文章目录
- 1、sed概述
- 1.1、 与vim等编辑器的区别:
- 1.2、sed工作原理
- 1.3 、sed数据处理原理
- 1.4 、正则表达式概念
- 2、 sed语法和常用选项
- 2.1、语法:
- 2.2、sed常用内部命令
- 2.3、参数:
- 3、 sed + 正则表达式(定位)
- 3.1 、数字定址
- 3.2、常用实例
- 3.2.1、指定行 字符串** 内容替换
- 3.2.2、限定区间行数 字符串内容替换
- 3.2.3、指定区间行 字符串内容替换
- 3.2.4、指定起始行及倍数行 字符串内容替换
- 3.2.5、指定起始行及跨行规则 字符串内容替换
- 3.2.6、指定起始行及跨行规则 字符串内容替换
- 3.2.7、指定起始行及跨行规则 字符串内容替换
- 3.3、正则表达式
- 3.3.1、解释
- 3.3.2、操作实例
- 4、sed使用技巧
- 4.1 、$= 统计文本有多少行
- 4.2 、行内容迁移
- 4.3、 将匹配的内容另存为新文件
- 5、练习实操
- 5.1、实操题目
- 5.2、 基于题目练习例子
1、sed概述
sed 全名为 stream editor,流编辑器,是贝尔实验室的 Lee E.McMahon 在 1973 年到 1974 年之间开发完成,目前可以在大多数操作系统中使用,sed 的出现作为 grep 的继任者。
1.1、 与vim等编辑器的区别:
- vim 文本编辑器: 编辑对象是文件;
- sed 行编辑器:编辑对象是文件中的行;
sed 是一种非交互式编辑器(即用户不必参与编辑过程),它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后再输出编辑结构。
1.2、sed工作原理
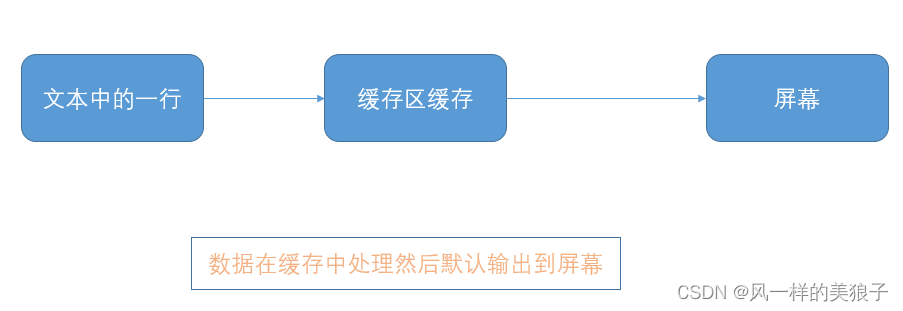
sed 本身一次处理一行内容。
- 处理的时候会把当前处理的行内容存储在临时缓冲区中,成为"模式空间",
- 接着用sed命令处理缓冲区中的内容,处理完成后,会把缓冲区的内容输出到屏幕。
- 接着处理下一行内容,如此不断重复此过程,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
1.3 、sed数据处理原理
1.4 、正则表达式概念
使用sed 主要就是使用正则模式进行匹配,所以需要了解正则表达式相关内容。
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式 我会单独写一篇内容讲解,此外就不在介绍。
2、 sed语法和常用选项
2.1、语法:
调用sed命令有两种形式:
sed [options] ‘command’ file(s)
sed [options] -f scriptfile file(s)
sed [options] ‘{command}[flags]’ [filename]
#中括号内容必有 大括号内容可有可无
sed # 执行命令
[options] # 命令选项
{command}[flags] # sed内部选项和参数
[filename] # 文件
命令选项
-e script 将脚本中指定的命令添加到处理输入时执行的命令中 多条件,一行中要有多个操作
-f script 将文件中指定的命令添加到处理输入时执行的命令中
-n 抑制自动输出
-i 编辑文件内容
-i.bak 修改时同时创建.bak备份文件。
-r 使用扩展的正则表达式
! 取反 (跟在模式条件后与shell有所区别)
2.2、sed常用内部命令
a : 在匹配行后添加一行或多行内容
c : 用新文件修改(替换)当前行中的文本
d : 删除
g : 全局执行
i : 在匹配的行之前插入文本
p 打印
r : 从以外文件中读相关内容,写到相关行之后
s : 用一个字符替整体替换成另外一个字符(查找替换)
w : 匹配到的行写入一个新的文件之中
y : 将字符转换成一个新的字符
i : 与s指令配合一起使用时,则是忽略大小写的作用
flags
数字 表示新文本替换的模式
g: 表示用新文本替换现有文本的全部实例
p: 表示打印原始的内容
w filename: 将替换的结果写入文件
2.3、参数:
- e : 允许多项编辑
- n : 取消默认输出
- i : 就地编辑文本
- r : 支持扩展正则表达式(sed中的正则表达式必须放在两个//中间)
- f : 指定定位规则的文件
3、 sed + 正则表达式(定位)
3.1 、数字定址
默认情况下sed会对每一行内容进行匹配、处理、输出,某些情况不需要对处理的文本全部编辑,只需要其中的一部分,比如1-5行,偶数行,或者是包含"word"字符串的行,这种情况下就需要我们去定位特定的行来处理,而不是全部内容,这里把这个定位指定的行叫做"定址"。
数字定址其实就是通过数字去指定具体要操作编辑的行,
数字定址有多种方式,每种方式都有不同的应用场景,下边以举例的方式来描述每种数字定址的用法。
固定定位
[root@localhost ~]# sed -n ‘3p’ 1.txt
范围定位
[root@localhost ~]# sed -n ‘1,3p’ 1.txt
3.2、常用实例
3.2.1、指定行 字符串** 内容替换
sed –n '1s/word/china/' message
命令说明:将第1行中word字符串替换为china,其它行如果有word也不会被替换。
3.2.2、限定区间行数 字符串内容替换
sed –n '3,5s/word/china/' message
命令说明:将第3-5行中word字符串替换为china,其它行如果有word也不会被替换。
3.2.3、指定区间行 字符串内容替换
sed –n ‘1,+4s/word/china/’ message
命令说明:从第1行开始,再接着往下数4行,也就是1-5行,这些行会把word字符串替换为china。
3.2.4、指定起始行及倍数行 字符串内容替换
sed –n '4,~3s/word/china/' message
命令说明:第4行开始,到第6行。解释6的由来,"4,~3"表示从4行开始到下一个3的倍数,这里从4开始算,那就是6了,当然9就不是了,因为是要求3的第一个超过前边数字4的倍数,这种适用场景不会太多。
3.2.5、指定起始行及跨行规则 字符串内容替换
sed –n '4~3s/word/china/' message
命令说明:从第4行开始,每隔3行就把hello替换为A。比如从4行开始,7行,10行等依次+3行。这个比较常用,比如3替换为2的时候,也就是每隔2行的步调,可以实现奇数和偶数行的操作。
3.2.6、指定起始行及跨行规则 字符串内容替换
sed –n '$s/word/china/' message
命令说明: 符号表示最后一行,和正则中的 符号表示最后一行,和正则中的 符号表示最后一行,和正则中的符号类似,但是第1行不用^表示,直接1就行了。
3.2.7、指定起始行及跨行规则 字符串内容替换
sed -n '1!s/word/china/' message
命令说明:!符号表示取反,该命令是将除了第1行,其它行word替换为china,上述定址方式也可以使用!符号。
3.3、正则表达式
3.3.1、解释
正则表达式必须放在/ / 之间
数字加数字
数字加正则
正则加数字
正则加正则
\c与c分隔符
\c与c只是一个代表,其中c可以换成任意一个字符
说明:正则匹配是非贪婪性的匹配
- 贪婪性:是匹配到了之后,不停继续匹配,直至文件所有的内容全部匹配完毕。
- 非贪婪性:是匹配,一旦匹配到了就停止匹配。
3.3.2、操作实例
正则定址使用目的和数字定址一样,只是它们在使用方式上有所不同,是通过正则表达式的匹配来确定需要处理编辑哪些行,其它行就不需要额外处理。
1、匹配到删除
sed -n '/word/d' message
说明:将匹配到word的行执行删除操作。
例子2:
2、删除空行
sed -n '/^$/d' message
3、匹配区间行进行删除
sed -n '/^THE/,/^COME/d' message
说明:匹配以THE开头的行到COME开头的行之间的行,把匹配到的这些行删除。
4、数字定址和正则定址混用
在实际使用过程中我们经常将数字定址和正则定址可以配合使用,参考下边的例子。
sed -n '1,/^THE/d' message
说明:匹配从第1行到THE开头的行,把匹配的行删除。
4、sed使用技巧
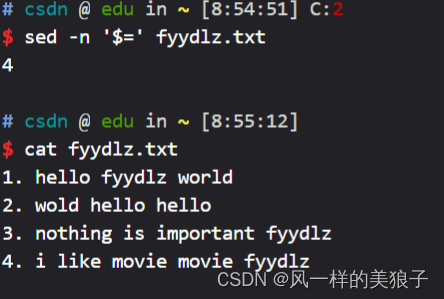
4.1 、$= 统计文本有多少行
- 统计fyydlz.txt有多少行;
- 打印fyydlz.txt 文本内容时加上行号;
sed -n '$=' fyydlz.txt
sed '=' fyydlz.txt
4.2 、行内容迁移
将1-5行迁移到10行后
sed '1,5{H;d};10G' fyydlz.txt
4.3、 将匹配的内容另存为新文件
sed '/the/w fyydlz.txt' fyydlz2.txt
5、练习实操
5.1、实操题目
本次实操题目内容:
假设文件fyydlz.txt的文本如下(可以利用touch命令和vi命令组合创建):
1. hello fyydlz world
2. wold hello hello
3. nothing is important fyydlz
4. i like movie movie fyydlz
sed 命令可以用来替换文本行、删除文本行,例子如下:
5.2、 基于题目练习例子
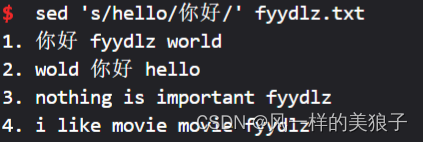
1、查找并替换每行第一个"hello"为"你好":
sed 's/hello/你好/' fyydlz.txt
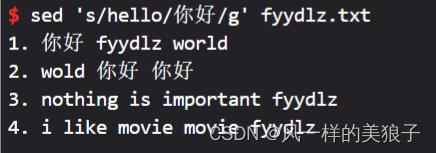
2、查找替换每行中所有的"hello"为"你好":
sed 's/hello/你好/g' fyydlz.txt
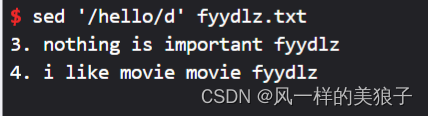
3、删除含有"hello"的行:
sed '/hello/d' fyydlz.txt
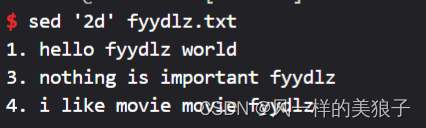
4、删除第2行:
sed '2d' fyydlz.txt
5、删除第最后一行:
sed 'd' fyydlz.txt

6、删除第2行到最后一行:
sed '2,d' fyydlz.txt