信息抽取的定义为:从自然语言文本中抽取指定类型的实体,关系、事件等事实信息。并形成结构化数据输出的文本处理技术。
信息抽取是从文本数据中抽取特定信息的一种技术,文本数据由医学具体的单位构成,例如,句子、段落、篇章。本文信息正式由一些小的具体的单位构成的,例如字、词、词组、句子、段落或是这些具体的单位的组合。
抽取文本数据的名词短语、人名、地名等都是文本信息抽取,当然,文本信息抽取技术所抽取的信息可以是各种类型的信息。
本文介绍从文本中提取的有限种类语义内容的技术,此信息提取过程(IE)将嵌入文本中的非结构化信息转换为结构化数据。例如用于填充关系数据库以支持进一步处理。
命名实体识别(NER): 找到文本中提到的每个命名实体,并标记其类型。构成命名实体类型的是特定于任务的人员,地点和组织是常见的,一旦提取了文本中的所有命名实体**,就可以将其链接到与实际实体相对应的集合中。
关系抽取:发现和分类文本实体之间的语义关系,这些关系通常为二元关系、如子女关系、就业关系、部分-整体关系和**地理空间关系。
命名实体识别NER
信息提取的第一步是检测文本中的实体。一个命名实体,粗略地说,是任何可以用一个专有名称引用的东西:一个人、一个位置、一个组织。
这个术语通常被扩展为包含本身不是实体的东西,包括日期、时间和其他类型的时态表达式。甚至像价格这样的数字表达式,下面是前面介绍的示例文本,其中标有命名实体:

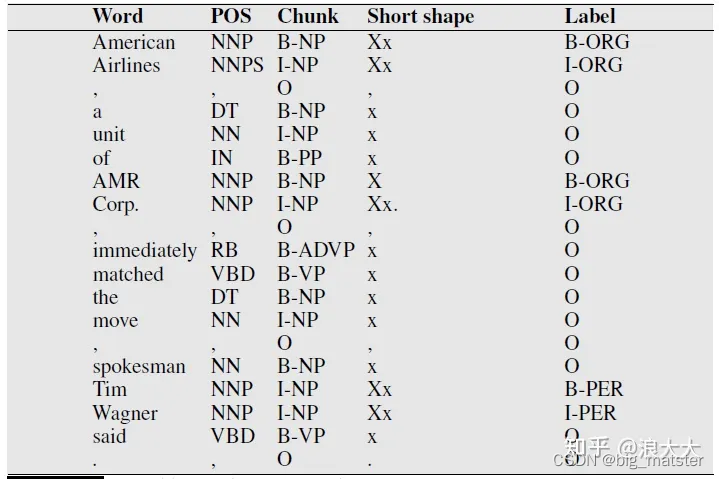
文本包含13个提到的命名实体,包括5个组织、4个地点、2次、1个人和1个提到钱的实体。除了用于提取事件和参与者之间的关系之外,命名实体对于许多其他语言处理任务也很有用。
在情感分析中,我们可能想知道消费者对特定实体的情绪,实体是回答问题或将文本链接到结构化知识资源,如Wikipedia)中的信息的有用的第一阶段
下图显示了典型的通用命名实体类型,许多应用程序还需呀使用特定的实体类型,如蛋白质、基因、商业产品或艺术品。

命名实体指的是查找构成专有名称的文本范围。然后对实体类型进行分类。
识别困难的原因之一是分割的模糊性。我们需要决定什么是实体,什么不是,界限在哪里,另一个困难是类型模糊。
J
F
K
JFK
JFK可以指一个人,纽约的机场,美国各地的学校、桥梁和街道。下图给出了这些交叉类型混淆的一些例子。

NER作为序列标记
命名实体识别的标准算法是一个逐词的序列标记任务。其中指定的标记同时捕获边界和类型。
序列分类器(如MEMM/CRF或bi-LSTM)被训练为在文本中使用标记来标记标记,这些标记表示特定类型的命名实体的存在。考虑下面来自运行示例的简化摘录
看一下最常用的两种
s
e
q
u
e
n
c
e
l
a
b
e
l
i
n
g
sequence labeling
sequencelabeling的编码方式,IO encoding简单的为每个 token 标注,如果不是 NE 就标为 O(other),所以一共需要 C+1 个类别(label)。
而IOB encoding需要 2C+1 个类别(label),因为它标了 NE boundary,B 代表 begining,NE 开始的位置,I 代表 continue,承接上一个 NE**,如果连续出现两个 B,自然就表示上一个 B 已经结束**了。

一个基于特征的NER算法

第一种方法提取特征并训练,词性标记类型的MEMM或CRF序列模型。而这种思路在NER中更为普遍和有效。
NER任务中,最常见的特征包括形态、局部
l
o
c
a
l
local
local词汇和句法信息。形态特征有如词形、大小写、前后缀等。局部词汇特征有如前后提示词、窗口词、连接词等。
最近,通过未登录词和非常规词的识别来提高NER的效果,也得到了尝试**。句法特征有词性、浅层句法结构等。
由于汉语的特殊性,除了词汇层面的特征外,汉字层面的特征也被充分地用来辅助提高NER的效果**,如提示单字、常用尾字等。同时,由于汉语分词和NER的密切联系,有研究发现分词结果可以有效地提高汉语NER的效果。
为了提高识别的效果,各种全局(global)信息也作为特征被广泛地应用在NER中,尤其是远距离依存和上下文同指等。与此同时,各种外部知识如未标注文本旦、人名词典、地名词典等也被普遍使用来提高NER模型的性能。
有研究表明**,在模型不变的情况下,全局信息和外部知识确实可以显著地提高识别的效果。值得注意的是,维基百科知识是最常见且有效的外部知识,而在汉语NER中,知网作为一个汉语特有的词汇语义知识库**,也被充分地应用在NER研究中。
例如,命名实体令牌L 'Occitane将生成以下非零值特征值::

地名表是地名的列表,通常为数百万个地点提供详细的地理和政治信息。
一种相关的资源是姓名列表,美国人口普查局还提供了大量的姓氏和名字列表。这些名字都来自于其在美国进行的十年一次人口普查类似的公司、商业产品以及各种生物和矿物的清单也可从各种来源获得。
地名表和名称特性通常作为每个名称列表的二进制特性实现。不幸的是,这样的列表很难创建和维护,而且它们的有用性差别很大。虽然地名表可能非常有效,但个人和组织的列表并不总是有用的
特征有效性取决于应用程序、类型、媒体和语言。
例如,形状特征对于英语新闻专线文本来说至关重要,但对于自动语音识别的抄本,其他未经编辑或非正式来源,或者像汉语这样不适用正字法大小写的语音,形状特征几乎没什么用处。
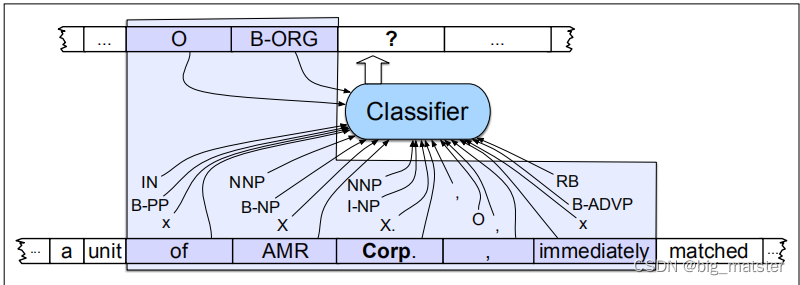
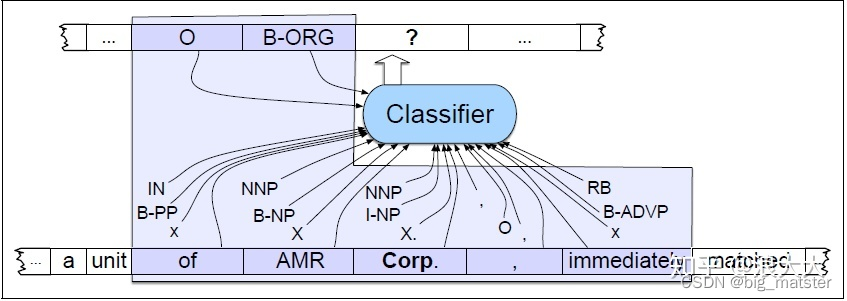
下图说明了在前面的示例中添加词性标记、语法基短语块标记和一些形状信息的结果。给定这样一个训练集,就可以训练像MEMM这样的序列分类器来标记新的句子。图17.7说明了这样一个序列标记器在token Corp.接下来被标记的地方的操作。如果我们假设一个上下文窗口包含前两个和后两个单词,那么分类器可用的特征就是框内区域中显示的特征。
一种用于NER的神经算法
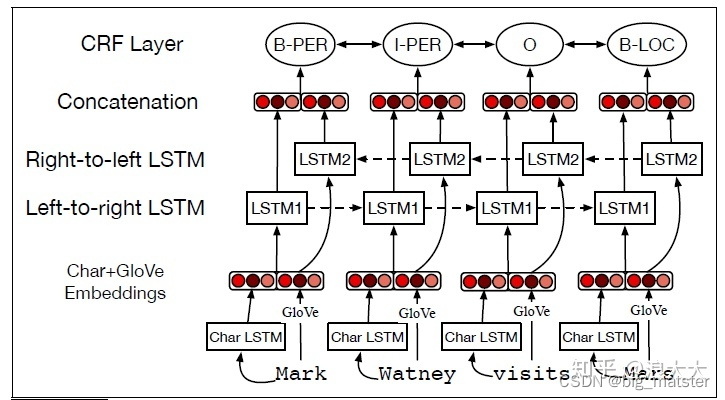
NER的标准神经算法是基于bi-LSTM。回想一下,在这个模型中,输入单词wi的单词和字符嵌入。这些通过左到右的LSTM和右向左LSTM,其输出被连接(或其他组合)在位置上生成一个单一的输出层。在最简单的方法中,这个层可以直接传递到一个softmax上,它在所有标签上创建一个概率分布,最可能的标记被选择为
t
i
t_i
ti
。对于被命名为标记这种贪婪的解码方法的实体来说,解码是不够的,因为它不允许我们强加相邻标签的强大约束。,标签I-PER必须遵循另一个i / b / b / b。相反,CRF层通常在双lstm输出的顶部使用,Viterbi解码算法被用来解码。图17.8显示了算法的草图:
基于规则的NER
虽然机器学习(神经或MEMM/CRF)序列模型是学术研究的规范,但NER的商业方法通常基于列表和规则的实用组合,还有少量的监督机器学习。
例如IBM系统T是一个文本理解结构,在这种结构中,一个用户指定复杂声明标记任务的约束在一个正式的查询语言,包括正则表达式、字典、语义约束,NLP运营商,和表结构,所有这些系统编译成一个高效提取器,一个常见的方法是使重复的基于规则的通过一个文本,允许一个通过影响下的结果。
这些阶段通常首先涉及,使用具有极高精确度但召回率较低的规则。后续阶段采用更加容易出错的统计方法,将第一次传递的输出考虑在内。
学术界基本上以纯统计序列模型为主,但工业上处理命名实体的方法还是会更加实际一些,监督学习加上一些规则,最为常用的方法是通过序列,经上一个序列结果作为输入传递到下一个序列中。
- 第一步,用高精准度的规则去标记模棱两可的命名实体。
- 第二步,寻找之前找到的名字的子串。
- 第三步,将特定领域的词语列表与之前识别出的命名实体进行对比。
- 第四步,应用概率序列标注模型将之前的标签作为特征。
关系抽取
关系抽取需要从文本中抽取两个或多个实体之间的语义关系,主要方法有下麦呢几类:
- 基本模板的方法(hand-written patterns)
- 基于触发词/字符串
- 基于依存句法。
- 监督学习
- 机器学习
- 深度学习
- 半监督/无监督学习
- Bootstrapping
- Distant supervision
- Unsupervised learning from the web
这种模式可以用图数据库去做。
基于模板的方法
关系提取最早也是最常见的算法是词汇句法模式。考虑下面这句话:

多数人并不知道什么是凝胶体,但它们很容易推断出它是一种一种下胚层)红藻,不管其是什么,其提出了以下词汇句法模式。:

但是手写模型虽然有高精准度,可以专门适合于某种模型,但是另一方面来说,基本上它们都是低回归率的,需要花很多时间去做。
监督学习去做关系提取的过程如下:首先特定的关系和命名实体已经选择了,训练集语料手动去标注关系和命名实体,接着就是注释的语料就是用来去训练分类器,去标注没有见过的训练集。
最直接的方法有3步:
- ,找寻一对命名实体。通常在一句话中。
- 二元分类器的作用是判断两个命名实体之间是否有关系。
- 分类器将用来去标记命名实体之间的关系。
伪代码可以这样描述:

对于命名体识别,在这个过程中最重要的步骤就是去辨认有用的接口特征
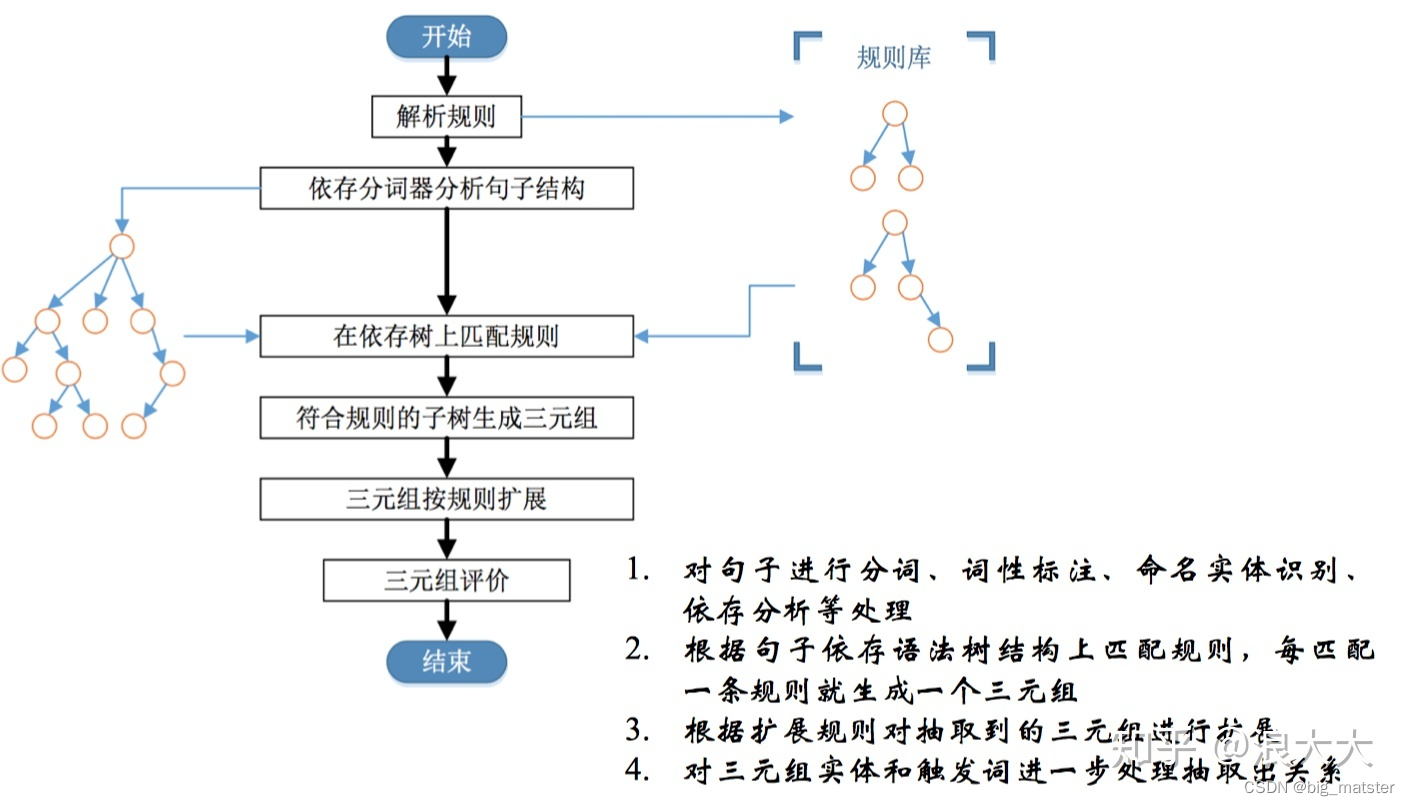
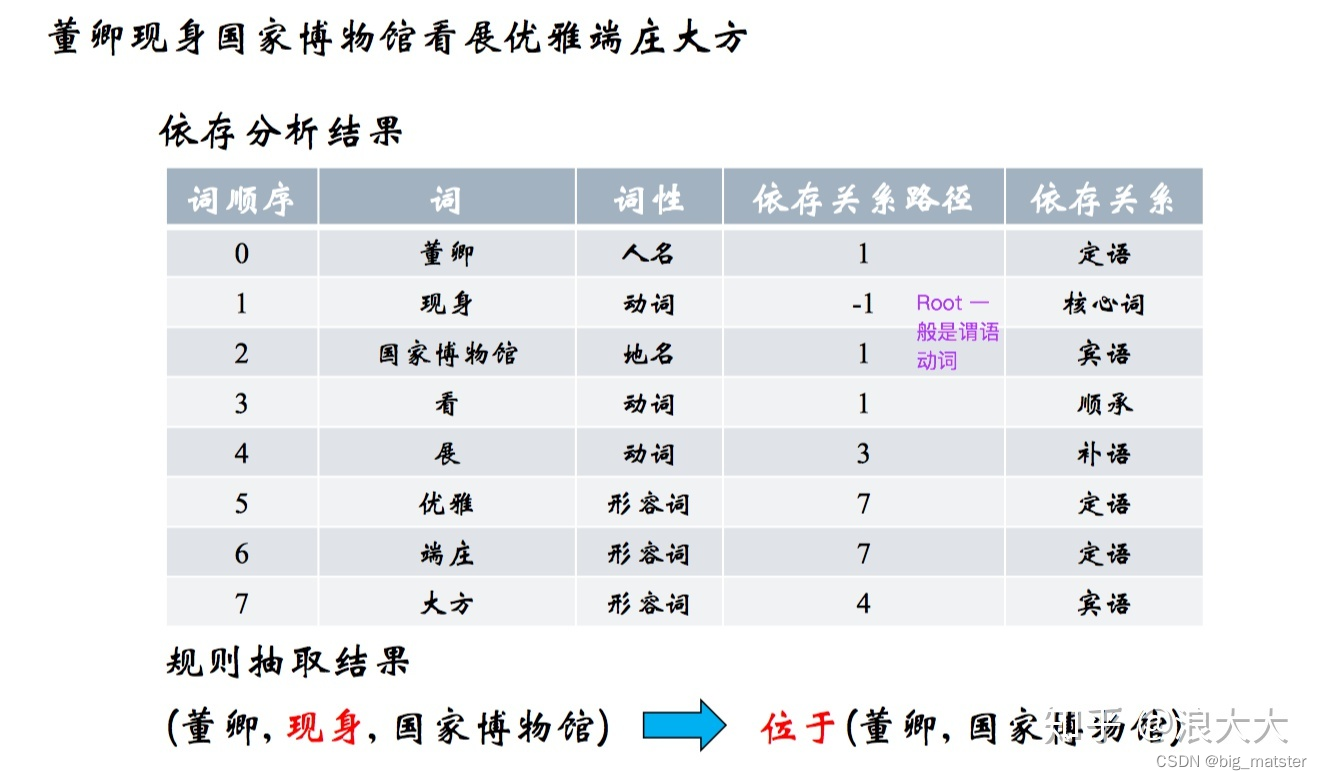
基于依存句法
通常可以以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定,流程为:
监督和深度学习
深度学习方法有分为两大类:pipeline 和 joint model
- Pipeline
- 吧实体识别和关系分类作为两个独立的过程,不会相互影响,关系识别依赖于实体识别的效果。
-
- Joint Model
- 实体识别和关系分类的过程共同优化
深度学习用到的特征通常育:
- Position embeddings
- Word embeddings
- Knowledge embeddings
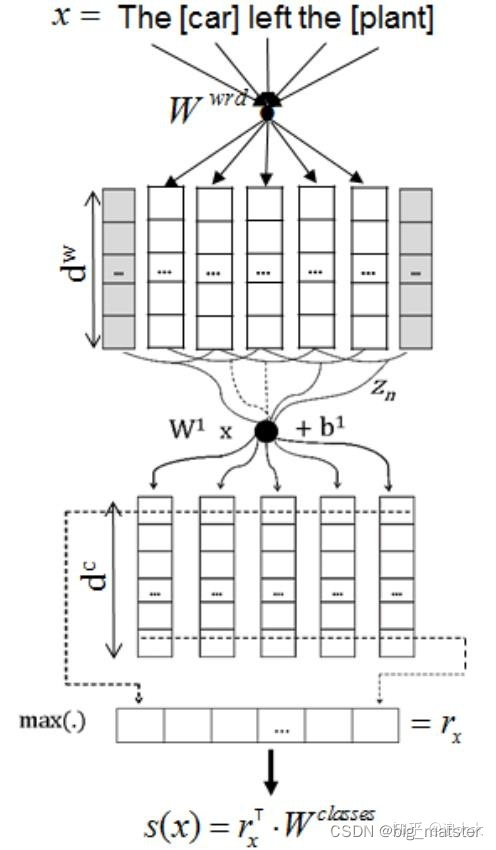
模型通常有$ CNN/RNN + attention$,损失函数 r a n k i n g l o s s ranking loss rankingloss 要优于交叉熵。
CR-CNN
总结
慢慢的会将关系识别入门,并搞懂,争取将那个比赛打通,并建立自己的模型思路和框架思路。