TextExplainer: 调试黑盒文本分类器
- 示例问题:20个新闻组数据集的LSA + SVM模型
- TextExplainer
- 文本解释器的工作原理
- 我们应该相信这个解释吗?
- 让它们犯错吧
- 让它们再次犯错吧
- 自定义TextExplainer: 采样过程
- 自定义TextExplainer:分类器
- 参考资料
尽管
eli5支持许多分类器和预处理方法,但它不能支持所有分类器和预处理方法。如果eli5不直接支持某个Python库,或者文本处理流水线对 eli5来说太复杂,eli5仍然可以帮助——它提供了LIME (Ribeiro 等,2016)算法的实现,该算法允许解释任意分类器(包括文本分类器)的预测。当很难在模型系数和文本特征之间建立精确的映射关系时(例如,如果涉及到降维) ,
eli5.lime也可以提供帮助。
关键词:LSA(Latent semantic analysis, 潜在语义分析), SVM(支持向量机)
示例问题:20个新闻组数据集的LSA + SVM模型
首先加载“20个新闻组”数据集,并创建一个文本处理流水线,这里使用一个难以调试的传统方法: 基于RBF内核的SVM,基于LSA特征训练。
from sklearn.datasets import fetch_20newsgroups
categories = ['alt.atheism', 'soc.religion.christian',
'comp.graphics', 'sci.med']
twenty_train = fetch_20newsgroups(
subset='train',
categories=categories,
shuffle=True,
random_state=42,
remove=('headers', 'footers'),
)
twenty_test = fetch_20newsgroups(
subset='test',
categories=categories,
shuffle=True,
random_state=42,
remove=('headers', 'footers'),
)
构建流水线,并训练模型:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline, make_pipeline
vec = TfidfVectorizer(min_df=3, stop_words='english', ngram_range=(1, 2))
svd = TruncatedSVD(n_components=100, n_iter=7, random_state=42)
lsa = make_pipeline(vec, svd)
clf = SVC(C=150, gamma=2e-2, probability=True)
pipe = make_pipeline(lsa, clf)
pipe.fit(twenty_train.data, twenty_train.target)
pipe.score(twenty_test.data, twenty_test.target)
输出结果:0.8901464713715047
将输入文档的维数降低到100,然后采用核支持向量机对文档进行分类。
def print_prediction(doc):
y_pred = pipe.predict_proba([doc])[0]
for target, prob in zip(twenty_train.target_names, y_pred):
print("{:.3f} {}".format(prob, target))
doc = twenty_test.data[0]
print_prediction(doc)
这就是管道为文档返回的内容——可以肯定的是,测试数据中的第一条消息属于 sci.med:
0.001 alt.atheism
0.001 comp.graphics
0.995 sci.med
0.004 soc.religion.christian
TextExplainer
这样的管道不能直接由eli5支持,但是可以使用eli5.lime.TextExplainer调试预测——检查文档中哪些内容重要,使得做出这个决定。
创建一个TextExplainer实例,然后将要解释的文档和一个黑盒分类器(一个返回概率的函数)传递给fit()方法,然后检查解释:
import eli5
from eli5.lime import TextExplainer
te = TextExplainer(random_state=42)
te.fit(doc, pipe.predict_proba)
te.show_prediction(target_names=twenty_train.target_names)

文本解释器的工作原理
解释是有意义的——期望合理的分类器考虑突出的单词。但怎么能确定这就是pipeline的运作方式而不是一个看起来漂亮的谎言呢?一个简单的理性检查是删除或更改突出显示的单词,以确认它们改变了结果:
import re
doc2 = re.sub(r'(recall|kidney|stones|medication|pain|tech)', '', doc, flags=re.I)
print_prediction(doc2)
输出结果如下,预测的概率确实改变了很多。
0.062 alt.atheism
0.144 comp.graphics
0.368 sci.med
0.426 soc.religion.christian
事实上,TextExplainer也做了类似的事情来得到解释。TextExplainer 生成了许多类似于文档的文本(通过删除一些单词) ,然后训练了一个白盒分类器,它预测黑盒分类器的输出(不是真正的标签!)。我们看到的解释是这个白盒分类器。
这种方法遵循LIME算法; 对于文本数据,该算法实际上非常简单:
- 产生文本的distorted版本;
- 使用黑盒分类器预测这些distorted文本的可能性;
- 训练另一个分类器(eli5支持的分类器之一) ,它试图预测黑盒分类器对这些文本的输出。
该算法之所以有效,是因为即使在全局范围内(对于每个可能的文本)很难或者不可能近似一个黑盒分类器,但是在给定文本附近的一个小区域内近似它通常可以很好地工作,即使使用简单的白盒分类器也是如此。
生成的示例(distorted文本)可以在samples_属性中找到:
print(te.samples_[0])
'''
As my kidney , isn' any
can .
Either they , be ,
to .
, - tech to mention ' had kidney
and , .
'''
默认情况下,TextExplainer生成5000个distorted文本(使用n_samples参数可以改变这个数量):
len(te.samples_) # 5000
已训练好的白盒分类器和向量化器可以使用vec_和clf_属性:
te.vec_, te.clf_
'''
(CountVectorizer(ngram_range=(1, 2), token_pattern='(?u)\\b\\w+\\b'),
SGDClassifier(alpha=0.001, loss='log', penalty='elasticnet',
random_state=RandomState(MT19937) at 0x7F475BE0A840))
'''
我们应该相信这个解释吗?
上面的解释听起来不错,但是我们如何确保这个简单的文本分类管道能够很好地接近黑盒分类器呢?
一种方法是检查保留数据集(也是生成的)的质量。TextExplainer 默认情况下是这样做的,并将指标存储在metrics_属性中:
te.metrics_
'''
{'mean_KL_divergence': 0.019677145569149457, 'score': 0.9853838094737808}
'''
- 'score’是一个精确度得分,由生成的样本和原始文档之间的余弦距离加权(也就是说,更接近实例的文本更重要)。准确性显示了“排名前1”的预测有多好。
- 'mean_KL_divergence’是所有目标类的平均Kullback-Leibler散度,它也由距离加权。KL散度显示了概率的近似程度; 0.0表示完全匹配。
在这个例子中,accuracy和KL散度都很好; 这意味着我们的白盒分类器通常在我们生成的数据集上分配与黑盒分类器相同的标签,并且它的预测概率接近我们的 LSA + SVM 流水线所预测的概率。所以很可能(虽然不能保证,我们将在后面讨论)这个解释是正确的并且是可信的。
当使用LIME (例如通过TextExplainer)时,检查这些分数总是一个好主意。如果它们不好,那么你可以说有些东西是不对的。
让它们犯错吧
默认情况下,TextExplainer 使用一个非常基本的文本处理流水线:Logistic Regression使用bag-of-words and bag-of-bigrams特征进行训练(参见te.clf_和te.vec_属性)。它限制了一组它可以解释的黑盒分类器: 因为文本被视为“bag of words/ngrams”,默认的白盒管道无法区分,例如在文档的开头和结尾的同一个单词。Bigrams在实践中有助于缓解这个问题,但不是完全缓解。
使用“text length”(与标记没有直接关系)等特性的黑盒分类器也很难用默认的bag-of-words/ngrams模型进行近似处理。这种失败通常是可以检测到——scores(accuracy 和 KL divergence)将是低的。
让我们检查一个完全合成的示例——一个黑盒分类器,它根据文档长度的奇异性和“药物(medication)”单词的存在来分配一个类。
import numpy as np
def predict_proba_len(docs):
# nasty predict_proba - the result is based on document length,
# and also on a presence of "medication"
proba = [
[0, 0, 1.0, 0] if len(doc) % 2 or 'medication' in doc else [1.0, 0, 0, 0]
for doc in docs
]
return np.array(proba)
te3 = TextExplainer().fit(doc, predict_proba_len)
te3.show_prediction(target_names=twenty_train.target_names)

TextExplainer正确地发现“药物(medication)”是重要的,但是没有考虑到“ len (doc)% 2”的情况,因此解释不完整。我们可以通过观察指标来检测这种失败——指标很低:
te3.metrics_
'''
{'mean_KL_divergence': 0.3141120647902322, 'score': 0.7776484262009539}
'''
如果(一个大的 If…)我们怀疑事实文档长度是偶数或奇数是重要的,那么可以定制TextExplainer来检查这个假设。
要做到这一点,我们需要创建一个向量器,它返回“is odd”特性和词袋特性,并将此向量器传递给TextExplainer。这个向量器应该遵循scikit-learn API。最简单的方法是使用FeatureUnion——只需确保FeatureUnion 加入的所有转换器都具有get_feature_names()方法。
from sklearn.pipeline import make_union
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.base import TransformerMixin
class DocLength(TransformerMixin):
def fit(self, X, y=None): # some boilerplate
return self
def transform(self, X):
return [
# note that we needed both positive and negative
# feature - otherwise for linear model there won't
# be a feature to show in a half of the cases
[len(doc) % 2, not len(doc) % 2]
for doc in X
]
def get_feature_names(self):
return ['is_odd', 'is_even']
vec = make_union(DocLength(), CountVectorizer(ngram_range=(1,2)))
te4 = TextExplainer(vec=vec).fit(doc[:-1], predict_proba_len)
print(te4.metrics_)
te4.explain_prediction(target_names=twenty_train.target_names)

好多了!这是一个简单例子,但是这个想法是站得住脚的——如果你认为某个东西可能很重要,那么把它作为 TextExplainer 的一个特性添加到这个组合中。
让它们再次犯错吧
另一个可能的问题是数据集生成方法。特征提取不仅应该足够强大,而且自动生成的文本也应该足够多样化。
TextExplainer在默认情况下删除随机单词,所以默认情况下它不能提供一个很好的解释,比如黑盒分类器在字符级别上工作。让我们尝试使用TextExplainer来解释一个使用char ngram作为特性的分类器:
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.linear_model import SGDClassifier
vec_char = HashingVectorizer(analyzer='char_wb', ngram_range=(4,5))
clf_char = SGDClassifier(loss='log')
pipe_char = make_pipeline(vec_char, clf_char)
pipe_char.fit(twenty_train.data, twenty_train.target)
pipe_char.score(twenty_test.data, twenty_test.target)
'''
0.8788282290279628
'''
eli5直接支持此管道,因此在实践中不需要为此使用TextExplainer。我们正在使用这个管道作为一个例子——它可能首先检查“true”的解释,而不使用TextExplainer,然后比较结果与TextExplainer的结果。
eli5.show_prediction(clf_char, doc, vec=vec_char, targets=['sci.med'], target_names=twenty_train.target_names)

TextExplainer 会产生一个不同的结果:
te = TextExplainer(random_state=42).fit(doc, pipe_char.predict_proba)
print(te.metrics_) # {'mean_KL_divergence': 0.019016252861715745, 'score': 0.9392062420285368}
te.show_prediction(targets=['sci.med'], target_names=twenty_train.target_names)

分数看起来不错,但不是很好; 第一眼看上去这个解释有点道理,但是我们知道分类器的工作方式不同。
为了解释这种黑盒分类器,我们需要改变数据集生成方法(更改/删除单个字符,而不仅仅是单词)和特征提取方法(例如使用char ngram 而不是单词和word ngram)。
TextExplainer有一个选项(char_based=True)可以使用基于字符的抽样和基于字符的分类器。如果这使得一个更强大的解释引擎,为什么不总是使用它?
te = TextExplainer(char_based=True, random_state=42)
te.fit(doc, pipe_char.predict_proba)
print(te.metrics_) # {'mean_KL_divergence': 0.09492399761018691, 'score': 0.6262826866605495}
te.show_prediction(targets=['sci.med'], target_names=twenty_train.target_names)
 结果看起来更糟。TextExplainer 正确地检测到,只有单词“medication”的第一部分是重要的,但结果总体上是嘈杂的,分数很差。让我们用更多的样品来试试:
结果看起来更糟。TextExplainer 正确地检测到,只有单词“medication”的第一部分是重要的,但结果总体上是嘈杂的,分数很差。让我们用更多的样品来试试:
te = TextExplainer(char_based=True, n_samples=50000, random_state=42)
te.fit(doc, pipe_char.predict_proba)
print(te.metrics_) # {'mean_KL_divergence': 0.024488473524243996, 'score': 0.8412768526797193}
te.show_prediction(targets=['sci.med'], target_names=twenty_train.target_names)

它越来越近了,但仍然没有到达那里。问题在于它的资源密集程度要高得多——需要更多的样本才能得到无噪声的结果。在这里,解释一个示例比训练原始管道花费更多的时间。
一般来说,要对黑盒分类器进行有效的解释,需要对黑盒分类器进行一些假设,如:
- 以词为特征,不考虑词的位置;
- 以词为特征,考虑词的位置;
- 它使用words ngram 作为特征;
- 它使用char ngram 作为特征,位置并不重要(例如,ngram在任何地方的意思都是一样的) ;
- 它对text characters使用任意的注意力,也就是说,文本的每一部分对于分类器本身可能是潜在的重要的;
- 在一个特定的位置有一个特定的标记是很重要的,例如“第三个标记是 X”,如果我们删除第二个标记,那么预测的改变不是因为第二个标记改变了,而是因为第三个标记改变了。
根据假设,我们应该同时选择数据集生成方法和白盒分类器。一般性和速度之间存在权衡。
简单的词袋假设允许快速生成样本,如果假设是正确的,那么只需要几百个样本就可以得到一个 OK 质量。但是这样的生成方法/模型将无法正确地解释更复杂的分类器(尽管它们仍然可以提供在实践中有用的解释)。
另一方面,允许每个字符都很重要是一种更强大的方法,但是它需要大量的样本(可能是几十万个)和大量的 CPU 时间才能得到无噪声的结果。
这种失败(关于黑盒管道的错误假设)的坏处在于不可能通过查看分数来检测失败。分数可能很高,因为生成的数据集不够多样化,而不是因为我们的近似值很好。
要点是,在使用LIME解释预测时,理解你所看到的“lenses”是非常重要的。
自定义TextExplainer: 采样过程
TextExplainer使用MaskingTextSampler或MaskingTextSampler实例生成文本以进行训练。MaskingTextSampler 是主要的文本生成类; MaskingTextSampler 提供了一种将多个采样器组合到具有相同接口的单个对象中的方法。
如果我们想尝试采样,可以将自定义采样器实例传递给TextExplainer。例如,让我们尝试一个取样器,它替换文本中不超过3个字符(默认是替换随机数字符) :
from eli5.lime.samplers import MaskingTextSampler
sampler = MaskingTextSampler(
# Regex to split text into tokens.
# "." means any single character is a token, i.e.
# we work on chars.
token_pattern='.',
# replace no more than 3 tokens
max_replace=3,
# by default all tokens are replaced;
# replace only a token at a given position.
bow=False,
)
samples, similarity = sampler.sample_near(doc)
print(samples[0])
'''
As I recall from my bout with kidney stones, there isn't any
medication tht can do anything about them except relieve the pain.
Either they pass, or they have to be broken up with sound, or they have
to be extracted surgically.
When I was in, the X-ray tech happened to mention that she'd had kidney
stones and children, and the childbirth hurt less.
'''
te = TextExplainer(char_based=True, sampler=sampler, random_state=42)
te.fit(doc, pipe_char.predict_proba)
print(te.metrics_) # {'mean_KL_divergence': 0.09256123621465144, 'score': 1.0}
te.show_prediction(targets=['sci.med'], target_names=twenty_train.target_names)

注意,准确度得分是完美的,但 KL散度很差。 这意味着这个采样器不是很有用:大多数生成的文本都是“简单的”,因为它们中的大多数(或全部?)仍应归类为sci.med,因此很容易获得良好的准确性。但是由于生成的文本不够多样化,分类器没有学到任何有用的东西; 很难预测黑盒管道在保留数据集上的概率输出。
默认情况下,TextExplainer混合使用多种采样策略,这似乎适用于基于标记的解释。但是适用于许多现实世界任务的良好采样策略本身可能是一个研究课题。
自定义TextExplainer:分类器
在前面的一个示例中,我们已经更改了 TextExplainer 使用的向量化器(以考虑其他功能)。 也可以改变白盒分类器——例如,使用一个小的决策树:
from sklearn.tree import DecisionTreeClassifier
te5 = TextExplainer(clf=DecisionTreeClassifier(max_depth=2), random_state=0)
te5.fit(doc, pipe.predict_proba)
print(te5.metrics_) # {'mean_KL_divergence': 0.03821910839634716, 'score': 0.9820333011866811}
te5.show_weights()
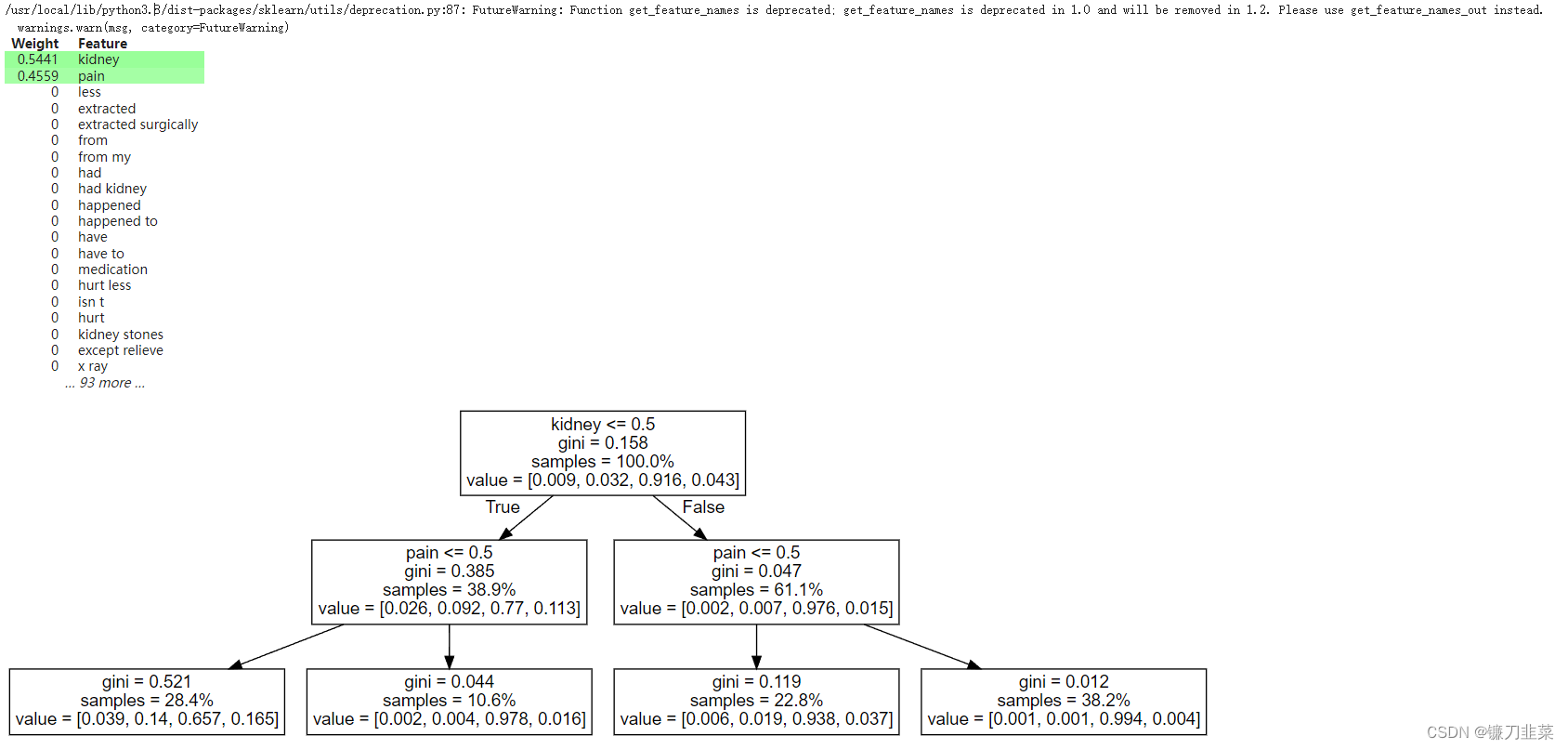
解读:“kidney <= 0.5”表示“文档中没有‘kidney’这个词”(我们又在解释原来的LDA+SVM pipeline)。
因此,根据这棵树,如果“kidney ”不在文档中且“pain”不在文档中,则属于 sci.med 的文档的概率下降到 0.65。 如果这些词中至少有一个保持,sci.med 概率保持在 0.9+。
print("both words removed::")
print_prediction(re.sub(r"(kidney|pain)", "", doc, flags=re.I))
print("\nonly 'pain' removed:")
print_prediction(re.sub(r"pain", "", doc, flags=re.I))
'''
both words removed::
0.013 alt.atheism
0.021 comp.graphics
0.891 sci.med
0.075 soc.religion.christian
only 'pain' removed:
0.003 alt.atheism
0.003 comp.graphics
0.978 sci.med
0.016 soc.religion.christian
'''
正如预期的那样,在删除这两个词后,sci.med的概率下降了,尽管没有我们简单的决策树预测的那么多(下降到 0.9 而不是0.64)。 消除"pain"提供了与预测完全相同的效果——sci.med的概率变为 0.98。
参考资料
[1] Latent semantic analysis (LSA)
[2] TextExplainer: debugging black-box text classifiers


![[LeetCode周赛复盘] 第 330 场周赛20230129](https://img-blog.csdnimg.cn/ea2a50c625fc4dcc9234d38f37ac074c.png)