前言
大家早好、午好、晚好吖 ❤ ~

基本思路流程: <通用的>
一. 数据来源分析:
-
明确需求:
-
明确采集的网站是什么?
-
明确采集的数据是什么?
-
-
通过开发者工具<浏览器自带的工具(谷歌浏览器)>, 进行抓包分析
先分析一章内容, 然后再分析如何采集多章内容
-
打开开发者工具: F12 / 鼠标右键点击检查选择network
-
刷新网页: 让本网页的数据内容重新加载一遍
-
选择Img: 可以很快速找到图片链接
图片链接<单张>:
-
搜索关键字: 可以直接搜索相关数据内容来自于哪里
图片链接集合数据包<多张>:
-
实现多章内容采集 —> 分析多章集合数据包链接变化规律
通过对比: 主要改变参数: 章节ID --> 只要获取所有章节ID就可以获取所有内容了
—>无论是什么ID大部分情况, 都可以在目录页面找到<—
请求目录页url:
找图片链接 --> 图片合集链接 —> 主要改变参数章节ID —> 目录页面获取
-
二. 代码实现步骤
-
获取章节ID/章节名字/名字:
-
发送请求, 模拟浏览器对于url地址发送请求
请求链接: 目录页url
-
获取数据, 获取服务器返回响应数据
开发者工具: response
-
解析数据, 提取我们想要的数据内容
章节ID/章节名字/名字
- 获取图片链接:
-
发送请求, 模拟浏览器对于url地址发送请求
请求链接:

-
获取数据, 获取服务器返回响应数据
开发者工具: response
-
解析数据, 提取我们想要的数据内容
- 图片链接
-
保存数据
-
环境使用:
-
解释器版本 >>> python 3.8
-
代码编辑器 >>> pycharm 2021.2
模块使用:
-
requests >>> pip install requests 数据请求模块
-
parsel >>> pip install parsel 数据解析模块
代码展示
PS:完整源码如有需要的小伙伴可以加下方的群去找管理员免费领取

# 导入数据请求模块 --> 第三方模块, 需要安装 pip install requests
import requests
# 导入数据解析模块 --> 第三方模块, 需要安装 pip install parsel
import parsel
# 导入文件操作模块 --> 内置模块, 不需要安装
import os
url = 'https://www.******.com/208707/'
headers = {
# user-agent 用户代理, 表示浏览器基本身份信息 Chrome 浏览器名字 101.0.0.0 浏览器版本 Windows 电脑系统
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
源码、解答、教程、资料加Q君羊:261823976##
# 把获取下来html字符串数据内容<response.text>, 转换成可解析对象
selector = parsel.Selector(response.text) # <Selector xpath=None data='<html>\n <head>\n <title>网游之近战法师_网游...'>
name = selector.css('.de-info__box .comic-title::text').get()
file = f'{name}\\'
if not os.path.exists(file):
os.mkdir(file)
lis = selector.css('.chapter__list .chapter__list-box .chapter__item')
for li in list(reversed(lis)):
# 提取章节ID +为什么加的意思
chapter_id = li.css('a::attr(data-chapterid)').get()
# 提取章节名字
chapter_title = li.css('a::text').getall()[-1].strip()
link = f'https://comic.******.com/chapter/content/v1/?chapter_id={chapter_id}&comic_id=208707&format=1&quality=1&sign=5a5b72c44ad43f6611f1e46dd4d457bf&type=1&uid=61003965'
源码、解答、教程、资料加Q君羊:261823976##
json_data = requests.get(url=link, headers=headers).json()
num = 1
print(chapter_title)
for index in json_data['data']['page']:
# 字典取值
image = index['image']
img_content = requests.get(url=image).content
with open(file + chapter_title + str(num) + '.jpg', mode='wb') as f:
f.write(img_content)
num += 1
print(image)
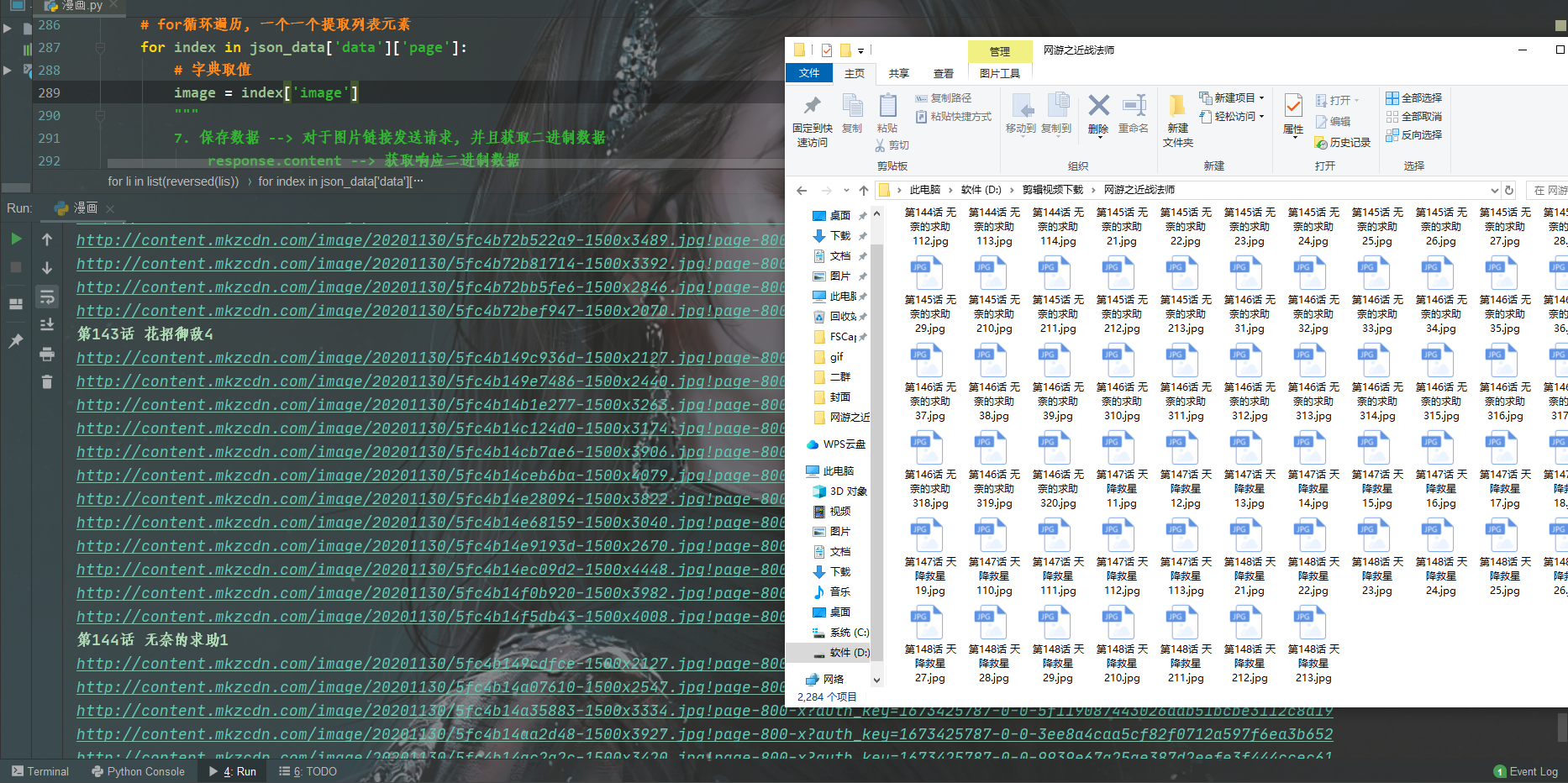
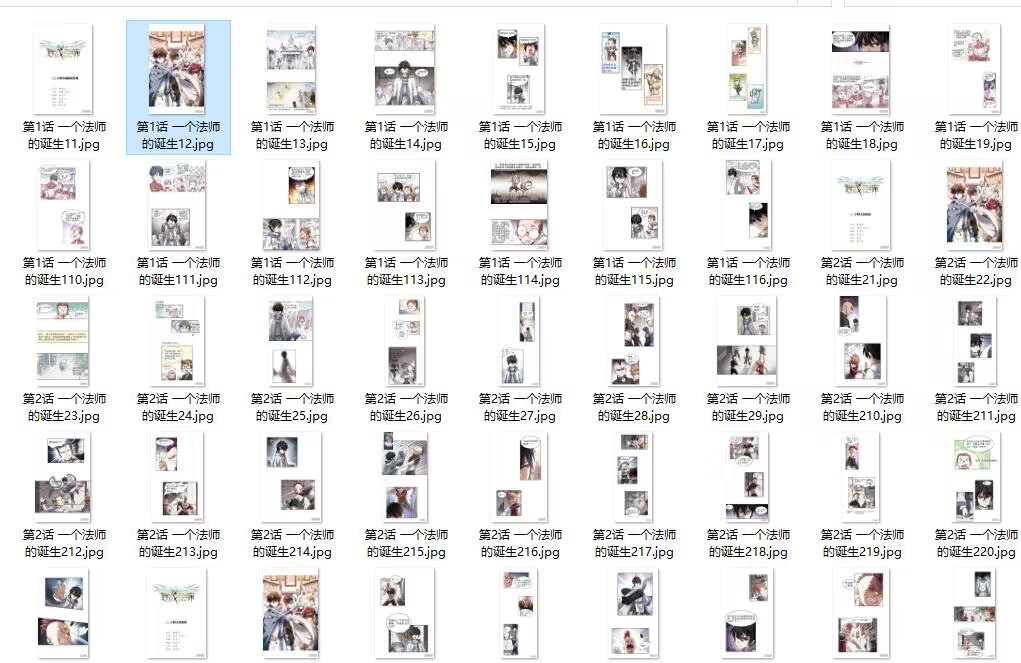
效果展示
尾语 💝
好了,今天的分享就差不多到这里了!
完整代码、更多资源、疑惑解答直接点击下方名片自取即可。
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!