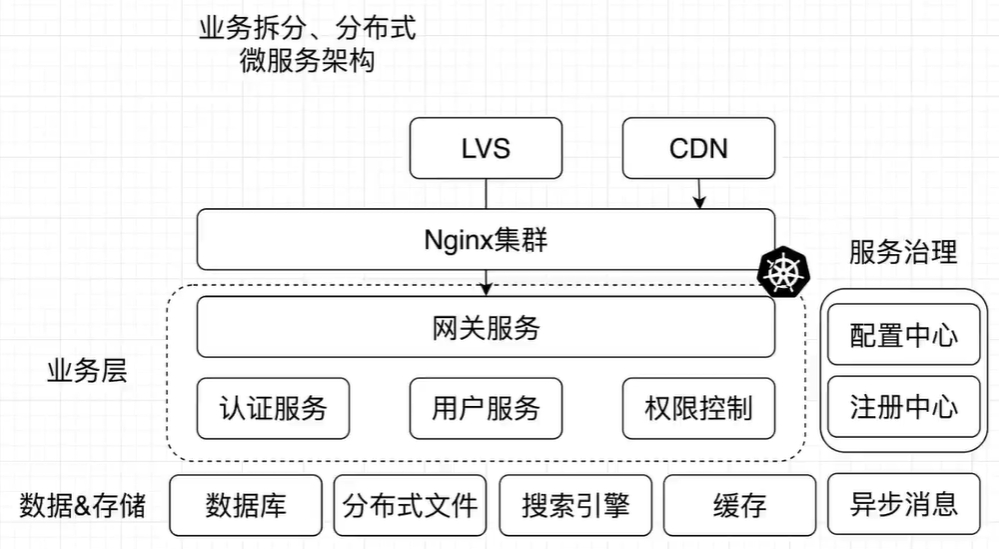
期末需要制作月评估,每月给孩子的能力水平打分。
 以前我是做在EXCEL里,手动打分,然后用公式计算1、2、3出现的个数,然后计算平均数,最后复制到Word里。
以前我是做在EXCEL里,手动打分,然后用公式计算1、2、3出现的个数,然后计算平均数,最后复制到Word里。

因为是手动计算,每次都要算很长时间,确保逐月的分数平均值增加




第1个月是1.0-1.5,第2个月在1.5-2.0之间,,第3个月在2.0-2.5,第4个月在2.5-3.0之间
于是我想,是否可以用Python自动按照比例在指定的Word单元格里输入1,2,3数字,并计算个数和平均值。。
经过三天实验,终于作出了一份
素材准备:

word第一页是评估表、第二页是参考目标,第三页是分页符生成的一个空行回车

代码展示
# -*- coding: utf-8 -*-
'''
目的:自动生成2-6月幼儿能力评估的打分(按比例生成) 1-12 13-14
工具:星火讯飞,阿夏
时间:2024年6月22日
'''
import os
import random
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt
from docx.enum.text import WD_UNDERLINE
date=['2、3','4','5','6']
# 抽取比例比如1抽取60%,2抽取40%、3抽取0%
bl=[[60,40,0],[40,50,10],[20,60,20],[0,20,80]]
wz=['孩子们大部分思维活跃,因此在区角活动中明显发现与动手操作活动中的活跃气氛相比,幼儿对于安静的活动(扣扣子、夹豆子、阅读)等兴趣不高,主动参与图书阅读活动的幼儿不多,很多幼儿快速翻完书本后就使用书作为道具开展其他动作游戏的道具,对于画面的解读能力偏弱,会对幼儿的逻辑思维、语言表达能力产生不利影响。因此我们以“小青蛙故事比赛”为契机,家园合作引导幼儿进行书本阅读和看图编故事的活动。孩子们都愿意通过阅读,结合动作、语言、歌曲进行表演活动,我们将继续引导幼儿开展相关阅读表演活动。',
'本月我们通过《周围的人》《幼儿园里朋友多》等主题引导孩子认识社会,在社会实践、家园共育、教育教学等活动下,孩子们逐渐积累关于周围各种不同职业的人的特点和相关信息,提高孩子对成人职业的认识。让幼儿了解社会成员的工作与我们的关系,并尊重他们的劳动。关心、热爱、尊重周围的人们。本月幼儿对自主午餐活动非常兴趣,他们尝试自己取碗筷、盛饭盛菜,这些都让孩子们感到很新奇。“老师你看我把自己盛的饭菜都吃光了!”自主午餐对中班孩子来说是非常有利的。',
'部分孩子在与同伴交往过程中产生了矛盾冲突,产生了愤怒、暴躁、倾诉等行为;部分孩子的情绪容易兴奋,难以迅速平静下来;部分孩子在因为他人的评价而产生自卑感……中班幼儿期是情绪发展最迅速和最关键的时期,面对全体幼儿不同的情绪问题,本学期我们将使用paths情绪课程来引导幼儿建立正确的情绪自我评价意识。本月引导幼儿正确认识正面和负面情绪,接受自己的情绪变化,并在情景中感知面对自己的各种情绪该如何处理才最恰当。很多孩子通过经验回忆,描述了自己对生气、愤怒、狂笑等情绪的体验,通过讨论梳理出一些应对方法。',
'本月对孩子们发展目标进行了观察和统计,除了一些长期病假的孩子以外,其他的孩子的数值都在原有基础有所提高,特别是阅读兴趣、情绪管理、自我服务的能力有了明显的提升,孩子们对于在人际关系中常见的“和朋友吵架了怎么办?”有了许多自己独特的解决方法。同时也发现个别特殊儿童的生活自理(自主午餐、自我服务)、手脑协调、语言表达能力都有明显的提高。下学期,我们将在关注幼儿集体发展的基础上,继续关注个别幼儿的发展情况,帮助幼儿个性化成长。'
]
print(len(wz))
# path=r'C:\Users\jg2yXRZ\OneDrive\桌面\月评估'
for num in range(5):
for x in range(len(bl)):
# 缺的学号
q=[1,7]
# 评价条数 确保表格有足够多的行数
bs=['0315','1516'] # 2-14列
# 人数,确保表格有足够多的行数
r=31
# b=[]
def delete_numbers(table, row_start, col_start, col_end):
for cell in table.rows[row_start - 1].cells[col_start - 1:col_end]:
cell.text = ""
def fill_random_numbers(table, row_start, row_end, col_start, col_end):
for row in table.rows[row_start - 1:row_end]:
for cell in row.cells[col_start - 1:col_end]:
cell.text = str(random.choices([1, 2,3], weights=[bl[x][0],bl[x][1],bl[x][2]], k=1)[0])
paragraph = cell.paragraphs[0]
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
def count_ones(table, row_start, col_start, row_end):
count = 0
for row in table.rows[row_start - 1:row_end]:
cell = row.cells[col_start - 1]
if cell.text == "1":
count += 1
return count
def count_twos(table, row_start, col_start, row_end):
count = 0
for row in table.rows[row_start - 1:row_end]:
cell = row.cells[col_start - 1]
if cell.text == "2":
count += 1
return count
def count_threes(table, row_start, col_start, row_end):
count = 0
for row in table.rows[row_start - 1:row_end]:
cell = row.cells[col_start - 1]
if cell.text == "3":
count += 1
return count
def calculate_average(table, row_start, col_start, row_end):
total = 0
count = 0
for row in table.rows[row_start - 1:row_end]:
cell = row.cells[col_start - 1]
if cell.text != "":
total += float(cell.text) # 将文本转换为浮点数进行计算
count += 1
else:
pass
return round(total / count, 1)
def calculate_average(table, row_start, col_start, row_end, clear_cells=False):
total = 0
count = 0
for row in table.rows[row_start - 1:row_end]:
cell = row.cells[col_start - 1]
if cell.text != "":
total += float(cell.text) # 将文本转换为浮点数进行计算
count += 1
else:
pass
average = round(total / count, 1)
total=0
count=0
return average
def main():
import time
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\月评估'
input_file = path+r"\模板 月评估.docx"
new_folder=path+r'\零时文件夹'
os.makedirs(new_folder, exist_ok=True)
output_file=new_folder+fr"\{x}.docx"
# 读取输入文件
doc = Document(input_file)
# 获取第一个表格
table = doc.tables[0]
# 插入文字
# 在指定的单元格(23,0)里插入文字
cell = table.cell(r+6-1, 2) # 注意索引从0开始,所以需要减1
# 在单元格中写入文字
cell.text =' '+wz[x]
# 获取第二段 插入月份
paragraph = doc.paragraphs[1]
# 在段落中添加文本和下划线
run1 = paragraph.add_run(" "+date[x]+" ")
run1.font.underline = WD_UNDERLINE.SINGLE
run2 = paragraph.add_run(" 月 ")
run3 = paragraph.add_run(" 中(4) ")
run3.font.underline = WD_UNDERLINE.SINGLE
run4 = paragraph.add_run("班")
for b in bs:
b1=int(b[0:2])
b2=int(b[2:4])
# paragraph.text = new_text
# 单元格(table, 第2行, 第32行, 第10列, 第14列)
# 填充随机数字
fill_random_numbers(table, 2, r+1, b1, b2)
# 删除第一行中第2格子到第17格子里面的数字
for qq in q:
delete_numbers(table, qq+1, 2, b2+1)
# 计算个数
# 遍历每一列,统计数字1的个数并填入对应的单元格
for col in range(b1, b2+1):
total_ones = count_threes(table, 2, col, r+2)
cell = table.cell(r+2-1, col-1)
cell.text = str(total_ones)
paragraph = cell.paragraphs[0]
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 遍历每一列,统计数字1的个数并填入对应的单元格
for col in range(b1, b2+1):
total_ones = count_twos(table, 2, col, r+3)
cell = table.cell(r+3-1, col-1)
cell.text = str(total_ones)
paragraph = cell.paragraphs[0]
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 遍历每一列,统计数字1的个数并填入对应的单元格
for col in range(b1, b2+1):
total_ones = count_ones(table, 2, col, r+4)
cell = table.cell(r+4-1, col-1)
cell.text = str(total_ones)
paragraph = cell.paragraphs[0]
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 计算平均值
# 在 main() 函数中添加以下代码:
for col in range(b1, b2+1):
# 计算指定范围内单元格的平均值
average = calculate_average(table, 2, col, r-1)
# 获取要写入平均值的单元格
cell = table.cell(r+5-1, col-1)
# 将平均值转换为字符串并写入单元格
cell.text = str(average)
# 获取单元格中的段落对象
paragraph = cell.paragraphs[0]
# 设置段落居中对齐
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 保存为新文件
doc.save(output_file)
if __name__ == "__main__":
main()
print('---4、合并文档--')
import os,time
import shutil
from docx import Document
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\月评估'
new_folder=path+r'\零时文件夹'
os.makedirs(new_folder,exist_ok=True)
output_file = path+fr"\{num:02d}中4班 月评估(202402-202406).docx"
output_doc = Document(new_folder+r'\0.docx')
files = os.listdir(new_folder)
for index, file in enumerate(files):
if file.endswith(".docx") and index != 0:
input_file = os.path.join(new_folder, file)
input_doc = Document(input_file)
# output_doc.add_page_break() # 添加换页符
for element in input_doc.element.body:
output_doc.element.body.append(element)
# 获取文档的段落数量 删除最后一段
num_paragraphs = len(output_doc.paragraphs)
if num_paragraphs > 0:
output_doc.paragraphs[num_paragraphs - 1]._element.getparent().remove(output_doc.paragraphs[num_paragraphs - 1]._element)
time.sleep(2)
output_doc.save(output_file)
我对4个月的数据,进行比例抽取(1-12列、13-14列分别抽取)

结果发现第1个月和最后一个月里,13-14列的平均值并没有比1-12的平均值小。所以我生成了5份。从里面找了一份相对适合的。

这份月评估生成时间很长很长,一份就可以生成5分钟。
最后只找出第5份的平均数相对符合要求