目录
量化原理
为什么需要量化?
量化粒度
框架综述
算子划分
量化中的图融合操作
量化实践:以pytorch mobilenet v2 模型为例
源码阅读
torch模型和onnx量化过程中的区别
后记
量化原理
为什么需要量化?
1、减少内存带宽和存储空间
深度学习模型主要是记录每个 layer(比如卷积层/全连接层) 的 weights 和 bias, FP32 模型中,每个 weight 数值原本需要 32-bit 的存储空间,量化之后只需要 8-bit 即可。因此,模型的大小将直接降为将近 1/4。
不仅模型大小明显降低, activation 采用 8-bit 之后也将明显减少对内存的使用,这也意味着低精度推理过程将明显减少内存的访问带宽需求,提高高速缓存命中率,尤其对于像 batch-norm, relu,elmentwise-sum 这种内存约束(memory bound)的 element-wise 算子来说,效果更为明显。
2、提高系统吞吐量(throughput),降低系统延时(latency)
直观理解,试想对于一个 专用寄存器宽度为 512 位的 SIMD 指令,当数据类型为 FP32 而言一条指令能一次处理 16 个数值,但是当我们采用 8-bit 表示数据时,一条指令一次可以处理 64 个数值。因此,在这种情况下,可以让芯片的理论计算峰值增加 4 倍。在CPU上,英特尔至强可扩展处理器的 AVX-512 和 VNNI 高级矢量指令支持低精度和高精度的累加操作。
量化粒度
量化粒度是指共享量化参数的大小,例如 每个 Tensor 共享一组量化参数,那么量化的粒度为 per-tensor。量化的粒度越小,模型的精度越好,但计算成本越高。
-
per-tensor:整个神经网络层用一组量化参数(scale, zero-point)
-
per-channel:一层神经网络每个通道用一组量化参数(scale, zero-point)。那么就是per-channel需要存更多的量化参数,对的计算速度也有一点影响。在深度学习中,张量的每一个通道通常代表一类特征,因此可能会出现不同的通道之间数据分布较大的情况。对于通道之间差异较大的情况仍然使用张量级的量化方式可能对精度产生一定的影响,因此通道级量化就显得格外重要。
为了获得最大的性能,考虑到整数矩阵乘法,量化的粒度应该是:
-
对于激活的量化,由于性能原因,推荐per-tensor
-
对于权重的量化,per-channel和per-tensor都行
可以想象到per-channel量化很明显细粒度更高,所以一般来说效果会更好,但当前主流的量化仍然是权重和激活都采用per-tensor量化。
框架综述
整个框架可以分成三部分:
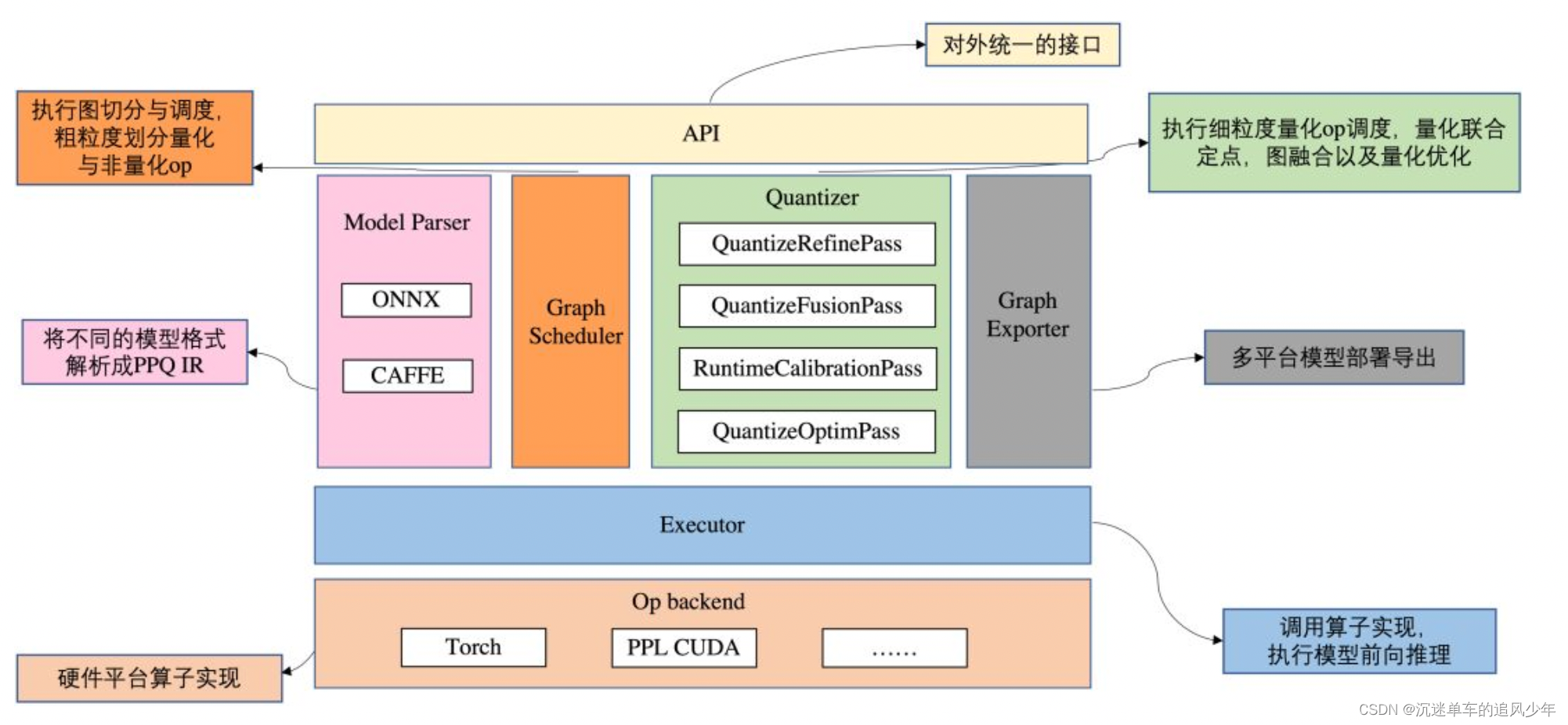
PPQ Paser 模块可读取 onnx 或 caffe 模型,并解析成内部格式。解析完成后,Scheduler 模块对模型进行切分与调度,粗颗粒度地划分量化与非量化算子。
Quantizer 模块是 PPQ 量化执行的中枢,为模型算子分配特定的部署平台,并初始化量化设置,调用各种优化 Pass,完成量化联合定点、图融合及量化优化。
Executor 模块依据模型拓扑关系,调用底层算子实现,执行前向推理。模型量化完成后,调用 Exporter 模块,导出模型和量化参数。
算子划分
PPQ 使用 graph dispatcher 将图中所有算子划分为三类:
-
不可量化区:这区域的算子与 shape或者 index 有关,一旦量化将导致图的计算发生错误,因此不可量化,同时默认被调度到 Host 端以浮点精度执行。
-
可量化区:这区域的算子被认为是可以量化的,它们是 input, conv, gemm 的延伸算子,PPQ 使用数值追踪技术标记这些算子,这些算子处理的运算一定是 input, conv, gemm 的计算结果。它们被调度到设备端以 int8 精度执行。
-
争议区:这区域的算子同时接收来自不可量化区以及可量化区的输入,所有争议区的算子延伸也是争议算子,量化这些算子是有风险的,PPQ 不能保证量化产生的影响。该区算子被调度到设备端以浮点精度执行。
为了找出这些区域,PPQ 使用图搜索引擎进行区域划分,其基本思想是通过枚举所有算子的计算情况,确定输入的来源是否与 shape 或 index 相关。你可以通过 ppq.scheduler 中的代码看到它们的具体实现。
在 PPQ 中,我们实现了三种不同的调度逻辑,不同的调度逻辑将产生不同的区域划分:
-
激进式调度:该调度方法将所有争议区算子视作可量化的。
-
保守式调度:该调度方法将所有争议区算子视作不可量化的(它们依然将被调度到设备端)。
-
pplnn:该调度方法只量化卷积层与其相关算子。
量化中的图融合操作
硬件精度未对齐的主要原因在于 —— 推理库后端会对模型做大量的联合定点和图融合优化,我们写入的量化参数已被后端融合或修改,量化模拟与后端推理并不一致,导致优化算法大打折扣。
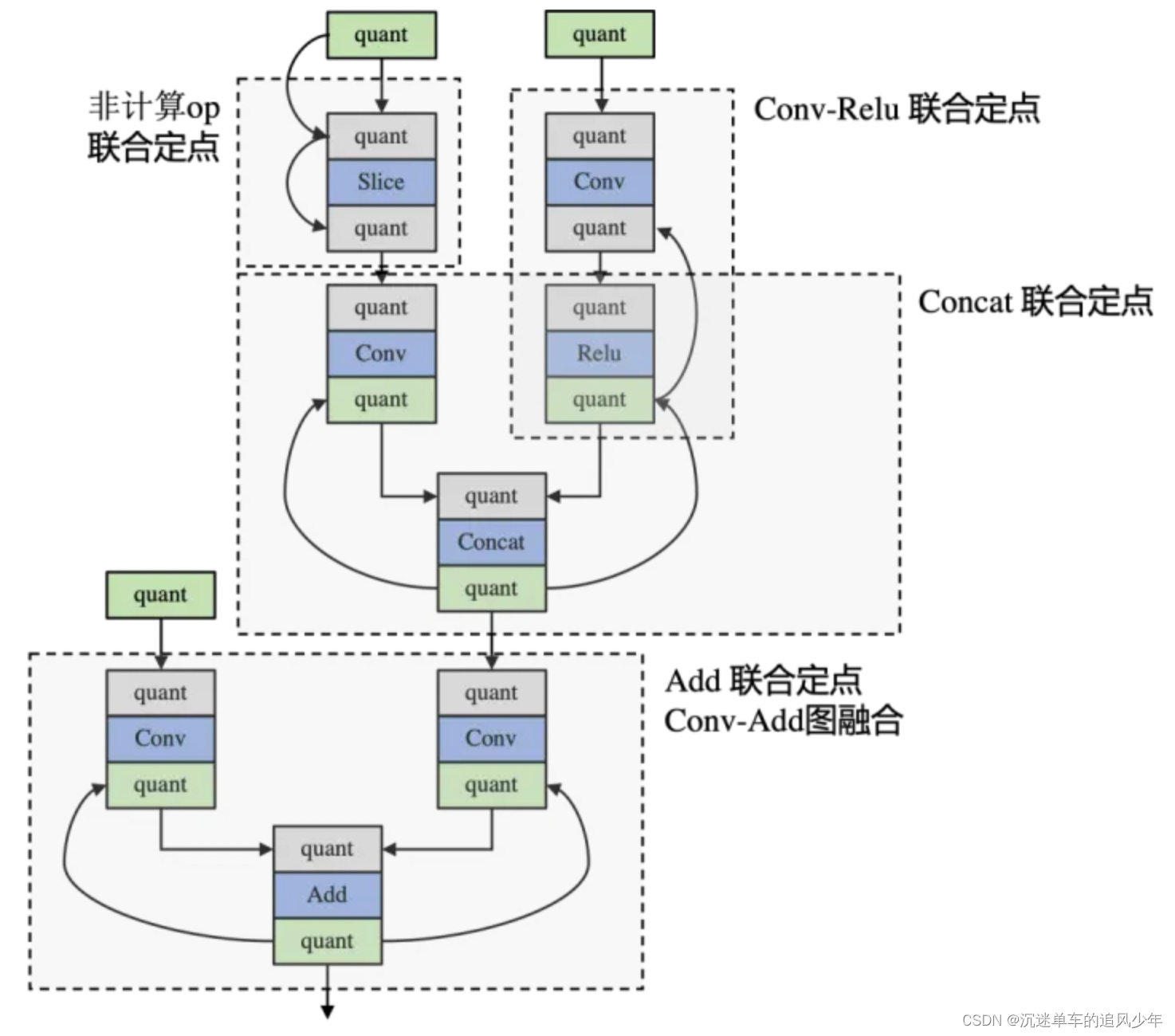
PPQ 使用 Tensor Quantization Config 类来描述算子数值量化的细节,其绑定在算子之上。
Executor 模块执行每一个算子时,并不会在模型中插入量化节点,而是通过一种类似于 hook 的形式,直接将量化操作添加到算子的执行逻辑中。模型算子输入/输出变量是否量化,由算子输入/输出的 Tensor Quantization Config 的 state 属性决定。
量化实践:以pytorch mobilenet v2 模型为例
首先按照官方教程安装ppq:ppq/quantize_torch_model.py at master · openppl-public/ppq · GitHub
我是使用 Install PPQ from source 方法安装的,直接安装会报错,可能是库之间相互依赖的问题,把requirements.txt文件中的onnx >= 1.9.0改成onnx == 1.9.0即可。
官方提供了一份完整的例子地址:ppq/quantize_torch_model.py at master · openppl-public/ppq · GitHub
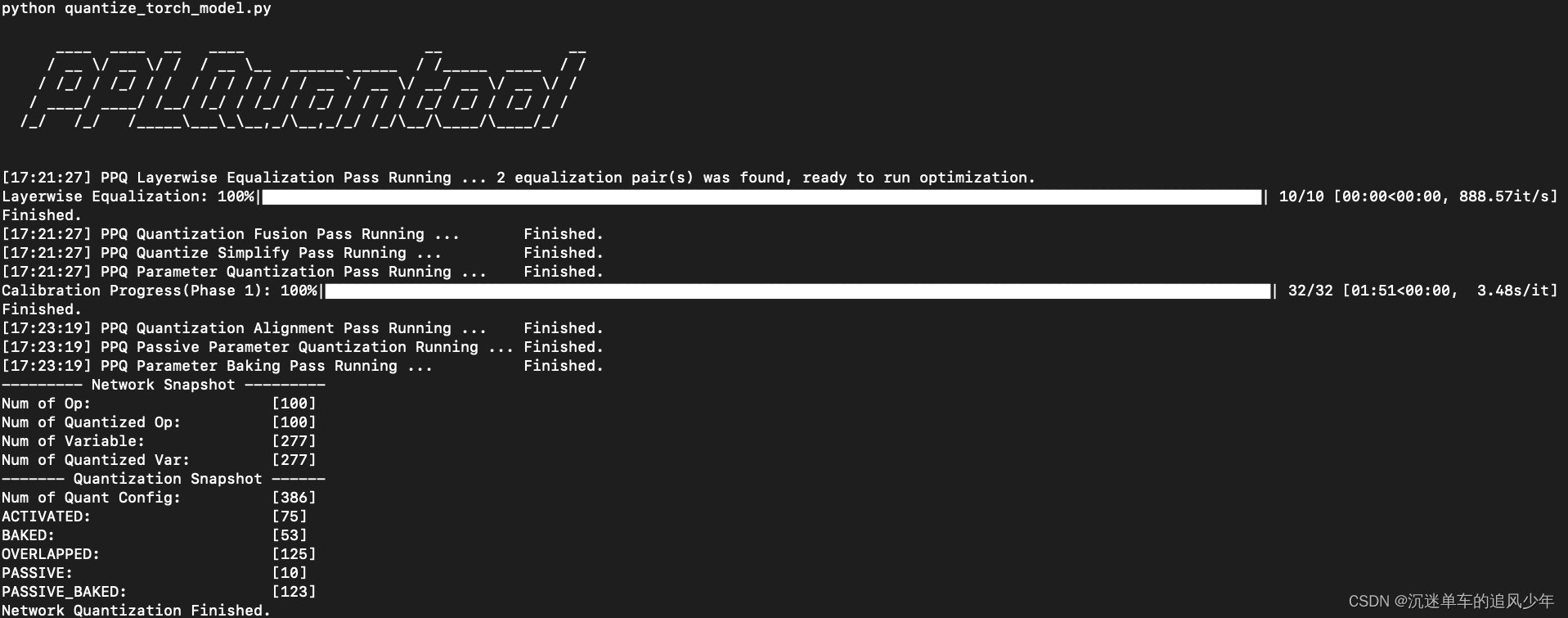
打开文件openppl/ppq/ppq/samples运行脚本python quantize_torch_model.py,注意运行前新建一个文件夹Output存放量化后的模型。
源码阅读
跑通了这个例子我们再来阅读一下源代码。
因为是静态离线量化,所以需要少量的校准数据,这里用随机生成的方法生成校准数据:
def load_calibration_dataset() -> Iterable:
return [torch.rand(size=INPUT_SHAPE) for _ in range(32)]加载pytorch内置的mobilenet V2模型,如果本地cache没有找到的话,会自动下载模型的配置和权重:
model = torchvision.models.mobilenet.mobilenet_v2(pretrained=True)
model = model.to(DEVICE)PPL需要创建一个 QuantizationSetting 对象用来管理量化过程,这个是由QuantizationSettingFactory实现的:
# create a setting for quantizing your network with PPL CUDA.
quant_setting = QuantizationSettingFactory.pplcuda_setting()
quant_setting.equalization = True # use layerwise equalization algorithm.
quant_setting.dispatcher = 'conservative' # dispatch this network in conservertive way.
这里设置了三项:
- 用cuda设置
- 采用分层均衡算法,这个貌似是这篇论文的,还没细看:https://hailo.ai/wp-content/uploads/2021/03/Exploring-Neural-Networks-Quantizationvia-Layer-Wise-Quantization-Analysis.pdf
- 以保守的方式调度这个网络,将所有争议区算子视作不可量化的
ppq针对torch模型都封装起来了,只需要调用quantize_torch_model()即可。如果是onnx模型,需要手动自建图调度,最后一样都要使用export_ppq_graph()导出计算图。
# quantize your model.
quantized = quantize_torch_model(
model=model, calib_dataloader=calibration_dataloader,
calib_steps=32, input_shape=[BATCHSIZE] + INPUT_SHAPE,
setting=quant_setting, collate_fn=collate_fn, platform=PLATFORM,
onnx_export_file='Output/onnx.model', device=DEVICE, verbose=0)
# Quantization Result is a PPQ BaseGraph instance.
assert isinstance(quantized, BaseGraph)
# export quantized graph.
export_ppq_graph(graph=quantized, platform=PLATFORM,
graph_save_to='Output/quantized(onnx).onnx',
config_save_to='Output/quantized(onnx).json')torch模型和onnx量化过程中的区别
onnx模型会直接调用quantize_onnx_model(),torch模型会调用quantize_onnx_model(),这个函数会先执行torch转onnx操作,然后再调用quantize_onnx_model():
@ empty_ppq_cache
def quantize_torch_model(
model: torch.nn.Module,
calib_dataloader: DataLoader,
calib_steps: int,
input_shape: List[int],
platform: TargetPlatform,
input_dtype: torch.dtype = torch.float,
setting: QuantizationSetting = None,
collate_fn: Callable = None,
inputs: List[Any] = None,
do_quantize: bool = True,
onnx_export_file: str = 'onnx.model',
device: str = 'cuda',
verbose: int = 0,
) -> BaseGraph:
"""量化一个 Pytorch 原生的模型 输入一个 torch.nn.Module 返回一个量化后的 PPQ.IR.BaseGraph.
quantize a pytorch model, input pytorch model and return quantized ppq IR graph
Args:
model (torch.nn.Module): 被量化的 torch 模型(torch.nn.Module) the pytorch model
calib_dataloader (DataLoader): 校准数据集 calibration dataloader
calib_steps (int): 校准步数 calibration steps
collate_fn (Callable): 校准数据的预处理函数 batch collate func for preprocessing
input_shape (List[int]): 模型输入尺寸,用于执行 jit.trace,对于动态尺寸的模型,输入一个模型可接受的尺寸即可。
如果模型存在多个输入,则需要使用 inputs 变量进行传参,此项设置为 None
a list of ints indicating size of input, for multiple inputs, please use
keyword arg inputs for direct parameter passing and this should be set to None
input_dtype (torch.dtype): 模型输入数据类型,如果模型存在多个输入,则需要使用 inputs 变量进行传参,此项设置为 None
the torch datatype of input, for multiple inputs, please use keyword arg inputs
for direct parameter passing and this should be set to None
setting (OptimSetting): 量化配置信息,用于配置量化的各项参数,设置为 None 时加载默认参数。
Quantization setting, default setting will be used when set None
inputs (List[Any], optional): 对于存在多个输入的模型,在Inputs中直接指定一个输入List,从而完成模型的tracing。
for multiple inputs, please give the specified inputs directly in the form of
a list of arrays
do_quantize (Bool, optional): 是否执行量化 whether to quantize the model, defaults to True, defaults to True.
platform (TargetPlatform, optional): 量化的目标平台 target backend platform, defaults to TargetPlatform.DSP_INT8.
device (str, optional): 量化过程的执行设备 execution device, defaults to 'cuda'.
verbose (int, optional): 是否打印详细信息 whether to print details, defaults to 0.
Raises:
ValueError: 给定平台不可量化 the given platform doesn't support quantization
KeyError: 给定平台不被支持 the given platform is not supported yet
Returns:
BaseGraph: 量化后的IR,包含了后端量化所需的全部信息
The quantized IR, containing all information needed for backend execution
"""
# dump pytorch model to onnx
dump_torch_to_onnx(model=model, onnx_export_file=onnx_export_file,
input_shape=input_shape, input_dtype=input_dtype,
inputs=inputs, device=device)
return quantize_onnx_model(onnx_import_file=onnx_export_file,
calib_dataloader=calib_dataloader, calib_steps=calib_steps, collate_fn=collate_fn,
input_shape=input_shape, input_dtype=input_dtype, inputs=inputs, setting=setting,
platform=platform, device=device, verbose=verbose, do_quantize=do_quantize)
返回的都是一个量化IR(中间表示),根据这个中间表示再去保存我们所需要的信息。
后记
openppl的中文文档和教程非常完善,堪比paddle,适合基于此学习模型量化。本篇博客是第一篇,大致了解了ppq的设计思想、框架结构,并通过一个简单的例子实践感受。后续的博客会继续探索openppl模型量化!