一、概述
-
Stream流操作是Java 8提供一个重要新特性,它允许开发人员以声明性方式处理集合,其核心类库主要改进了对集合类的API和新增Stream操作。Stream类中每一个方法都对应集合上的一种操作。将真正的函数式编程引入到Java中,能 让代码更加简洁,极大地简化了集合的处理操作,提高了开发的效率和生产力。 -
同时
Stream不是一种数据结构,它只是某种数据源的一个视图,源可以是数组、文件、集合、函数,Java容器或I/O通道(channel)等。在Stream中的操作每一次都会产生新的流,内部不会像普通集合操作一样立刻获取值,而是 惰性取值 ,只有等到用户真正需要结果的时候才会执行。 -
并且对于现在调用的方法,本身都是一种高层次构件,与线程模型无关。因此在并行使用中,开发者们无需再去操 心线程和锁了。
Stream内部都已经做好了 。 -
对于
Stream流的可以把它当成工厂中的流水线,每个Stream流的操作过程遵循着创建 -->操作 -->获取结果的过程,就像流水线上的节点一样组成一个个链条。除此之外你还可以把他理解成sql的视图,集合就相当于数据表中的数据,获取Stream流的过程就是确定数据表的属性和元数据的过程,元数据的每一个元素就是表中的数据,对Stream流进行操作的过程就是通过sql对这些数据进行查找、过滤、组合、计算、操作、分组等过程,获取结果就是sql执行完毕之后获取的结果视图一样。
二、Stream流的获取方法
1)单列集合
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream();
2)双列集合
HashMap<String, Integer> map = new HashMap<>();
双列集合不能直接获取Stream流,一般有以下两种方式获取双列集合的Stream流:
-
使用
keyset先获取到所有的键,再把这个set集合中所有的键放到stream流中
Stream<String> stream = map.keySet().stream(); // 使用示例 stream.forEach(key -> System.out.println(key + "=" + map.get(key))) -
使用
entrySet先获取到所有的键值对对象,再把这个
set集合中所有的键值对对象放到streamStream<Map.Entry<String, Integer>> stream = map.entrySet().stream(); // 使用示例 stream.forEach(item -> System.out.println(item.getKey() + '-' + item.getValue()));
3)数组
int[] arr = {1, 2, 3}
IntStream stream = Arrays.stream(arr)
// 使用示例
stream.forEach(System.out::println);
4)同种数据类型的多个数据
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5)
// 使用示例
stream.forEach(System.out::println);
5)获取并行流
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> parallelStream = list.parallelStream();
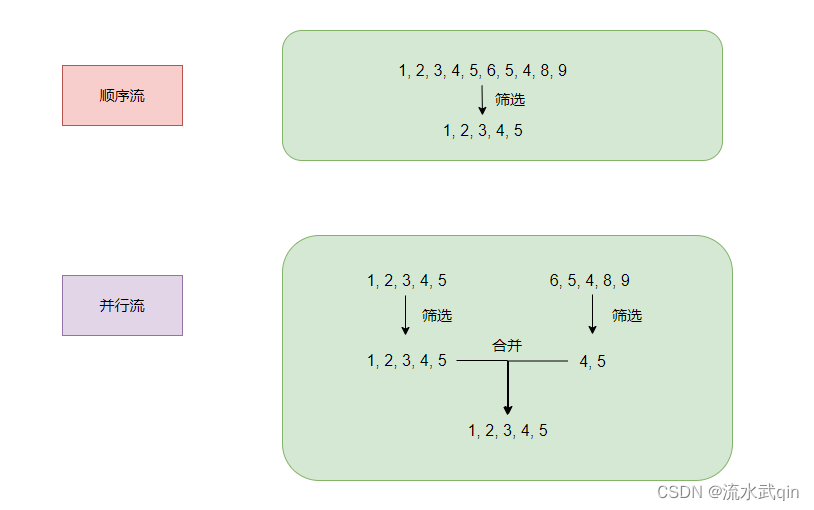
stream和parallelStream的简单区分:
-
stream是顺序流,由主线程按顺序对流执行操作 -
parallelStream是并行流,内部以多线程并行执行的方式操作流,前提是对流中的数据处理没有顺序要求。
例如筛选集合中的奇数,两者的处理有所不同:
6)文件
// lines方法需要抛出或者捕获异常,因为文件data.txt是有可能不存在的
Stream <String > lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset());
7)通过函数生成
Stream提供了iterate和generate两个静态方法从函数中生成流。
iterate
// iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作
Stream<Integer> iterate = Stream.iterate(0, item -> item + 1);
// iterator生成的流为无限流,使用时需要进行截取
iterate.limit(10).forEach(item -> System.out.println(item));
generate
// generate方法接受一个参数,方法参数类型为Supplier,一个生产型的函数式接口
Stream<Double> generate = Stream.generate(Math::random);
// generate生成的流为无限流,使用时需要进行截取
generate.limit(10).forEach(item -> System.out.println(item));
三、Stream流的基本操作
3.1 中间操作
中间操作的相关方法执行完之后,会返回一个处理过后的Stream流,这样依然可以继续执行其它流操作。
形成一定的链式编程。
1)filter
对流中的数据进行过滤、筛选 。
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
Stream<Integer> stream = list.stream().filter(item -> item > 8)
2)distinct
// 普通数字集合去重
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
Stream<Integer> stream = list.stream().distinct();
// 对象集合根据某字段去重(根据图书名称去重)
Map<Object, Boolean> map = new HashMap<>();
List<Book> distinctNameBooks = books.stream()
.filter(item -> map.putIfAbsent(item.getName(), Boolean.TRUE) == null)
.collect(Collectors.toList());
// 提取集合中的对象的某个字段属性并去重
List<String> nameList = pipeList.stream()
.map(Student::getName)
.distinct().collect(Collectors.toList());
putIfAbsent 方法:
如果传入key对应的value已经存在,就返回存在的value,不进行替换。
如果不存在,就添加key和value,返回null
3)limit
截取此流中的部分元素组成的流,截取前指定参数个数的。
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
Stream<Integer> stream = list.stream().limit(2);
4)skip
跳过指定参数个数的数据,返回由该流的剩余元素组成的流。
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
Stream<Integer> stream = list.stream().skip(3);
5)concat
合并两个流,返回合并后的新流。
List<Integer> list1 = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> list2 = Arrays.asList(6, 7, 8, 9, 10);
Stream<Integer> concat = Stream.concat(list1.stream(), list2.stream());
6)map
流映射,可以将接受的元素映射成另外一个类型的元素。
List<String> stringList = Arrays.asList("lambda", "stream");
Stream<Integer> stream = stringList.stream().map(item -> item.length());
即使是复杂对象也是一样处理。
7)flatMap
流转换,可以将一个流中的每个值都转换为另一个流。
Stream<String[]> stream2 = stringList.stream().map(item -> item.split(""));
Stream<String> stringStream = stream2.flatMap(Arrays::stream);
8)allMatch
匹配所有,返回一个boolean类型的数据,意为流中元素是否都满足某个条件。
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
if (list.stream().allMatch(item -> item > 5)) {
System.out.println("集合中的所有元素都大于5");
}
9)anyMatch
匹配其中任意一个,返回一个boolean类型的数据,意为流中元素是否存在满足某个条件的元素。
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
if (list.stream().anyMatch(item -> item > 5)) {
System.out.println("集合中存在大于5的值");
}
10)noneMatch
全部不匹配,返回一个boolean类型的数据,意为流中元素是否都不满足某个条件。
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10);
if (list.stream().noneMatch(item -> item > 5)) {
System.out.println("集合中的所有元素小于或等于5");
}
3.2 终结操作
1)forEach
对此流的每个元素执行相同操作,和for循环效果类似。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream().forEach(System.out::println);
2)count
统计出流中元素的个数。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
long count = list.stream().count();
3)counting
也是统计出流中元素个数,只不过这一般要与collect联合使用。
import static java.util.stream.Collectors.counting;
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Long count = list.stream().count();
4)findFirst
查找流中的第一个元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> first = list.stream().findFirst();
5)findAny
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> any = list.stream().findAny();
6)reduce
将流中的元素组合起来。
reduce方法的第一个参数是一个初始值,第二个参数是初始值和流中的各个元素挨个要进行的操作。
例如是求和,就是初始值依次按照求和规则加上前面的值。
第一个参数初始值是可选的,不一定要填。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Integer sum = list.stream().reduce(0, (a, b) -> (a + b));
// 使用方法引用简写
Integer sum = list.stream().reduce(0, Integer::sum);
// 方法引用等同于如下写法
Integer sum2 = list.stream().reduce(0, (a, b) -> Integer.sum(a, b));
reduce更多应用可以看下面的各类求和、求最大最小值的部分,这里只介绍基本用法
3.3 收集操作
1)Collectors.toList()
在底层会创建一个List集合.并把所有的数据添加到List集合中.
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 2);
List<Integer> collect = list.stream().filter(number -> number % 2 == 0)
.collect(Collectors.toList());
2)Collectors.toSet()
把流中的数据写使用set集合收集起来,使用set集合不会保留重复数据
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 2);
List<Integer> collect = list.stream().filter(number -> number % 2 == 0)
.collect(Collectors.toSet());
3)Collectors.toMap()
List<Integer> list = Arrays.asList("zhangsan,23", "lisi,24");
// s 依次表示流中的每一个数据
// 第一个lambda表达式就是如何获取到Map中的键
// 第二个lambda表达式就是如何获取到Map中的值
Map<String, Integer> map = list.stream()
.collect(Collectors.toMap(
s -> s.split(",")[0],
s -> Integer.parseInt(s.split(",")[1])
));
四、其它常见操作
4.1 求和
1)给数值集合求和
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 方式一、使用lambda表达式
Integer sum1 = list.stream().reduce(0, (a, b) -> (a + b));
// 方式二、使用方法引用简写
Integer sum2 = list.stream().reduce(0, Integer::sum);
// 方法引用等同于如下写法
Integer sum2 = list.stream().reduce(0, (a, b) -> Integer.sum(a, b));
// 方式三、使用summingInt系列的方法(summingDouble、summingLong等)
Integer sum3 = list.stream().collect(summingInt(Integer::intValue))
// 方式四、推荐写法 (通过mapToInt将对象流转换为数值流,避免了装箱和拆箱操作,易读的同时保证了性能)
Integer sum4 = list.stream().mapToInt(item -> item).sum();
2)对集合中对象的某个字段求和
// 这里如果是整型或者是浮点数就用各自的方法即可,因为这样比较常规,所以这里以BigDecimal为例
List<Book> list = new ArrayList<>();
BigDecimal reduce = list.stream()
// 将Opportunity对象的金额属性取出
.map(Book::getCount)
// 使用reduce()聚合函数,得到金额总和
.reduce(BigDecimal.ZERO, BigDecimal::add);
4.2 求最大最小值
1)不使用reduce
// 普通数值集合
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> min1 = list.stream().min(Integer::compareTo);
Optional<Integer> max1 = list.stream().max(Integer::compareTo);
OptionalInt min2 = list.stream().mapToInt(Integer::valueOf).min();
OptionalInt max2 = list.stream().mapToInt(Integer::valueOf).max();
// 对象集合
List<Book> list = new ArrayList<>();
OptionalInt min3 = list.stream().mapToInt(Book::getCount).min(); // 推荐写法
OptionalInt max3 = list.stream().mapToInt(Book::getCount).max(); // 推荐写法
OptionalInt min4 = list.stream()
.mapToInt(Book::getCount)
.collect(minBy(Integer::compareTo));
OptionalInt max4 = list.stream()
.mapToInt(Book::getCount)
.collect(maxBy(Integer::compareTo));
推荐写法通过mapToInt将对象流转换为数值流,避免了装箱和拆箱操作,易读的同时保证了性能
2)使用reduce
List<Book> list = new ArrayList<>();
OptionalInt min = list.stream().map(Book::getCount).reduce(Integer::min);
OptionalInt max = list.stream().map(Book::getCount).reduce(Integer::max);
4.3 求平均值
List<Book> list = new ArrayList<>();
Double avg = list.stream().collect(averagingInt(Book::getCount));
4.4 同时求总和、平均值、最大值、最小值
List<Book> list = new ArrayList<>();
IntSummaryStatistics intSummaryStatistics = list.stream().collect(summarizingInt(Book::getCount));
int min = intSummaryStatistics.getMin(); // 获取最小值
int max = intSummaryStatistics.getMax(); // 获取最大值
long sum = intSummaryStatistics.getSum(); // 获取总和
Double avg = intSummaryStatistics.getAverage(); // 获取平均值
4.5 拼接流中的元素
// joining的方法参数为元素的分界符
List<String> stringList = Arrays.asList("lambda", "stream");
String result = stringList.stream().collect(Collectors.joining(","));
System.out.println(result); //lambda,stream
4.6 分组
1)普通分组
List<Book> list = new ArrayList<>();
Map<String, List<Book>> list.stream().collect(groupingBy(Book::getName));
2)使用集合中的对象的某个字段分组并统计每组数量
Map<String, Long> collect = list.stream()
.collect(Collectors.groupingBy(ish::getName, Collectors.counting()));
4.7 分区
分区是特殊的分组,它分类依据是true和false,所以返回的结果最多可以分为两组
List<Book> list = new ArrayList<>();
Map<Boolean, List<Book>> list.stream().collect(groupingBy(Book::isChina));
应用场景示例:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Map<Boolean, List<Integer>> collect2 = list.stream()
.collect(partitioningBy(item -> item < 3));
输出结果是这样:{false=[3, 4, 5], true=[1, 2]}按true和false分为了两组;
4.8 排序
1)基本数据类型自然排序
List<Integer> list = Arrays.asList(2, 3, 1, 4, 5);
// 升序
List<Integer> collect = list.stream().sorted().collect(Collectors.toList());
// 降序
List<Integer> collect1 = list.stream().sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
2)按照对象属性进行排序
List<Student> list = new ArrayList<>();
// 按学生年龄倒序, 不加reversed()就是升序
List<Student> collect = list.stream()
.sorted(Comparator.comparing(Student::getAge).reversed())
.collect(Collectors.toList());
// 如果需要多条件排序,可以使用thenComparing()
// 例如先按照年龄排序,再按照姓名排序
List<Student> collect2 = list.stream()
.sorted(Comparator.comparing(Student::getAge)
.thenComparing(Comparator.comparing(Student::getName)))
.collect(Collectors.toList());
3) List<Map<String, Object>>集合按某个key进行排序
List<Map<String, Object>> dataList = new ArrayList<>();
// 准备两数据
dataList.add(new HashMap<String, Object>() {
{
put("id", "1");
put("type", "0");
}
});
dataList.add(new HashMap<String, Object>() {
{
put("id", "2");
put("type", "2");
}
});
// 升序
List<Map<String, Object>> newAscList = dataList.stream()
.sorted(Comparator.comparing((Map m) -> (new BigDecimal(m.get("question_type").toString()))))
.collect(Collectors.toList());
// 降序
List<Map<String, Object>> newDescList = dataList.stream()
.sorted(Comparator.comparing((Map m) -> (new BigDecimal(m.get("question_type").toString()))).reversed())
.collect(Collectors.toList());