本篇主要介绍数据的可靠性有关的知识,包括binlog的写入机制和redolog的写入机制,通过了解这些机制从而可以在MySQL的IO性能瓶颈上做些优化;
前文介绍了MySQL在可靠性、性能相关的概念,包括WAL技术、redolog与binlog、2阶段提交、change buffer、flush等,得到的结论是:只要redolog和binlog保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复;
在介绍本篇内容之前,先简单回忆下这些知识点;
WAL / redolog&binglog / 2阶段提交 / change buffer / flush时机
WAL技术
WAL 的全称是 Write-Ahead Logging;更新数据时,先写日志再写磁盘,节省随机写磁盘的IO消耗(转成顺序写);redolog日志中记录的更新会在"一定时机"flush到磁盘;
redolog&binglog
是MySQL中的两套日志;
redolog只有InnoDB有而别的引擎没有,循环写,空间有限,因此不具备“归档”这功能,是物理日志(记录的是“在某个数据页上做了什么修改”);
binlog是MySQL的Server层实现的,所有引擎都可以使用,是逻辑日志(记录的是这个语句的原始逻辑),可以追加写入;
redolog具备crash-safe能力,binlog可用于归档和主从同步;
2阶段提交
InnoDB先写redolog(prepare),执行器写binlog,最后InnoDB写redolog(commit);redolog的写入拆成了两个步骤:prepare和commit,这就是"两阶段提交";此过程中,redolog和binlog通过XID关联,用于数据的崩溃恢复,并保证主从数据一致;
change buffer
是内存中bufferpool的一部分,将更新操作缓存在 change buffer 中,在"一定时机"作用于原数据页,得到最新结果(merge);这一机制保证不用每次更新数据时都立即将磁盘中的数据页加载到内存中做更新操作,从而节省随机读磁盘的IO消耗;写多读少、写完不马上读、非唯一索引(唯一索引字段更新需先读再判断唯一性)则推荐使用;
flush
意思是刷脏页,将"正确"的脏页刷到磁盘,原内存页变为"干净页";除了MySQL的定时刷和关机前刷,redolog满了(会停下所有更新)或内存bufferpool满了(内存淘汰)都会触发flush;刷脏页时会消耗IO因此不能太集中,需要根据当前脏页比例和redolog写入速度来控制频率/速度;
binlog 的写入机制

由上图可知:
系统为每个事务线程分配了一片binlog cache内存,共用一份binlog文件;
事务执行过程中,各个事务线程先把日志写到binlog cache中,事务提交的时,再把binlog cache写到同一份binlog文件并清空binlog cache;
图中write是把日志写入到文件系统的page cache内存中,所以速度比较快;图中fsync是将数据持久化到磁盘,占用磁盘的IOPS;
其中,write和fsync的时机,是由参数sync_binlog控制的:
sync_binlog=0,表示每次提交事务都只write,不fsync;
sync_binlog=1,表示每次提交事务都会执行fsync;
sync_binlog=N(N>1),表示每次提交事务都write,但累积N个事务后才fsync;
因此,在出现IO瓶颈的场景里,将sync_binlog设置成一个比较大的值,可以提升性能;在实际的业务场景中,考虑到丢失日志量的可控性,一般不将这个参数设成0,比较常见的是将其设置为100~1000中的某个数值;
需要注意,将sync_binlog设置为N(N>1),对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志;
redo log 的写入机制
与binlog类似,redolog在写入过程中也会经历在redolog buffer、page cache、disk这3个阶段,并且InnoDB提供了innodb_flush_log_at_trx_commit参数,来控制redolog的写入策略:
设置为0,表示每次事务提交时都只是把redolog留在redolog buffer中;
设置为1,表示每次事务提交时都将redolog直接持久化到磁盘;
设置为2,表示每次事务提交时都只是把redolog写到page cache;
InnoDB有一个后台线程,每隔1秒,就会把redolog buffer中的日志,调用write写到文件系统的page cache,然后调用fsync持久化到磁盘;
注意,事务执行"中间过程"的redolog也是直接写在redolog buffer中的,这些redolog也会被后台线程一起持久化到磁盘;也就是说,一个还没有提交的事务的redolog,也是有可能被持久化到磁盘的;
除了后台线程每秒一次的轮询操作外,还有两种场景会让一个没有提交的事务的redolog写入到磁盘中:
一种是,redolog buffer占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程会主动写盘;注意,由于此时这个事务还没有提交,所以这个写盘动作只是write,而没有调用fsync,也就是只留在了文件系统的page cache。
另一种是,并行的事务提交的时候,由于各个事务线程共享redolog buffer,其他事务提交,顺带将这个还未提交的事务的redolog从redolog buffer持久化到磁盘;
假设一个事务A执行到一半,已经写了一部分redolog到buffer中,这时候有另外一个线程的事务B提交,如果innodb_flush_log_at_trx_commit设置的是1,那么按照这个参数的逻辑,事务B要把redolog buffer里的日志全部持久化到磁盘;这时候,就会带上事务A在redolog buffer里的日志一起持久化到磁盘;
组提交(group commit)机制
通常我们说MySQL的“双1”配置,指的就是sync_binlog和innodb_flush_log_at_trx_commit都设置成1;也就是说,一个事务完整提交前,需要等待两次刷盘,一次是redolog(prepare阶段),一次是binlog;
这时候,你可能有一个疑问,如果从MySQL看到的TPS是每秒两万的话,每秒就会写四万次磁盘;但是,用工具测试出来,磁盘能力也就两万左右,怎么能实现两万的TPS?
解释这个问题,就要用到组提交(group commit)机制了;下面举个栗子,如图3所示,是3个并发事务(trx1,trx2,trx3)在prepare阶段,都写完redologbuffer,准备持久化到磁盘的过程,对应的LSN分别是50、120和160;
这里引入了日志逻辑序列号(log sequence number,LSN)的概念;LSN是单调递增的(有序),用来对应redolog的一个个写入点;每次写入长度为length的redolog,LSN的值就会加上length;LSN也会写到InnoDB的数据页中,来确保数据页不会被多次执行重复的redolog;

由图可知,
trx1是第一个到达的,会被选为这组的leader;
等trx1要开始写盘的时候,发现这个组里面已经有了3个事务,最大的LSN=160,这时候trx1的LSN也变成了160;
trx1去写盘的时候,带的就是LSN=160,因此等trx1返回时,所有LSN小于等于160的redolog,都已经被持久化到磁盘;
这时候trx2和trx3就可以直接返回了;
所以,一次组提交里面,组员越多,节约磁盘IOPS的效果越好;在并发更新场景下,第一个事务写完redolog buffer以后,接下来这个fsync越晚调用,组员可能越多,节约IOPS的效果就越好;
MySQL针对组提交的优化
为了让一次fsync带的组员更多,MySQL有一个很有趣的优化:拖时间——对于单个事务的提交,不急着立即fsync而是等一等;
在介绍两阶段提交的时候,有下面的这一张图:

图中,"写binlog"是一个动作,但MySQL针对组提交机制做了优化,实际上,写binlog是分成两步的:
先把binlog从binlogcache中写到磁盘上的binlog文件;
调用fsync持久化;
MySQL为了让组提交的效果更好,把redolog做fsync的时间拖到了步骤1之后;也就是说,上面的图实际变成了这样:
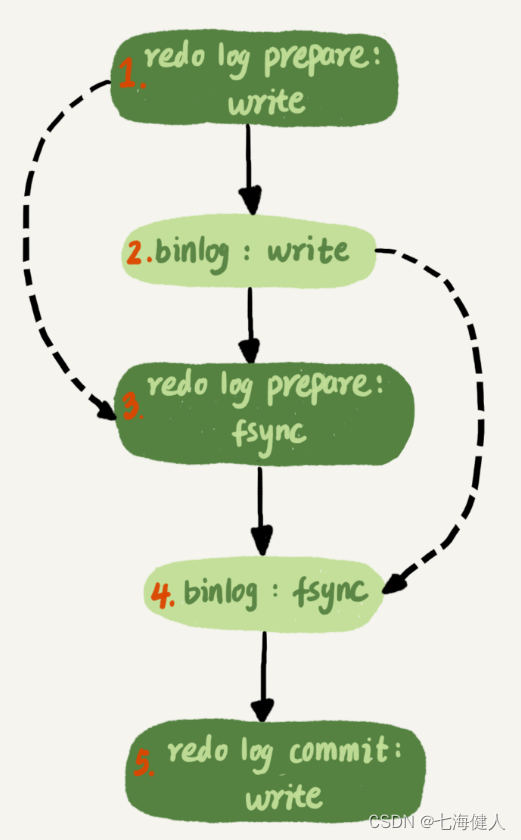
这么一来,binlog也可以组提交了;在执行图中第4步把binlog fsync到磁盘时,如果有多个事务的binlog已经write写完了,也是一起持久化的,这样也可以减少IOPS的消耗;
现在你就能理解了,WAL机制主要得益于两个方面:
redolog和binlog都是顺序写,磁盘的顺序写比随机写速度要快;
充分利用组提交机制,可以大幅度降低磁盘的IOPS消耗;
下篇文章:待定
本章参考:23 | MySQL是怎么保证数据不丢的?