一、为啥要补环境?
我们每次逆向扣完代码存放在 nodejs 上是运行不出结果的,因为缺少浏览器环境特有的一些 window/document/navigator/localstorage 等参数,所以我们需要把这些缺少的浏览器环境补上,让这份js代码在本地nodejs环境下也能运行出结果来。
以下是Node和真实浏览器的差别:

补环境的基本格式
补环境可以分为三部分,上中下三层。
- 上层放你需要补的环境参数
- 中层放你扣好的js代码
- 下层放生成的目标参数,通过它传递给你的爬虫
补环境的好处就是我们完全不用考虑内部的算法逻辑,让它能正常跑起来输出就行。
结构如图:

二、v_jstools安装
1、下载地址: https://github.com/cilame/v_jstools
2、下载解压后,打开 chrome://extensions/ , 然后把解压后的文件夹拖进去即可

把它从插件中取出来固定

三、测试案例
目标网址:aHR0cHM6Ly9xLjEwanFrYS5jb20uY24v
目标路径如下图:

操作步骤
1. 扣代码
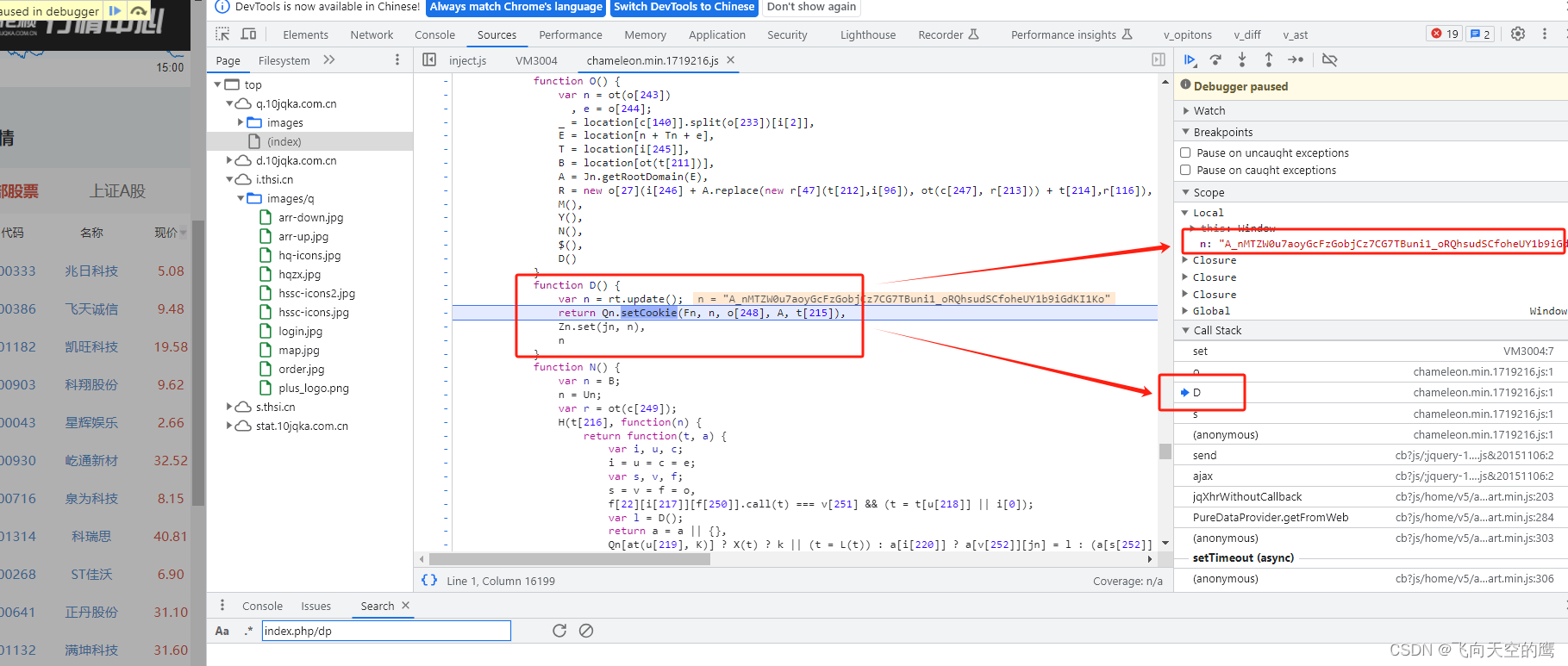
1、利用hook,将cookie生成的地方找到。在console中输入一下代码,等待一会,会自动跳转到hook的cookie生成处
// 定义 hook 脚本,这样,代码读写cookie的时候,就会断点停下来,方便分析了
Object.defineProperty(document, 'cookie', {
get: function() {
debugger;
return "";
},
set: function(value) {
debugger;
return value;
},
});
然后找到右侧的堆栈的方式进行查看,发现cookie实现的 js核心 代码,如图:

新建一个js文件,直接将上面js文件所有代码复制下来,其中顶部的可以改成实时的时间更新,如图:

致辞,中间层扣代码已结束~
2. 利用插件自动补环境
1、配置
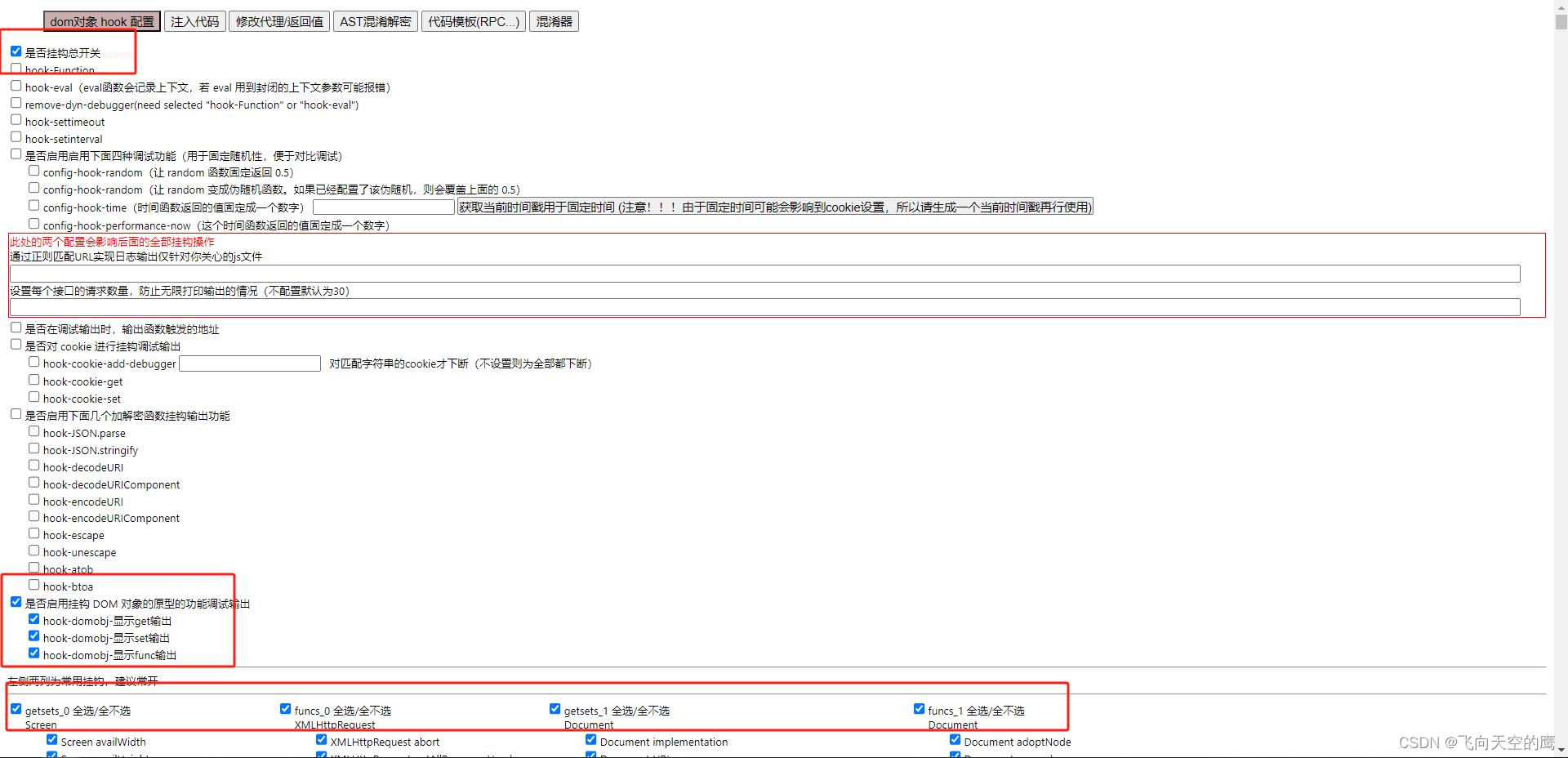
1.先点击打开如下两个开关,然后打开配置页面

2.如下插件配置详情,勾选上总开关,DOM开关,以及常用的挂钩,然后关掉该配置页面即可,如图:
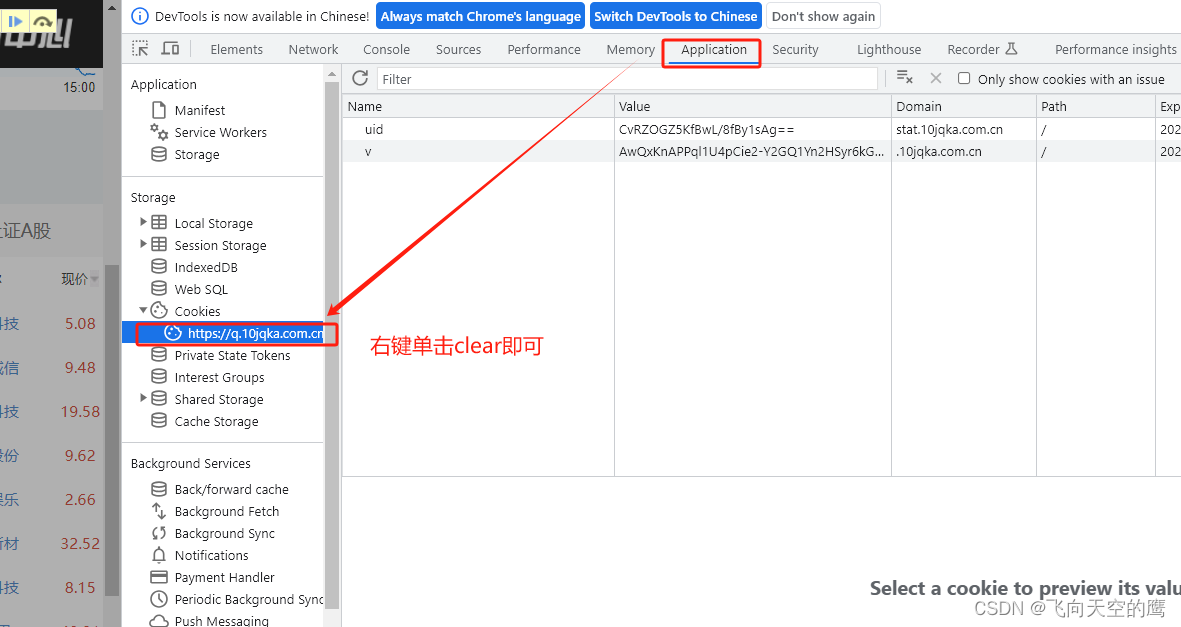
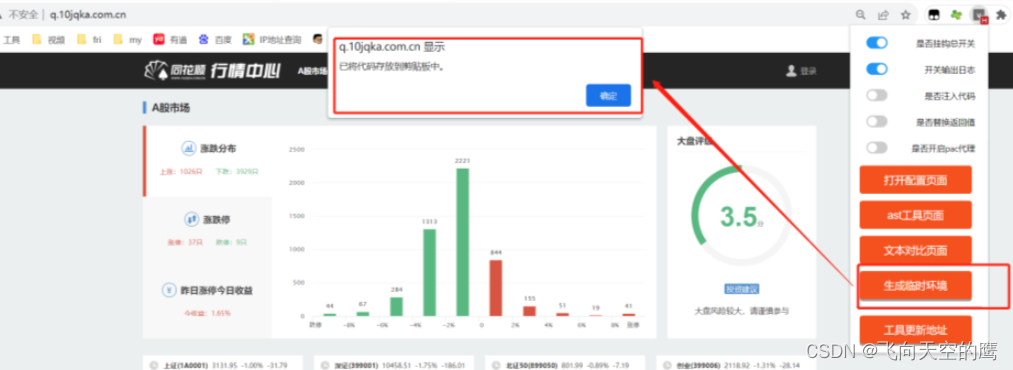
2. 清掉缓存cookie,方法如图:
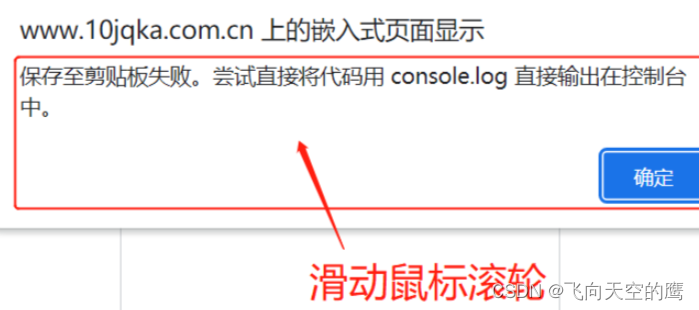
然后刷新网页,在滑动鼠标下滚下,防止无法正常生成临时环境,如下弹出,代表环境参数已经生成好
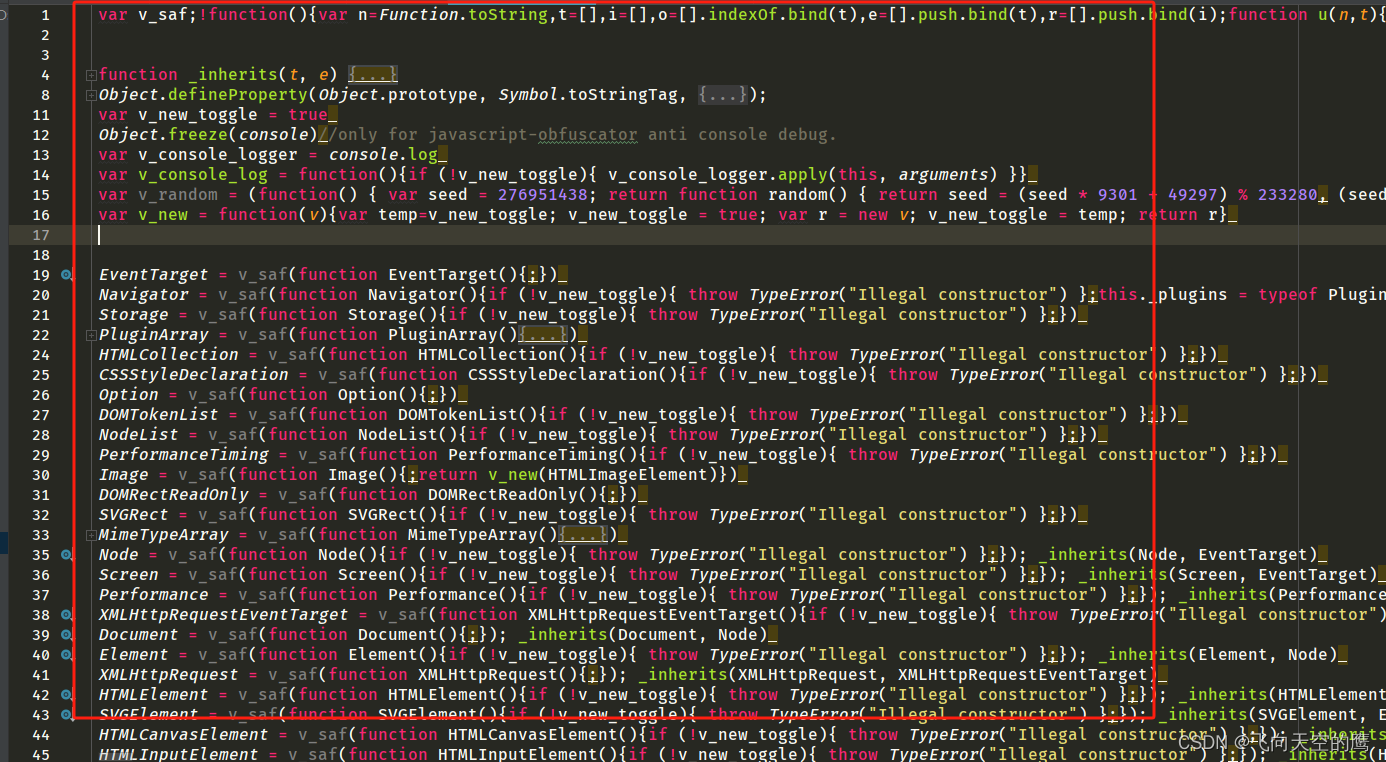
然后我们在刚刚新建的js文件里面ctrl+v粘贴刚刚生成的临时环境,放在最上方即可
3.填写执行引用
function get_cookiess() {
console.log(document.cookie);
cookies = document.cookie.split("; ")[0].split("=")[1];
return cookies
};
console.log('最终生成的cookie是: ', get_cookiess());
至此,可以正常生成cookie了,但是发现生成完cookie,js一直没有停止,无法中断程序退出的现象,就是run后不能自动停掉程序。
解决方法:可以尝试将setInterval()定时函数给置空,这是因为setinterval不会清除定时器队列,每重复执行1次都会导致定时器叠加,最终卡死你的网页。
在顶部添加这个即可:
setInterval = function () {};
运行代码结果如下:
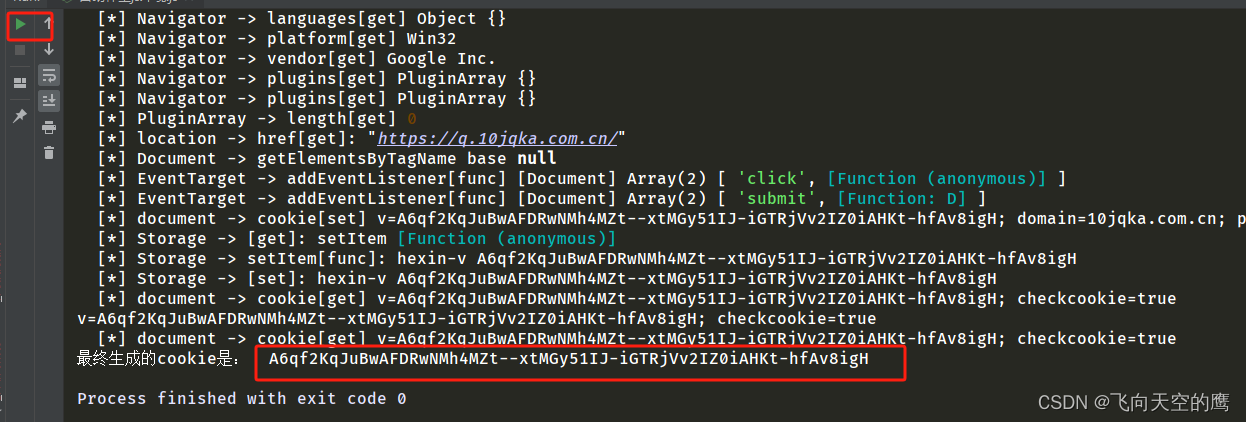
把它传给python代码
import requests
import execjs
import lxml
from lxml import etree
url = "https://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/1/ajax/1/"
with open('D:\Spider_work\自动补全js环境.js', 'r', encoding='utf-8') as f:
hexin_js = f.read()
cookie = execjs.compile(hexin_js).call('get_cookiess')
print('Js生成最新cookie:', cookie)
payload={}
headers = {
'Accept': 'text/html, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'v={}'.format(cookie),
'Referer': 'https://q.10jqka.com.cn/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'hexin-v': cookie,
'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"'
}
response = requests.request("GET", url, headers=headers, data=payload)
print('----------------------')
html = etree.HTML(response.text)
doc_list = html.xpath("//table//tr")[1:]
for tr in doc_list:
nums = tr.xpath('./td[1]/text()')[0]
tds = tr.xpath('./td[2]/a/text()')[0]
name = tr.xpath('./td[3]/a/text()')[0]
xj_price = tr.xpath('./td[4]/text()')[0]
zdf = tr.xpath('./td[5]/text()')[0]
print(nums, tds, name, xj_price, zdf)