目录
Mobilenetv2的介绍
Mobilenetv2的结构
Inverted Residual Block倒残差结构
Pytorch实现Inverted Residual Block
搭建Mobilenetv2
Pytorch实现Mobilenetv2主干网络
相关参考资料
Mobilenetv2的介绍
Mobilenetv2网络设计基于Mobilenetv1,它保持了其简单性,不需要任何特殊的操作,同时显著提高了其准确性,实现了移动应用的多图像分类和检测任务的最先进水平。
MobileNetV2是基于倒置的残差结构,普通的残差结构是先经过 1x1 的卷积核把 feature map的通道数压下来,然后经过 3x3 的卷积核,最后再用 1x1 的卷积核将通道数扩张回去,即先压缩后扩张,而MobileNetV2的倒置残差结构是先扩张后压缩。另外,我们发现移除通道数很少的层做线性激活非常重要。
论文对模型在ImageNet分类、COCO目标检测和VOC图像分割的表现进行了度量,评估权衡了精度、乘加操作次数,实际延迟和参数的数量。
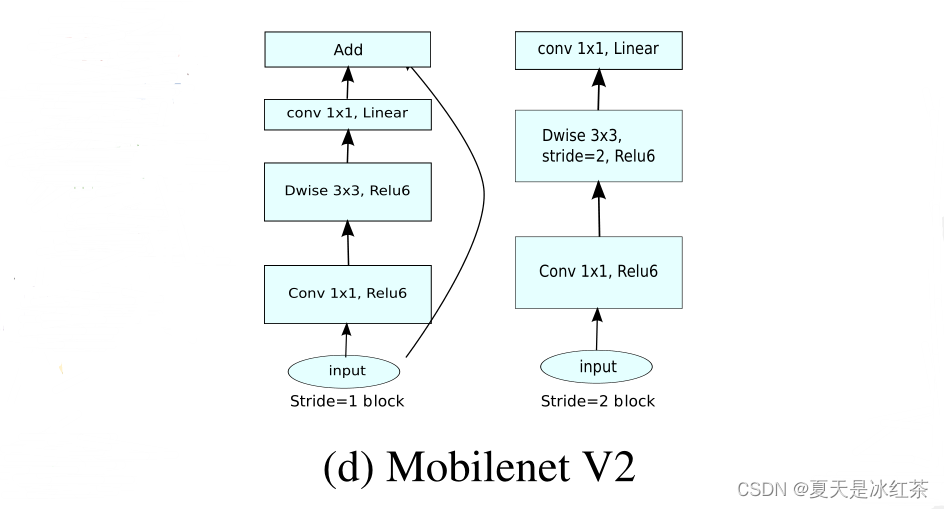
Mobilenetv2的结构
Inverted Residual Block倒残差结构
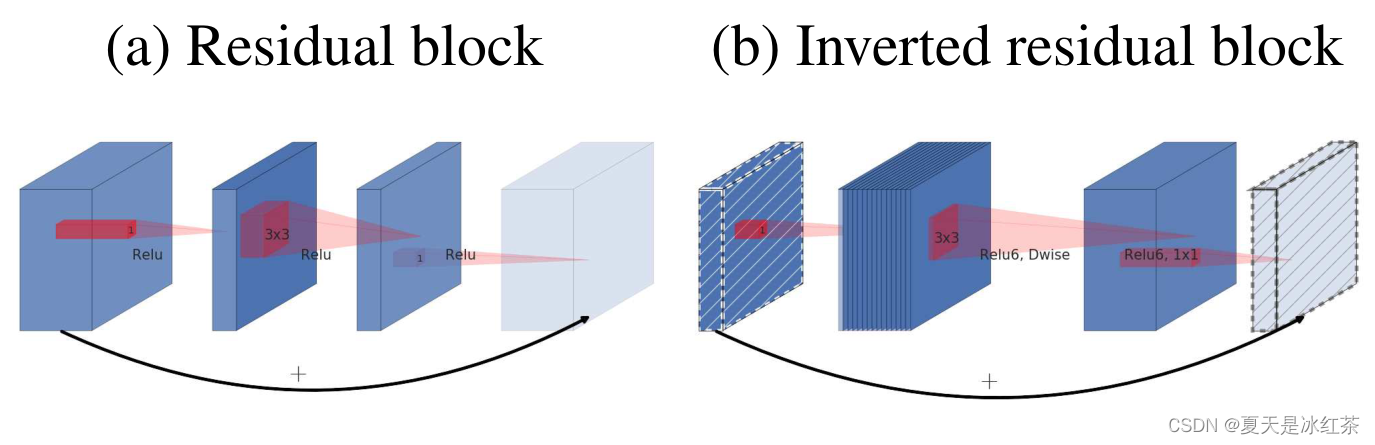
可以看见在我们上图的右边,就是倒残差结构,它会经历以下部分:
- 1x1卷积升维
- 3x3卷积DW
- 1x1卷积降维
接下来请结合着下面的代码来看,首先有一个expand_ratio来表示是否对输入进来的特征层进行升维,如果不需要就会进行卷积、标准化、激活函数、卷积、标准化。不然就会先有1x1卷积进行通道数的上升,在用3x3逐层卷积,进行跨特征点的特征提取,最后1x1卷积进行通道数的下降。
上升是为了让我们的网络结构有具备更好的特征表征能力,下降是为了让我们的网络具备更低的运算量,在完成这样的特征提取后,如果要使用残差边,我们就会将特征提取的结果直接与输入相接,如果没有使用残差边,就会直接输出卷积结果。
Pytorch实现Inverted Residual Block
import torch.nn as nn
BatchNorm2d = nn.BatchNorm2d
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# 进行3x3的逐层卷积,进行跨特征点的特征提取
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=(3,3), stride=stride, padding=1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# 利用1x1卷积进行通道数的调整
nn.Conv2d(hidden_dim, oup, kernel_size=(1,1), stride=(1,1), padding=0, bias=False),
BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# 利用1x1卷积进行通道数的上升
nn.Conv2d(inp, hidden_dim, kernel_size=(1,1), stride=(1,1), padding=0, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# 进行3x3的逐层卷积,进行跨特征点的特征提取
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=(3,3), stride=stride, padding=1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# 利用1x1卷积进行通道数的下降
nn.Conv2d(hidden_dim, oup, kernel_size=(1,1), stride=(1,1), padding=0, bias=False),
BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)搭建Mobilenetv2
在这里它的实现还是相对比较清晰的。在建立Mobilenetv2前,首先先定义了bn卷积,只有卷积核的大小有所不同,具体可以看下面pytoch实现当中。
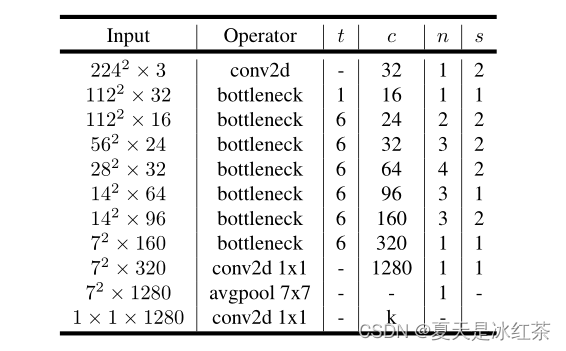
变量features会先对图片有3x3大小、步长为2d的卷积进行一个高和宽的压缩。接下来会进入一个列表的循环,t表示是否进行1*1卷积上升的过程,c表示output_channel大小,n表示小列表倒残差次数,s是步长,表示是否对高和宽进行压缩。
那么这样来看,如果最初图片为(512,512,3),经过features后,在经过循环列表会有这样的处理。
- 输入features:512,512,3 -> 256, 256, 32
- 第1次循环:256, 256, 32 -> 256, 256, 16
- 第2次循环:256, 256, 16 -> 128, 128, 24
- 第3次循环:128, 128, 24 -> 64, 64, 32
- 第4次循环:64, 64, 32 -> 32, 32, 64
- 第5次循环:32, 32, 64 -> 32, 32, 96
- 第6次循环:32, 32, 96 -> 16, 16, 160
- 第7次循环:16, 16, 160 -> 16, 16, 320
接着会用1x1卷积调整通道数,完成features的建立。
论文给出的:
Pytorch实现Mobilenetv2主干网络
import math
import torch.nn as nn
BatchNorm2d = nn.BatchNorm2d
def conv_bn(inp, oup, strides):
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size=(3,3), stride=strides, padding=1, bias=False),
BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size=(1,1), stride=(1,1), padding=0, bias=False),
BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
assert input_size % 32 == 0
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * width_mult) if width_mult > 1.0 else last_channel
self.features = [conv_bn(3, input_channel, 2)]
for t, c, n, s in interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
self.features = nn.Sequential(*self.features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, n_class),
)
self.initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.mean(3).mean(2)
x = self.classifier(x)
return x
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def mobilenetv2(pretrained=False, **kwargs):
model = MobileNetV2(n_class=1000, **kwargs)
if pretrained:
pass
return model
if __name__ == "__main__":
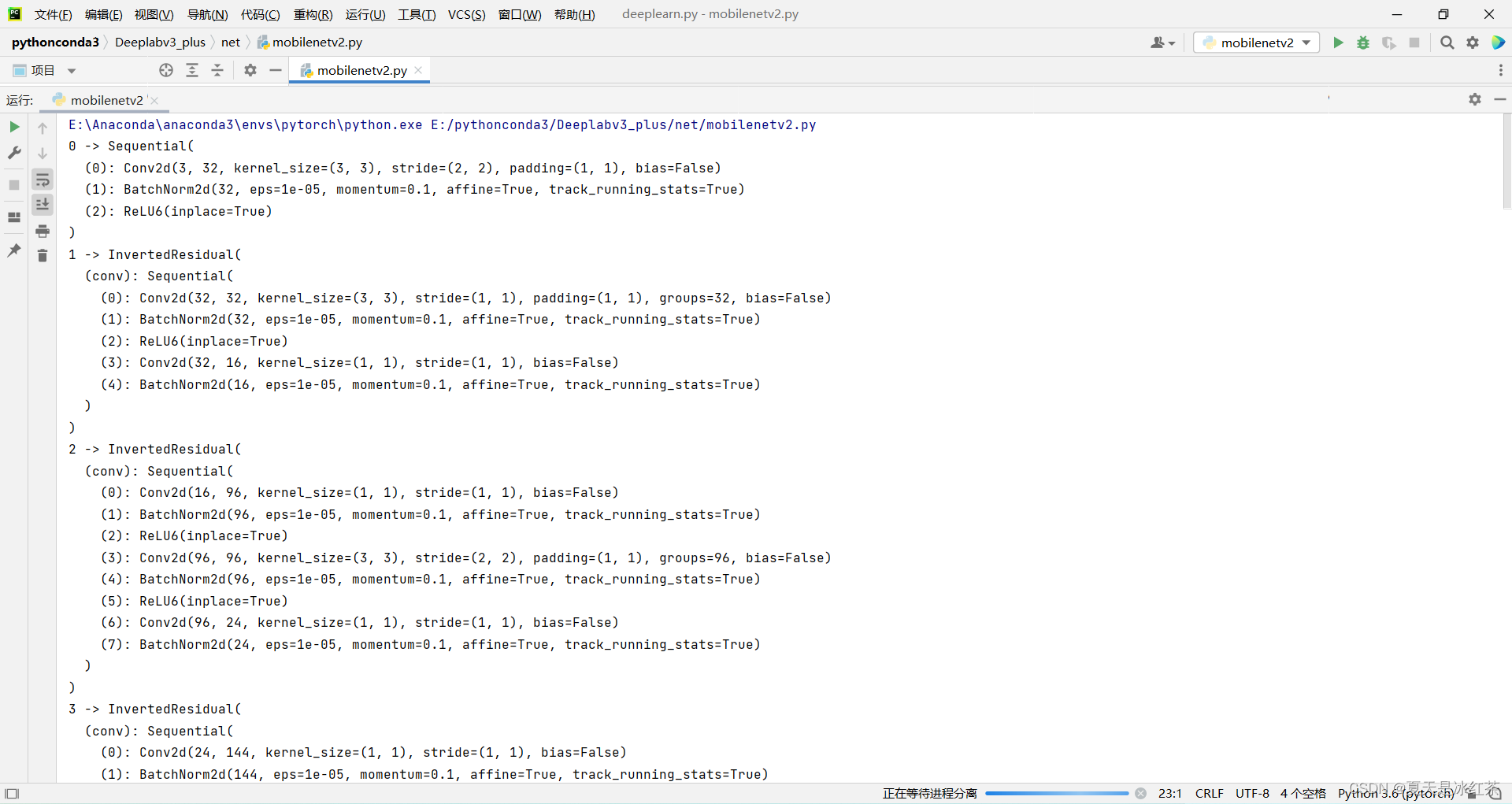
model = mobilenetv2()
for i, layer in enumerate(model.features):
print(i, '->', layer)
运行成功,至此mobielnetv2的搭建完成
相关参考资料
DeepLabV3-/Mobilenetv2.pdf at main · Auorui/DeepLabV3- (github.com)
MobileNet_v2模型解读
MobileNet_v2模型解读——知乎
憨批的语义分割重制版9——Pytorch 搭建自己的DeeplabV3+语义分割平台







![[Python从零到壹] 番外篇之可视化利用D3库实现CSDN博客每日统计效果(类似github)](https://img-blog.csdnimg.cn/15efe1ed83884d8c8c542b3feb57b9f4.jpeg#pic_center)