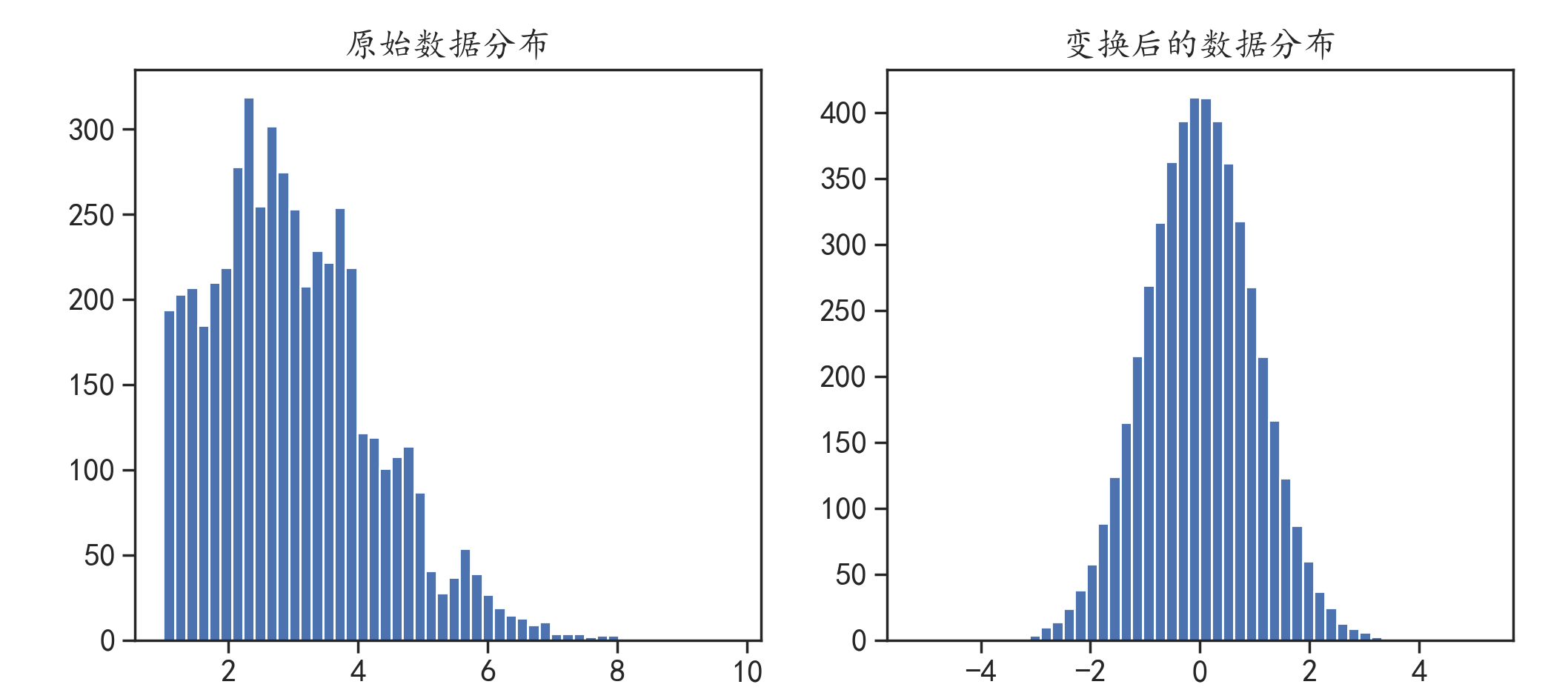
多种预训练任务解决NLP处理SMILES的多种弊端,代码:Knowledge-based-BERT,原文:Knowledge-based BERT: a method to extract molecular features like computational chemists,代码解析继续downstream_task。模型框架如下:

文章目录
- 1.load_data_for_random_splited
- 2.model
- 2.1.pos_weight
- 1.2.load_pretrained_model
- 3.run
- 3.1.run_an_eval_global_epoch
- 3.2.step
for task in args['task_name_list']:
args['task_name'] = task
args['data_path'] = '../data/task_data/' + args['task_name'] + '.npy'
all_times_train_result = []
all_times_val_result = []
all_times_test_result = []
result_pd = pd.DataFrame()
result_pd['index'] = ['roc_auc', 'accuracy', 'sensitivity', 'specificity', 'f1-score', 'precision', 'recall',
'error rate', 'mcc']
for time_id in range(args['times']):
set_random_seed(2020+time_id)
train_set, val_set, test_set, task_number = build_data.load_data_for_random_splited(
data_path=args['data_path'], shuffle=True
)
print("Molecule graph is loaded!")
1.load_data_for_random_splited
def load_data_for_random_splited(data_path='example.npy', shuffle=True):
data = np.load(data_path, allow_pickle=True)
smiles_list = data[0]
tokens_idx_list = data[1]
labels_list = data[2]
mask_list = data[3]
group_list = data[4]
if shuffle:
random.shuffle(group_list)
print(group_list)
train_set = []
val_set = []
test_set = []
task_number = len(labels_list[1])
for i, group in enumerate(group_list):
molecule = [smiles_list[i], tokens_idx_list[i], labels_list[i], mask_list[i]]
if group == 'training':
train_set.append(molecule)
elif group == 'val':
val_set.append(molecule)
else:
test_set.append(molecule)
print('Training set: {}, Validation set: {}, Test set: {}, task number: {}'.format(
len(train_set), len(val_set), len(test_set), task_number))
return train_set, val_set, test_set, task_number
2.model
train_loader = DataLoader(dataset=train_set,
batch_size=args['batch_size'],
shuffle=True,
collate_fn=collate_data)
val_loader = DataLoader(dataset=val_set,
batch_size=args['batch_size'],
collate_fn=collate_data)
test_loader = DataLoader(dataset=test_set,
batch_size=args['batch_size'],
collate_fn=collate_data)
pos_weight_task = pos_weight(train_set)
one_time_train_result = []
one_time_val_result = []
one_time_test_result = []
print('***************************************************************************************************')
print('{}, {}/{} time'.format(args['task_name'], time_id+1, args['times']))
print('***************************************************************************************************')
loss_criterion = torch.nn.BCEWithLogitsLoss(reduction='none', pos_weight=pos_weight_task.to(args['device']))
model = K_BERT_WCL(d_model=args['d_model'], n_layers=args['n_layers'], vocab_size=args['vocab_size'],
maxlen=args['maxlen'], d_k=args['d_k'], d_v=args['d_v'], n_heads=args['n_heads'], d_ff=args['d_ff'],
global_label_dim=args['global_labels_dim'], atom_label_dim=args['atom_labels_dim'])
stopper = EarlyStopping(patience=args['patience'], pretrained_model=args['pretrain_model'],
pretrain_layer=args['pretrain_layer'],
task_name=args['task_name']+'_downstream_k_bert_wcl', mode=args['mode'])
model.to(args['device'])
stopper.load_pretrained_model(model)
optimizer = Adam(model.parameters(), lr=args['lr'])
2.1.pos_weight
def pos_weight(train_set):
smiles, tokens_idx, labels, mask = map(list, zip(*train_set))
task_pos_weight_list = []
for j in range(len(labels[1])):
num_pos = 0
num_impos = 0
for i in labels:
if i[j] == 1:
num_pos = num_pos + 1
if i[j] == 0:
num_impos = num_impos + 1
task_pos_weight = num_impos / (num_pos+0.00000001)
task_pos_weight_list.append(task_pos_weight)
return torch.tensor(task_pos_weight_list)
- 这里不理解为什么这么设置 task_pos_weight_list
1.2.load_pretrained_model
def load_pretrained_model(self, model):
if self.pretrain_layer == 1:
pretrained_parameters = ['embedding.tok_embed.weight', 'embedding.pos_embed.weight', 'embedding.norm.weight', 'embedding.norm.bias', 'layers.0.enc_self_attn.linear.weight', 'layers.0.enc_self_attn.linear.bias', 'layers.0.enc_self_attn.layernorm.weight', 'layers.0.enc_self_attn.layernorm.bias', 'layers.0.enc_self_attn.W_Q.weight', 'layers.0.enc_self_attn.W_Q.bias', 'layers.0.enc_self_attn.W_K.weight', 'layers.0.enc_self_attn.W_K.bias', 'layers.0.enc_self_attn.W_V.weight', 'layers.0.enc_self_attn.W_V.bias', 'layers.0.pos_ffn.fc.0.weight', 'layers.0.pos_ffn.fc.2.weight', 'layers.0.pos_ffn.layernorm.weight', 'layers.0.pos_ffn.layernorm.bias']
elif self.pretrain_layer == 2:
pretrained_parameters = ['embedding.tok_embed.weight', 'embedding.pos_embed.weight', 'embedding.norm.weight', 'embedding.norm.bias', 'layers.0.enc_self_attn.linear.weight', 'layers.0.enc_self_attn.linear.bias', 'layers.0.enc_self_attn.layernorm.weight', 'layers.0.enc_self_attn.layernorm.bias', 'layers.0.enc_self_attn.W_Q.weight', 'layers.0.enc_self_attn.W_Q.bias', 'layers.0.enc_self_attn.W_K.weight', 'layers.0.enc_self_attn.W_K.bias', 'layers.0.enc_self_attn.W_V.weight', 'layers.0.enc_self_attn.W_V.bias', 'layers.0.pos_ffn.fc.0.weight', 'layers.0.pos_ffn.fc.2.weight', 'layers.0.pos_ffn.layernorm.weight', 'layers.0.pos_ffn.layernorm.bias', 'layers.1.enc_self_attn.linear.weight', 'layers.1.enc_self_attn.linear.bias', 'layers.1.enc_self_attn.layernorm.weight', 'layers.1.enc_self_attn.layernorm.bias', 'layers.1.enc_self_attn.W_Q.weight', 'layers.1.enc_self_attn.W_Q.bias', 'layers.1.enc_self_attn.W_K.weight', 'layers.1.enc_self_attn.W_K.bias', 'layers.1.enc_self_attn.W_V.weight', 'layers.1.enc_self_attn.W_V.bias', 'layers.1.pos_ffn.fc.0.weight', 'layers.1.pos_ffn.fc.2.weight', 'layers.1.pos_ffn.layernorm.weight', 'layers.1.pos_ffn.layernorm.bias']
elif self.pretrain_layer == 3:
...
elif self.pretrain_layer == 'all_12layer':
pretrained_parameters = ['embedding.tok_embed.weight', 'embedding.pos_embed.weight',
'embedding.norm.weight', 'embedding.norm.bias',
'layers.0.enc_self_attn.linear.weight', 'layers.0.enc_self_attn.linear.bias',
'layers.0.enc_self_attn.layernorm.weight', 'layers.0.enc_self_attn.layernorm.bias',
'layers.0.enc_self_attn.W_Q.weight', 'layers.0.enc_self_attn.W_Q.bias',
'layers.0.enc_self_attn.W_K.weight', 'layers.0.enc_self_attn.W_K.bias',
'layers.0.enc_self_attn.W_V.weight', 'layers.0.enc_self_attn.W_V.bias',
'layers.0.pos_ffn.fc.0.weight', 'layers.0.pos_ffn.fc.2.weight',
'layers.0.pos_ffn.layernorm.weight', 'layers.0.pos_ffn.layernorm.bias',
'layers.1.enc_self_attn.linear.weight', 'layers.1.enc_self_attn.linear.bias',
'layers.1.enc_self_attn.layernorm.weight', 'layers.1.enc_self_attn.layernorm.bias',
'layers.1.enc_self_attn.W_Q.weight', 'layers.1.enc_self_attn.W_Q.bias',
'layers.1.enc_self_attn.W_K.weight', 'layers.1.enc_self_attn.W_K.bias',
'layers.1.enc_self_attn.W_V.weight', 'layers.1.enc_self_attn.W_V.bias',
'layers.1.pos_ffn.fc.0.weight', 'layers.1.pos_ffn.fc.2.weight',
'layers.1.pos_ffn.layernorm.weight', 'layers.1.pos_ffn.layernorm.bias',
'layers.2.enc_self_attn.linear.weight', 'layers.2.enc_self_attn.linear.bias',
'layers.2.enc_self_attn.layernorm.weight', 'layers.2.enc_self_attn.layernorm.bias',
'layers.2.enc_self_attn.W_Q.weight', 'layers.2.enc_self_attn.W_Q.bias',
'layers.2.enc_self_attn.W_K.weight', 'layers.2.enc_self_attn.W_K.bias',
'layers.2.enc_self_attn.W_V.weight', 'layers.2.enc_self_attn.W_V.bias',
'layers.2.pos_ffn.fc.0.weight', 'layers.2.pos_ffn.fc.2.weight',
'layers.2.pos_ffn.layernorm.weight', 'layers.2.pos_ffn.layernorm.bias',
'layers.3.enc_self_attn.linear.weight', 'layers.3.enc_self_attn.linear.bias',
'layers.3.enc_self_attn.layernorm.weight', 'layers.3.enc_self_attn.layernorm.bias',
'layers.3.enc_self_attn.W_Q.weight', 'layers.3.enc_self_attn.W_Q.bias',
'layers.3.enc_self_attn.W_K.weight', 'layers.3.enc_self_attn.W_K.bias',
'layers.3.enc_self_attn.W_V.weight', 'layers.3.enc_self_attn.W_V.bias',
'layers.3.pos_ffn.fc.0.weight', 'layers.3.pos_ffn.fc.2.weight',
'layers.3.pos_ffn.layernorm.weight', 'layers.3.pos_ffn.layernorm.bias',
'layers.4.enc_self_attn.linear.weight', 'layers.4.enc_self_attn.linear.bias',
'layers.4.enc_self_attn.layernorm.weight', 'layers.4.enc_self_attn.layernorm.bias',
'layers.4.enc_self_attn.W_Q.weight', 'layers.4.enc_self_attn.W_Q.bias',
'layers.4.enc_self_attn.W_K.weight', 'layers.4.enc_self_attn.W_K.bias',
'layers.4.enc_self_attn.W_V.weight', 'layers.4.enc_self_attn.W_V.bias',
'layers.4.pos_ffn.fc.0.weight', 'layers.4.pos_ffn.fc.2.weight',
'layers.4.pos_ffn.layernorm.weight', 'layers.4.pos_ffn.layernorm.bias',
'layers.5.enc_self_attn.linear.weight', 'layers.5.enc_self_attn.linear.bias',
'layers.5.enc_self_attn.layernorm.weight', 'layers.5.enc_self_attn.layernorm.bias',
'layers.5.enc_self_attn.W_Q.weight', 'layers.5.enc_self_attn.W_Q.bias',
'layers.5.enc_self_attn.W_K.weight', 'layers.5.enc_self_attn.W_K.bias',
'layers.5.enc_self_attn.W_V.weight', 'layers.5.enc_self_attn.W_V.bias',
'layers.5.pos_ffn.fc.0.weight', 'layers.5.pos_ffn.fc.2.weight',
'layers.5.pos_ffn.layernorm.weight', 'layers.5.pos_ffn.layernorm.bias',
'layers.6.enc_self_attn.linear.weight', 'layers.6.enc_self_attn.linear.bias',
'layers.6.enc_self_attn.layernorm.weight', 'layers.6.enc_self_attn.layernorm.bias',
'layers.6.enc_self_attn.W_Q.weight', 'layers.6.enc_self_attn.W_Q.bias',
'layers.6.enc_self_attn.W_K.weight', 'layers.6.enc_self_attn.W_K.bias',
'layers.6.enc_self_attn.W_V.weight', 'layers.6.enc_self_attn.W_V.bias',
'layers.6.pos_ffn.fc.0.weight', 'layers.6.pos_ffn.fc.2.weight',
'layers.6.pos_ffn.layernorm.weight', 'layers.6.pos_ffn.layernorm.bias',
'layers.7.enc_self_attn.linear.weight', 'layers.7.enc_self_attn.linear.bias',
'layers.7.enc_self_attn.layernorm.weight', 'layers.7.enc_self_attn.layernorm.bias',
'layers.7.enc_self_attn.W_Q.weight', 'layers.7.enc_self_attn.W_Q.bias',
'layers.7.enc_self_attn.W_K.weight', 'layers.7.enc_self_attn.W_K.bias',
'layers.7.enc_self_attn.W_V.weight', 'layers.7.enc_self_attn.W_V.bias',
'layers.7.pos_ffn.fc.0.weight', 'layers.7.pos_ffn.fc.2.weight',
'layers.7.pos_ffn.layernorm.weight', 'layers.7.pos_ffn.layernorm.bias',
'layers.8.enc_self_attn.linear.weight', 'layers.8.enc_self_attn.linear.bias',
'layers.8.enc_self_attn.layernorm.weight', 'layers.8.enc_self_attn.layernorm.bias',
'layers.8.enc_self_attn.W_Q.weight', 'layers.8.enc_self_attn.W_Q.bias',
'layers.8.enc_self_attn.W_K.weight', 'layers.8.enc_self_attn.W_K.bias',
'layers.8.enc_self_attn.W_V.weight', 'layers.8.enc_self_attn.W_V.bias',
'layers.8.pos_ffn.fc.0.weight', 'layers.8.pos_ffn.fc.2.weight',
'layers.8.pos_ffn.layernorm.weight', 'layers.8.pos_ffn.layernorm.bias',
'layers.9.enc_self_attn.linear.weight', 'layers.9.enc_self_attn.linear.bias',
'layers.9.enc_self_attn.layernorm.weight', 'layers.9.enc_self_attn.layernorm.bias',
'layers.9.enc_self_attn.W_Q.weight', 'layers.9.enc_self_attn.W_Q.bias',
'layers.9.enc_self_attn.W_K.weight', 'layers.9.enc_self_attn.W_K.bias',
'layers.9.enc_self_attn.W_V.weight', 'layers.9.enc_self_attn.W_V.bias',
'layers.9.pos_ffn.fc.0.weight', 'layers.9.pos_ffn.fc.2.weight',
'layers.9.pos_ffn.layernorm.weight', 'layers.9.pos_ffn.layernorm.bias',
'layers.10.enc_self_attn.linear.weight', 'layers.10.enc_self_attn.linear.bias',
'layers.10.enc_self_attn.layernorm.weight',
'layers.10.enc_self_attn.layernorm.bias', 'layers.10.enc_self_attn.W_Q.weight',
'layers.10.enc_self_attn.W_Q.bias', 'layers.10.enc_self_attn.W_K.weight',
'layers.10.enc_self_attn.W_K.bias', 'layers.10.enc_self_attn.W_V.weight',
'layers.10.enc_self_attn.W_V.bias', 'layers.10.pos_ffn.fc.0.weight',
'layers.10.pos_ffn.fc.2.weight', 'layers.10.pos_ffn.layernorm.weight',
'layers.10.pos_ffn.layernorm.bias'
'fc.1.weight', 'fc.1.bias', 'fc.3.weight', 'fc.3.bias', 'classifier_global.weight',
'classifier_global.bias', 'classifier_atom.weight', 'classifier_atom.bias']
pretrained_model = torch.load(self.pretrained_model, map_location=torch.device('cpu'))
# pretrained_model = torch.load(self.pretrained_model)
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_model['model_state_dict'].items() if k in pretrained_parameters}
model_dict.update(pretrained_dict)
model.load_state_dict(pretrained_dict, strict=False)
3.run
for epoch in range(args['num_epochs']):
train_score = run_a_train_global_epoch(args, epoch, model, train_loader, loss_criterion, optimizer)
# Validation and early stop
_ = run_an_eval_global_epoch(args, model, train_loader)[0]
val_score = run_an_eval_global_epoch(args, model, val_loader)[0]
test_score = run_an_eval_global_epoch(args, model, test_loader)[0]
if epoch < 5:
early_stop = stopper.step(0, model)
else:
early_stop = stopper.step(val_score, model)
print('epoch {:d}/{:d}, {}, lr: {:.6f}, train: {:.4f}, valid: {:.4f}, best valid {:.4f}, '
'test: {:.4f}'.format(
epoch + 1, args['num_epochs'], args['metric_name'], optimizer.param_groups[0]['lr'], train_score, val_score,
stopper.best_score, test_score))
if early_stop:
break
stopper.load_checkpoint(model)
3.1.run_an_eval_global_epoch
def run_an_eval_global_epoch(args, model, data_loader):
model.eval()
eval_meter = Meter()
with torch.no_grad():
for batch_id, batch_data in enumerate(data_loader):
smiles, token_idx, global_labels, mask = batch_data
token_idx = token_idx.long().to(args['device'])
mask = mask.float().to(args['device'])
global_labels = global_labels.float().to(args['device'])
logits_global = model(token_idx)
eval_meter.update(logits_global, global_labels, mask=mask)
del token_idx, global_labels
torch.cuda.empty_cache()
y_pred, y_true = eval_meter.compute_metric('return_pred_true')
y_true_list = y_true.squeeze(dim=1).tolist()
y_pred_list = torch.sigmoid(y_pred).squeeze(dim=1).tolist()
# save prediction
y_pred_label = [1 if x >= 0.5 else 0 for x in y_pred_list]
auc = metrics.roc_auc_score(y_true_list, y_pred_list)
accuracy = metrics.accuracy_score(y_true_list, y_pred_label)
se, sp = sesp_score(y_true_list, y_pred_label)
pre, rec, f1, sup = metrics.precision_recall_fscore_support(y_true_list, y_pred_label)
mcc = metrics.matthews_corrcoef(y_true_list, y_pred_label)
f1 = f1[1]
rec = rec[1]
pre = pre[1]
err = 1 - accuracy
result = [auc, accuracy, se, sp, f1, pre, rec, err, mcc]
return result
3.2.step
def step(self, score, model):
if self.best_score is None:
self.best_score = score
self.save_checkpoint(model)
elif self._check(score, self.best_score):
self.best_score = score
self.save_checkpoint(model)
self.counter = 0
else:
self.counter += 1
print(
'EarlyStopping counter: {} out of {}'.format(self.counter, self.patience))
if self.counter >= self.patience:
self.early_stop = True
return self.early_stop