文章目录
- 1.项目介绍
- 2.搜索引擎技术栈和项目环境
- 3.正排索引和倒排索引 - 搜索引擎具体原理
- 4.编写数据去标签和数据清洗模块Parser
- 5.编写建立索引模块Index
- 6.编写搜索引擎模块Searcher
- 7.编写http_server
- 8.效果展示
1.项目介绍
Boost官网没有对应的搜索引擎,不方便我们查看,本项目帮助我们搜索查阅Boost官方文档
2.搜索引擎技术栈和项目环境
技术栈:C/C++ C++11 STL 准标准库Boost 分词库cppjieba jsoncpp cpp-httplib库
项目环境:Centos7 云服务器,VsCode
3.正排索引和倒排索引 - 搜索引擎具体原理
文档1:雷军买了四斤小米
文档2:雷军发布了小米手机
正排索引:从文档ID找到文档内容
| 文档ID | 文档内容 |
|---|---|
| 1 | 雷军买了四斤小米 |
| 2 | 雷军发布了小米手机 |
倒排索引:根据关键字找到文档ID
| 关键字 | 文档ID |
|---|---|
| 雷军 | 文档1,文档2 |
| 买 | 文档1 |
| 四斤 | 文档1 |
| 小米 | 文档1,文档2 |
| 发布 | 文档2 |
| 小米手机 | 文档2 |
例如:模拟一次搜索关键字
小米->倒排索引中查找->提取出文档ID(1,2)->根据正排索引->找到文档内容->返回相应的结果
4.编写数据去标签和数据清洗模块Parser
1.下载官方手册的网页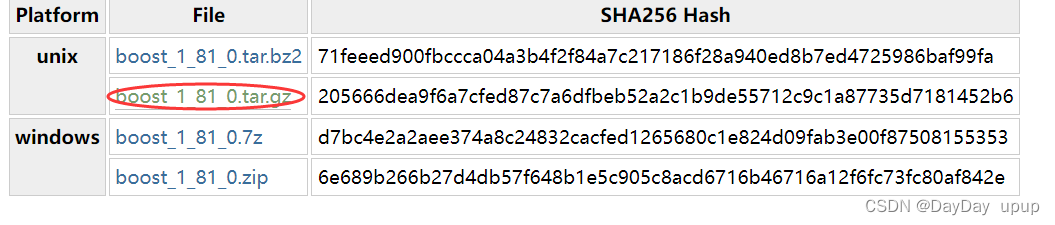
下载解压后就是官方网页的信息
例:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Chapter 41. Boost.Typeof</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="up" href="libraries.html" title="Part I. The Boost C++ Libraries (BoostBook Subset)">
<link rel="prev" href="boost_typeindex/acknowledgements.html" title="Acknowledgements">
<link rel="next" href="typeof/tuto.html" title="Tutorial">
</head>
2.去标签
<>:html的标签,我们需要去除的标签,一般为成对出对

将input中网页的信息,进行去标签后存入output中
目标:去标签后,文档之间用/3分割
整体代码框架
const std::string src_path = "data/input/html";
const std::string output = "data/output/raw.txt";
const std::string boost_root = "https://www.boost.org/doc/libs/1_81_0/doc/html";
struct DocInfo
{
/* data */
std::string title; // 文档的标题
std::string content; // 文档的主要内容
std::string url; // 文档在官网中URl
};
// 在src_path路径下所有的文件名称
bool EnumFile(const std::string &src_path, std::vector<std::string> *file_list);
// 把file_list中所有文档的主要内容取出
bool ParseHtml(const std::vector<std::string> &file_list, std::vector<DocInfo> *results);
// 把解析完毕的文件内容写入到output ,以/3为分隔符
bool SaveHtml(const std::string &output, const std::vector<DocInfo> &results);
int main()
{
// 在src_path路径下所有的文件名称
std::vector<std::string> file_lists;
if (EnumFile(src_path, &file_lists) == false)
{
std::cerr << "EnumFile error" << std::endl;
exit(1);
}
// 把file_list中所有文档的主要内容取出
std::vector<DocInfo> results;
if (ParseHtml(file_lists, &results) == false)
{
std::cerr << "ParseHtml error" << std::endl;
exit(1);
}
// 把解析完毕的文件内容写入到output ,以/3为分隔符
if (SaveHtml(output, results) == false)
{
std::cerr << "SaveHtml error" << std::endl;
exit(1);
}
return 0;
}
EnumFile实现
Boost库的安装不做过多介绍
static bool EnumFile(const std::string &src_path, std::vector<std::string> *file_list)
{
//Boost官方提供的文件操作
namespace fs = boost::filesystem;
fs::path root_path(src_path);
if (!fs::exists(root_path))
{
std::cerr << "fs::exists:" << src_path << std::endl;
exit(1);
}
fs::recursive_directory_iterator end;
for (fs::recursive_directory_iterator it(root_path); it != end; ++it)
{
if (!fs::is_regular_file(*it))
continue;
if (it->path().extension() != ".html")
continue;
// std::cout<<"debug:"<<it->path().string()<<std::endl;
file_list->emplace_back(it->path().string());
}
return true;
}
ParseHtml实现
读取文件操作
namespace ns_util
{
class FileUtil
{
public:
static bool ReadFile(const std::string& file,std::string* content)
{
std::ifstream ifs(file.c_str());
std::string tmp;
while(std::getline(ifs,tmp))
{
*content+=tmp;
}
return true;
}
};
}
bool ParseHtml(const std::vector<std::string> &file_lists, std::vector<DocInfo> *results)
{
for (const std::string &file_list : file_lists)
{
// 读取每个文档所有的内容
std::string content;
ns_util::FileUtil::ReadFile(file_list, &content);
DocInfo doc;
// 取出标题
if (ParseTitle(content, &doc) == false)
{
std::cerr << "ParseTitle error" << std::endl;
}
// 取出主要内容
if (ParseContent(content, &doc) == false)
{
std::cerr << "ParseContent error" << std::endl;
}
// 取出url
if (ParseUrl(file_list, &doc) == false)
{
std::cerr << "ParseContent error" << std::endl;
}
results->emplace_back(doc);
}
取出标题
static bool ParseTitle(const std::string &content, DocInfo *doc)
{
size_t begin = content.find("<title>");
if (begin == std::string::npos)
{
return false;
}
size_t end = content.find("</title>");
if (end == std::string::npos)
{
return false;
}
std::string title;
size_t len = strlen("<title>");
title = content.substr(begin + len, end - begin-len);
doc->title.swap(title);
return true;
}
取出主要内容
static bool ParseContent(const std::string &content, DocInfo *doc)
{
enum status
{
LABLE,
CONTENT
};
enum status s = LABLE;
std::string con;
for (auto c : content)
{
switch (s)
{
case LABLE:
{
if(c == '>')
s = CONTENT;
break;
}
case CONTENT:
{
if(c == '<')
{
s = LABLE;
continue;
}
if(c=='\n')
c=' ';
con+=c;
break;
}
default:
{
break;
}
}
}
doc->content.swap(con);
return true;
}
取出url
官网的url:https://www.boost.org/doc/libs/1_81_0/libs/beast/doc/html/index.html
当前路径:data/input/html/index.html
只要加粗的地方相加就能得到官网的url
const std::string boost_root = "https://www.boost.org/doc/libs/1_81_0/doc/html"
static bool ParseUrl(const std::string &file_list, DocInfo *doc)
{
size_t len = src_path.size();
std::string url;
url+=boost_root;
url+=file_list.substr(len);
doc->url.swap(url);
return true;
}
把解析完毕的文件内容写入到output ,以/3为分隔符
bool SaveHtml(const std::string &output, const std::vector<DocInfo> &results)
{
#define SEP '\3'
std::ofstream out(output,std::ios::out | std::ios::binary);
if(out.is_open() == false)
{
std::cerr<<"out.is_open"<<std::endl;
return false;
}
for(auto & result:results)
{
std::string out_string;
out_string+=result.title;
out_string+=SEP;
out_string+=result.content;
out_string+=SEP;
out_string+=result.url;
out_string+='\n';
out.write(out_string.c_str(),out_string.size());
}
out.close();
return true;
}
5.编写建立索引模块Index
namespace ns_index
{
struct DocInfo
{
std::string title; // 文档的标题
std::string content; // 文档的主要内容
std::string url; // 文档的url
u_int64_t doc_id; //文档的id
};
struct InvertedElem
{
u_int64_t doc_id; // 文档id
std::string word; // 词的内容
int weight; // 权值
};
typedef std::vector<InvertedElem> InvertedList;
class Index
{
private:
Index(){}
Index(const Index&) = delete;
Index operator=(const Index&) = delete;
public:
//单利模式
static Index* GetInstance()
{
if(instance == nullptr)
{
mtx.lock();
if(instance == nullptr)
{
instance = new Index();
}
mtx.unlock();
}
return instance;
}
//根据正排索引找文档
DocInfo* GetForwardIndex(u_int64_t doc_id)
{
if(doc_id > forward_index.size())
{
std::cerr<<"doc_id is too big"<<std::endl;
return nullptr;
}
return &forward_index[doc_id];
}
//根据倒排索引找doc
InvertedList* GetBackwardIndex(const std::string& word)
{
auto it = backward_index.find(word);
if(it == backward_index.end())
{
std::cerr<<"no word"<<std::endl;
return nullptr;
}
return &it->second;
}
//建立正排和倒排索引
bool BuildIndex(const std::string& input)
{
}
private:
std::vector<DocInfo> forward_index; // 正排索引
std::unordered_map<std::string,InvertedList> backward_index; //倒排索引
static Index* instance;
static std::mutex mtx; //锁
};
Index* Index::instance = nullptr;
std::mutex Index::mtx;
}
建立正排和倒排索引
bool BuildIndex(const std::string& input)
{
std::ifstream in(input,std::ios::in| std::ios::binary);
if(in.is_open() == false)
{
std::cerr<<"fail to open"<<input<<std::endl;
return false;
}
//打开成功了文件
std::string line;
while(std::getline(in,line))
{
//建立正排索引
DocInfo* info = BuildForwardIndex(line);
if(info == nullptr)
{
std::cerr<<"fail to BuildForwardIndex"<<std::endl;
continue;
}
//建立倒排索引
if(BuildBackwardIndex(*info) == false)
{
std::cerr<<"fail to BuildBackwardIndex"<<std::endl;
continue;
}
}
return true;
}
//建立正排索引
DocInfo* BuildForwardIndex(const std::string& line)
{
std::vector<std::string> results;
const std::string sep ="\3";
ns_util::StringUtil::Split(line,&results,sep);
if(results.size()!=3)
{
std::cerr<<"results.size()!=3"<<std::endl;
return nullptr;
}
DocInfo doc;
doc.title=results[0];
doc.content=results[1];
doc.url=results[2];
doc.doc_id=forward_index.size();
forward_index.emplace_back(doc);
return &forward_index.back();
}
jieba分词的使用可参考这篇文章本项目仅仅做一点简单使用
jieba库
class JiebaUtil
{
public:
static void CurString(const std::string&s,std::vector<std::string>* words)
{
jieba.CutForSearch(s,*words);
}
private:
static cppjieba::Jieba jieba; //jieba对象
};
cppjieba::Jieba JiebaUtil::jieba(DICT_PATH,HMM_PATH,USER_DICT_PATH,IDF_PATH,STOP_WORD_PATH);
//建立倒排索引
bool BuildBackwardIndex(const DocInfo& info)
{
struct word_cnt
{
int title_cnt; //标题某个词出先的次数
int content_cnt;//内容某个词出现的次数
word_cnt():title_cnt(0) ,content_cnt(0){}
};
//切分字符串
std::vector<std::string> title_words;
ns_util::JiebaUtil::CurString(info.title,&title_words);
std::vector<std::string> content_words;
ns_util::JiebaUtil::CurString(info.content,&content_words);
std::unordered_map<std::string,word_cnt> word_map;
//对每个单词计数
for(auto word:title_words)
{
boost::to_lower(word);
word_map[word].title_cnt++;
}
for(auto word:content_words)
{
boost::to_lower(word);
word_map[word].content_cnt++;
}
for(auto& word_pair:word_map)
{
InvertedElem elem;
elem.doc_id = info.doc_id;
elem.weight = 10*word_pair.second.title_cnt +word_pair.second.content_cnt;
elem.word = word_pair.first;
InvertedList& inverted_list = backward_index[word_pair.first];
inverted_list.emplace_back(elem);
}
return true;
}
6.编写搜索引擎模块Searcher
搜索逻辑:
1.根据关键字进行分词
2.根据分词结果查找索引
3.根据返回结果进行排序
4.序列化json_string
class Searcher
{
public:
Searcher(){}
~Searcher(){}
void InitSearch(const std::string& input)
{
//1. 获取index对象
index = ns_index::Index::GetInstance();
std::cout<<"获取index单例成功.."<<std::endl;
//2. 根据index对象建立索引
index->BuildIndex(input);
std::cout<<"建立正排和倒排索引成功"<<std::endl;
}
//query :搜索关键字
//json_string: 返回给用户的序列化的字符串
void Search(const std::string& query,std::string* json_string)
{
// 1.进行分词
// 2.根据分词结果查找索引
// 3.根据返回结果进行排序
// 4.序列化json_string
}
private:
ns_index::Index* index;
};
//query :搜索关键字
//json_string: 返回给用户的序列化的字符串
void Search(const std::string& query,std::string* json_string)
{
// 1.根据关键字进行分词
std::vector<std::string> words;
ns_util::JiebaUtil::CurString(query,&words);
// 2.根据分词结果查找索引
ns_index::InvertedList inverted_list_all;
for(auto word:words)
{
//不区分大小写
boost::to_lower(word);
ns_index::InvertedList* inverted_list = index->GetBackwardIndex(word);
if(inverted_list == nullptr)
{
continue;
}
inverted_list_all.insert(inverted_list_all.end(),inverted_list->begin(),inverted_list->end());
}
// 3.根据返回结果进行排序
sort(inverted_list_all.begin(),inverted_list_all.end(),
[](const ns_index::InvertedElem& e1,const ns_index::InvertedElem& e2)
{
return e1.weight>e2.weight;
});
// 4.序列化json_string
Json::Value root;
for(auto& elem:inverted_list_all)
{
ns_index::DocInfo* doc = index->GetForwardIndex(elem.doc_id);
if(doc == nullptr)
{
continue;
}
Json::Value val;
val["title"] = doc->title;
// 网页主要内容太大,截取部分关键摘要
val["desc"] = GetDesc(doc->content,elem.word);
val["url"] = doc->url;
root.append(val);
}
Json::StyledWriter writer;
*json_string = writer.write(root);
}
private:
// 网页主要内容太大,截取部分关键摘要
std::string GetDesc(const std::string & content,const std::string& word)
{
std::string desc;
const size_t prev_step = 50;
const size_t next_step = 100;
//找到首次出现的位置
auto it = std::search(content.begin(),content.end(),word.begin(),word.end(),
[](char c1,char c2){ return std::tolower(c1) == std::tolower(c2);});
if(it == content.end())
{
return "None";
}
size_t pos = std::distance(content.begin(),it);
size_t start = 0;
size_t end = content.size();
if(pos > start + prev_step)
{
start = pos - prev_step;
}
if(pos + next_step < end)
{
end = pos + next_step;
}
if(start>end)
return "None";
return content.substr(start,end-start);
}
7.编写http_server
注:cpp-httplib 需要较新的C++编译器
const std::string input ="data/output/raw.txt";
int main()
{
ns_searcher::Searcher search;
search.InitSearch(input);
httplib::Server svr;
svr.set_base_dir(root_path.c_str());
svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp){
if(!req.has_param("word")){
rsp.set_content("必须要有搜索关键字!", "text/plain; charset=utf-8");
return;
}
std::string word = req.get_param_value("word");
std::string json_string;
search.Search(word, &json_string);
rsp.set_content(json_string, "application/json");
});
svr.listen("0.0.0.0", 8081);
return 0;
}
8.效果展示






![[LeetCode周赛复盘] 第 330 场周赛20230129](https://img-blog.csdnimg.cn/ea2a50c625fc4dcc9234d38f37ac074c.png)