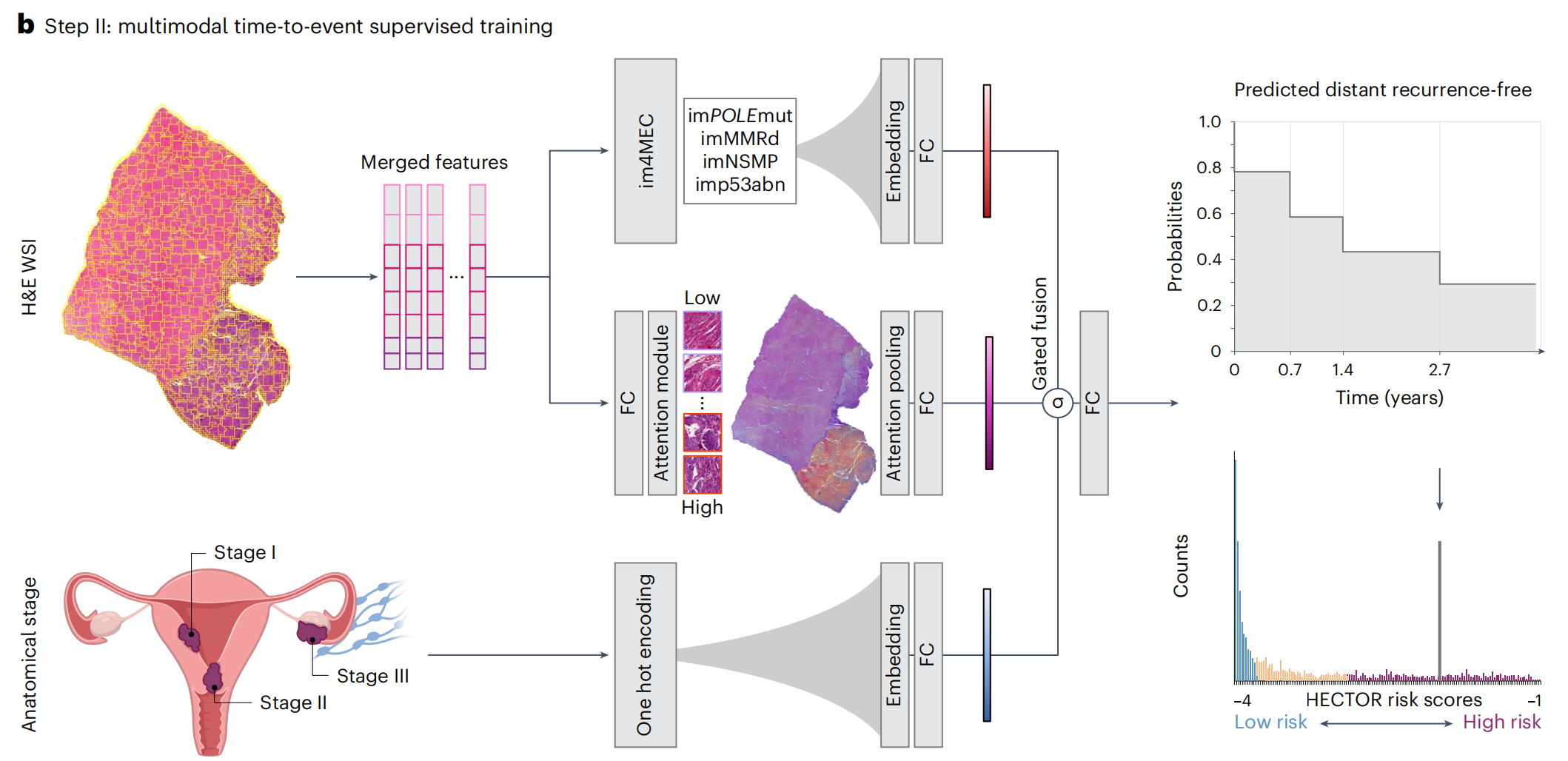
第一种方法:
按照某列进行由大到小的排序,然后再进去去重,保留第一个值,最终保留的结果就是最大值的数据
# 由大到小排序
data_frame = data_frame.sort_values(by='column_a', ascending=False)
# 按照column_b列去重保留第一条,剩下的值即为最大值
data_frame.drop_duplicates(labels='column_b', keep='first', inplace=True)第二种方法:
获取某列最大值的索引,然后再反取索引对应的行即可
比如,有一个daframe有A,B,C三列,现在需要取C列每个值对应A列最大的值:
df = pd.DataFrame({
'A': [1, 4, 7, 10, 2],
'B': [5, 2, 9, 3, 6],
'C': [8, 8, 1, 1, 1]
})
print(df)
print('----------------')
# 需要取C列每个值对应的A列的最大值
df_new = df.groupby('C')['A'].agg(pd.Series.idxmax)
print(df_new)
print('----------------')
df = df.iloc[df_new]
print(df)