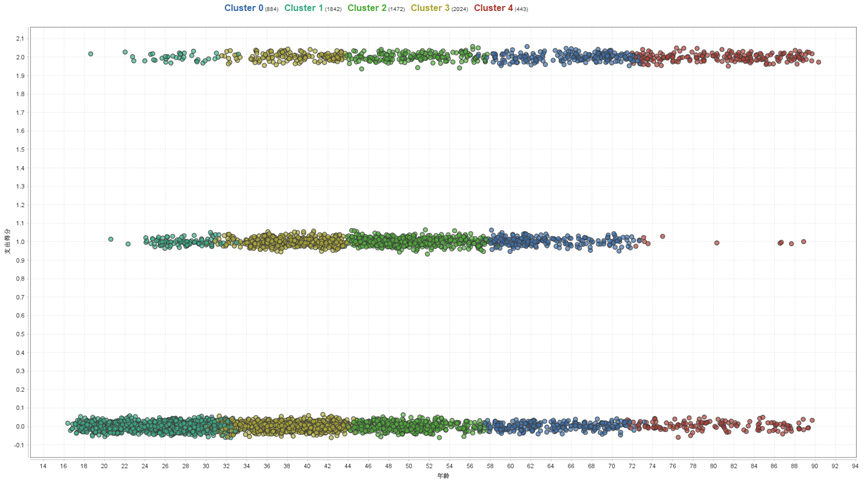
划分方法
K-均值算法(K-means算法)
方法:
- 首先选择K个随机的点,称为聚类中心.
- 对于数据集中的,每一个数据,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类.
- 计算每一个组的平均值,将改组所关联的中心点移动到平均值的位置
- 重复2~4直至中心点不再变化.
PAM(k-中心点算法)
 算法分析:k-中心点算法消除了k-平均算法对孤立点的敏感性;比k-平均算法更健壮。算法分析:k-中心点算法消除了k-平均算法对孤立点的敏感性;比k-平均算法更健壮。
算法分析:k-中心点算法消除了k-平均算法对孤立点的敏感性;比k-平均算法更健壮。算法分析:k-中心点算法消除了k-平均算法对孤立点的敏感性;比k-平均算法更健壮。
层次方法
SOM聚类算法
FCM聚类算法
AGNES算法
自底向上的凝聚层次聚类方法
AGNES将每个对象自为一簇,然后这些簇根据某种准则逐步合并,直到所有的对象最终合并形成一个簇。

DIANA算法
自顶向下的分裂层次聚类方法
在DIANA中,所有的对象用于形成一个初始簇。根据某种原则(如,簇中最近的相邻对象的最大欧氏距离),将该簇分裂。簇的分裂过程反复进行,直到最终每个新簇只包含一个对象。

BIRCH 算法算法
BIRCH算法,首先用树结构对数据对象进行层次划分,其中叶节点或低层次的非叶节点可以看作是由分辨率决定的“微簇”,然后使用其他的聚类算法对这些微簇进行宏聚类,它克服了凝聚聚类方法所面临的两个困难:
①可伸缩性;
②不能撤销前一步所做的工作。
BIRCH 算法最大的特点是能利用有限的内存资源完成对大数据集高质量地聚类,通过单遍扫描数据集最小化I/O 代价。










![[FreeRTOS 基础知识] 信号量 概念](https://img-blog.csdnimg.cn/direct/376b4922e6444895adcbc65f7fdc9450.png)