目录
Abstract
Modernizing a ConvNet: a Roadmap
2.1.Training Techniques
2.2. Macro Design
2.3. ResNeXt-ify
2.4. Inverted Bottleneck
2.5. Large Kernel Sizes
2.6. Micro Design
论文:https://arxiv.org/abs/2201.03545
代码:GitHub - facebookresearch/ConvNeXt: Code release for ConvNeXt model
Abstract
视觉识别的“咆哮的20年代”始于ViT的引入,它迅速取代卷积网络(ConvNet)成为最先进的图像分类模型。另一方面,普通的ViT在应用于一般的计算机视觉任务(如物体检测和语义分割)时面临困难。正是分层Transformers(例如Swin Transformer)重新引入了几个ConvNets先验,使得Transformer作为通用视觉主干实际上可行,并在各种视觉任务中表现出出色的性能。然而,这种混合方法的有效性在很大程度上仍然归功于Transformer的内在优势,而不是卷积的固有归纳偏差。在这项工作中,作者重新检查了设计空间,并测试了纯ConvNet所能达到的极限。作者逐步将标准ResNet“modernize”,使其朝着ViT的设计方向发展,并在此过程中发现了导致性能差异的几个关键组件。这一探索的结果是一系列被称为ConvNeXt的纯ConvNet模型。ConvNeXts完全由标准ConvNet模块构建,在精度和可扩展性方面与Transformer竞争,实现了87.8%的ImageNet top-1精度,在COCO检测和ADE20K分割方面优于Swin transformer,同时保持了标准ConvNets的简单性和效率。
Modernizing a ConvNet: a Roadmap
在这项工作中,作者研究了ConvNets和Transformer之间的结构差异,并在比较网络性能时尝试识别混淆变量。作者的研究旨在减小ViT前时代和后时代的差距,以及测试纯ConvNet所能实现的极限。
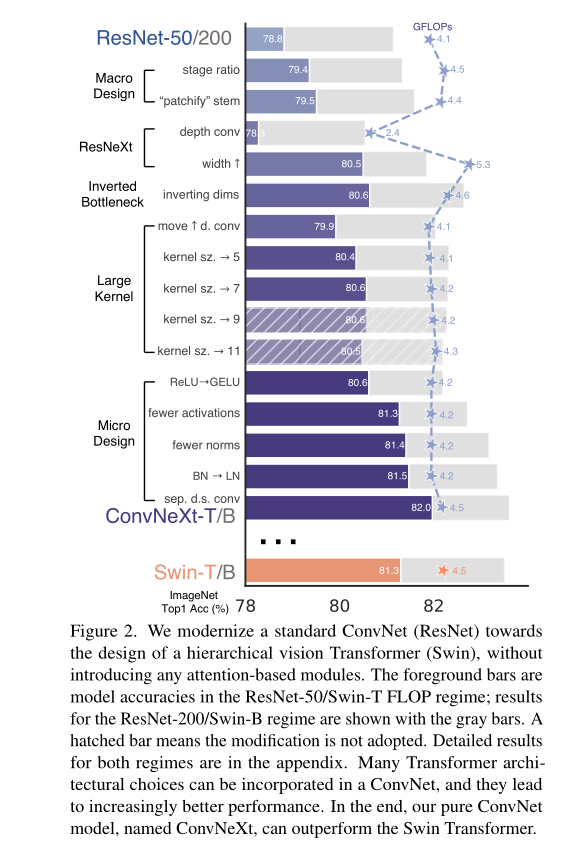
在本节中,作者提供了一个从ResNet到ConvNet的路线。在较高层次上,作者的探索旨在研究和遵循来自Swin Transformer的不同层次的设计,同时保持网络作为标准ConvNet的简单性。我们的探索路线如下。起点是ResNet-50模型。首先用类似于ViT的训练技术来训练它,并获得了与原始ResNet-50相比有很大改善的结果。这是我们的基线。然后,作者研究了一系列设计决策,并将其总结为1)宏观设计,2)ResNeXt, 3)反向瓶颈,4)大内核尺寸,以及5)各种分层的微观设计。在图2中展示了“网络现代化”的每个步骤所能实现的过程和结果。由于网络复杂性与最终性能密切相关,flop在探索过程中大致受控,尽管在中间步骤,flop可能高于或低于参考模型。所有模型都在ImageNet-1K上进行训练和评估。
2.1.Training Techniques
除了网络架构的设计,训练过程也会影响最终的性能。ViT不仅带来了一套新的模块和架构设计,还为视觉引入了不同的训练技术(例如AdamW优化器)。这主要涉及优化策略和相关的超参数。因此,作者探索的第一步就是使用ViT的训练方法训练基线模型ResNet50/200。最近的研究表明,一套先进的训练技术可以显著地提高ResNet-50的性能。在该研究中,作者使用了一个接近DieT和Swim Transformer的训练方法。ResNet的训练从原来的90个epoch扩展到300个epoch。作者使用AdamW优化器,数据增强技术如Mixup,Cutmix,RandAugment , Random Erasing,正则化方案包括随机深度和标签平滑。就其本身而言,这种增强的训练方法将ResNet-50模型的性能从76.1%提高到78.8%(+2.7%),这意味着传统ConvNets和ViT之间的很大一部分性能差异可能是由于训练技术。作者将在整个“modernization”过程中使用这个具有相同超参数的固定训练配方。在ResNet-50系统中,每个报告的准确度都是由三种不同的随机种子训练获得的平均值。
2.2. Macro Design
本节分析Swim Transformer的宏观网络设计。Swim Tranformer遵循ConvNets使用多级设计,其中每个阶段具有不同的特征映射分辨率。有两个有趣的考虑因素:阶段计算比例和"stem cell"结构。
- 改变阶段计算比例。ResNet中跨阶段计算分布的原始设计很大程度上是经验的。重的“res4”级是为了兼容下游任务,如目标检测,其中探测器头在14X14特征平面上。另一方面,Swim-T遵循同样的原则,但是阶段计算比例略有不同,为1:1:3:1.对于较大的Swim-Transformer比例为1:1:9:1.根据设计,作者将每个阶段的块数量从ResNet-50中的(3,4,6,3)调整为(3,3,9,3),这也使flop与Swin-T对齐。模型精度由78.8%提高到79.4%。值得注意的是,研究人员已经彻底研究了计算的分布[1,2],并且可能存在更优化的设计.
[1] Ilija Radosavovic, Justin Johnson, Saining Xie, Wan-YenLo, and Piotr Dollár. On network design spaces for visual recognition. In ICCV, 2019.
[2] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaim-ing He, and Piotr Dollár. Designing network design spaces.In CVPR, 2020.- 将根部”Patchify“。一般来说,stem cell的设计主要考虑的是在网络的初始阶段如何处理输入图像。由于自然图像固有的冗余,普通stem cell结构会在标准的ConvNets和ViT中积极地将输入图像下采样到适当的特征图大小。标准ResNet中的stem cell包含一个7x7的卷积层,stride为2,然后是一个最大池化层,这产生了输入图像的4倍下采样。在Vi'TiT中,更激进的“补丁”策略被用作stem cell,这对应于一个大的内核大小(例如核大小= 14或16)和非重叠卷积。Swin Transformer使用了类似的“补丁”层,但补丁大小较小,为4,以适应架构的多级设计。作者用使用4x4,stride为4卷积层实现的修补层取代resnet风格的stem cell。准确率从79.4%提高到79.5%。这表明ResNet中的干细胞可能被更简单的“补丁”层à la ViT所取代,这将导致类似的性能。我们将在网络中使用“patchify stem”(4x4非重叠卷积)。
2.3. ResNeXt-ify
在这一部分中,作者尝试采用ResNeXt的思想,它比普通ResNet具有更好的FLOPs/准确性权衡。核心组件是分组卷积,其中卷积滤波器被分成不同的组。
在高层次上,ResNeXt的指导原则是“使用更多的组,扩大宽度”。更准确地说,ResNeXt在瓶颈3x3 conv层使用分组卷积。由于这大大降低了flop,因此可以通过扩展网络宽度来弥补容量损失。作者使用深度卷积,这是分组卷积的一种特殊情况,分组的数量等于通道的数量。深度卷积已经通过MobileNet和Xception普及。作者注意到,深度卷积类似于自注意中的加权和运算,它在每个通道的基础上运算,即只在空间维度上混合信息。深度卷积和1x1卷积的组合导致空间和通道混合的分离,这是ViT共享的属性,其中每个操作要么跨空间维度混合信息,要么跨通道维度混合信息,但不是同时混合。深度卷积的使用有效地降低了网络flop,并如预期的那样,降低了精度。
根据ResNeXt中提出的策略,作者将网络宽度增加到与Swin-T相同的通道数量(从64增加到96)。这使得网络性能达到80.5%,FLOPs增加(5.3G)。
2.4. Inverted Bottleneck
一个重要的设计在每一个Transformer块是它创建一个反向瓶颈,即,MLP块的隐藏尺寸是输入尺寸的四倍宽。(见图4)。
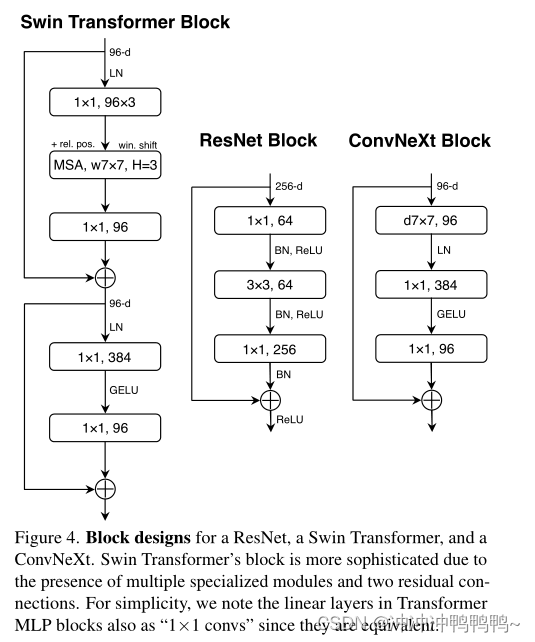
有趣的是,这种Transformer设计与ConvNets中使用的膨胀比为4的反向瓶颈设计相连接。
这里作者探讨反向瓶颈设计。图3 (a)到(b)说明了这些配置。尽管深度卷积层的FLOPs增加了,但由于降采样残差块的shortcut 1⇥1 conv层的FLOPs显著降低,这一变化将整个网络的FLOPs降低到4.6G。有趣的是,这导致性能略有提高(80.5%到80.6%)。在ResNet-200 / Swin-B机制中,这一步骤带来了更多的收益(81.9%至82.6%),同时降低了FLOPs。
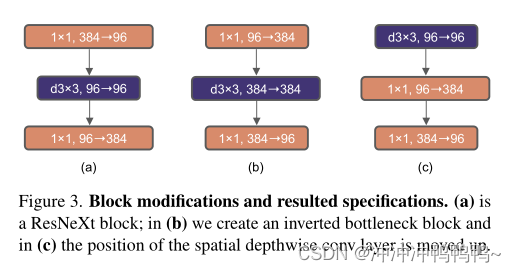
2.5. Large Kernel Sizes
在这一部分的探索中,主要关注大型卷积核。ViT最显著的特点是其非局部的自我关注,这使得每一层都有一个全局的接受域。虽然大内核的ConvNets在过去已经被使用,但黄金标准(由VGGNet推广)是堆叠小内核(3x3)的conv层,这些层在现代GPU上具有高效的硬件实现。尽管Swin transformer在self-attention块中重新引入了本地窗口,但窗口大小至少为7X7,明显大于ResNe(X)t内核大小3X3。在这里重新讨论ConvNets中大内核大小卷积的使用。
Moving up depthwise conv layer .要探索大型内核,一个先决条件是向上移动深度转换层的位置(图3 (b)到(c))。这个设计决策在transformer中也很明显:MSA块被放置在MLP层之前。由于有一个倒置的瓶颈块,这是一个自然的设计选择,复杂/低效的模块(MSA,大内核conv)将有更少的通道,而高效、密集的 1×1 层将做繁重的工作。这个中间步骤将FLOPs降低到4.1G,导致性能暂时下降到79.9%。
Increasing the kernel size.有了所有这些准备,采用更大尺寸的卷积核的好处是明显的。作者实验了几种内核尺寸包括3、5、7、9和11,网络的性能从79.9% (3×3) 提高到80.6% (7×7) ,但网络的FLOPs基本保持不变。此外,作者观察到卷积核大小在 (7×7) 时候性能达到饱和点。在大容量模型中也验证了这一行为:当作者将内核大小增加到 (7×7) 时,ResNet-200机制模型并没有显示出进一步的增益。(这里在其他经典网络模型中已经证明,前面也说了,VGG就是 (7×7) )。
2.6. Micro Design
在本节中,作者将在微观尺度上研究其他几个架构差异——这里的大多数探索都是在层级别上完成的,重点是激活函数和归一化层的特定选择。
Replacing ReLU with GELU.NLP和视觉架构之间的一个差异是使用哪些激活函数的细节。随着时间的推移,已经开发了许多激活函数,但由于其简单和高效,整流线性单元(ReLU)仍然广泛用于ConvNets。在Transformer的原始论文中,ReLU也被用作激活函数。高斯误差线性单元,或GELU,可以被认为是ReLU的更平滑的变体,被用于最先进的Transformer,包括谷歌的BERT和OpenAI的GPT-2,以及最近的ViTs。作者发现,在他们的ConvNet中,ReLU也可以被GELU取代,尽管准确度保持不变(80.6%)。
Fewer activation functions. Transformer和ResNet块之间的一个小区别是Transformer的激活函数更少。考虑一个在MLP块中具有键/查询/值线性嵌入层、投影层和两个线性层的Transformer块。在MLP块中只存在一个激活函数。相比之下,通常的做法是将激活函数附加到每个卷积层,包括1x1 convs。在这里,作者将研究当坚持相同的策略时,性能是如何变化的。如图4所示,从剩余块中消除所有GELU层,只保留两个1x1层之间的一个,复制Transformer块的样式。该过程将结果提高了0.7% ,与Swin-T的性能基本相当。
Fewer normalization layers.Transformer通常也有更少的归一化层。这里删除了两个BatchNorm (BN)层,在cox1层之前只留下一个BN层。这进一步提高了性能,达到81.4%,已经超过了Swin-T的结果。本文中每个块的归一化层甚至比Transformer更少,因为根据经验,作者发现在块的开始添加一个额外的BN层并不能提高性能。
Substituting BN with LN.BatchNorm是ConvNets中的一个重要组成部分,它提高了收敛性,减少了过拟合。然而,BN也有许多复杂性,可能会对模型的性能产生不利影响。人们曾多次尝试开发替代的归一化技术,但在大多数视觉任务中,BN仍是首选。另一方面,Transformer中使用了更简单的层归一化(LN),从而在不同的应用场景中获得了良好的性能。
在原来的ResNet中直接用LN代替BN会导致性能次优。随着网络架构和训练技术的所有修改,在这里我们重新审视使用LN取代BN的影响。作者观察到我们的模型用LN训练没有任何困难;实际上,性能略好,准确率达到81.5%。从现在开始,将在每个剩余块中使用一个LayerNorm作为规范化的选择。
Separate downsampling layers.在ResNet中,空间下采样由每阶段开始的残差块实现,使用3x3 stride为2的卷积(和1x1 stride 2的卷积在快捷连接处)。在Swin Transformer中,在级之间添加了一个单独的下采样层。作者探索了类似的策略,其中作者使用2x2 stride 2 卷积层进行空间下采样。这种修改令人惊讶地导致了训练的发散。进一步的研究表明,在空间分辨率改变的地方添加归一化层有助于稳定训练。这些包括Swin Transformer中也使用的几个LN层:一个在每个下采样层之前,一个在阀杆之后,一个在最终的全局平均池化之后。可以将准确率提高到82.0%,大大超过了Swin-T的81.3%。