用
similarity_search函数。 -
question="什么是大语言模型" sim_docs = vectordb.similarity_search(question,k=3) print(f"检索到的内容数:{len(sim_docs)}") for i, sim_doc in enumerate(sim_docs): print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n") -
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。最大边际相关性 (
MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。 -
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3) for i, sim_doc in enumerate(mmr_docs): print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
-
-
LangChain 为基于 LLM 开发自定义应用提供了高效的开发框架,便于开发者迅速地激发 LLM 的强大能力,搭建 LLM 应用。LangChain 也同样支持多种大模型的 Embeddings,内置了 OpenAI、LLAMA 等大模型 Embeddings 的调用接口。但是,LangChain 并没有内置所有大模型,它通过允许用户自定义 Embeddings 类型,来提供强大的可扩展性。
-
以智谱 AI 为例[llm-universe/notebook/C3 搭建知识库/附LangChain自定义Embedding封装讲解.ipynb at main · datawhalechina/llm-universe (github.com)](https://github.com/datawhalechina/llm-universe/blob/main/notebook/C3 搭建知识库/附LangChain自定义Embedding封装讲解.ipynb),讲述如何基于 LangChain 自定义 Embeddings。要实现自定义 Embeddings,需要定义一个自定义类继承自 LangChain 的 Embeddings 基类,然后定义两个函数:① embed_query 方法,用于对单个字符串(query)进行 embedding;②embed_documents 方法,用于对字符串列表(documents)进行 embedding。
-
首先我们导入所需的第三方库:
-
from __future__ import annotations import logging from typing import Dict, List, Any from langchain.embeddings.base import Embeddings from langchain.pydantic_v1 import BaseModel, root_validator logger = logging.getLogger(__name__) # 定义一个继承自 Embeddings 类的自定义 Embeddings 类: class ZhipuAIEmbeddings(BaseModel, Embeddings): """`Zhipuai Embeddings` embedding models.""" client: Any """`zhipuai.ZhipuAI""" -
在 Python 中,root_validator 是 Pydantic 模块中一个用于自定义数据校验的装饰器函数。root_validator 用于在校验整个数据模型之前对整个数据模型进行自定义校验,以确保所有的数据都符合所期望的数据结构。
-
root_validator 接收一个函数作为参数,该函数包含需要校验的逻辑。函数应该返回一个字典,其中包含经过校验的数据。如果校验失败,则抛出一个 ValueError 异常。这里我们只需将
.env文件中ZHIPUAI_API_KEY配置好即可,zhipuai.ZhipuAI会自动获取ZHIPUAI_API_KEY。 -
@root_validator() def validate_environment(cls, values: Dict) -> Dict: """ 实例化ZhipuAI为values["client"] Args: values (Dict): 包含配置信息的字典,必须包含 client 的字段. Returns: values (Dict): 包含配置信息的字典。如果环境中有zhipuai库,则将返回实例化的ZhipuAI类;否则将报错 'ModuleNotFoundError: No module named 'zhipuai''. """ from zhipuai import ZhipuAI values["client"] = ZhipuAI() return values -
embed_query是对单个文本(str)计算 embedding 的方法,这里我们重写该方法,调用验证环境时实例化的ZhipuAI来 调用远程 API 并返回 embedding 结果。 -
def embed_query(self, text: str) -> List[float]: """ 生成输入文本的 embedding. Args: texts (str): 要生成 embedding 的文本. Return: embeddings (List[float]): 输入文本的 embedding,一个浮点数值列表. """ embeddings = self.client.embeddings.create( model="embedding-2", input=text ) return embeddings.data[0].embedding -
embed_documents 是对字符串列表(List[str])计算embedding 的方法,对于这种类型输入我们采取循环方式挨个计算列表内子字符串的 embedding 并返回。
-
def embed_documents(self, texts: List[str]) -> List[List[float]]: """ 生成输入文本列表的 embedding. Args: texts (List[str]): 要生成 embedding 的文本列表. Returns: List[List[float]]: 输入列表中每个文档的 embedding 列表。每个 embedding 都表示为一个浮点值列表。 """ return [self.embed_query(text) for text in texts]
-
-
基于大语言模型知识问答应用落地实践 – 知识库构建(上) | 亚马逊AWS官方博客 (amazon.com)
-
从碎片到系统:设计师必备的知识库搭建指南 - 少数派 (sspai.com)
-
一文教你基于LangChain和ChatGLM3搭建本地知识库问答_人工智能_华为云开发者联盟_InfoQ写作社区
跟着DW学习大语言模型-什么是知识库,如何构建知识库
news2026/2/12 14:31:49
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1859950.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【办公类-51-01】月评估数字生成01-平均数空值
期末需要制作月评估,每月给孩子的能力水平打分。
以前我是做在EXCEL里,手动打分,然后用公式计算1、2、3出现的个数,然后计算平均数,最后复制到Word里。 因为是手动计算,每次都要算很长时间,确保…

借助TheGraph 查询ENS信息
关于ENS (以太坊域名服务) ENS 全称是 Ethereum Name Service,它是一个建立在以太坊区块链上的去中心化域名系统。
ENS 在 Web3 领域发挥着重要作用,主要有以下几个方面: 可读性更好的地址: ENS 允许用户将复杂的以太坊地址(如 0x12345…) 映射为更简单易记的域名。这极大地提…

KUBIKOS - Animated Cube Mini BIRDS(卡通立方体鸟类)
软件包中添加了对通用渲染管线 (URP) 的支持! KUBIKOS - 动画立方体迷你鸟是17种不同的可爱低多边形移动友好鸟的集合!每只都有自己的动画集。 完美收藏你的游戏! +17种不同的动物! + 低多边形(400~900个三角形) + 操纵和动画! + 4096x4096 纹理图集 + Mecanim 准备就绪…
生命在于学习——Python人工智能原理(4.3)
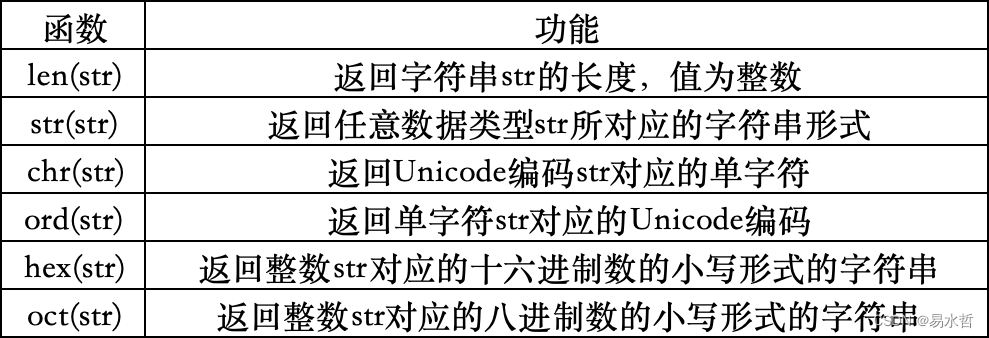
三、Python的数据类型
3.1 python的基本数据类型
3.1.4 布尔值(bool)
在Python中,布尔值是表示真或假的数据类型,有两个取值,True和False,布尔值常用于控制流程、条件判断和逻辑运算,本质上来…
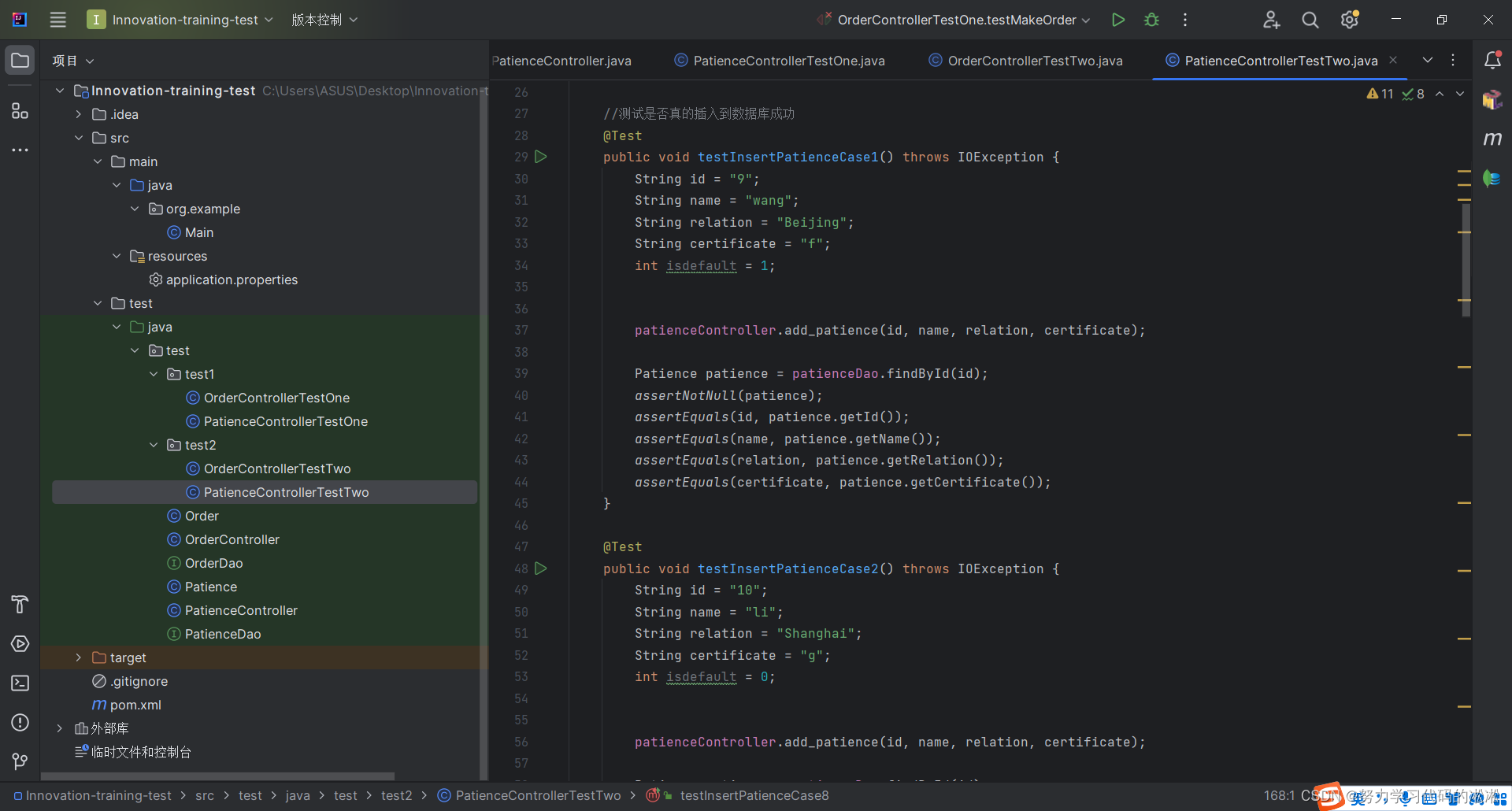
项目实训-接口测试(十八)
项目实训-后端接口测试(十八) 文章目录 项目实训-后端接口测试(十八)1.概述2.测试对象3.测试一4.测试二 1.概述
本篇博客将记录我在后端接口测试中的工作。
2.测试对象 3.测试一 这段代码是一个单元测试方法,用于验证…
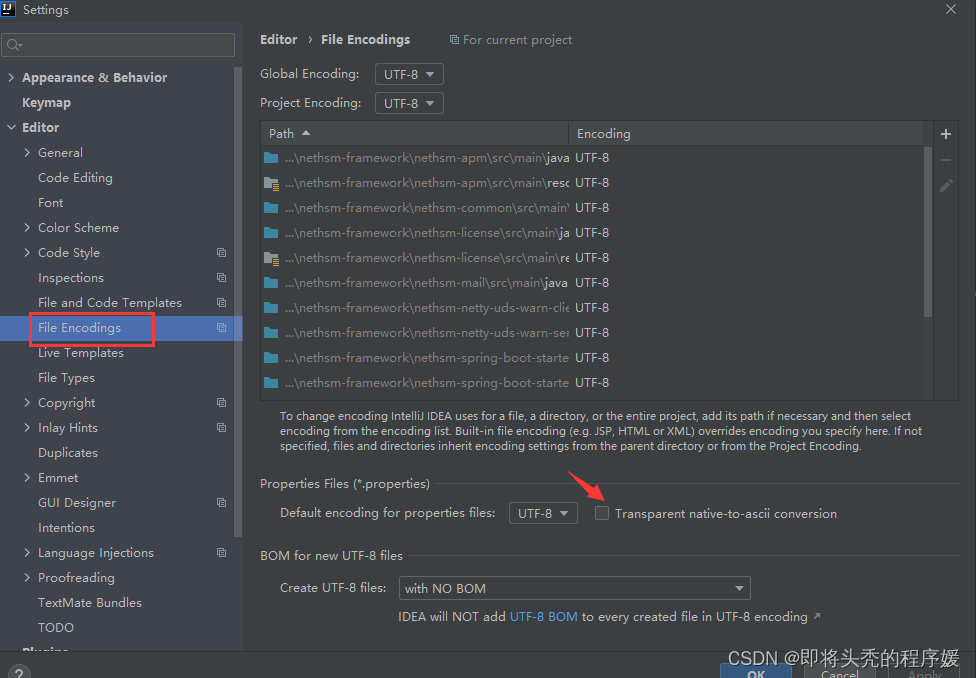
idea 开发工具properties文件中的中文不显示
用idea打开一个项目,配置文件propertise中的中文都不展示,如图: 可修改idea配置让中文显示: 勾选箭头指向的框即可,点击应用保存,重新打开配置文件,显示正常

Cell2Sentence:为LLM传输生物语言
像GPT这样的LLM在自然语言任务上表现出了令人印象深刻的性能。这里介绍一种新的方法,通过将基因表达数据表示为文本,让这些预训练的模型直接适应生物背景,特别是单细胞转录组学。具体来说,Cell2Sentence将每个细胞的基因表达谱转换…
前端架构(含演进历程、设计内容、AI辅助设计、架构演进历程)
前端架构的演进历程 前端架构师的必要条件 全面的技术底蕴全局观(近期 远期)业务要有非常深刻的理解沟通协调能力和团队意识深刻理解前端架构的原则和模式 前端架构的设计内容 技术选型(库、工具、标准规范、性能、安全、扩展性 )设计模式及代码组织(模…

ADS SIPro使用技巧之RapidScan-Z0
PCB走线的阻抗对每个网络的信号完整性至关重要,但是,验证每个信号是不切实际的,尤其对于设计复杂度很高的产品而言,设计者的有限精力只能用于关注关键的设计点,这一过程往往会造成一些设计的疏忽从而导致错误。 ADS SI…
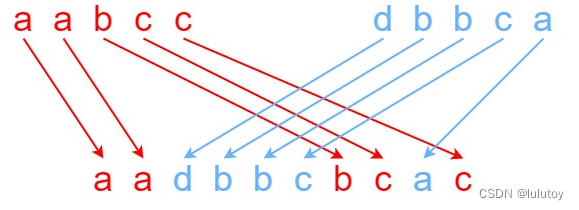
97. 交错字符串(leetcode)
97. 交错字符串(leetcode)
题目描述 给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。 两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串: s s1 …
图书管理系统(详解版 附源码)
目录
项目分析
实现页面
功能描述
页面预览
准备工作
数据准备
创建数据库
用户表
创建项目
导入前端页面
测试前端页面
后端代码实现
项目公共模块
实体类
公共层
统一结果返回
统一异常处理
业务实现
持久层
用户登录
用户注册
密码加密验证
添加图书…
串口小工具(来源网络,源码修改)
从CSDN 中的一位博主的分享做了一些修改 QtSerial 的配和更稳定些 信号和槽 … … 更不容易崩 # This Python file uses the following encoding: utf-8
import sys
import timefrom PySide6.QtGui import QIcon, QTextCursor
from PySide6.QtWidgets import QApplication, QWi…

【PyQt5】一文向您详细介绍 layout.addWidget() 的作用
【PyQt5】一文向您详细介绍 layout.addWidget() 的作用 下滑即可查看博客内容 🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇 🎓 博主简介:985高校的普通本…

el-dialog el-select适配移动端
一、el-dialog
2024.06.20今天我学习了如何对el-dialog弹窗适配移动端展示,效果如下: 代码如下:
media screen and (min-width: 220px) and (max-width: 600px) {::v-deep .el-dialog {width: 95% !important;}
}
二、el-select
代码如下…

技术革命背后的新功能发布:探索Facebook创新
随着技术的飞速发展和社交媒体的普及,Facebook作为全球最大的社交平台之一,不断推出新的功能和服务,以满足用户的需求和提升用户体验。这些新功能不仅仅是技术进步的体现,更是Facebook在竞争激烈的数字化时代中保持领先地位的关键…
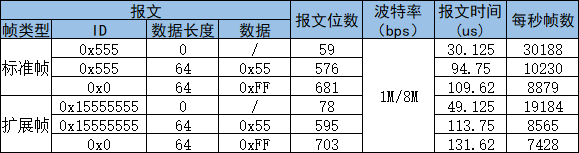
CANFD每秒最多可以发送多少帧报文?CAN FD结构详解
我们知道CANFD比CAN拥有更长的数据长度(最长64字节),更高的波特率(8Mbps甚至更高)。那么波特率更高,数据更长的CANFD,一秒钟最高可以发送多少帧CANFD报文呢? 想知道问题的答案&#…

C++结构体内存对齐规则
背景介绍
最近在使用Java语言写一个Java客户端,对接一个C/C语言编写的Server时,采用TCP协议进行通信,在将C结构体序列化的输出流转换为Java结构体时,需要按照结构体每个字段对应的字节长度截取字节流转换为Java类型,遇…

2024国际数字能源展,推动全球能源产业转型升级和可持续发展
随着全球对能源安全和可持续发展的日益关注,数字能源技术作为推动能源革命的重要力量,正逐步成为国际能源领域的新热点。2023年6月29日至7月2日,深圳会展中心成功举办了全球首个以数字能源为主题的2023国际数字能源展,这一盛会的成…
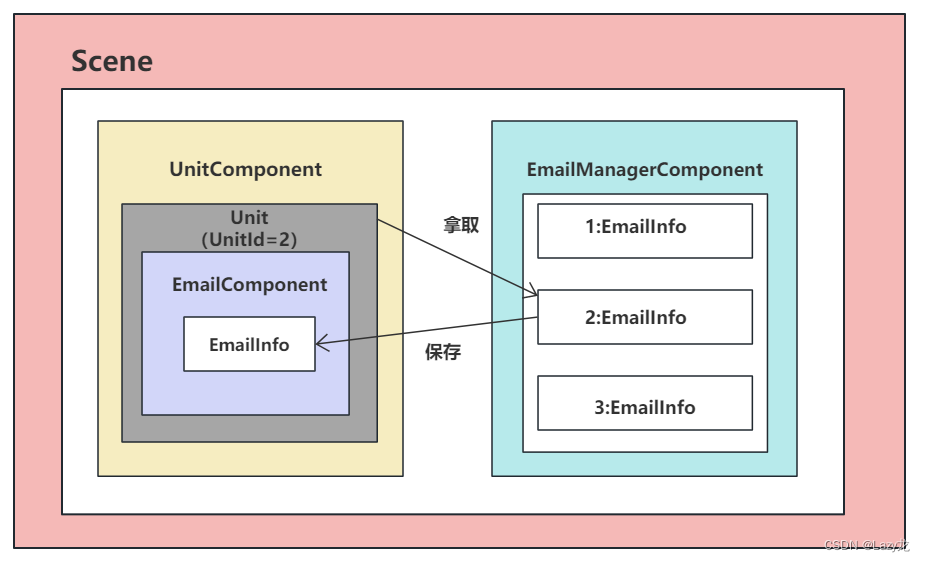
ET实现游戏中邮件系统逻辑思路(服务端)
ET是一个游戏框架,用的编程语言是C#,游戏引擎是Unity,框架作者:熊猫 ET社区 在游戏中我们通常都会看到有邮件系统,邮件系统的作用有给玩家通知、发放奖励等
下面小编使用ET框架带大家看一下邮件系统的一种实现方…