一、引言
随着大数据和人工智能技术的快速发展,数据成为了推动科技进步的重要资源。然而,在实际应用中,数据往往呈现出碎片化、分散化的特点,如何有效地利用这些数据成为了业界关注的焦点。联盟学习(Federated Learning)作为一种新兴的技术,旨在解决数据孤岛问题,实现多方数据在不共享原始数据的前提下进行联合建模,为数据价值的挖掘提供了新的思路。本文将从联盟学习的原理、现状、特点、适用场景和不足之处等方面进行深入探讨,并给出后续优化方向和学习路线建议。
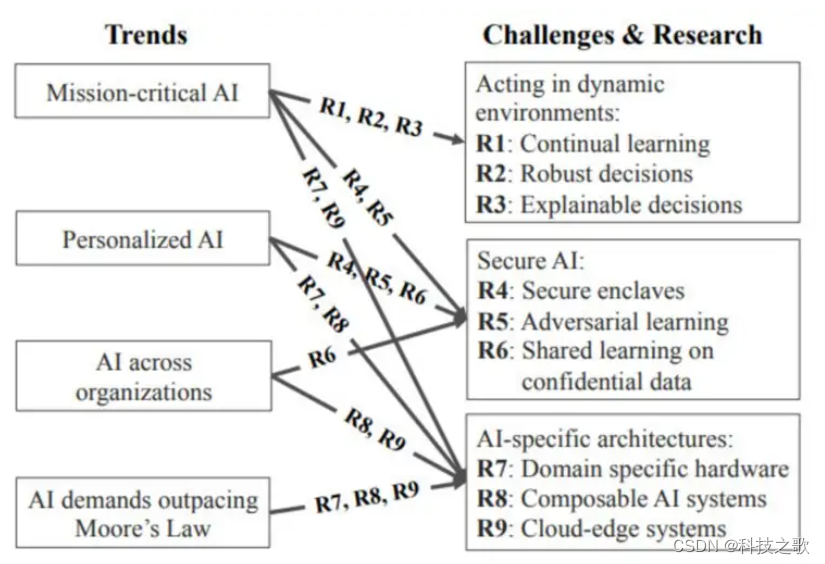
二、联盟学习的原理
联盟学习到底是什么?
联盟学习,又称联邦学习或联合学习,是一种机器学习设定,其中多个客户端在中央服务器的协调下共同训练模型,同时保持训练数据的去中心化及分散性。具体而言,联盟学习的核心思想是将数据模型的训练过程拆分为多个部分,在本地客户端进行模型训练,然后将训练得到的模型参数或梯度信息上传至中央服务器进行聚合,最终得到全局模型。通过这种方式,不同参与方可以在不暴露或汇聚原始数据的前提下,实现联合建模,达到数据价值共享的目的。
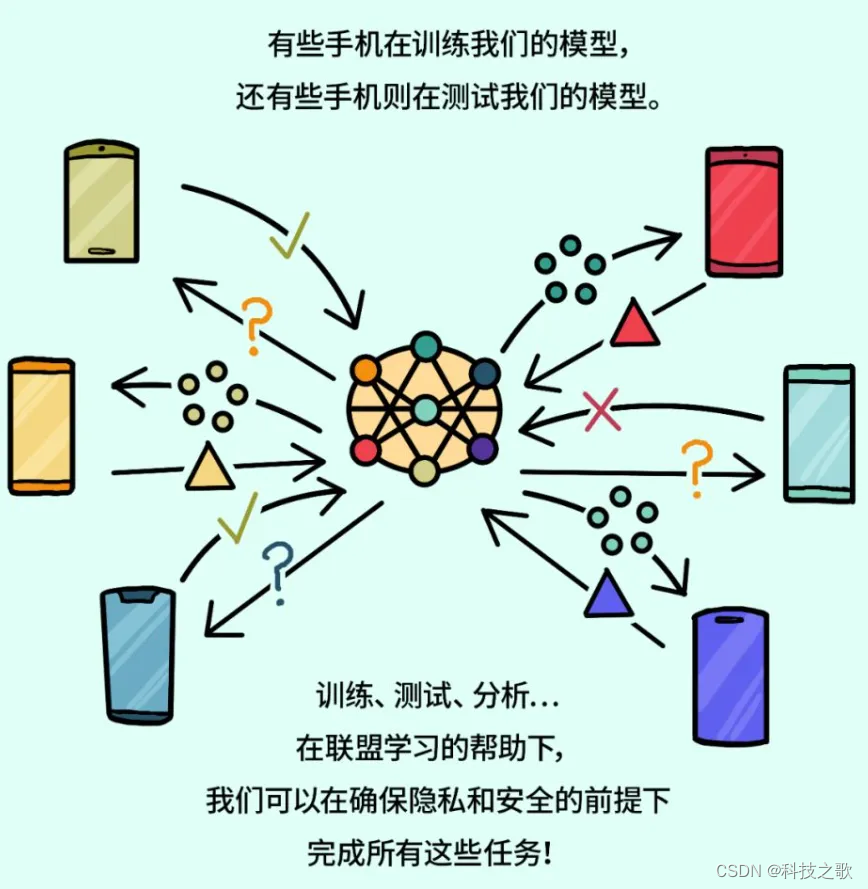
要使用去中心化的数据来训练中心化的模型
● 通过把训练过程搬移到端侧:设定相应的条件(充电、接入WiFi、休眠时才进行相应训练)
● 测试、训练都在端侧,端侧对训练后的模型参数进行聚合,到服务端再进行中心化训练,进行版本迭代
● 每台设备在发送任何东西之前安全聚合协议都会在其中加入零和掩码对训练成果进行混淆。但当你把所有训练成果聚合在一起的时候掩码被抵消了!
● 服务器使用安全聚合(secure aggregation)将加密过的训练成果整合在一起,且只对聚合过程本身进行解密处理
三、联盟学习的特点
- 数据去中心化:联盟学习允许不同参与方在本地进行模型训练,避免了数据的集中存储和传输,降低了数据泄露和隐私侵犯的风险。
- 模型聚合:通过中央服务器的协调,不同参与方可以将本地训练得到的模型参数或梯度信息进行聚合,得到全局模型,实现知识的共享和融合。
- 高效性:联盟学习充分利用了分布式计算的优势,通过并行化训练提高了模型训练的效率和速度。
- 隐私保护:由于联盟学习过程中不直接传输原始数据,仅传输模型参数或梯度信息,因此可以有效保护数据隐私和安全。

四、联盟学习的适用场景
- 跨领域合作:当不同领域的企业或机构需要利用各自的数据进行联合建模时,可以采用联盟学习技术,实现数据的共享和融合。
- 隐私敏感领域:在金融、医疗等隐私敏感领域,数据的安全性和隐私性至关重要。联盟学习技术可以在不泄露原始数据的前提下进行联合建模,满足这些领域对数据隐私保护的需求。
- 分散式数据源:当数据分散在多个地方或设备上时,传统的集中式训练方法无法实现高效的数据利用。联盟学习技术可以充分利用分散式数据源的优势,实现高效的数据挖掘和价值共享。
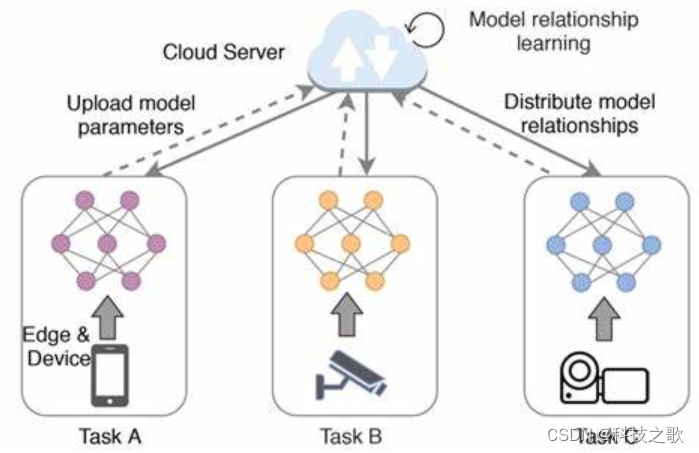
五、联盟学习的不足之处
- 通信开销:由于联盟学习需要在不同参与方之间进行模型参数或梯度信息的传输,因此通信开销较大。这可能会限制联盟学习在大规模数据集上的应用。
- 异构性问题:不同参与方的数据可能存在异构性,即数据分布、特征表示等方面存在差异。这可能会导致模型训练的困难和性能下降。
- 安全性问题:虽然联盟学习可以在一定程度上保护数据隐私和安全,但仍然存在一定的安全风险。例如,恶意参与方可能会通过伪造模型参数或梯度信息来攻击系统。
六、学习路线建议
对于想要深入了解和掌握联盟学习技术的读者,以下是一个建议的学习路线:
- 基础知识学习:掌握机器学习、深度学习等基础知识,了解分布式计算、网络通信等相关技术。
- 联盟学习原理学习:阅读相关论文和书籍,深入理解联盟学习的原理、算法和应用场景。
- 实践操作:通过编写代码和参与项目实践,掌握联盟学习的实现方法和技巧。
- 深入研究:针对联盟学习的不足之处和后续优化方向进行深入研究,提出自己的解决方案和创新点。
结语
联盟学习作为一种新兴的技术,为数据价值的挖掘提供了新的思路和方法。通过深入学习和实践联盟学习技术,我们可以更好地利用碎片化、分散化的数据资源,推动科技进步和社会发展。同时,我们也需要关注联盟学习的不足之处和潜在风险,加强安全防护和性能优化等方面的研究。


![[分布式网络通讯框架]----ZooKeeper下载以及Linux环境下安装与单机模式部署(附带每一步截图)](https://img-blog.csdnimg.cn/direct/74ec6b86bff74dbdb143feb42c1a994a.png)