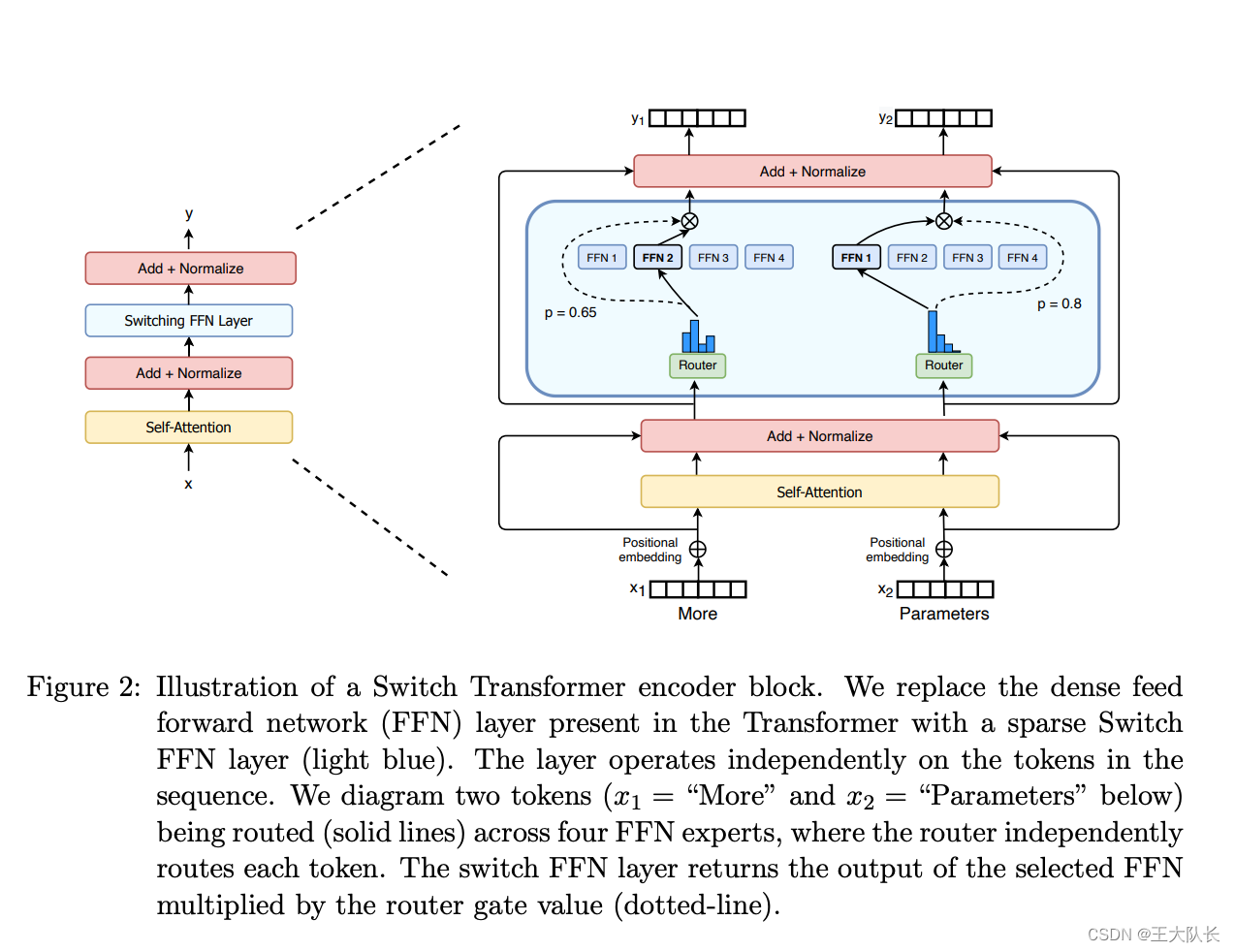
MOE网络结构
和传统的 transformer 网络结构相比,我们将 Transformer 模型的每个 FFN 层替换为 MoE 层,MoE 层由门网络(Router)和一定数量的专家(Expert)组成。
- 这些 Expert 其实也是 FFN 层,但是是 sparse FFN 层。
- Router 理论上可以是一个简单的网络最后加上一个 Softmax 来归一化得到每个 expert 的分数即可。
MOE优缺点
优点:降低推理耗时
因为在 transformer 的推理过程中 FFN 的权重的维度是 ffn1: d_model x d_ff(d_ff 通常很大例如等于 4*d_model),ffn2: d_ff x d_model,所以除了 attention 之外这两个 ffn 的推理耗时占比也是比较大的,因此将 transformer 换成 MOE 的一个优点就是降低推理耗时。
这里需要注意的是 MOE 的所有 expert 加起来参数比 transformer 的参数要多,但是我们推理过程中只会根据 Router 来选择激活一个或者几个 expert,所以这时的推理时的参数是要比 transformer 要小的。
缺点:增加网络参数量、finetune 困难目前不成熟
因为 MOE 需要提前加载所有 Expert 的参数,所以比起 transformer 来说参数量会大一些(只是提前加载的参数量)
Sparse model 更容易过拟合,并且 MOE 比较难 finetune。