目录
前言
目的
思路
代码实现
1. 请求URL,获取源代码
2. 解析源代码,获取数据
3. 完善保存数据的函数save_data
4. 理清main函数逻辑,循环传递每一页有效信息的参数
完整代码
运行效果
总结
前言
近日,我们每周四都能刷到一堆“疯狂星期四”的梗图或者消息,那么如果真的Vivo50,我们该去哪里消费呢?假设我们来到一个新的城市,或者想知道我们爆了50金币网友所在的城市到底有没有相关店铺该怎么办?
那么我们就可以来进行一个小小的爬虫,一次编程,方便后面的每一次查询。
目的
1. 实现输入任意关键词查询店铺
2. 将所有店铺信息输出到控制台,自行选择是否保存到本地
3. 要求是封装好的结果,将各个功能分离
思路
1. 请求URL,获取源代码
2. 解析源代码,获取数据
3. 完善逻辑
代码实现
1. 请求URL,获取源代码
首先访问请求店铺信息页面(URL不便展示,放在评论区了),发现我们查询以后页面URL是不变的,那么我们就很自然的想到是一个动态请求。
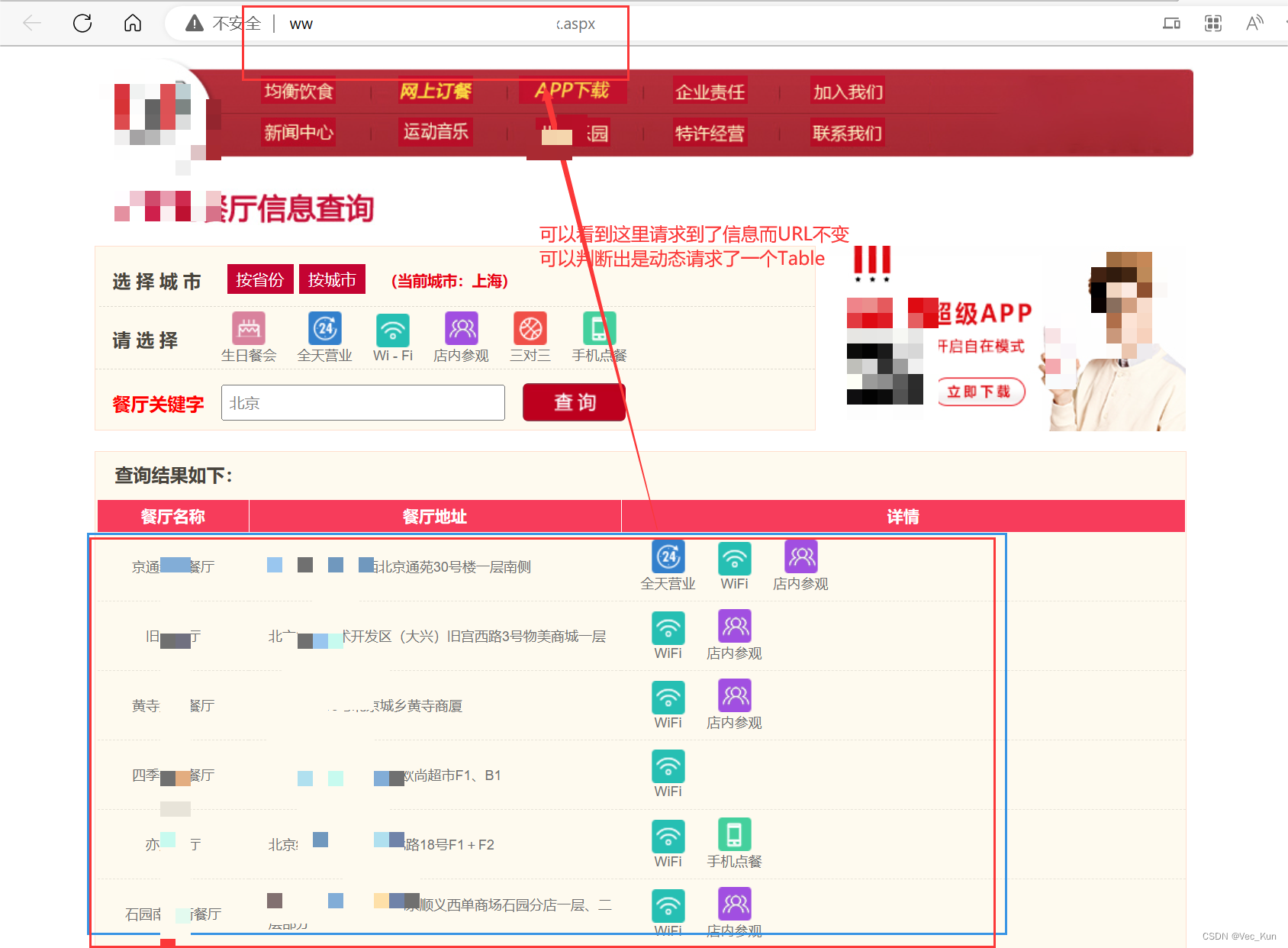
那么很熟悉,打开抓包工具,输入任意关键词,查询店铺,发现拿到了一个json:

打开标头项,可以拿到URL与请求方式,打开负载,可以拿到请求所需的参数,打开预览,可以发现里面包含了我们想要的数据。
import requests
import json
import csv
# 全局变量URL与UA
url = '见评论区'
UA = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61"
}
# 请求URL,获取源代码
def request_url(link, headers, params):
resp = requests.post(url=link, headers=headers, params=params)
resp.encoding = 'utf-8'
return resp.text2. 解析源代码,获取数据
解析源代码需要两个变量:请求结果与存储请求。参数一很好理解,它就是我们要解析的数据,参数二是我们自定义的是否存储到本地文件的一个变量,当它为y时选择调用save_data函数将信息保存到本地csv文件,为n时不调用,仅在控制台输出。
# 解析请求到的信息
def parse_data(resp, save):
data = json.loads(resp)
if len(data["Table1"]) == 0:
return True
# 如果Table1包含信息,那就遍历拿出每一条
for store_dict in data["Table1"]:
print(store_dict)
if save == 'y':
save_data(store_dict)3. 完善保存数据的函数save_data
# 保存店铺信息到本地
def save_data(store_dict):
with open('2_KFC_Store_List.csv', mode='a+', newline='', encoding='utf-8') as f:
csvwriter = csv.writer(f)
storeName = store_dict['storeName']
addressDetail = store_dict['addressDetail']
pro = store_dict['pro']
provinceName = store_dict['provinceName']
cityName = store_dict['cityName']
csvwriter.writerow([storeName, addressDetail, pro, provinceName, cityName])4. 理清main函数逻辑,循环传递每一页有效信息的参数
def main():
pageIndex = 1
store_name = input("欢迎使用KFC店铺查询系统!请输入您想要查询店铺的关键词\n")
save_query = input("是否保存店铺信息到本地?(y/n)\n")
if save_query == 'n':
print("正在处理信息...店铺信息将打印到控制台...")
if save_query == 'y':
print("正在处理信息...店铺信息将打印到控制台并保存到本地文件'2_KFC_Store_List.csv'...")
while True:
data_dict = {
"cname": "",
"pid": "",
"keyword": store_name,
"pageIndex": pageIndex,
"pageSize": 10
}
resp = request_url(url, UA, data_dict)
if parse_data(resp, save_query):
break
else:
pageIndex += 1
if __name__ == '__main__':
main()如上述代码, 当解析数据函数拿到的店铺信息为空时会返回True,当True时就结束循环,否则页码+1继续翻页。
同时也能注意到主函数运行前要先输入两个参数,一个是params中必需的查询关键词keyword,另一个是是否保存信息到本地的一个参数,为y或n。
完整代码
import requests
import json
import csv
# 全局变量URL与UA
url = '见评论区'
UA = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61"
}
# 请求URL,获取源代码
def request_url(link, headers, params):
resp = requests.post(url=link, headers=headers, params=params)
resp.encoding = 'utf-8'
return resp.text
# 解析请求到的信息
def parse_data(resp, save):
data = json.loads(resp)
if len(data["Table1"]) == 0:
return True
# 如果Table1包含信息,那就遍历拿出每一条
for store_dict in data["Table1"]:
print(store_dict)
if save == 'y':
save_data(store_dict)
# 保存店铺信息到本地
def save_data(store_dict):
with open('2_KFC_Store_List.csv', mode='a+', newline='', encoding='utf-8') as f:
csvwriter = csv.writer(f)
storeName = store_dict['storeName']
addressDetail = store_dict['addressDetail']
pro = store_dict['pro']
provinceName = store_dict['provinceName']
cityName = store_dict['cityName']
csvwriter.writerow([storeName, addressDetail, pro, provinceName, cityName])
def main():
pageIndex = 1
store_name = input("欢迎使用KFC店铺查询系统!请输入您想要查询店铺的关键词\n")
save_query = input("是否保存店铺信息到本地?(y/n)\n")
if save_query == 'n':
print("正在处理信息...店铺信息将打印到控制台...")
if save_query == 'y':
print("正在处理信息...店铺信息将打印到控制台并保存到本地文件'2_KFC_Store_List.csv'...")
while True:
data_dict = {
"cname": "",
"pid": "",
"keyword": store_name,
"pageIndex": pageIndex,
"pageSize": 10
}
resp = request_url(url, UA, data_dict)
if parse_data(resp, save_query):
break
else:
pageIndex += 1
if __name__ == '__main__':
main()
运行效果
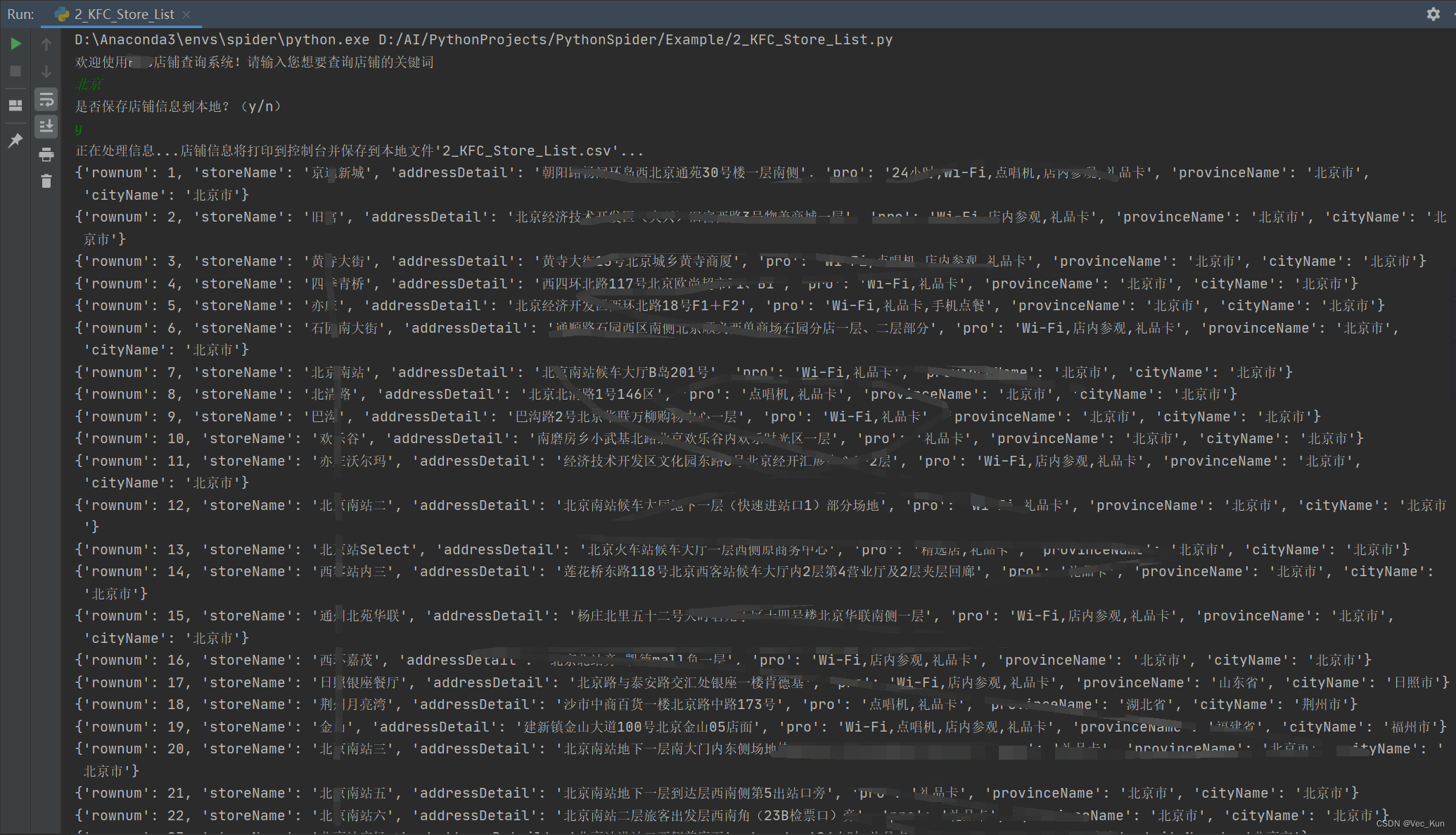
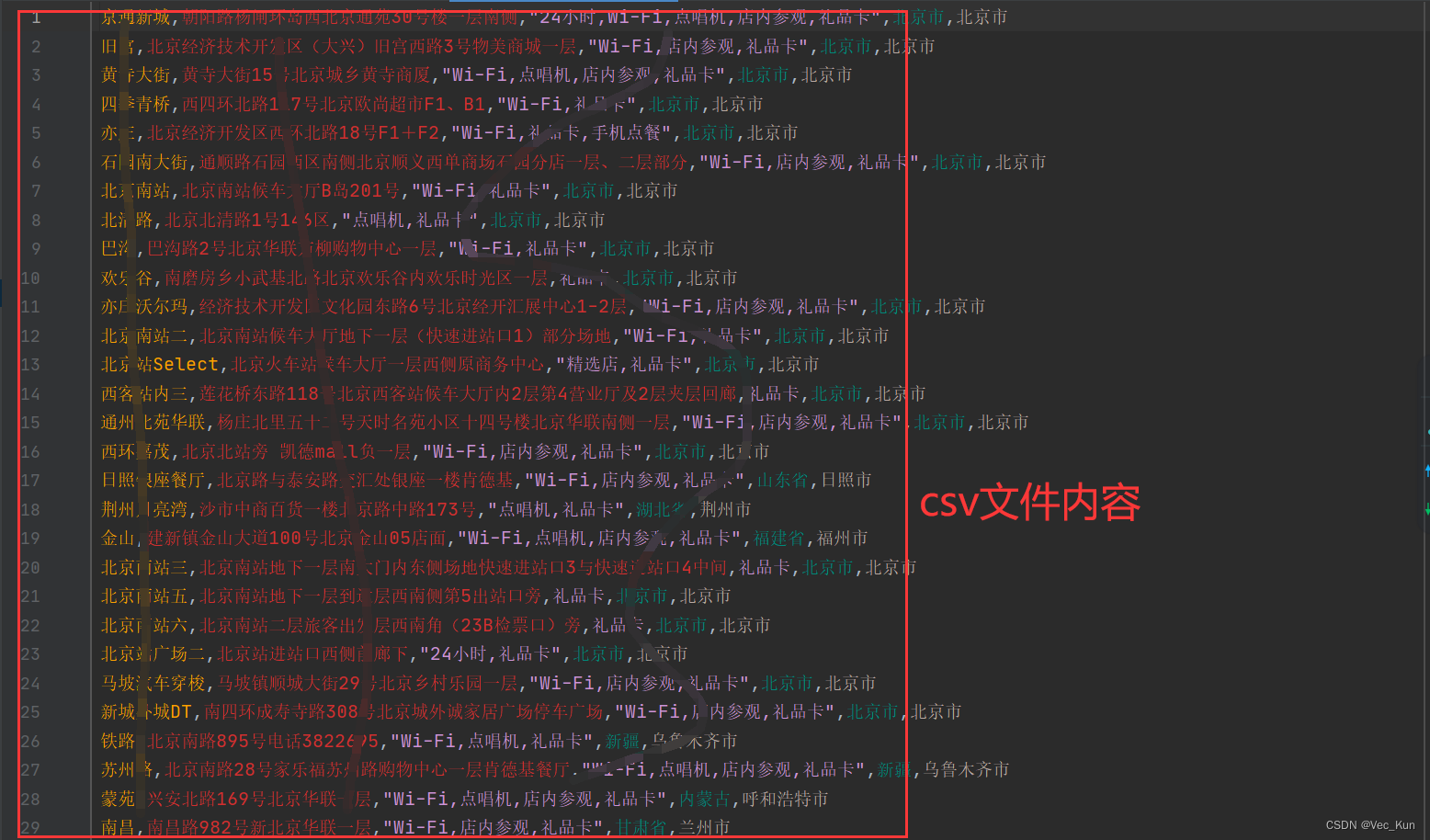
总结
本节我们练习了抓取指定关键词的某快餐所有店铺信息,较为综合,主要学习思路,可以举一反三。