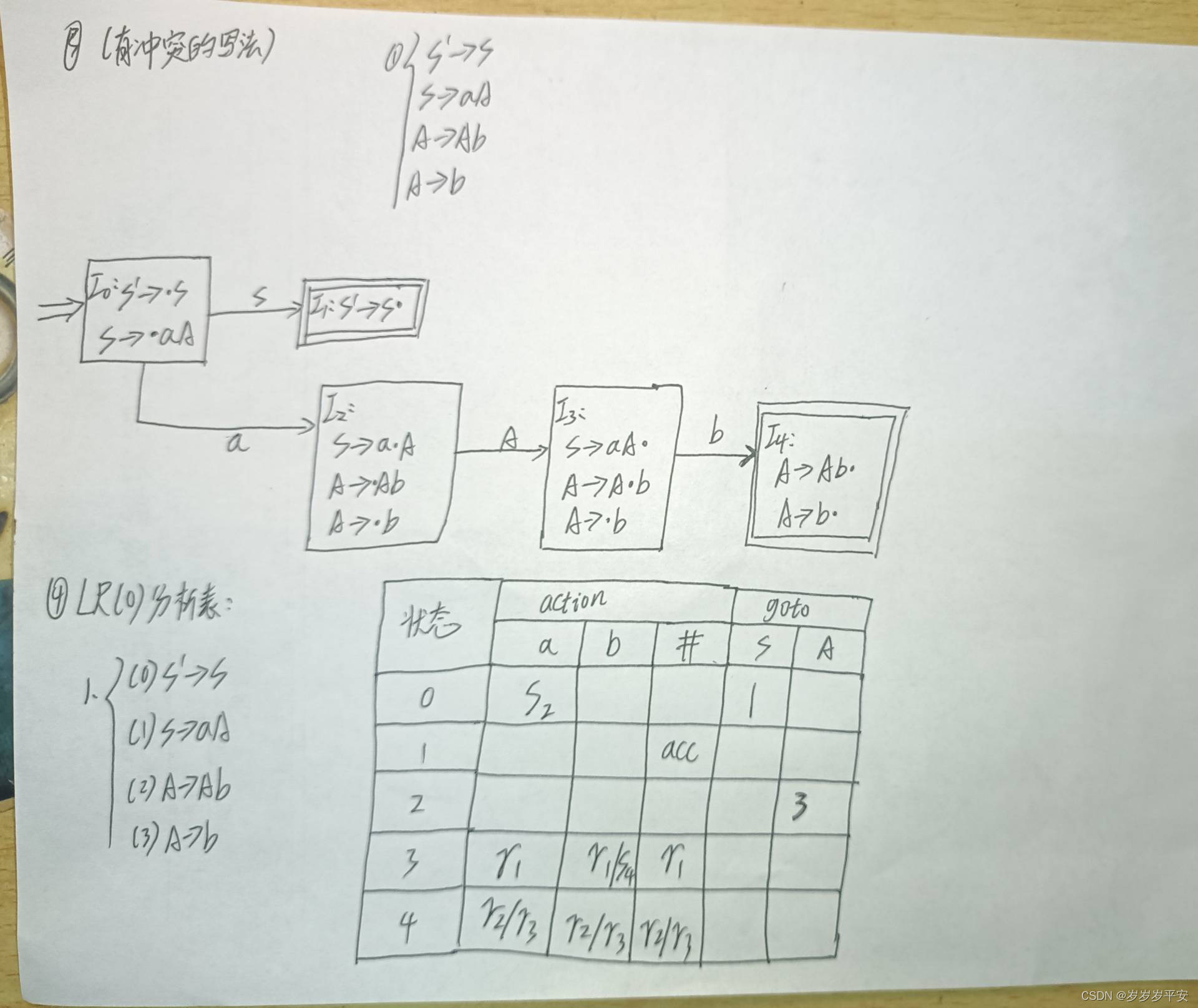
Pytorch
- 一、训练模型
- 1.导入资源包
- 2.定义数据预处理
- 3.读取数据
- 二、定义卷积神经网络
- 1.导入必要的库
- 2.定义名为convolutional_block的卷积块类
- 3.定义了一个名为identity_block的恒等块类
- 4.定义了一个名为Resnet的深度卷积神经网络类
- 三、创建模型
- 1. 检查GPU设备
- 2. 训练过程
- 四、训练模型
- 1. 设置模型为训练模式
- 2.定义实验过程
- 3.增加学习率调度器
- 六、测试模型
- 1.导入资源包
- 2.定义数据预处理
- 定义数据预处理
- 3.自定义Resnet50模型
- 4.实例化 Resnet50 类
一、训练模型
1.导入资源包
import torch.optim as optim: 导入PyTorch的优化工具包,其中包括了各种优化算法,如SGD、Adam等。
import torchvision.transforms as transforms: 导入PyTorch的视觉变换工具包,用于对图像进行预处理和变换,如调整大小、裁剪、归一化等。
from torchvision import models: 从torchvision模块中导入预训练的模型,如ResNet、AlexNet、VGG等。
from sched import scheduler
import torch.optim as optim
import torch
import torch.nn as nn
import torch.utils.data
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torch.optim.lr_scheduler as lr_scheduler
import os
from torchvision import models
2.定义数据预处理
这些预处理操作的目的是为了增强模型的泛化能力,并确保模型在训练和验证时输入数据的格式一致。通过这些操作,模型能够接受不同尺寸、角度和方向的图像,从而提高其在实际应用中的表现。同时,归一化处理有助于稳定训练过程,加速模型收敛。,这些预处理操作的目的是为了增强模型的泛化能力,并确保模型在训练和验证时输入数据的格式一致。通过这些操作,模型能够接受不同尺寸、角度和方向的图像,从而提高其在实际应用中的表现。同时,归一化处理有助于稳定训练过程,加速模型收敛。
# 定义数据预处理
transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
3.读取数据
# 读取数据
dataset = './dataset'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'val')
batch_size = 32
num_classes = 2 # 修改为您的分类数
data = {
'train': datasets.ImageFolder(root=train_directory, transform=transform['train']),
'val': datasets.ImageFolder(root=valid_directory, transform=transform['val'])
}
train_loader = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
test_loader = DataLoader(data['val'], batch_size=batch_size, shuffle=False, num_workers=8)
注:这段代码的主要目的是读取和准备图像数据集,以便用于训练和验证深度学习模型,这段代码设置了数据加载器,它们将在训练和验证过程中提供经过预处理的图像数据。这些数据加载器是PyTorch中用于批量加载数据并使其易于迭代的重要工具。
二、定义卷积神经网络
1.导入必要的库
from torch.autograd import Variable: 从torch.autograd模块中导入Variable类。Variable是PyTorch中自动微分的关键类,它封装了张量,并提供了自动计算梯度等功能。然而,从PyTorch 0.4版本开始,Variable已经被整合到torch.Tensor中,因此不再需要显式地从torch.autograd中导入Variable。在最新的PyTorch版本中,直接使用torch.Tensor即可,它继承了Variable的所有功能。
# 神经网络
import torch
import torch.nn as nn
from torch.autograd import Variable
2.定义名为convolutional_block的卷积块类
这个convolutional_block类定义了一个卷积块,它将输入张量通过两个并行路径(step1和step2),然后将它们的结果相加,并应用ReLU激活函数。这种结构通常用于残差网络(ResNet)中,有助于解决深度网络训练过程中的梯度消失问题。
class convolutional_block(nn.Module):#convolutional_block层
def __init__(self,cn_input,cn_middle,cn_output,s=2):
super(convolutional_block,self).__init__()
self.step1=nn.Sequential(nn.Conv2d(cn_input,cn_middle,(1,1),(s,s),padding=0,bias=False),nn.BatchNorm2d(cn_middle,affine=False),nn.ReLU(inplace=True),
nn.Conv2d(cn_middle,cn_middle,(3,3),(1,1),padding=(1,1),bias=False),nn.BatchNorm2d(cn_middle,affine=False),nn.ReLU(inplace=True),
nn.Conv2d(cn_middle,cn_output,(1,1),(1,1),padding=0,bias=False),nn.BatchNorm2d(cn_output,affine=False))
self.step2=nn.Sequential(nn.Conv2d(cn_input,cn_output,(1,1),(s,s),padding=0,bias=False),nn.BatchNorm2d(cn_output,affine=False))
self.relu=nn.ReLU(inplace=True)
def forward(self,x):
x_tmp=x
x=self.step1(x)
x_tmp=self.step2(x_tmp)
x=x+x_tmp
x=self.relu(x)
return x
3.定义了一个名为identity_block的恒等块类
定义了一个名为identity_block的恒等块类,它也是nn.Module的子类。这个类实现了一个恒等块的构造和前向传播过程,它通常用于深度卷积神经网络(CNN)中,特别是在残差网络(ResNet)结构中。恒等块的主要特点是输入和输出之间有一个直接的联系(即残差连接),这有助于解决深度网络训练过程中的梯度消失问题。
class identity_block(nn.Module):#identity_block层
def __init__(self,cn,cn_middle):
super(identity_block,self).__init__()
self.step=nn.Sequential(nn.Conv2d(cn,cn_middle,(1,1),(1,1),padding=0,bias=False),nn.BatchNorm2d(cn_middle,affine=False),nn.ReLU(inplace=True),
nn.Conv2d(cn_middle,cn_middle,(3,3),(1,1),padding=1,bias=False),nn.BatchNorm2d(cn_middle,affine=False),nn.ReLU(inplace=True),
nn.Conv2d(cn_middle,cn,(1,1),(1,1),padding=0,bias=False),nn.BatchNorm2d(cn,affine=False))
self.relu=nn.ReLU(inplace=True)
def forward(self,x):
x_tmp=x
x=self.step(x)
x=x+x_tmp
x=self.relu(x)
return x
4.定义了一个名为Resnet的深度卷积神经网络类
class Resnet(nn.Module):#主层
def __init__(self,c_block,i_block):
super(Resnet,self).__init__()
self.conv=nn.Sequential(nn.Conv2d(3,64,(7,7),(2,2),padding=(3,3),bias=False),nn.BatchNorm2d(64,affine=False),nn.ReLU(inplace=True),nn.MaxPool2d((3,3),2,1))
self.layer1=c_block(64,64,256,1)
self.layer2=i_block(256,64)
self.layer3=c_block(256,128,512)
self.layer4=i_block(512,128)
self.layer5=c_block(512,256,1024)
self.layer6=i_block(1024,256)
self.layer7=c_block(1024,512,2048)
self.layer8=i_block(2048,512)
self.out=nn.Linear(2048,2,bias=False)
self.avgpool=nn.AvgPool2d(7,7)
def forward(self,input):
x=self.conv(input)
x=self.layer1(x)
for i in range(2):
x=self.layer2(x)
x=self.layer3(x)
for i in range(3):
x=self.layer4(x)
x=self.layer5(x)
for i in range(5):
x=self.layer6(x)
x=self.layer7(x)
for i in range(2):
x=self.layer8(x)
x=self.avgpool(x)
x=x.view(x.size(0),-1)
output=self.out(x)
return output
net=Resnet(convolutional_block,identity_block).cuda()
注:这段代码定义了一个ResNet结构的深度学习模型,它可以用于图像分类任务。模型的结构是模块化的,可以通过调整卷积块和恒等块的数量和配置来适应不同的需求和数据集。最后,模型被移动到GPU上以加速训练和推理过程。
三、创建模型
1. 检查GPU设备
如果 GPU 可用,则定义一个 torch.device 对象,表示使用 GPU。如果 GPU 不可用,则定义一个 torch.device 对象,表示使用 CPU。
以下是函数的详细步骤:
1)检查 GPU 可用性:
-
if torch.cuda.is_available(): 这行代码检查是否有可用的 GPU 设备。
-
device = torch.device(‘cuda’): 如果 GPU 可用,则定义一个 torch.device 对象,表示使用 GPU。
-
print(“CUDA is available! Using GPU for training.”): 打印一条消息,表示 CUDA
可用,并且使用 GPU 进行训练。 -
else: 如果 GPU 不可用,则执行以下代码。
2)使用 CPU 进行训练:
- evice = torch.device(‘cpu’): 定义一个 torch.device 对象,表示使用 CPU。
- print(“CUDA is not available. Using CPU for training.”): 打印一条消息,表示 CUDA 不可用,并且使用 CPU 进行训练。
# 首先,检查是否有可用的 GPU
if torch.cuda.is_available():
# 定义 GPU 设备
device = torch.device('cuda')
print("CUDA is available! Using GPU for training.")
else:
# 如果没有可用的 GPU,则使用 CPU
device = torch.device('cpu')
print("CUDA is not available. Using CPU for training.")
2. 训练过程
如果 GPU 可用,将模型移动到 GPU 上,并使用 GPU 进行训练;如果 GPU 不可用,则使用 CPU 进行训练。
3)将模型移动到 GPU:
- model.to(device): 将模型移动到之前定义的 device 对象所表示的设备上。如果 device 是 ‘cuda’,则模型将被移动到 GPU;如果 device 是 ‘cpu’,则模型将被移动到 CPU。
4)定义损失函数:
- criterion = nn.CrossEntropyLoss(): 定义交叉熵损失函数,这是用于分类问题的常见损失函数。
5)创建优化器:
- optimizer = optim.Adam(Alex_model.parameters(), lr=0.001, weight_decay=1e-4): 创建Adam 优化器,其中 lr=0.001 表示学习率为 0.001,weight_decay=1e-4 表示权重衰减为 0.0001。
# 将模型移动到 GPU
model.to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 创建优化器
optimizer = optim.Adam(Alex_model.parameters(), lr=0.001, weight_decay=1e-4)
运行结果:

四、训练模型
1. 设置模型为训练模式
这个函数是训练过程中的核心部分,它执行了模型的前向传播、损失计算、反向传播和参数更新,以及定期输出训练进度和性能指标。
def train(model, device, train_loader, optimizer, epoch):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
if batch_idx % 10 == 0: # 每10个批次打印一次
print(f'Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}')
print(f'Epoch {epoch}, Loss: {running_loss / len(train_loader)}, Accuracy: {100 * correct / total}%')
2.定义实验过程
这个函数是模型评估过程中的核心部分,它计算了模型在验证集上的损失和准确率,这些指标对于监控模型性能和调整训练策略非常重要。
# 定义验证过程
def val(model, device, test_loader, criterion):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f'Validation, Loss: {running_loss / len(test_loader)}, Accuracy: {100 * correct / total}%')
3.增加学习率调度器
通过训练和验证过程来优化模型参数,并使用学习率调度器来调整学习率,以提高模型的性能。在实际应用中,EPOCHS通常会设置为一个较大的值,以确保模型得到充分的训练。
# 创建优化器
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 创建学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 训练模型
EPOCHS = 1
for epoch in range(1, EPOCHS + 1):
train(model, device, train_loader, optimizer, epoch)
val(model, device, test_loader, criterion)
scheduler.step() # 调整学习率
运行结果:

六、测试模型
1.导入资源包
torchvision.transforms:这个模块提供了一组图像转换操作,可以在数据加载时对图像进行预处理,例如调整大小、裁剪、翻转等。
import torch
from PIL import Image
import torchvision.transforms as transforms
from torchvision import models
from torch.autograd import Variable
2.定义数据预处理
定义图像的预处理步骤,并将使用GPU(如果可用)进行模型训练。在实际应用中,您需要根据自己的数据集和任务需求来调整这些参数。
定义数据预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 定义类别
classes = ['cat', 'dog'] # 替换为您的实际类别名称
# 检查是否有可用的 GPU
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
3.自定义Resnet50模型
定义了一个自定义的ResNet-50模型,这是一个在图像识别任务中广泛使用的卷积神经网络(CNN)架构。代码中使用了一些简写,比如c_block和i_block,这些应该是在代码的其他部分定义的类,分别代表ResNet中的convolution block(卷积块)和identity block(恒等块)。
# 定义自定义的 Resnet50 模型
class Resnet(nn.Module):#主层
def __init__(self,c_block,i_block):
super(Resnet,self).__init__()
self.conv=nn.Sequential(nn.Conv2d(3,64,(7,7),(2,2),padding=(3,3),bias=False),nn.BatchNorm2d(64,affine=False),nn.ReLU(inplace=True),nn.MaxPool2d((3,3),2,1))
self.layer1=c_block(64,64,256,1)
self.layer2=i_block(256,64)
self.layer3=c_block(256,128,512)
self.layer4=i_block(512,128)
self.layer5=c_block(512,256,1024)
self.layer6=i_block(1024,256)
self.layer7=c_block(1024,512,2048)
self.layer8=i_block(2048,512)
self.out=nn.Linear(2048,2,bias=False)
self.avgpool=nn.AvgPool2d(7,7)
def forward(self,input):
x=self.conv(input)
x=self.layer1(x)
for i in range(2):
x=self.layer2(x)
x=self.layer3(x)
for i in range(3):
x=self.layer4(x)
x=self.layer5(x)
for i in range(5):
x=self.layer6(x)
x=self.layer7(x)
for i in range(2):
x=self.layer8(x)
x=self.avgpool(x)
x=x.view(x.size(0),-1)
output=self.out(x)
return output
4.实例化 Resnet50 类
用于加载预训练的ResNet-50模型,并使用该模型对上传的图片进行预测,image = Variable(image).to(DEVICE): 这一行将预处理后的图像转换为PyTorch变量(如果您的模型需要),并将其移动到DEVICE上。
# 实例化 Resnet50 类
model=Resnet(convolutional_block,identity_block).cuda()
# 加载权重
model.load_state_dict(torch.load("Resnet50.pth"))
model.to(DEVICE)
model.eval()
# 定义预测函数
def predict_image(image_path):
# 打开图片
image = Image.open(image_path)
# 应用预处理
image = transform(image).unsqueeze(0) # 添加batch维度
# 转换为Variable(如果模型需要)
image = Variable(image).to(DEVICE)
# 获取模型预测
output = model(image)
_, prediction = torch.max(output.data, 1)
return classes[prediction.item()]
# 上传的图片路径
uploaded_image_path = '77.jpg'
# 进行预测
predicted_class = predict_image(uploaded_image_path)
print(f"The uploaded image is predicted as: {predicted_class}")
运行结果: