有一个同学用我的推荐链接注册了tushare社区帐号https://tushare.pro/register?reg=671815,现在有了170分积分。目前使用数据的频率受限制。不过可以在调试期间通过python控制台获取数据,将数据保存在本地以后使用不用高频率访问tushare数据接口,访问频率限制影响不大。
>>> data = pro.stock_basic(fields='ts_code,symbol,name,area,industry,list_date,market,is_hs,list_status,exchange,delist_date,curr_type')
>>> type(data)
<class 'pandas.core.frame.DataFrame'>
>>> data
ts_code symbol name area ... list_status list_date delist_date is_hs
0 000001.SZ 000001 平安银行 深圳 ... L 19910403 None S
1 000002.SZ 000002 万科A 深圳 ... L 19910129 None S
2 000004.SZ 000004 国华网安 深圳 ... L 19910114 None N
3 000006.SZ 000006 深振业A 深圳 ... L 19920427 None S
4 000007.SZ 000007 *ST全新 深圳 ... L 19920413 None N
... ... ... ... ... ... ... ... ... ...
5360 873726.BJ 873726 卓兆点胶 江苏 ... L 20231019 None N
5361 873806.BJ 873806 云星宇 北京 ... L 20240111 None N
5362 873833.BJ 873833 美心翼申 重庆 ... L 20231108 None N
5363 920002.BJ 920002 万达轴承 None ... L 20240530 None N
5364 689009.SH 689009 九号公司-WD 北京 ... L 20201029 None None
[5365 rows x 12 columns]
>>> data.info
<bound method DataFrame.info of ts_code symbol name area ... list_status list_date delist_date is_hs
0 000001.SZ 000001 平安银行 深圳 ... L 19910403 None S
1 000002.SZ 000002 万科A 深圳 ... L 19910129 None S
2 000004.SZ 000004 国华网安 深圳 ... L 19910114 None N
3 000006.SZ 000006 深振业A 深圳 ... L 19920427 None S
4 000007.SZ 000007 *ST全新 深圳 ... L 19920413 None N
... ... ... ... ... ... ... ... ... ...
5360 873726.BJ 873726 卓兆点胶 江苏 ... L 20231019 None N
5361 873806.BJ 873806 云星宇 北京 ... L 20240111 None N
5362 873833.BJ 873833 美心翼申 重庆 ... L 20231108 None N
5363 920002.BJ 920002 万达轴承 None ... L 20240530 None N
5364 689009.SH 689009 九号公司-WD 北京 ... L 20201029 None None
[5365 rows x 12 columns]>
>>> data.describe()
ts_code symbol name area ... list_status list_date delist_date is_hs
count 5365 5365 5365 5358 ... 5365 5365 0 5364
unique 5365 5365 5364 32 ... 1 2727 0 3
top 000001.SZ 000001 三维股份 浙江 ... L 20200727 NaN N
freq 1 1 2 706 ... 5365 31 NaN 2481
[4 rows x 12 columns]
>>> data.index
RangeIndex(start=0, stop=5365, step=1)
>>> data.columns
Index(['ts_code', 'symbol', 'name', 'area', 'industry', 'market', 'exchange',
'curr_type', 'list_status', 'list_date', 'delist_date', 'is_hs'],
dtype='object')
>>> data.shape
(5365, 12)
>>> data.shape[0]
5365
>>> data.shape[1]
12
>>> data.values
array([['000001.SZ', '000001', '平安银行', ..., '19910403', None, 'S'],
['000002.SZ', '000002', '万科A', ..., '19910129', None, 'S'],
['000004.SZ', '000004', '国华网安', ..., '19910114', None, 'N'],
...,
['873833.BJ', '873833', '美心翼申', ..., '20231108', None, 'N'],
['920002.BJ', '920002', '万达轴承', ..., '20240530', None, 'N'],
['689009.SH', '689009', '九号公司-WD', ..., '20201029', None, None]],
dtype=object)
>>>
>>> print(data.dtypes)
ts_code object
symbol object
name object
area object
industry object
market object
exchange object
curr_type object
list_status object
list_date object
delist_date object
is_hs object
dtype: object
>>> 1、DataFrame操作
tushare pro接口返回的数据类型<class 'pandas.core.frame.DataFrame'>
>>> type(data)
<class 'pandas.core.frame.DataFrame'>
从上面可以看到data = pro.stock_basic(fields='ts_code,symbol,name,area,industry,list_date,market,is_hs,list_status,exchange,delist_date,curr_type')返回的数据是[5365 rows x 12 columns]
pandas.DataFrame.info
打印一个DataFrame的简要介绍(index范围、columns的dtype、非空值的数量和内存的使用情况):
DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=None)[source]
verbose(adj 冗长的): bool, optional,决定是否打印完整的摘要, 如果为False,那么会省略一部分
buf: writable buffer, defaults to sys.stdout,,决定将输出发送到哪里,默认情况下, 输出打印到sys.stdout
max_cols: int, optional 从“详细输出”转换为“缩减输出”,如果DataFrame的列数超过max_cols,则缩减输出。
memory_usage: bool, str, optional 决定是否应显示DataFrame元素(包括索引)的总内存使用情况,默认情况下为True。True始终显示内存使用情况;False永远不会显示内存使用情况。
show_counts: bool, optional,是否显示非空值的数量,值为True始终显示计数,而值为False则不显示计数
>>> data.info(verbose=True)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5365 entries, 0 to 5364
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ts_code 5365 non-null object
1 symbol 5365 non-null object
2 name 5365 non-null object
3 area 5358 non-null object
4 industry 5358 non-null object
5 market 5365 non-null object
6 exchange 5365 non-null object
7 curr_type 5365 non-null object
8 list_status 5365 non-null object
9 list_date 5365 non-null object
10 delist_date 0 non-null object
11 is_hs 5364 non-null object
dtypes: object(12)
memory usage: 251.5+ KB
>>> data.info(verbose=False)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5365 entries, 0 to 5364
Columns: 12 entries, ts_code to is_hs
dtypes: object(12)
memory usage: 251.5+ KB
>>>
>>> print(data.tail())
ts_code symbol name area ... list_status list_date delist_date is_hs
5360 873726.BJ 873726 卓兆点胶 江苏 ... L 20231019 None N
5361 873806.BJ 873806 云星宇 北京 ... L 20240111 None N
5362 873833.BJ 873833 美心翼申 重庆 ... L 20231108 None N
5363 920002.BJ 920002 万达轴承 None ... L 20240530 None N
5364 689009.SH 689009 九号公司-WD 北京 ... L 20201029 None None[5 rows x 12 columns]
>>> print(data.head())
ts_code symbol name area ... list_status list_date delist_date is_hs
0 000001.SZ 000001 平安银行 深圳 ... L 19910403 None S
1 000002.SZ 000002 万科A 深圳 ... L 19910129 None S
2 000004.SZ 000004 国华网安 深圳 ... L 19910114 None N
3 000006.SZ 000006 深振业A 深圳 ... L 19920427 None S
4 000007.SZ 000007 *ST全新 深圳 ... L 19920413 None N[5 rows x 12 columns]
>>>
# 获得DataFrame行索引信息
data.index
# 获得DataFrame列索引信息
data.columns# 获得DataFrame的size
data.shape
# 获得DataFrame的行数
data.shape[0]# 获得DataFrame的 列数
data.shape[1]# 获得DataFrame中的值
data.values# 获得DataFrame中列值数据类型
data.dtypes
Pandas describe()
Pandas describe()用于查看一些基本的统计详细信息,例如每列的均值、标准差、最大值、最小值和众数
>>> data.describe()
ts_code symbol name area ... list_status list_date delist_date is_hs
count 5365 5365 5365 5358 ... 5365 5365 0 5364
unique 5365 5365 5364 32 ... 1 2727 0 3
top 000001.SZ 000001 三维股份 浙江 ... L 20200727 NaN N
freq 1 1 2 706 ... 5365 31 NaN 2481[4 rows x 12 columns]
>>> type(data.describe())
<class 'pandas.core.frame.DataFrame'>
>>>
describe()的输出也是DataFrame
>>> import pandas as pd
>>> import pdb
>>>
dict_data={"X":list("abcdef"),"Y":list("defghi"),"Z":list("ghijkl")}
df=pd.DataFrame.from_dict(dict_data)
df.index=["A","B","C","D","E","F"]
>>> df
X Y Z
A a d g
B b e h
C c f i
D d g j
E e h k
F f i l
>>> df.describe()
X Y Z
count 6 6 6
unique 6 6 6
top a d g
freq 1 1 1
>>>
>>> type(df.describe())
<class 'pandas.core.frame.DataFrame'>
>>>
>>> # A 行 X 列数据,必须两个数据都输入,否则报错
print(df.at["A","X"])
# 第二 行 第二 列数据,序号从0开始
print(df.iat[2,2])
a
i
>>>
>>> # 指定行名和列名的方式,和at的用法相同
print(df.loc["A","X"],"\n","*"*20)
# 可以完整切片,这是 at 做不到的
print(df.loc[:,"X"],"\n","*"*20)
# 可以从某一行开始切片
print(df.loc["B":,"X"],"\n","*"*20)
# 可以只切某一列
print(df.loc["B",:],"\n","*"*20)
# 和指定上一条代码效果是一样的
print(df.loc["B"],"\n","*"*20)
a
********************
A a
B b
C c
D d
E e
F f
Name: X, dtype: object
********************
B b
C c
D d
E e
F f
Name: X, dtype: object
********************
X b
Y e
Z h
Name: B, dtype: object
********************
X b
Y e
Z h
Name: B, dtype: object
********************
>>>
>>> # 指定行号和列号的方式,和 loc 的用法相同
print(df.iloc[0,0],"\n","*"*20)
# 可以完整切片
print(df.iloc[:,0],"\n","*"*20)
# 可以从某一行开始切片
print(df.iloc[1:,0],"\n","*"*20)
# 可以只切某一列
print(df.iloc[1,:],"\n","*"*20)
# 和指定上一条代码效果是一样的
print(df.iloc[1],"\n","*"*20)
a
********************
A a
B b
C c
D d
E e
F f
Name: X, dtype: object
********************
B b
C c
D d
E e
F f
Name: X, dtype: object
********************
X b
Y e
Z h
Name: B, dtype: object
********************
X b
Y e
Z h
Name: B, dtype: object
********************
>>>DataFrame索引数据
at 函数:通过行名和列名来取值
loc函数主要通过 行标签 索引行数据
iloc函数主要通过行号、索引行数据
导出数据
dataframe可以使用to_csv方法方便地导出到csv文件中,如果数据中含有中文,一般encoding指定为”utf-8″,否则导出时程序会因为不能识别相应的字符串而抛出异常,index指定为False表示不用导出dataframe的index数据。
>>> data.to_csv("C:\\Users\\Downloads\\stock.csv", index=False)
>>> data.to_csv("C:\\Users\\Downloads\\stock_indx.csv", index=True)
index为False和True时区别如下

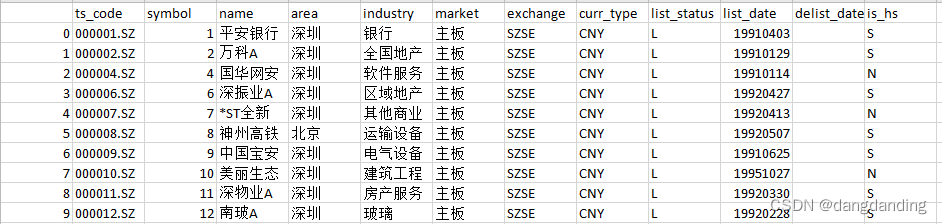
从文件读取数据到pandas
pandas在读取csv文件是通过read_csv这个函数读取
base_data = pd.read_csv("C:\\Users\\Downloads\\stock.csv")
base_data1 = pd.read_csv("C:\\Users\\Downloads\\stock_idx.csv") #比上一个文件多一列