4、listener可以通过 store.getState() 得到当前状态。如果使用的是 React,这时可以触发重新渲染 View。
function listerner() {
let newState = store.getState();
component.setState(newState);
}
对比 Flux
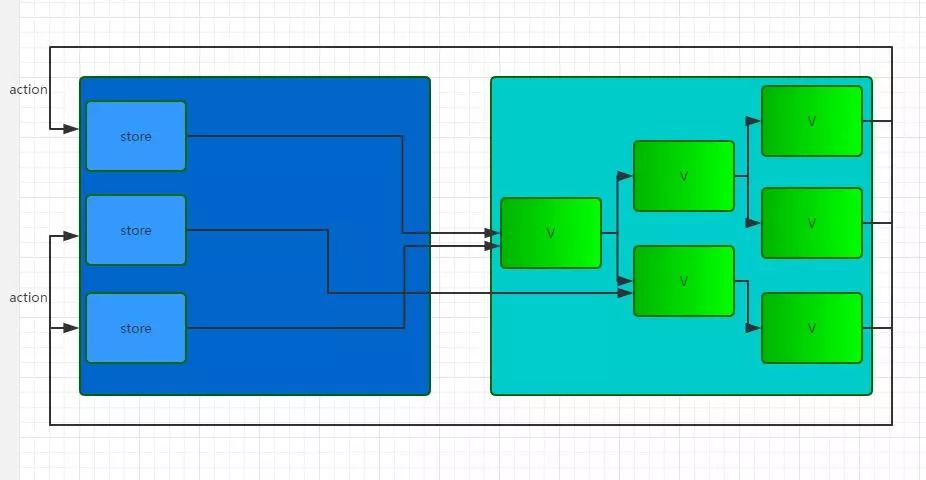
和 Flux 比较一下:Flux 中 Store 是各自为战的,每个 Store 只对对应的 View 负责,每次更新都只通知对应的View:
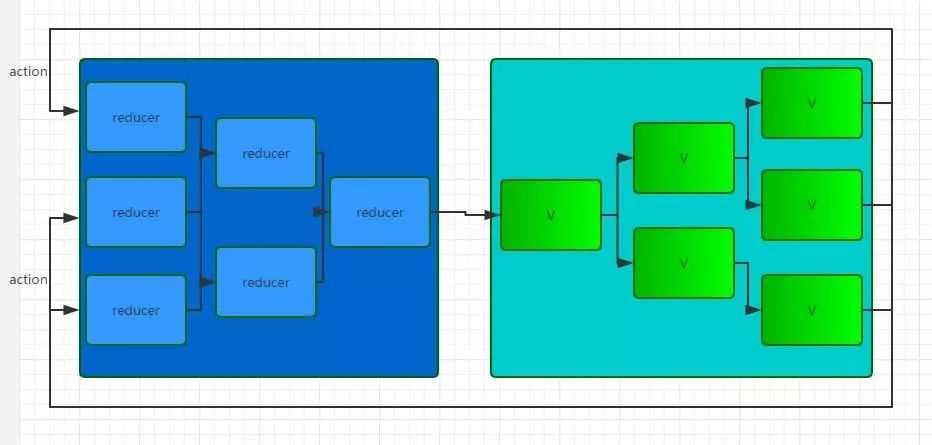
Redux 中各子 Reducer 都是由根 Reducer 统一管理的,每个子 Reducer 的变化都要经过根 Reducer 的整合:
简单来说,Redux有三大原则:单一数据源:Flux 的数据源可以是多个。State 是只读的:Flux 的 State 可以随便改。* 使用纯函数来执行修改:Flux 执行修改的不一定是纯函数。
Redux 和 Flux 一样都是单向数据流。
中间件
刚才说到的都是比较理想的同步状态。在实际项目中,一般都会有同步和异步操作,所以 Flux、Redux 之类的思想,最终都要落地到同步异步的处理中来。
在 Redux 中,同步的表现就是:Action 发出以后,Reducer 立即算出 State。那么异步的表现就是:Action 发出以后,过一段时间再执行 Reducer。
那怎么才能 Reducer 在异步操作结束后自动执行呢?Redux 引入了中间件 Middleware 的概念。
其实我们重新回顾一下刚才的流程,可以发现每一个步骤都很纯粹,都不太适合加入异步的操作,比如 Reducer,纯函数,肯定不能承担异步操作,那样会被外部IO干扰。Action呢,就是一个纯对象,放不了操作。那想来想去,只能在 View 里发送 Action 的时候,加上一些异步操作了。比如下面的代码,给原来的 dispatch 方法包裹了一层,加上了一些日志打印的功能:
let next = store.dispatch;
store.dispatch = function dispatchAndLog(action) {
console.log(‘dispatching’, action);
next(action);
console.log(‘next state’, store.getState());}
既然能加日志打印,当然也能加入异步操作。所以中间件简单来说,就是对 store.dispatch 方法进行一些改造的函数。不展开说了,所以如果想详细了解中间件,可以点这里。
Redux 提供了一个 applyMiddleware 方法来应用中间件:
const store = createStore(
reducer,
applyMiddleware(thunk, promise, logger));
这个方法主要就是把所有的中间件组成一个数组,依次执行。也就是说,任何被发送到 store 的 action 现在都会经过thunk,promise,logger 这几个中间件了。
处理异步
对于异步操作来说,有两个非常关键的时刻:发起请求的时刻,和接收到响应的时刻(可能成功,也可能失败或者超时),这两个时刻都可能会更改应用的 state。一般是这样一个过程:
请求开始时,dispatch 一个请求开始 Action,触发 State 更新为“正在请求”状态,View 重新渲染,比如展现个Loading啥的。
请求结束后,如果成功,dispatch 一个请求成功 Action,隐藏掉 Loading,把新的数据更新到 State;如果失败,dispatch 一个请求失败 Action,隐藏掉 Loading,给个失败提示。
显然,用 Redux 处理异步,可以自己写中间件来处理,当然大多数人会选择一些现成的支持异步处理的中间件。比如 redux-thunk 或 redux-promise 。
Redux-thunk
thunk 比较简单,没有做太多的封装,把大部分自主权交给了用户:
const createFetchDataAction = function(id) {
return function(dispatch, getState) {
// 开始请求,dispatch 一个 FETCH_DATA_START action
dispatch({
type: FETCH_DATA_START,
payload: id
})
api.fetchData(id)
.then(response => {
// 请求成功,dispatch 一个 FETCH_DATA_SUCCESS action
dispatch({
type: FETCH_DATA_SUCCESS,
payload: response
})
})
.catch(error => {
// 请求失败,dispatch 一个 FETCH_DATA_FAILED action
dispatch({
type: FETCH_DATA_FAILED,
payload: error
})
})
}}//reducerconst reducer = function(oldState, action) {
switch(action.type) {
case FETCH_DATA_START :
// 处理 loading 等
case FETCH_DATA_SUCCESS :
// 更新 store 等
case FETCH_DATA_FAILED :
// 提示异常
}}
缺点就是用户要写的代码有点多,可以看到上面的代码比较啰嗦,一个请求就要搞这么一套东西。
Redux-promise
redus-promise 和 redux-thunk 的思想类似,只不过做了一些简化,成功失败手动 dispatch 被封装成自动了:
const FETCH_DATA = ‘FETCH_DATA’//action creatorconst getData = function(id) {
return {
type: FETCH_DATA,
payload: api.fetchData(id) // 直接将 promise 作为 payload
}}//reducerconst reducer = function(oldState, action) {
switch(action.type) {
case FETCH_DATA:
if (action.status === ‘success’) {
// 更新 store 等处理
} else {
// 提示异常
}
}}
刚才的什么 then、catch 之类的被中间件自行处理了,代码简单不少,不过要处理 Loading 啥的,还需要写额外的代码。
其实任何时候都是这样:封装少,自由度高,但是代码就会变复杂;封装多,代码变简单了,但是自由度就会变差。redux-thunk 和 redux-promise 刚好就是代表这两个面。
redux-thunk 和 redux-promise 的具体使用就不介绍了,这里只聊一下大概的思路。大部分简单的异步业务场景,redux-thunk 或者 redux-promise 都可以满足了。
上面说的 Flux 和 Redux,和具体的前端框架没有什么关系,只是思想和约定层面。下面就要和我们常用的 Vue 或 React 结合起来了:
Vuex
Vuex 主要用于 Vue,和 Flux,Redux 的思想很类似。
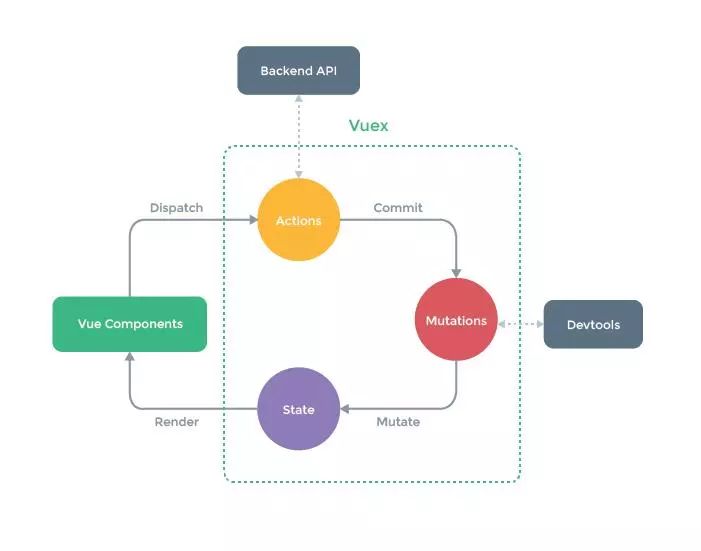
Store
每一个 Vuex 里面有一个全局的 Store,包含着应用中的状态 State,这个 State 只是需要在组件中共享的数据,不用放所有的 State,没必要。这个 State 是单一的,和 Redux 类似,所以,一个应用仅会包含一个 Store 实例。单一状态树的好处是能够直接地定位任一特定的状态片段,在调试的过程中也能轻易地取得整个当前应用状态的快照。
Vuex通过 store 选项,把 state 注入到了整个应用中,这样子组件能通过 this.\$store 访问到 state 了。
const app = new Vue({
el: ‘#app’,
// 把 store 对象提供给 “store” 选项,这可以把 store 的实例注入所有的子组件
store,
components: { Counter },
template: `
`})const Counter = {
template: <div>{{ count }}</div>,
computed: {
count () {
return this.$store.state.count
}
}}
State 改变,View 就会跟着改变,这个改变利用的是 Vue 的响应式机制。
Mutation
显而易见,State 不能直接改,需要通过一个约定的方式,这个方式在 Vuex 里面叫做 mutation,更改 Vuex 的 store 中的状态的唯一方法是提交 mutation。Vuex 中的 mutation 非常类似于事件:每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。
const store = new Vuex.Store({
state: {
count: 1
},
mutations: {
increment (state) {
// 变更状态
state.count++
}
}})
触发 mutation 事件的方式不是直接调用,比如 increment(state) 是不行的,而要通过 store.commit 方法:
store.commit(‘increment’)
注意:mutation 都是同步事务。
mutation 有些类似 Redux 的 Reducer,但是 Vuex 不要求每次都搞一个新的 State,可以直接修改 State,这块儿又和 Flux 有些类似。具尤大的说法,Redux 强制的 immutability,在保证了每一次状态变化都能追踪的情况下强制的 immutability 带来的收益很有限,为了同构而设计的 API 很繁琐,必须依赖第三方库才能相对高效率地获得状态树的局部状态,这些都是 Redux 不足的地方,所以也被 Vuex 舍掉了。
到这里,其实可以感觉到 Flux、Redux、Vuex 三个的思想都差不多,在具体细节上有一些差异,总的来说都是让 View 通过某种方式触发 Store 的事件或方法,Store 的事件或方法对 State 进行修改或返回一个新的 State,State 改变之后,View 发生响应式改变。
Action
到这里又该处理异步这块儿了。mutation 是必须同步的,这个很好理解,和之前的 reducer 类似,不同步修改的话,会很难调试,不知道改变什么时候发生,也很难确定先后顺序,A、B两个 mutation,调用顺序可能是 A -> B,但是最终改变 State 的结果可能是 B -> A。
对比Redux的中间件,Vuex 加入了 Action 这个东西来处理异步,Vuex的想法是把同步和异步拆分开,异步操作想咋搞咋搞,但是不要干扰了同步操作。View 通过 store.dispatch(‘increment’) 来触发某个 Action,Action 里面不管执行多少异步操作,完事之后都通过 store.commit(‘increment’) 来触发 mutation,一个 Action 里面可以触发多个 mutation。所以 Vuex 的Action 类似于一个灵活好用的中间件。
Vuex 把同步和异步操作通过 mutation 和 Action 来分开处理,是一种方式。但不代表是唯一的方式,还有很多方式,比如就不用 Action,而是在应用内部调用异步请求,请求完毕直接 commit mutation,当然也可以。
Vuex 还引入了 Getter,这个可有可无,只不过是方便计算属性的复用。
Vuex 单一状态树并不影响模块化,把 State 拆了,最后组合在一起就行。Vuex 引入了 Module 的概念,每个 Module 有自己的 state、mutation、action、getter,其实就是把一个大的 Store 拆开。
总的来看,Vuex 的方式比较清晰,适合 Vue 的思想,在实际开发中也比较方便。
对比Redux
Redux:view——>actions——>reducer——>state变化——>view变化(同步异步一样)
Vuex:view——>commit——>mutations——>state变化——>view变化(同步操作) view——>dispatch——>actions——>mutations——>state变化——>view变化(异步操作)
React-redux
Redux 和 Flux 类似,只是一种思想或者规范,它和 React 之间没有关系。Redux 支持 React、Angular、Ember、jQuery 甚至纯 JavaScript。
但是因为 React 包含函数式的思想,也是单向数据流,和 Redux 很搭,所以一般都用 Redux 来进行状态管理。为了简单处理 Redux 和 React UI 的绑定,一般通过一个叫 react-redux 的库和 React 配合使用,这个是 react 官方出的(如果不用 react-redux,那么手动处理 Redux 和 UI 的绑定,需要写很多重复的代码,很容易出错,而且有很多 UI 渲染逻辑的优化不一定能处理好)。
Redux将React组件分为容器型组件和展示型组件,容器型组件一般通过connect函数生成,它订阅了全局状态的变化,通过mapStateToProps函数,可以对全局状态进行过滤,而展示型组件不直接从global state获取数据,其数据来源于父组件。
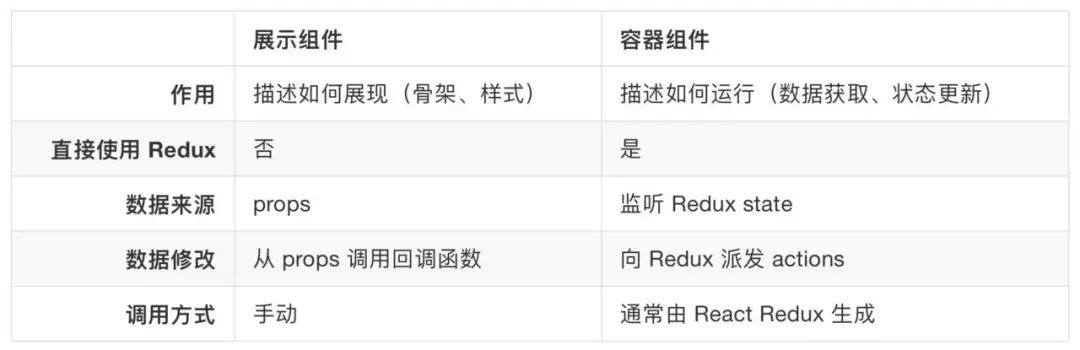
如果一个组件既需要UI呈现,又需要业务逻辑处理,那就得拆,拆成一个容器组件包着一个展示组件。
因为 react-redux 只是 redux 和 react 结合的一种实现,除了刚才说的组件拆分,并没有什么新奇的东西,所以只拿一个简单TODO项目的部分代码来举例:
入口文件 index.js,把 redux 的相关 store、reducer 通过 Provider 注册到 App 里面,这样子组件就可以拿到 store 了。
import React from 'react’import { render } from 'react-dom’import { Provider } from 'react-redux’import { createStore } from 'redux’import rootReducer from './reducers’import App from './components/App’const store = createStore(rootReducer)
render(
,
document.getElementById(‘root’))
actions/index.js,创建 Action:
let nextTodoId = 0export const addTodo = text => ({
type: ‘ADD_TODO’,
id: nextTodoId++,
text})export const setVisibilityFilter = filter => ({
type: ‘SET_VISIBILITY_FILTER’,
filter})export const toggleTodo = id => ({
type: ‘TOGGLE_TODO’,
id})export const VisibilityFilters = {
SHOW_ALL: ‘SHOW_ALL’,
SHOW_COMPLETED: ‘SHOW_COMPLETED’,
SHOW_ACTIVE: ‘SHOW_ACTIVE’}
reducers/todos.js,创建 Reducers:
const todos = (state = [], action) => {
switch (action.type) {
case ‘ADD_TODO’:
return [
…state,
{
id: action.id,
text: action.text,
completed: false
}
]
case ‘TOGGLE_TODO’:
return state.map(todo =>
todo.id === action.id ? { …todo, completed: !todo.completed } : todo
)
default:
return state
}}export default todos
reducers/index.js,把所有的 Reducers 绑定到一起:
import { combineReducers } from 'redux’import todos from './todos’import visibilityFilter from './visibilityFilter’export default combineReducers({
todos,
visibilityFilter,
…})
containers/VisibleTodoList.js,容器组件,connect 负责连接React组件和Redux Store:
import { connect } from 'react-redux’import { toggleTodo } from '…/actions’import TodoList from '…/components/TodoList’const getVisibleTodos = (todos, filter) => {
switch (filter) {
case ‘SHOW_COMPLETED’:
return todos.filter(t => t.completed)
case ‘SHOW_ACTIVE’:
return todos.filter(t => !t.completed)
case ‘SHOW_ALL’:
default:
return todos
}}// mapStateToProps 函数指定如何把当前 Redux store state 映射到展示组件的 props 中const mapStateToProps = state => ({
todos: getVisibleTodos(state.todos, state.visibilityFilter)})// mapDispatchToProps 方法接收 dispatch() 方法并返回期望注入到展示组件的 props 中的回调方法。const mapDispatchToProps = dispatch => ({
toggleTodo: id => dispatch(toggleTodo(id))})export default connect(
mapStateToProps,
mapDispatchToProps)(TodoList)
简单来说,react-redux 就是多了个 connect 方法连接容器组件和UI组件,这里的“连接”就是一种映射:mapStateToProps 把容器组件的 state 映射到UI组件的 props mapDispatchToProps 把UI组件的事件映射到 dispatch 方法
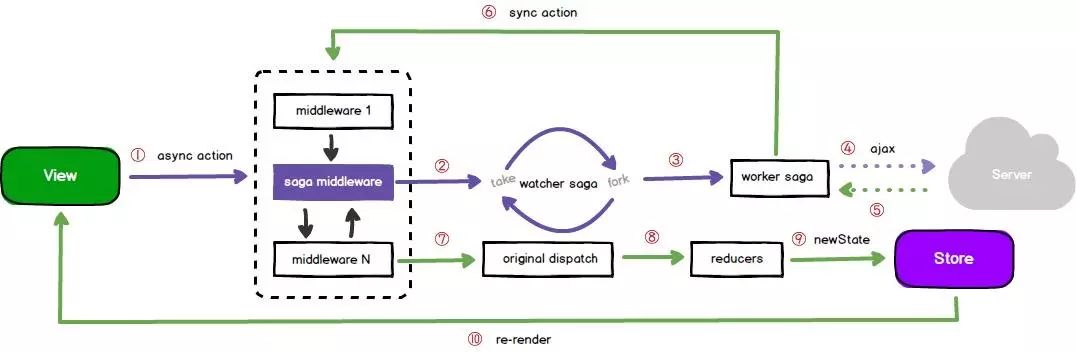
Redux-saga
刚才介绍了两个Redux 处理异步的中间件 redux-thunk 和 redux-promise,当然 redux 的异步中间件还有很多,他们可以处理大部分场景,这些中间件的思想基本上都是把异步请求部分放在了 action creator 中,理解起来比较简单。
redux-saga 采用了另外一种思路,它没有把异步操作放在 action creator 中,也没有去处理 reductor,而是把所有的异步操作看成“线程”,可以通过普通的action去触发它,当操作完成时也会触发action作为输出。saga 的意思本来就是一连串的事件。
redux-saga 把异步获取数据这类的操作都叫做副作用(Side Effect),它的目标就是把这些副作用管理好,让他们执行更高效,测试更简单,在处理故障时更容易。
在聊 redux-saga 之前,需要熟悉一些预备知识,那就是 ES6 的 Generator。
如果从没接触过 Generator 的话,看着下面的代码,给你个1分钟傻瓜式速成,函数加个星号就是 Generator 函数了,Generator 就是个骂街生成器,Generator 函数里可以写一堆 yield 关键字,可以记成“丫的”,Generator 函数执行的时候,啥都不干,就等着调用 next 方法,按照顺序把标记为“丫的”的地方一个一个拎出来骂(遍历执行),骂到最后没有“丫的”标记了,就返回最后的return值,然后标记为 done: true,也就是骂完了(上面只是帮助初学者记忆,别喷~)。
function* helloWorldGenerator() {
yield ‘hello’;
yield ‘world’;
return ‘ending’;}var hw = helloWorldGenerator();
hw.next() // 先把 ‘hello’ 拎出来,done: false 代表还没骂完// { value: ‘hello’, done: false } next() 方法有固定的格式,value 是返回值,done 代表是否遍历结束
hw.next() // 再把 ‘world’ 拎出来,done: false 代表还没骂完// { value: ‘world’, done: false }
hw.next() // 没有 yield 了,就把最后的 return ‘ending’ 拎出来,done: true 代表骂完了// { value: ‘ending’, done: true }
hw.next() // 没有 yield,也没有 return 了,真的骂完了,只能挤出来一个 undefined 了,done: true 代表骂完了// { value: undefined, done: true }
这样搞有啥好处呢?我们发现 Generator 函数的很多代码可以被延缓执行,也就是具备了暂停和记忆的功能:遇到yield表达式,就暂停执行后面的操作,并将紧跟在yield后面的那个表达式的值,作为返回的对象的value属性值,等着下一次调用next方法时,再继续往下执行。用 Generator 来写异步代码,大概长这样:
function* gen(){
var url = ‘https://api.github.com/users/github’;
var jsonData = yield fetch(url);
console.log(jsonData);}var g = gen();var result = g.next();
// 这里的result是 { value: fetch(‘https://api.github.com/users/github’), done: true }// fetch(url) 是一个 Promise,所以需要 then 来执行下一步
result.value.then(function(data){
return data.json();}).then(function(data){
// 获取到 json data,然后作为参数调用 next,相当于把 data 传给了 jsonData,然后执行 console.log(jsonData);
g.next(data);});
再回到 redux-saga 来,可以把 saga 想象成开了一个以最快速度不断地调用 next 方法并尝试获取所有 yield 表达式值的线程。举个例子:
// saga.jsimport { take, put } from 'redux-saga/effects’function* mySaga(){
// 阻塞: take方法就是等待 USER_INTERACTED_WITH_UI_ACTION 这个 action 执行
yield take(USER_INTERACTED_WITH_UI_ACTION);
// 阻塞: put方法将同步发起一个 action
yield put(SHOW_LOADING_ACTION, {isLoading: true});
// 阻塞: 将等待 FetchFn 结束,等待返回的 Promise
const data = yield call(FetchFn, ‘https://my.server.com/getdata’);
// 阻塞: 将同步发起 action (使用刚才返回的 Promise.then)
yield put(SHOW_DATA_ACTION, {data: data});}
这里用了好几个yield,简单理解,也就是每个 yield 都发起了阻塞,saga 会等待执行结果返回,再执行下一指令。也就是相当于take、put、call、put 这几个方法的调用变成了同步的,上面的全部完成返回了,才会执行下面的,类似于 await。
用了 saga,我们就可以很细粒度的控制各个副作用每一部的操作,可以把异步操作和同步发起 action 一起,随便的排列组合。saga 还提供 takeEvery、takeLatest 之类的辅助函数,来控制是否允许多个异步请求同时执行,尤其是 takeLatest,方便处理由于网络延迟造成的多次请求数据冲突或混乱的问题。
saga 看起来很复杂,主要原因可能是因为大家不熟悉 Generator 的语法,还有需要学习一堆新增的 API 。如果抛开这些记忆的东西,改造一下,再来看一下代码:
function mySaga(){
if (action.type === ‘USER_INTERACTED_WITH_UI_ACTION’) {
store.dispatch({ type: ‘SHOW_LOADING_ACTION’, isLoading: true});
const data = await Fetch(‘https://my.server.com/getdata’);
store.dispatch({ type: ‘SHOW_DATA_ACTION’, data: data});
}}
上面的代码就很清晰了吧,全部都是同步的写法,无比顺畅,当然直接这样写是不支持的,所以那些 Generator 语法和API,无非就是做一些适配而已。
saga 还能很方便的并行执行异步任务,或者让两个异步任务竞争:
// 并行执行,并等待所有的结果,类似 Promise.all 的行为const [users, repos] = yield [
call(fetch, ‘/users’),
call(fetch, ‘/repos’)]// 并行执行,哪个先完成返回哪个,剩下的就取消掉了const {posts, timeout} = yield race({
posts: call(fetchApi, ‘/posts’),
timeout: call(delay, 1000)})
saga 的每一步都可以做一些断言(assert)之类的,所以非常方便测试。而且很容易测试到不同的分支。
这里不讨论更多 saga 的细节,大家了解 saga 的思想就行,细节请看文档。
对比 Redux-thunk
比较一下 redux-thunk 和 redux-saga 的代码:
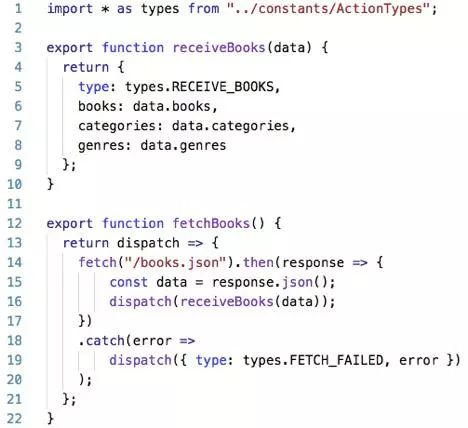
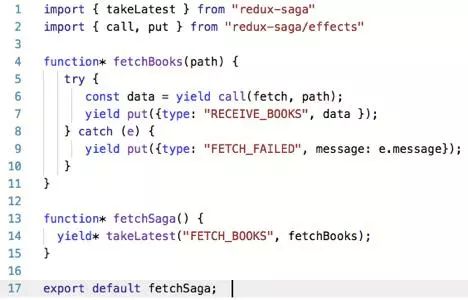
和 redux-thunk 等其他异步中间件对比来说,redux-saga 主要有下面几个特点:异步数据获取的相关业务逻辑放在了单独的 saga.js 中,不再是掺杂在 action.js 或 component.js 中。dispatch 的参数是标准的 action,没有魔法。saga 代码采用类似同步的方式书写,代码变得更易读。代码异常/请求失败 都可以直接通过 try/catch 语法直接捕获处理。* 很容易测试,如果是 thunk 的 Promise,测试的话就需要不停的 mock 不同的数据。
其实 redux-saga 是用一些学习的复杂度,换来了代码的高可维护性,还是很值得在项目中使用的。
Dva
Dva是什么呢?官方的定义是:dva 首先是一个基于 redux 和 redux-saga 的数据流方案,然后为了简化开发体验,dva 还额外内置了 react-router 和 fetch,所以也可以理解为一个轻量级的应用框架。
简单理解,就是让使用 react-redux 和 redux-saga 编写的代码组织起来更合理,维护起来更方便。
之前我们聊了 redux、react-redux、redux-saga 之类的概念,大家肯定觉得头昏脑涨的,什么 action、reducer、saga 之类的,写一个功能要在这些js文件里面不停的切换。
dva 做的事情很简单,就是让这些东西可以写到一起,不用分开来写了。比如:
app.model({
// namespace - 对应 reducer 在 combine 到 rootReducer 时的 key 值
namespace: ‘products’,
// state - 对应 reducer 的 initialState
state: {
list: [],
loading: false,
},
// subscription - 在 dom ready 后执行
subscriptions: [
function(dispatch) {
dispatch({type: ‘products/query’});
},
],
// effects - 对应 saga,并简化了使用
effects: {
[‘products/query’]: function*() {
yield call(delay(800));
yield put({
type: ‘products/query/success’,
payload: [‘ant-tool’, ‘roof’],
});
},
},
// reducers - 就是传统的 reducers
reducers: {
‘products/query’ {
return { …state, loading: true, };
},
[‘products/query/success’](state, { payload }) {
return { …state, loading: false, list: payload };
},
},});
以前书写的方式是创建 sagas/products.js, reducers/products.js 和 actions/products.js,然后把 saga、action、reducer 啥的分开来写,来回切换,现在写在一起就方便多了。
比如传统的 TODO 应用,用 redux + redux-saga 来表示结构,就是这样:

saga 拦截 add 这个 action, 发起 http 请求, 如果请求成功, 则继续向 reducer 发一个 addTodoSuccess 的 action, 提示创建成功, 反之则发送 addTodoFail 的 action 即可。
如果使用 Dva,那么结构图如下:
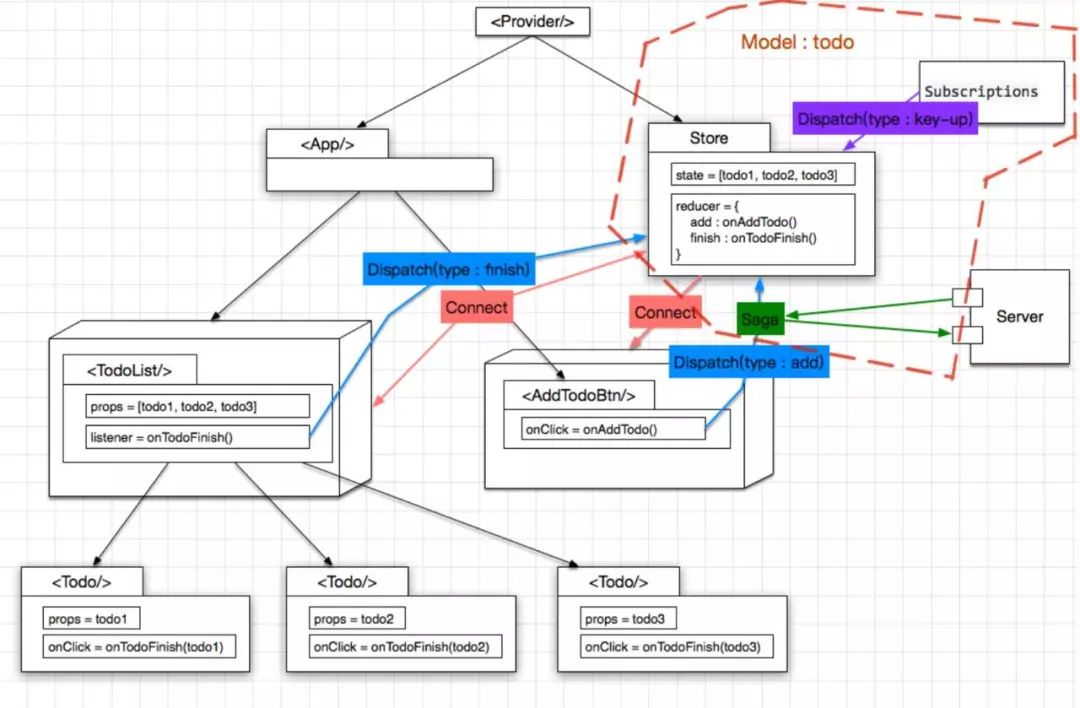
整个结构变化不大,最主要的就是把 store 及 saga 统一为一个 model 的概念(有点类似 Vuex 的 Module),写在了一个 js 文件里。增加了一个 Subscriptions, 用于收集其他来源的 action,比如快捷键操作。
app.model({
namespace: ‘count’,
state: {
record: 0,
current: 0,
},
reducers: {
add(state) {
const newCurrent = state.current + 1;
return { …state,
record: newCurrent > state.record ? newCurrent : state.record,
current: newCurrent,
};
},
minus(state) {
return { …state, current: state.current - 1};
},
},
effects: {
*add(action, { call, put }) {
yield call(delay, 1000);
yield put({ type: ‘minus’ });
},
},
subscriptions: {
keyboardWatcher({ dispatch }) {
key(‘⌘+up, ctrl+up’, () => { dispatch({type:‘add’}) });
},
},});
之前我们说过约定优于配置的思想,Dva正式借鉴了这个思想。
MobX
前面扯了这么多,其实还都是 Flux 体系的,都是单向数据流方案。接下来要说的 MobX,就和他们不太一样了。
我们先清空一下大脑,回到初心,什么是初心?就是我们最初要解决的问题是什么?最初我们其实为了解决应用状态管理的问题,不管是 Redux 还是 MobX,把状态管理好是前提。什么叫把状态管理好,简单来说就是:统一维护公共的应用状态,以统一并且可控的方式更新状态,状态更新后,View跟着更新。不管是什么思想,达成这个目标就ok。
Flux 体系的状态管理方式,只是一个选项,但并不代表是唯一的选项。MobX 就是另一个选项。
MobX背后的哲学很简单:任何源自应用状态的东西都应该自动地获得。译成人话就是状态只要一变,其他用到状态的地方就都跟着自动变。

看这篇文章的人,大概率会对面向对象的思想比较熟悉,而对函数式编程的思想略陌生。Flux 或者说 Redux 的思想主要就是函数式编程(FP)的思想,所以学习起来会觉得累一些。而 MobX 更接近于面向对象编程,它把 state 包装成可观察的对象,这个对象会驱动各种改变。什么是可观察?就是 MobX 老大哥在看着 state 呢。state 只要一改变,所有用到它的地方就都跟着改变了。这样整个 View 可以被 state 来驱动。
const obj = observable({
a: 1,
b: 2})
autoRun(() => {
console.log(obj.a)})
obj.b = 3 // 什么都没有发生
obj.a = 2 // observe 函数的回调触发了,控制台输出:2
上面的obj,他的 obj.a 属性被使用了,那么只要 obj.a 属性一变,所有使用的地方都会被调用。autoRun 就是这个老大哥,他看着所有依赖 obj.a 的地方,也就是收集所有对 obj.a 的依赖。当 obj.a 改变时,老大哥就会触发所有依赖去更新。
MobX 允许有多个 store,而且这些 store 里的 state 可以直接修改,不用像 Redux 那样每次还返回个新的。这个有点像 Vuex,自由度更高,写的代码更少。不过它也会让代码不好维护。
MobX 和 Flux、Redux 一样,都是和具体的前端框架无关的,也就是说可以用于 React(mobx-react) 或者 Vue(mobx-vue)。一般来说,用到 React 比较常见,很少用于 Vue,因为 Vuex 本身就类似 MobX,很灵活。如果我们把 MobX 用于 React 或者 Vue,可以看到很多 setState() 和 http://this.state.xxx = 这样的处理都可以省了。
还是和上面一样,只介绍思想。具体 MobX 的使用,可以看这里。
对比 Redux
我们直观地上两坨实现计数器代码:
基础学习:
前端最基础的就是 HTML , CSS 和 JavaScript 。
网页设计:HTML和CSS基础知识的学习
HTML是网页内容的载体。内容就是网页制作者放在页面上想要让用户浏览的信息,可以包含文字、图片、视频等。

CSS样式是表现。就像网页的外衣。比如,标题字体、颜色变化,或为标题加入背景图片、边框等。所有这些用来改变内容外观的东西称之为表现。

动态交互:JavaScript基础的学习
JavaScript是用来实现网页上的特效效果。如:鼠标滑过弹出下拉菜单。或鼠标滑过表格的背景颜色改变。还有焦点新闻(新闻图片)的轮换。可以这么理解,有动画的,有交互的一般都是用JavaScript来实现的。
e.log(obj.a)})
obj.b = 3 // 什么都没有发生
obj.a = 2 // observe 函数的回调触发了,控制台输出:2
上面的obj,他的 obj.a 属性被使用了,那么只要 obj.a 属性一变,所有使用的地方都会被调用。autoRun 就是这个老大哥,他看着所有依赖 obj.a 的地方,也就是收集所有对 obj.a 的依赖。当 obj.a 改变时,老大哥就会触发所有依赖去更新。
MobX 允许有多个 store,而且这些 store 里的 state 可以直接修改,不用像 Redux 那样每次还返回个新的。这个有点像 Vuex,自由度更高,写的代码更少。不过它也会让代码不好维护。
MobX 和 Flux、Redux 一样,都是和具体的前端框架无关的,也就是说可以用于 React(mobx-react) 或者 Vue(mobx-vue)。一般来说,用到 React 比较常见,很少用于 Vue,因为 Vuex 本身就类似 MobX,很灵活。如果我们把 MobX 用于 React 或者 Vue,可以看到很多 setState() 和 http://this.state.xxx = 这样的处理都可以省了。
还是和上面一样,只介绍思想。具体 MobX 的使用,可以看这里。
对比 Redux
我们直观地上两坨实现计数器代码:
基础学习:
前端最基础的就是 HTML , CSS 和 JavaScript 。
网页设计:HTML和CSS基础知识的学习
HTML是网页内容的载体。内容就是网页制作者放在页面上想要让用户浏览的信息,可以包含文字、图片、视频等。
[外链图片转存中…(img-KpPet6p5-1719238503886)]
CSS样式是表现。就像网页的外衣。比如,标题字体、颜色变化,或为标题加入背景图片、边框等。所有这些用来改变内容外观的东西称之为表现。
[外链图片转存中…(img-JdbdPxoQ-1719238503886)]
动态交互:JavaScript基础的学习
JavaScript是用来实现网页上的特效效果。如:鼠标滑过弹出下拉菜单。或鼠标滑过表格的背景颜色改变。还有焦点新闻(新闻图片)的轮换。可以这么理解,有动画的,有交互的一般都是用JavaScript来实现的。