上回我们介绍了传统定时任务与分布式任务调度的差异以及它们的优缺点,本节我们使用Xxl-job来实现相关需求。
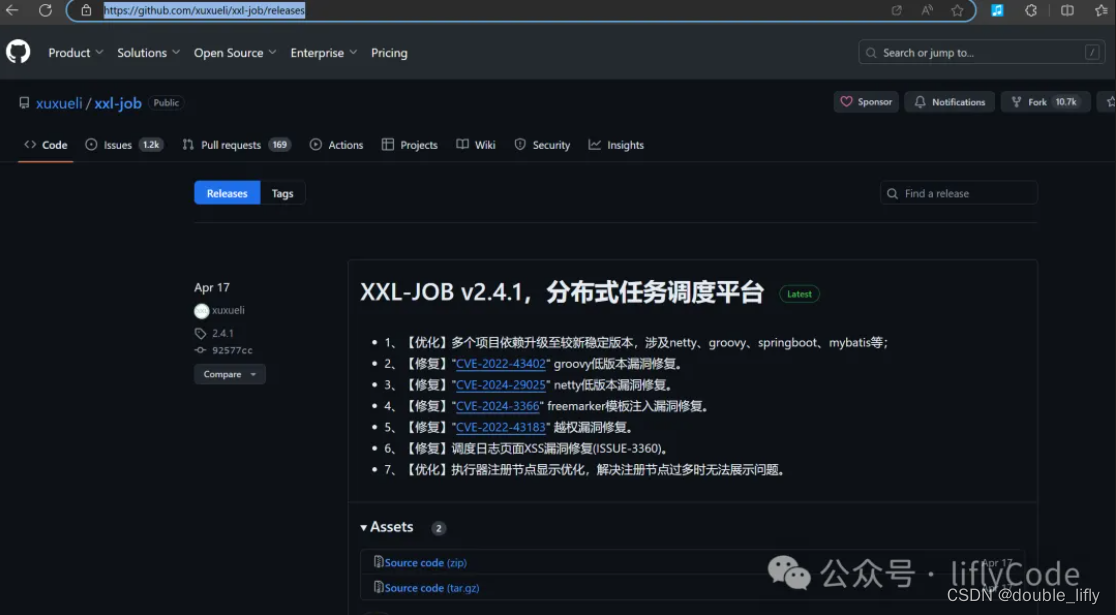
首先我们需要下载Xxl-job对应的服务端;下面是Xxl-job的github地址:
Releases · xuxueli/xxl-job (github.com)
版本我们选择V-2.3.0版本。
本地解压导入idea编译器中,并配置数据源:
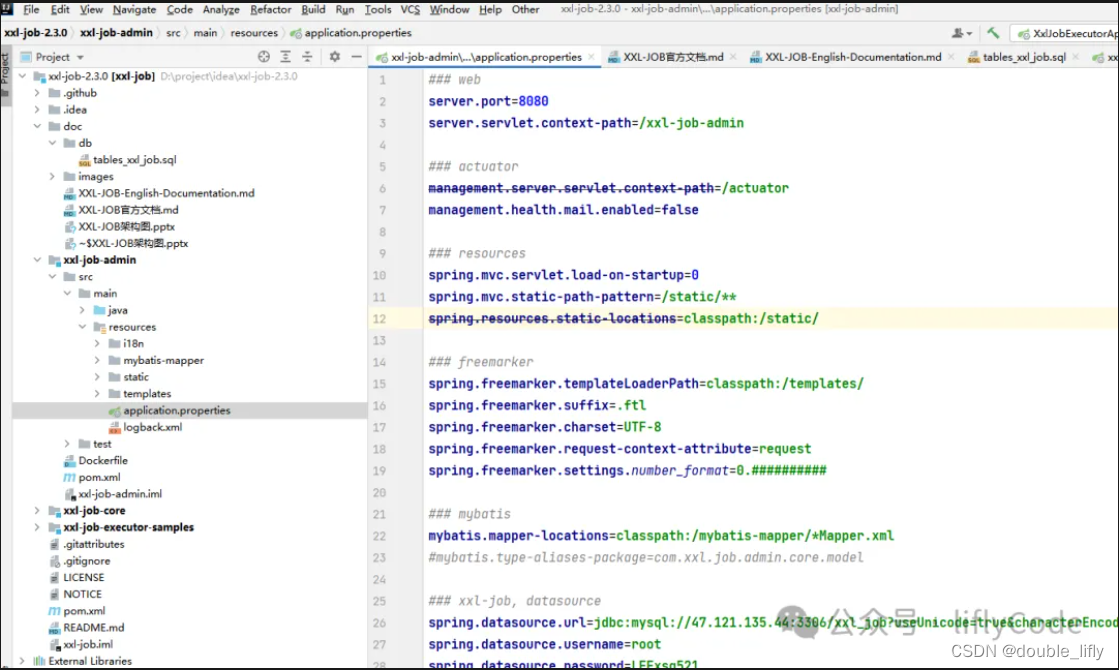
在xxl-job-admin模块中application.properties中进行配置:
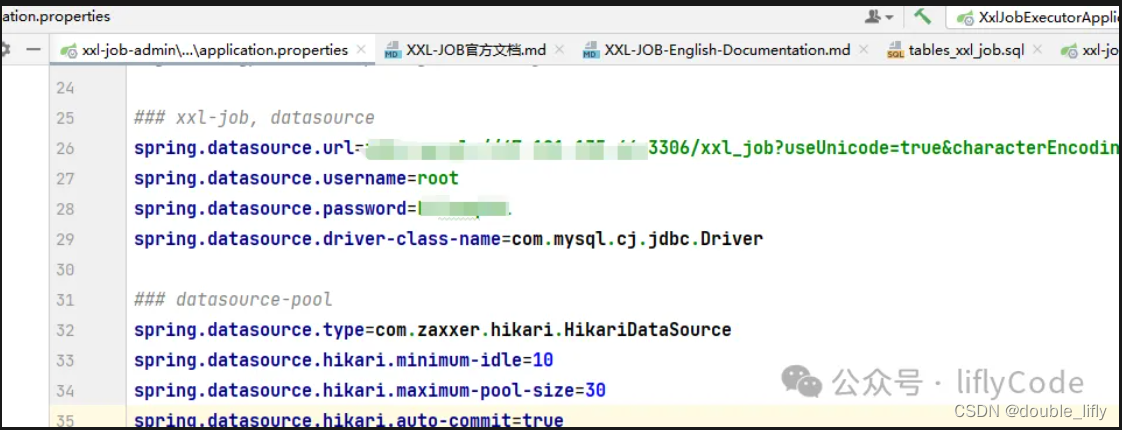
在配置文件中,我们除了可以配置数据源之外,还可以配置邮件告警信息,就是说当任务执行失败,给已发送邮件给对应的开发去排查相关问题。
为了安全考虑,我们还可以配置token:
配置完成后,我们还需要将xxl-job为我们提供的数据表导入数据库中,相关的sql文件在doc/db目录下:
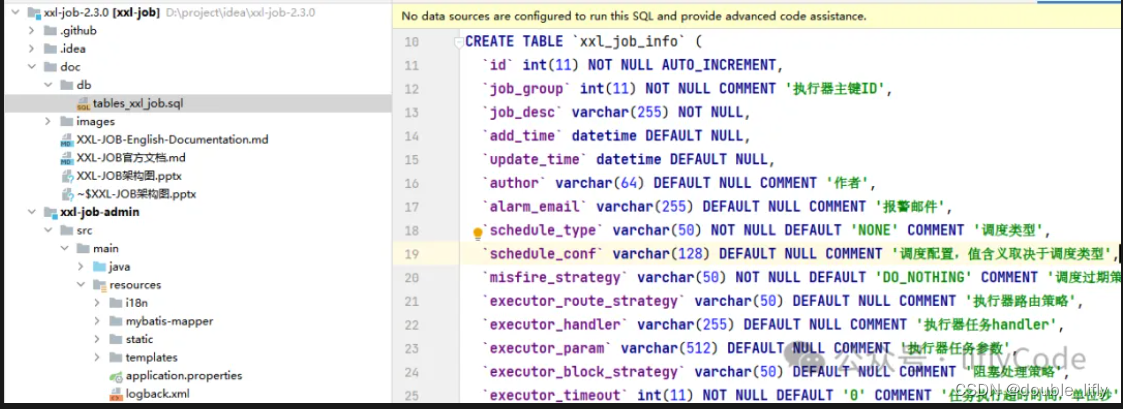
执行以上sql文件到数据库中:
当以上步骤完成后,我们就可以启动xxl-job,访问端口可以查看我们的服务端了。
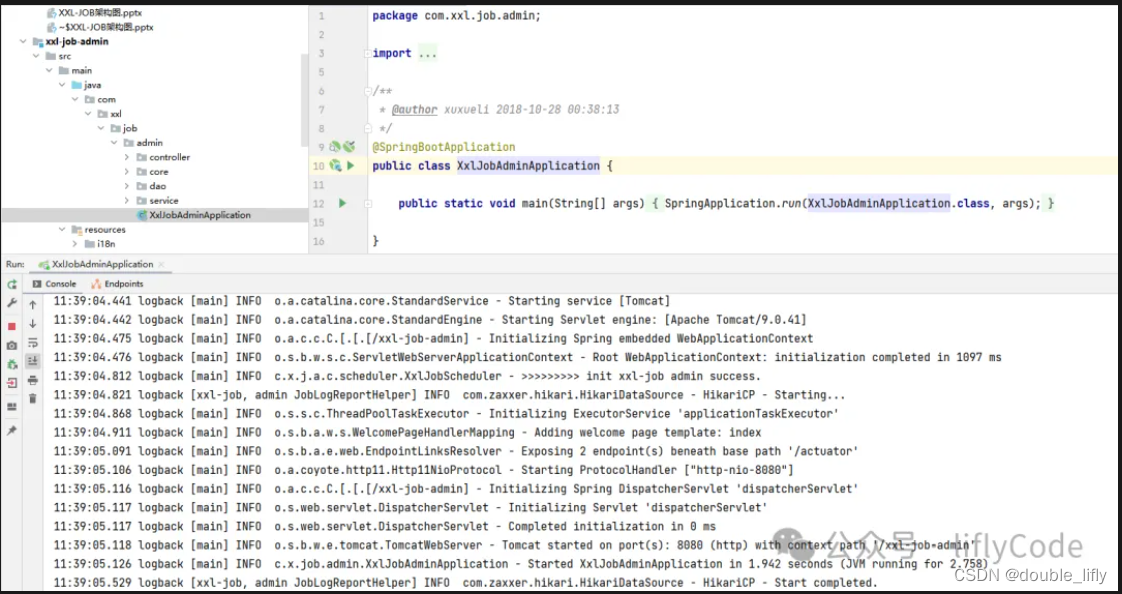
可以看到我们的服务端已经启动成功,下面我们来访问一下:
localhost:8080/xxl-job-admin;账号密码为:admin/123456
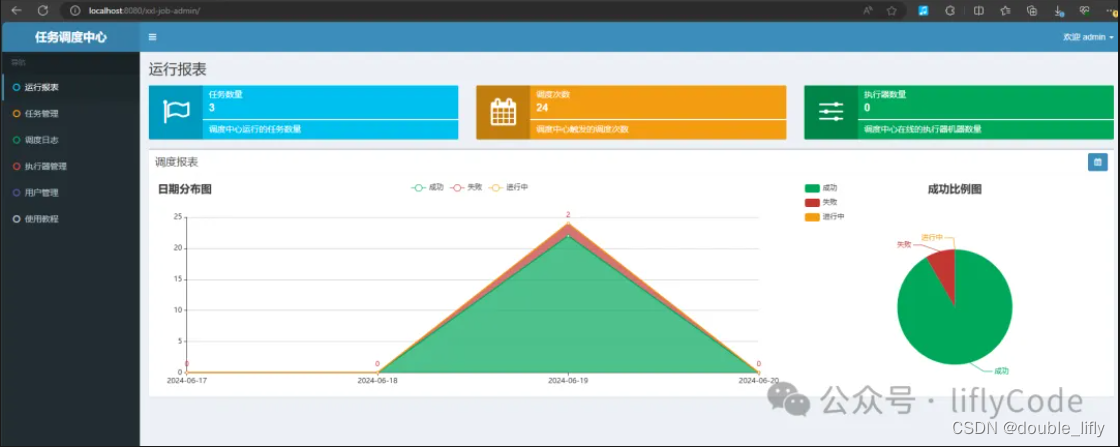
可以看到服务部署成功了。到此先暂停下,先梳理下xxx-job部署的步骤,有哪些点需要注意。
下面我们去开发我们对应的需求。
首先进入我们自己的项目中,导入xxl-job相关依赖:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
添加配置文件,这里我是用的yml形式的配置文件,当然你们也可以使用application.properties配置文件,两者不冲突哦。
xxl:
job:
accessToken: # 这个要跟服务断我们配置的token一致
admin:
# 部署的服务端地址
addresses: http://192.168.31.25:8080/xxl-job-admin
executor:
# address可以不写,可以在服务端配置执行器选择自动注册就好了
# address: 192.168.31.25:8080
appname: xdclass-user-xxl-job
# ip: 192.168.31.25
logpath: ./data/logs/xxl-job/executor
logretentiondays: 30
# 注册的端口,默认是9999
port: 8893
下面我们需要开发一个配置文件来读取上面的配置:
/**
* @Author: LiFly
* @Date: 2024/6/19 15:50
* @Description:
*/
@Configuration
@Slf4j
public class XxlJobConfig {
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.admin.addresses}")
private String adminAddress;
@Value("${xxl.job.executor.appname}")
private String appName;
// @Value("${xxl.job.executor.ip}")
// private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logretentionDays;
@Bean
public XxlJobSpringExecutor xxlJobSpringExecutor(){
log.info(">>>>>>>>>>>>>>>>>>>>>>>>>>>xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddress);
xxlJobSpringExecutor.setAppname(appName);
// xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogRetentionDays(logretentionDays);
return xxlJobSpringExecutor;
}
}
大致就长成这样,配置类开发好,我们就可以来编写个demo来测试下:
/**
* @Author: LiFly
* @Date: 2024/6/19 16:00
* @Description:
*/
@Component
public class MyJobHandler {
private final Logger log = LoggerFactory.getLogger(MyJobHandler.class);
@Autowired
private UserService userService;
@XxlJob("userJobHandler")
public ReturnT<String> execute(String param){
JsonData jsonData = userService.detail(1798667808547328001L);
log.info("myJobHandler data={}",jsonData.getData().toString());
return ReturnT.SUCCESS;
}
private void init(){
log.info(" init success >>>>>>>>>>>>");
}
private void destroy(){
log.info(" destory success >>>>>>>>>>>>>");
}
}
上面的job就是说要查询id为1798667808547328001L的详细信息。开发好我们的demo后,我们就可以启动项目,登录xxl-job-admin来配置我们的任务调度器。
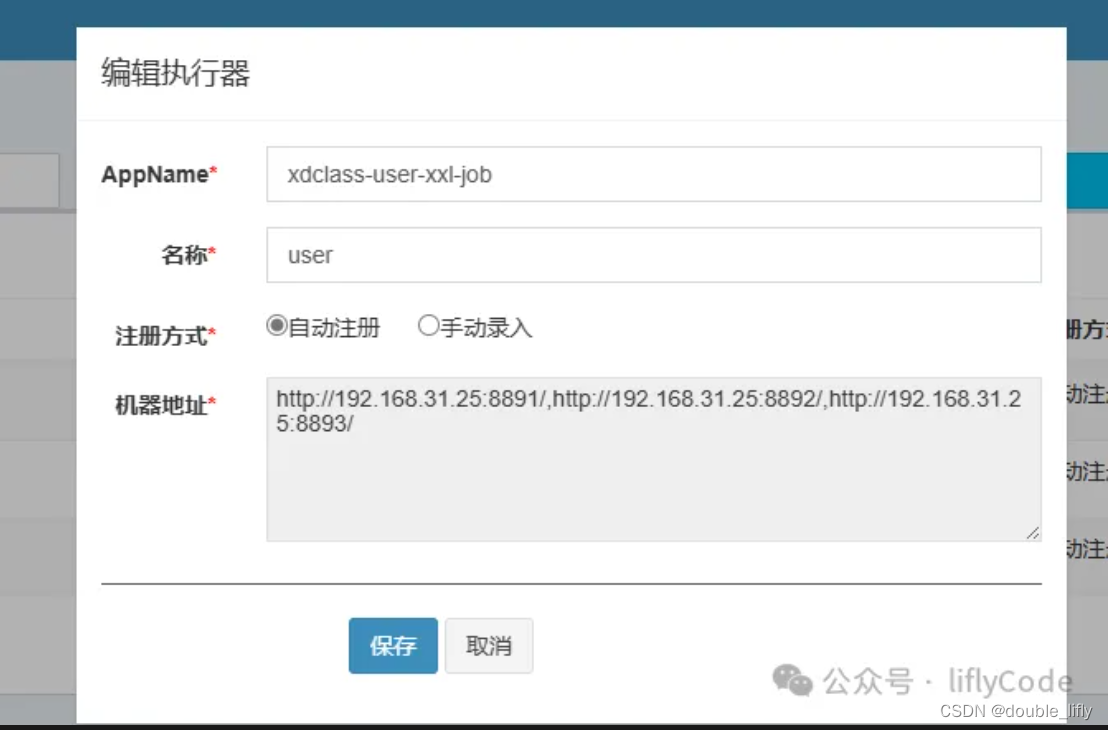
在执行器管理中,我们选择新增执行器。
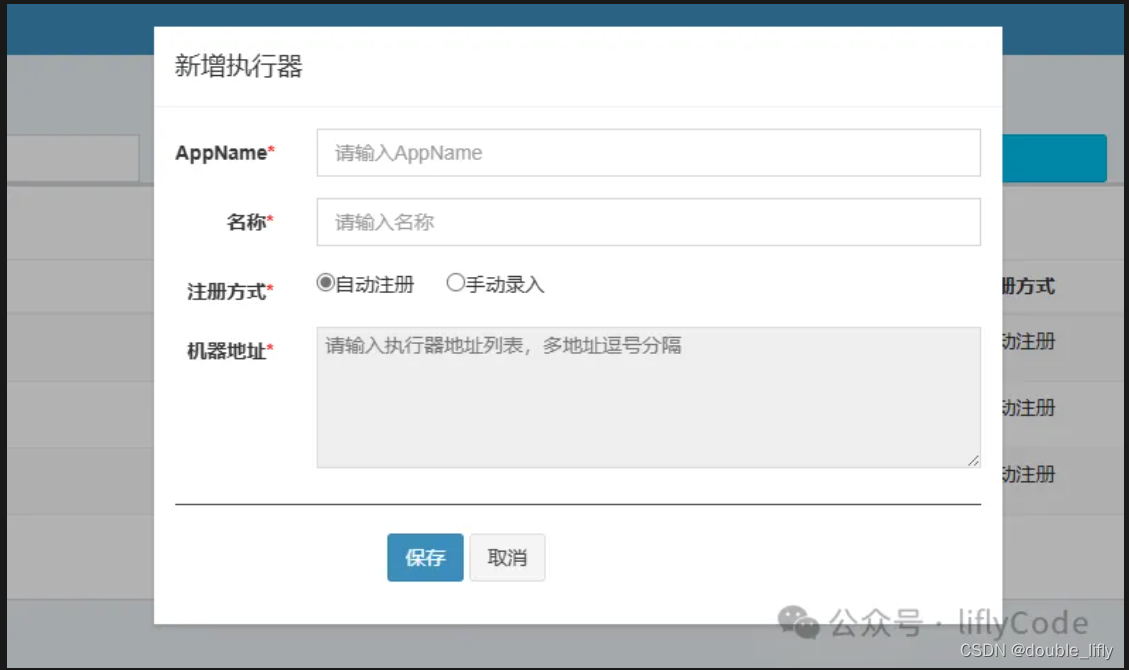
AppName:与我们的配置文件一致:xdclass-user-xxl-job
名称就自己取一个就可以了,注册方式我们选择自动注册,也可以手动录入,看自己选择就可以了,选择保存,我们来到任务管理,选择添加任务。

执行器要与我们刚刚创建的执行器名称对应上哈。点击新增:
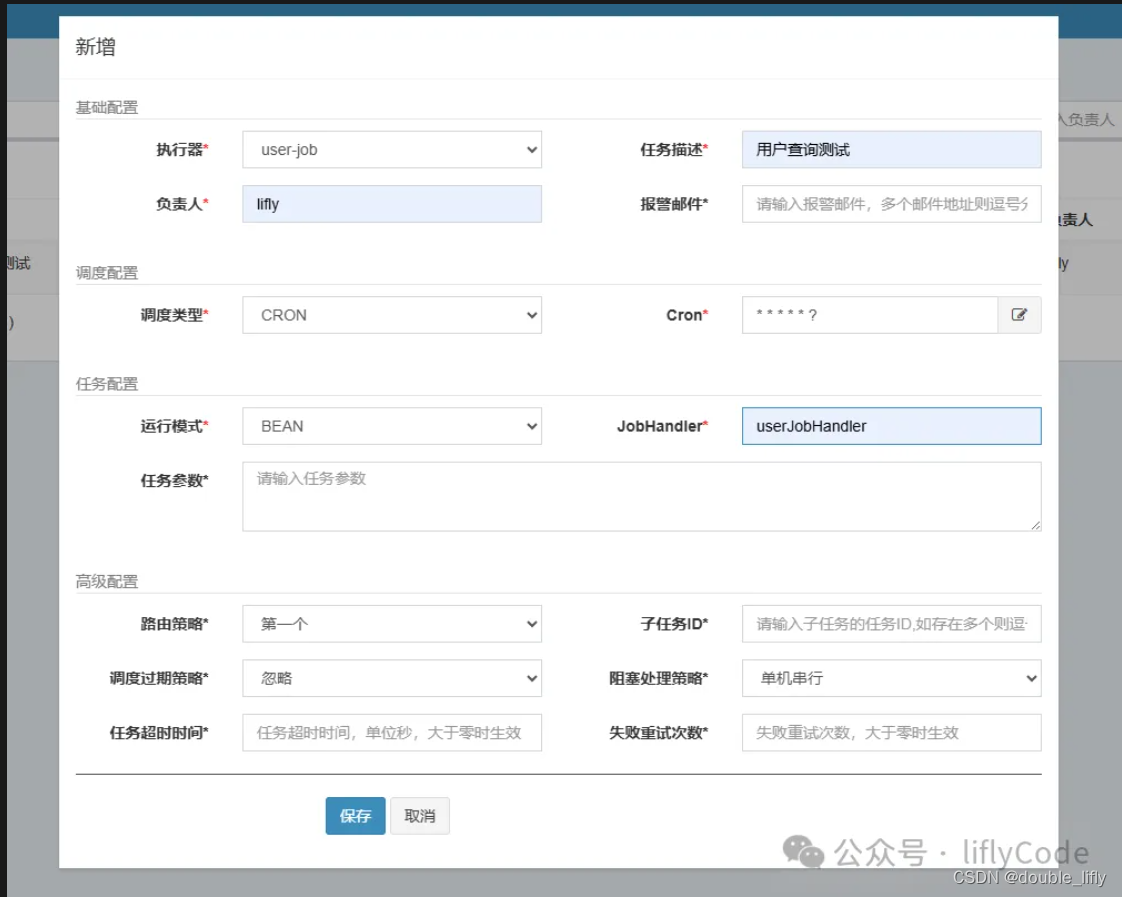
这里我们填写对应的任务描述,负责人;其他的默认就行,JobHandler名称就是我们在项目中开发的任务名称:userJobHandler;然后我们选择保存。下面就是见证奇迹的时刻了;回到任务管理,点击操作,我们选择执行一次,然后我们去调度日志中查看日志:
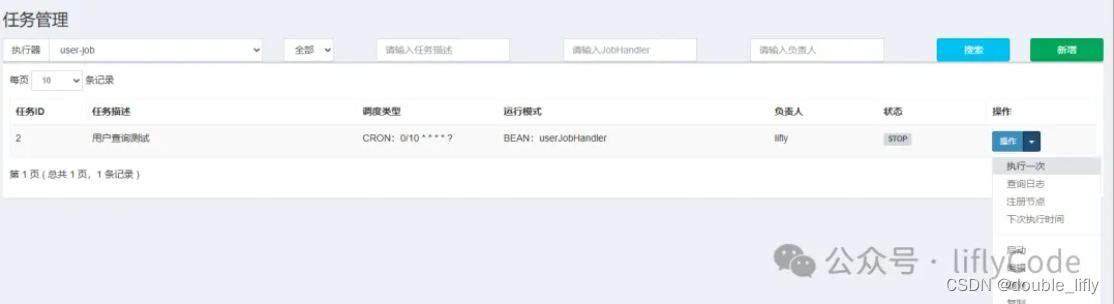
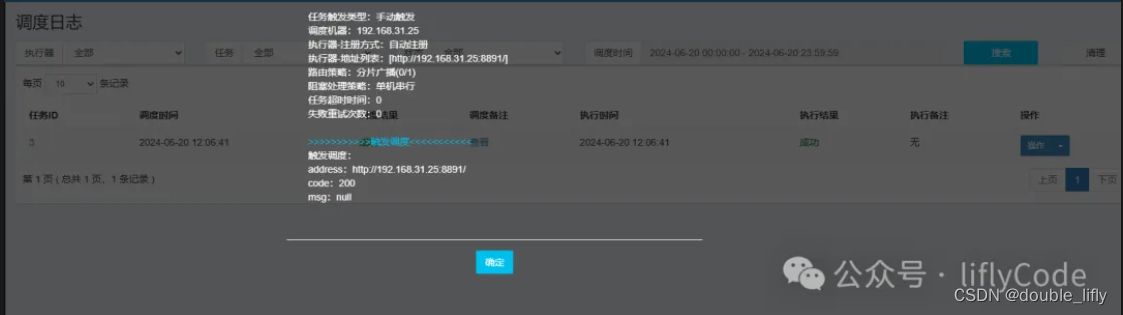 我们可以看到执行成功,下面我们来到我们的项目看下刚才执行的日志:
我们可以看到执行成功,下面我们来到我们的项目看下刚才执行的日志:
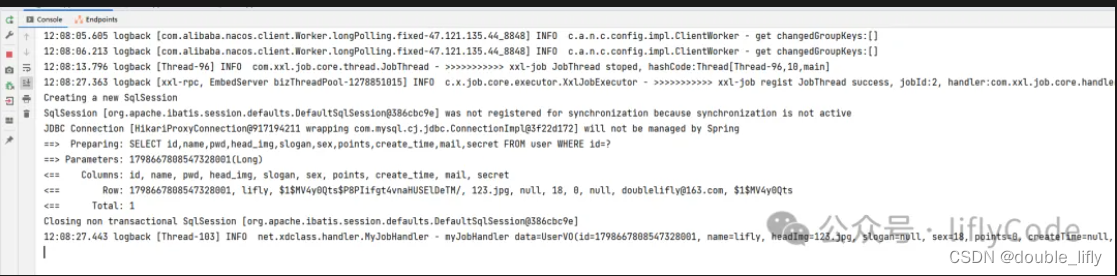
可以看到,我们控制台也打印了相关日志,说明我们的demo执行成功了。到此我们的xxl-job服务端和客户端都已部署成功了,也测试成功了。
下面我们来开发我们的需求,在开发需求之前我们还需要了解下xxl-job中的分片任务,并以此来开发我们的需求。
分片任务:
-
执行器集群部署,如果任务的路由策略选择【分片广播】,一次任务调度将会【广播触发】对应集群中所有执行器执行一次任务,同时系统自动传递分片参数,执行器可根据分片参数开发分片任务
-
需要处理的海量数据,以执行器为划分,每个执行器分配一定的任务数,并行执行
-
XXL-Job支持动态扩容执行器集群,从而动态增加分片数量,到达更快处理任务
-
分片的值是调度中心分配的
// 当前分片数,从0开始,即执行器的序号
int shardIndex = XxlJobHelper.getShardIndex();
//总分片数,执行器集群总机器数量
int shardTotal = XxlJobHelper.getShardTotal();
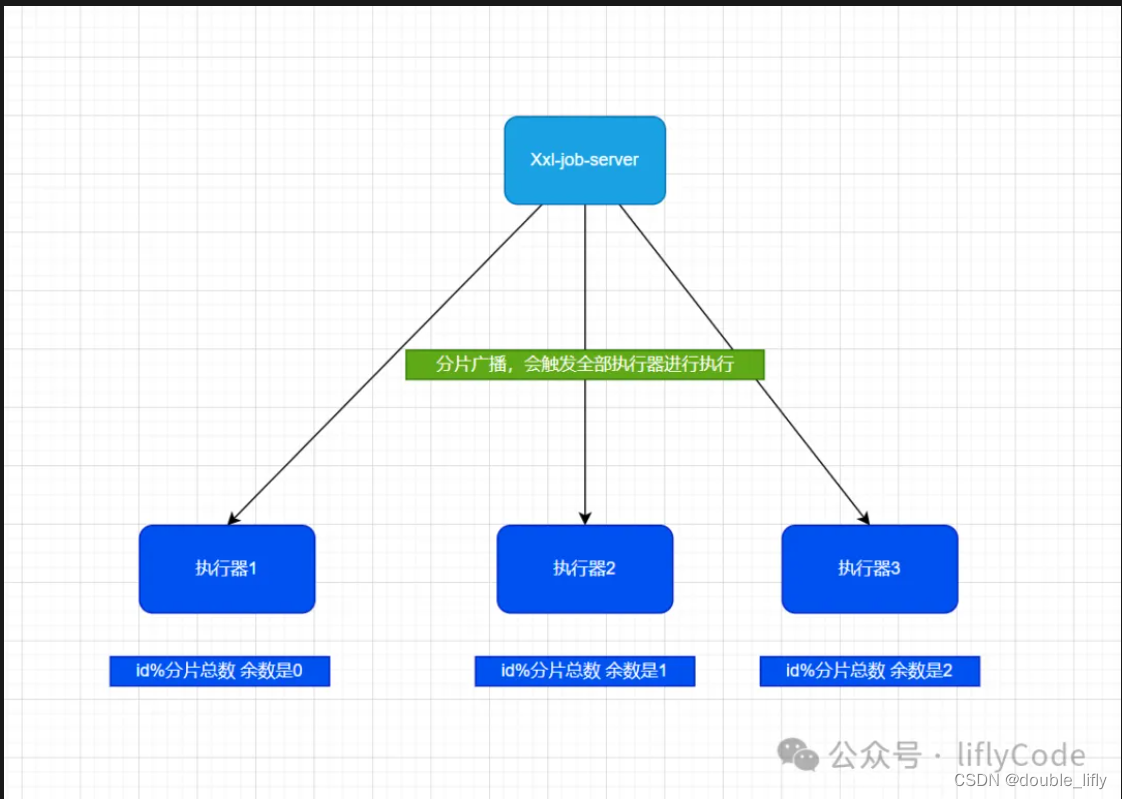
我们的需求是:构建一个分布式短信发送系统,应对双十一活动需向1000万用户快速推送营销短信的挑战,每条数据的业务处理逻辑为0.1s。对于普通任务来说,只有一个线程来处理 可能需要10万秒才能处理完,业务则严重受影响。
如果将1000万用户数据分发达10台机器,采用分片广播策略,只需要1万秒就可以了。
下面我们来模拟1000用户,分片处理,在项目中新开发一个job
@XxlJob("shardingJobHandler")
public void shardingJobHandler(){
//获取当前执行器编号
int shardIndex = XxlJobHelper.getShardIndex();
//总的分片数,就是执行器的集群数量
int shardTotal = XxlJobHelper.getShardTotal();
log.info("分片总数shardTotal={},当前分片数shardIndex={}",shardTotal,shardIndex);
List<Integer> allUserIds = getAllUserIds();
allUserIds.forEach(obj->{
if (obj % shardTotal == shardIndex){
log.info("第{}片,命中分片开始处理用户id={}",shardIndex,obj);
}
});
}
private List<Integer> getAllUserIds() {
List<Integer> ids = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
ids.add(i);
}
return ids;
}
下面我们模拟3台集群,同一个服务分别不同端口来启动,注册端口也需要不同,第一个服务端口为8991,注册端口为8891;第二个服务服务端口为8992,注册端口为8892;第三额服务端口为8993,注册端口为8893;分别启动服务;
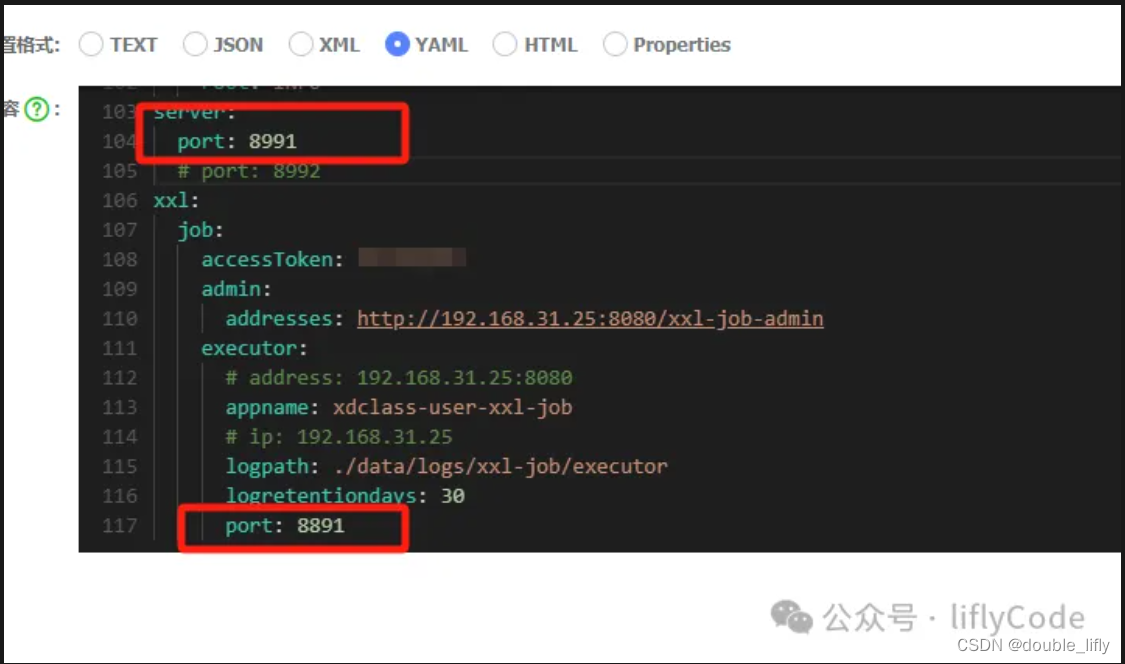

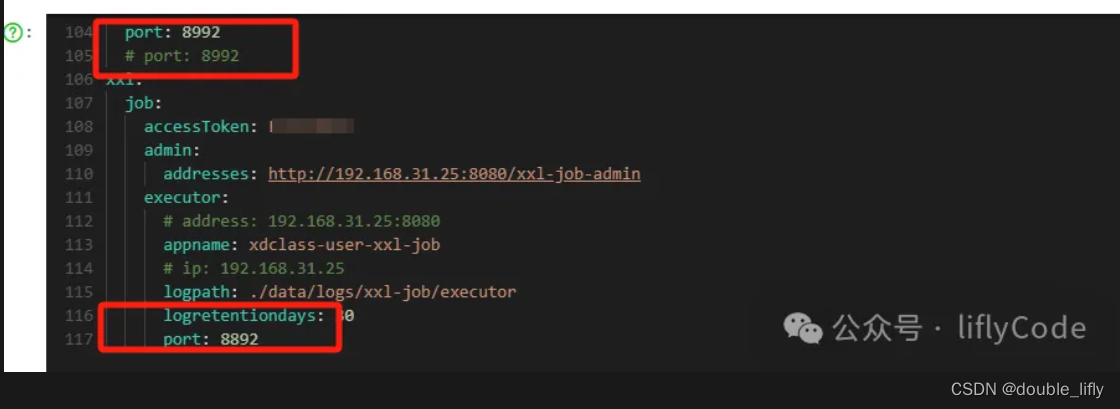

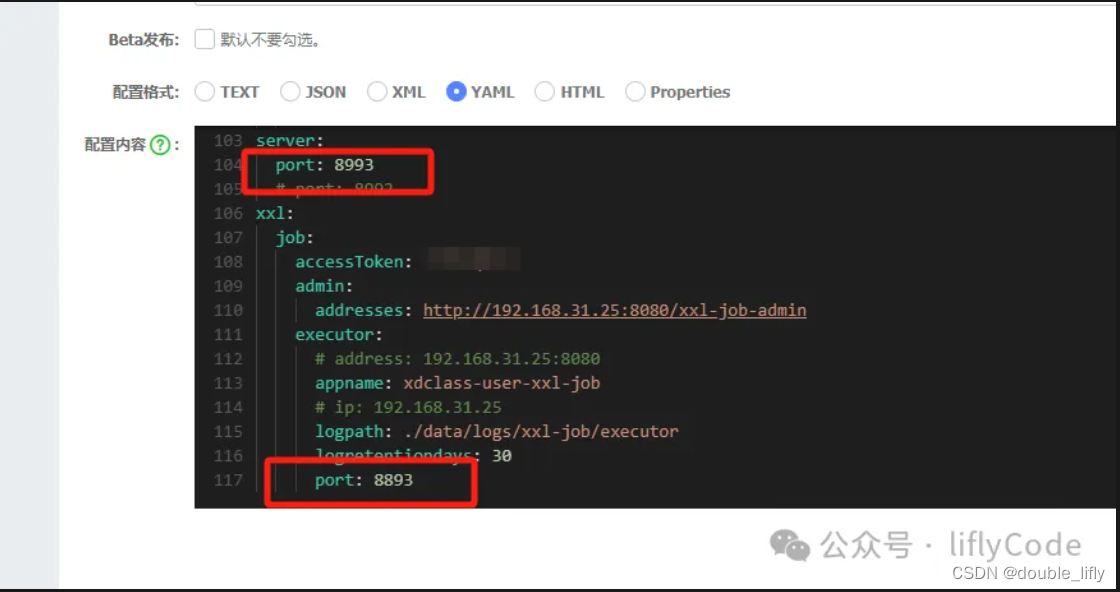

下面我们登录xxl-job-admin创建执行器,配置任务管理器,
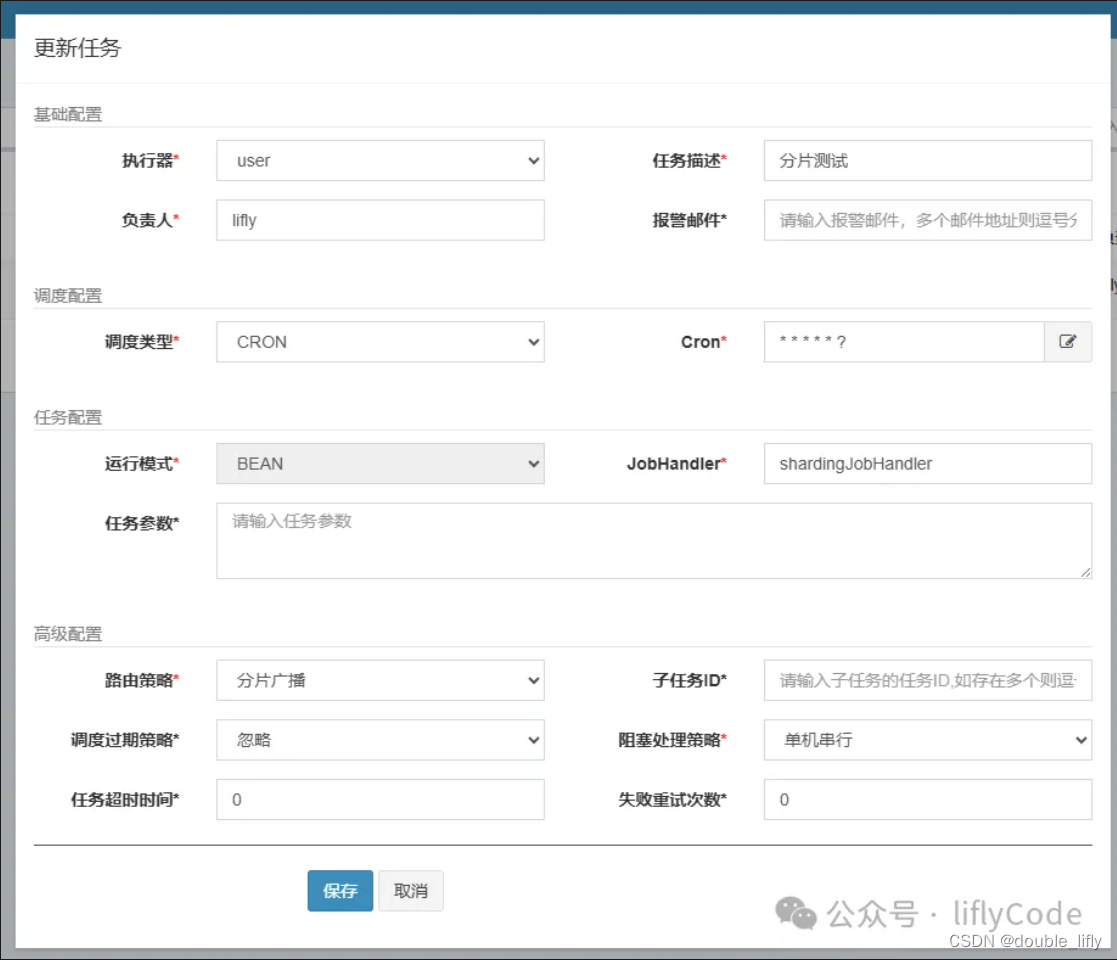
点击操作中的执行一次,我们去看下控制台打印的信息:
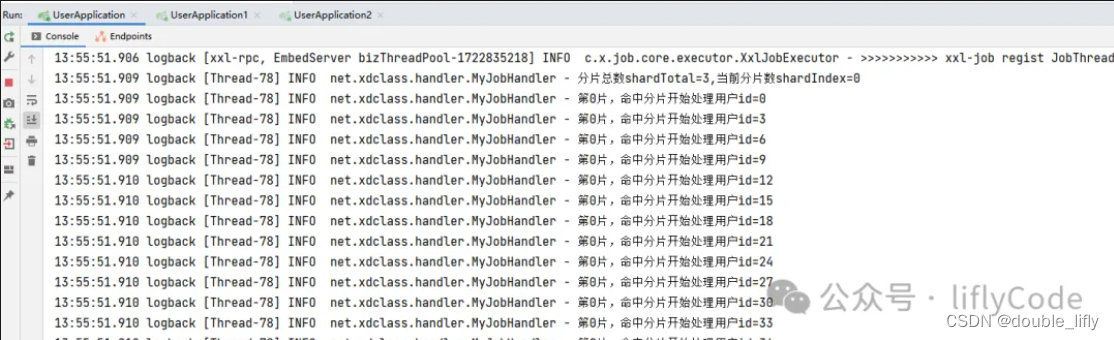
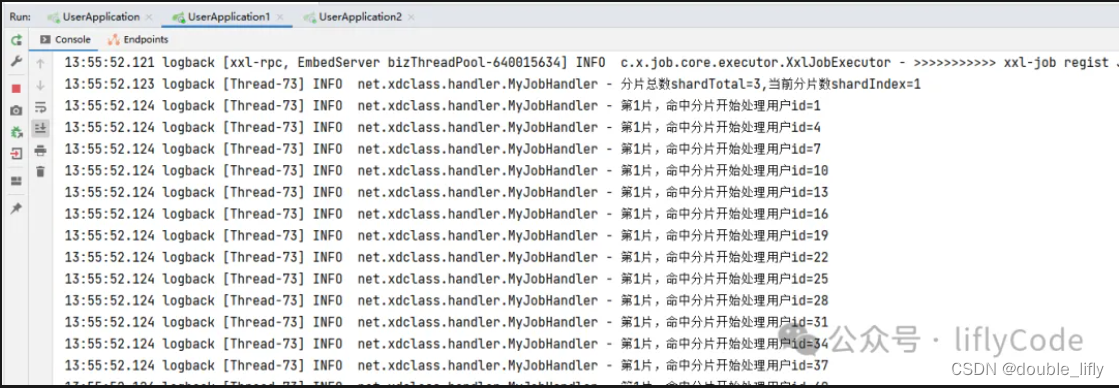
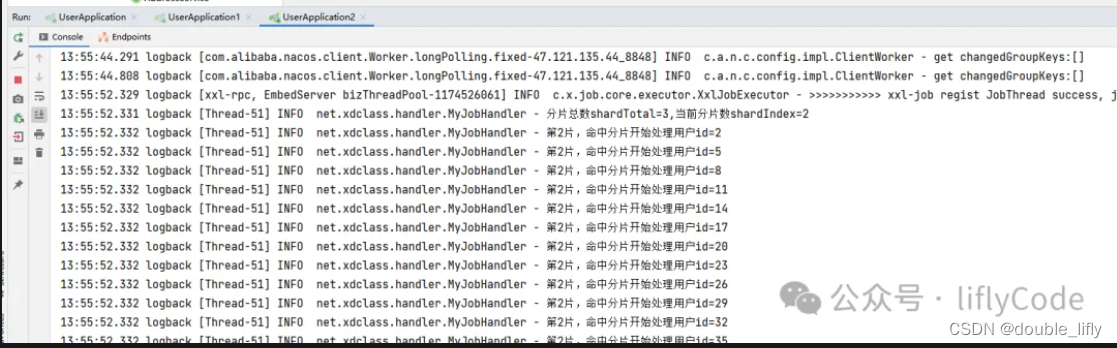
通过以上测试我们实现了分片处理1000条数据数据,3台处理器执行。从而可以更快地处理任务。
经过细致的部署与实践,我们不仅成功搭建了基于XXL-Job的分布式短信发送系统雏形,还深入探索了其分片任务的强大功能,为应对双十一等大规模营销活动的短信推送挑战提供了强有力的技术支撑。从XXL-Job服务端的快速部署、客户端项目的无缝集成,到分片策略的巧妙运用,每一步都展现了XXL-Job在处理高并发、大数据量任务上的灵活性与高效性。
通过模拟1000用户数据的分片处理,我们见证了任务在分布式环境下的加速执行过程。仅需简单的配置与代码调整,即可实现任务在多台服务器间的智能分配,显著提升了处理速度,将原本单一任务可能需要的漫长执行时间缩短至更合理的范畴。这一过程不仅验证了分片广播策略的有效性,也为后续扩展至1000万用户的真实场景奠定了坚实的基础。
总结而言,XXL-Job不仅是一款功能强大的分布式任务调度框架,更是一个促进系统架构优化、提升业务响应速度的有力工具。通过本次实践,我们深刻体会到了合理的任务分片与分布式部署对于应对大规模数据处理的重要性,为构建高性能、高可用的短信发送系统提供了宝贵的经验。未来,随着系统的不断优化与扩展,相信XXL-Job将继续发挥其核心作用,助力企业技术栈在复杂业务需求面前游刃有余,从容不迫。
更多内容,请关注一下公众号: