11 Table API和SQL
11.1 快速上手
- 引入TableAPI的依赖
- 桥接器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
主要通过bridge桥接器进行将Table转换成DataStream
- 计划器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
计划器以及scala流式处理
- 上代码
public class SimpleTableExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.读取数据,得到DataStream
SingleOutputStreamOperator<Event> eventStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//2. 创建表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//3.将DataStream转换成Table
//POJO类属性当作表的列
Table eventTable = tableEnv.fromDataStream(eventStream);
//4.直接写SQL进行转换
//调用sqlQuery返回的依然是一个表,即表和表之间的
//from后面一定要带空格,``是用在关键字
Table resultTable1 = tableEnv.sqlQuery("select user,url,`timestamp` from " + eventTable);
//5.或者基于Table直接转换
Table resultTable2 = eventTable.select($("user"), $("url"))
.where($("user").isEqual("Alice"));
//6.通过转回流然后打印输出
tableEnv.toDataStream(resultTable1).print("result1");
tableEnv.toDataStream(resultTable2).print("result2");
env.execute();
}
}
结果
result1> +I[Bob, ./prod?id=100, 1670142197928]
result1> +I[Bob, ./home, 1670142198946]
result1> +I[Alice, ./home, 1670142199959]
result2> +I[Alice, ./home]
result1> +I[Mary, ./fav, 1670142200963]
result1> +I[Bob, ./prod?id=100, 1670142201970]
result1> +I[Bob, ./home, 1670142202972]
result1> +I[Mary, ./home, 1670142203983]
result1> +I[Bob, ./fav, 1670142204988]
result1> +I[Alice, ./home, 1670142205994]
result2> +I[Alice, ./home]
result1> +I[Bob, ./cart, 1670142207000]
result1> +I[Mary, ./cart, 1670142208012]
result1> +I[Bob, ./fav, 1670142209015]
result1> +I[Bob, ./prod?id=100, 1670142210020]
result1> +I[Bob, ./home, 1670142211033]
result1> +I[Alice, ./home, 1670142212036]
result2> +I[Alice, ./home]
11.2 基本API
11.2.1 程序架构
- 概述
分为数据源(Source),转换(Transform),输出(Sink)
- 流程

创建表环境
使用executeSql()方法设置输入表和输出表,特殊的是with 'connector’连接器连接外部系统
sqlQuery()传入sql语句对输入表进行处理,也可以使用TableAPI调用from()或者select()方法
得到的处理表调用.executeInsert(),传入输出表输出
11.2.2 创建表环境
- 第一种
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
- 第二种


调用EnvironmentSettings类中的newInstance()方法返回Builder,在Builder类中有build(),返回EnvironmentSettings,同时可以调用


将setting传入TableEnvironment类的create()方法中,得到TableEnvironment
代码如下
特点是不依赖StreamExecutionEnvironment流式执行环境
//1. 定义环境配置来创建表执行环境
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()//流执行环境
.useBlinkPlanner()//计划器
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
- 其他(了解)
- 基于老版本planner进行流处理
//1.1基于老版本planner进行
EnvironmentSettings settings1 = EnvironmentSettings.newInstance()
.inStreamingMode()//流执行环境
.useOldPlanner()//老版本计划器
.build();
TableEnvironment tableEnv1 = TableEnvironment.create(settings1);
- 基于老版本planner进行批处理
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment batchTableEnvironment = BatchTableEnvironment.create(batchEnv);
- 基于Blink版本planner进行批处理
EnvironmentSettings settings3 = EnvironmentSettings.newInstance()
.inBatchMode()//批执行环境
.useBlinkPlanner()
.build();
TableEnvironment tableEnv3 = TableEnvironment.create(settings3);
11.2.3 创建表
- 概述
表环境会维护一个目录和表的对应关系,拥有唯一的ID,由以下三部分组成:目录,数据库,表名,例如:default_catalog.default_database.MyTable
- 创建方式
- 连接器表

- 虚拟表


通过createTemporaryView()创建临时的虚拟表,第一个参数表名称,第二个参数表实例
- 两者区别是,连接器表是实体的,而虚拟表是虚拟的,只是用到这张表的时候,会将对应的语句嵌入到SQL中
11.2.4 表的查询/输出
- 概述
提供了两种查询方式,SQL以及TableAPI
- 执行SQL进行查询
写SQL并且调用.sqlQuery()

除了简单的select,也可以使用count,sun,avg等进行计算
- TableAPI

注册的表传入.from之中

- 代码
- 总体代码
public class CommonApiTest {
public static void main(String[] args) {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);
//
// StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 定义环境配置来创建表执行环境
//基于blink版本planner进行流处理
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()//流执行环境
.useBlinkPlanner()//计划器
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// //1.1 基于老版本planner进行流处理
// EnvironmentSettings settings1 = EnvironmentSettings.newInstance()
// .inStreamingMode()//流执行环境
// .useOldPlanner()//老版本计划器
// .build();
//
// TableEnvironment tableEnv1 = TableEnvironment.create(settings1);
//
// //1.2 基于老版本planner进行批处理
// ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
// BatchTableEnvironment batchTableEnvironment = BatchTableEnvironment.create(batchEnv);
//
//
// //1.3 基于Blink版本planner进行批处理
// EnvironmentSettings settings3 = EnvironmentSettings.newInstance()
// .inBatchMode()//批执行环境
// .useBlinkPlanner()
// .build();
//
// TableEnvironment tableEnv3 = TableEnvironment.create(settings3);
//2.表的创建
String createDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT" +
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
")";
tableEnv.executeSql(createDDL);
//调用Table的API进行表的查询转换
Table clickTable = tableEnv.from("clickTable");
Table resultTable = clickTable.where($("user_name").isEqual("Bob"))
.select($("user_name"), $("url"));
//注册成虚拟表
tableEnv.createTemporaryView("result2",resultTable);
//执行SQL进行表的查询转换
Table resultTable2 = tableEnv.sqlQuery("select url,user_name from result2");
//创建一张用户输出的表
String createOutDDL = "CREATE TABLE outTable (" +
" user_name STRING, " +
" url STRING " +
" ) WITH (" +
" 'connector'='filesystem'," +
" 'path' = 'output'," +
" 'format' = 'csv'"+
" )";
tableEnv.executeSql(createOutDDL);
//输出表
resultTable2.executeInsert("outTable");
}
}
结果

结果分区很多,因为没有设置并行度,默认就是电脑核数
- 创建一张用于控制台打印输出的表
//创建一张用于控制台打印输出的表
String createPrintOutDDL = "CREATE TABLE printoutTable (" +
" user_name STRING, " +
" url STRING " +
" ) WITH (" +
" 'connector'='print' " +
" )";
tableEnv.executeSql(createPrintOutDDL);
//输出表
resultTable2.executeInsert("printoutTable");
结果
3> +I[Bob, ./home]
6> +I[Bob, ./prod?id=100]
8> +I[Bob, ./prod?id=10]
4> +I[Bob, ./cart]
2> +I[Bob, ./prod?id=10]
6> +I[Bob, ./cart]
4> +I[Bob, ./home]
- 聚合运算
public class CommonApiTest2 {
public static void main(String[] args) {
//1. 定义环境配置来创建表执行环境
//基于blink版本planner进行流处理
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()//流执行环境
.useBlinkPlanner()//计划器
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//2.表的创建
String createDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT" +
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
")";
tableEnv.executeSql(createDDL);
//执行聚合计算的查询转换
Table aggResult = tableEnv.sqlQuery("select user_name,COUNT(url) as cnt " +
"from clickTable " +
"group by user_name");
//创建一张用于控制台打印输出的表
String createPrintOutDDL = "CREATE TABLE printoutTable (" +
" user_name STRING, " +
" cnt BIGINT "+
" ) WITH (" +
" 'connector'='print' " +
" )";
tableEnv.executeSql(createPrintOutDDL);
//输出表
aggResult.executeInsert("printoutTable");
}
}
结果
8> +I[Bob, 1] rowkind为+I表示新增
4> +I[Mary, 1]
9> +I[Alice, 1]
8> -U[Bob, 1] rowkind为-U表示更新前的数据
4> -U[Mary, 1]
8> +U[Bob, 2] rowkind为-U表示更新后的数据
4> +U[Mary, 2]
8> -U[Bob, 2]
8> +U[Bob, 3]
4> -U[Mary, 2]
4> +U[Mary, 3]
8> -U[Bob, 3]
4> -U[Mary, 3]
4> +U[Mary, 4]
8> +U[Bob, 4]
11.2.5 表和流的转换
- 表转换成流
- 简单的仅仅rowkind为+I的流叫做插入流,直接调用.toToDataStream()转换成流的操作
此时用toChangelogStream()也是没问题的
public class SimpleTableExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.读取数据,得到DataStream
SingleOutputStreamOperator<Event> eventStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//2. 创建表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//3.将DataStream转换成Table
//POJO类属性当作表的列
Table eventTable = tableEnv.fromDataStream(eventStream);
//4.直接写SQL进行转换
//调用sqlQuery返回的依然是一个表,即表和表之间的
//from后面一定要带空格,``是用在关键字
Table resultTable1 = tableEnv.sqlQuery("select user,url,`timestamp` from " + eventTable);
//5.通过转回流然后打印输出
tableEnv.toDataStream(resultTable1).print("result1");
env.execute();
}
}
结果
result1> +I[Mary, ./cart, 1670218890037]
result1> +I[Mary, ./fav, 1670218891038]
result1> +I[Mary, ./fav, 1670218892039]
result1> +I[Alice, ./fav, 1670218893040]
result1> +I[Mary, ./fav, 1670218894053]
result1> +I[Bob, ./prod?id=100, 1670218895053]
result1> +I[Bob, ./cart, 1670218896054]
result1> +I[Mary, ./cart, 1670218897054]
- 基于StreamTableEnvironment环境的.toChangelogStream()
public class SimpleTableExample2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.读取数据,得到DataStream
SingleOutputStreamOperator<Event> eventStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//2. 创建表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//3.将DataStream转换成Table
//POJO类属性当作表的列
Table eventTable = tableEnv.fromDataStream(eventStream);
//4.聚合转换
//注册表
tableEnv.createTemporaryView("clickTable",eventTable);
Table aggResult = tableEnv.sqlQuery("select user,COUNT(url) as cnt " +
"from clickTable " +
"group by user");
//5.打印输出
tableEnv.toChangelogStream(aggResult).print("agg");
env.execute();
}
}
结果
agg> +I[Bob, 1]
agg> -U[Bob, 1]
agg> +U[Bob, 2]
agg> +I[Alice, 1]
agg> -U[Alice, 1]
agg> +U[Alice, 2]
agg> -U[Bob, 2]
agg> +U[Bob, 3]
- 流转换成表
(1)流转成Table对象
- 流属性转成表列
Table eventTable = tableEnv.fromDataStream(eventStream);
- 指定流的字段作为表的列

- 甚至可以重命名

(2)注册表和流转表一起,即调用createTemporaryView(),第一个参数是名字,第二个参数是流,后面参数可以指定传的字段

(3) 调用fromChangelogStream()方法
即将更新日志流转换成表
- 支持的数据类型
流转表需要考虑的较多
(1)原子类型
基础数据类型以及通用数据类型,转换的就是一列,值排排好,类型就是原来的类型
也可以重命名字段名称,详见上面2说的
本质当作了一元组Tuple1处理
(2) Tuple类型
二元组就是两个值分别转成表的第一列以及第二列
转的时候可以取字段,交换字段,重命名字段

(3) POJO类型也就是复合类型
(4)Row类型
需指定具体类型,以及附加了一个RowKind用来表示更新日志流的数据
· 来个例子了解下
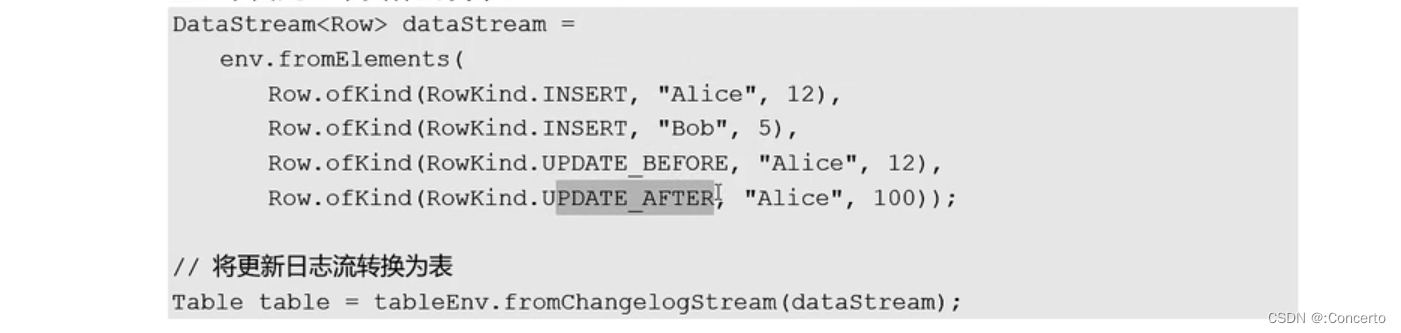
11.3 流处理中的表
11.3.1 动态表和持续查询
- 动态表
因为flink是流式处理,而表是有界的,因此得到的表需要不断的动态变化更新,因此被称为“动态表”。
动态表概念类比关系型数据库“物化视图”,可以用来缓存SQL查询的结果
- 持续查询
多个持续查询的连续动作,触发条件就是源源不断来的数据

11.3.2 用SQL持续查询
- 更新查询
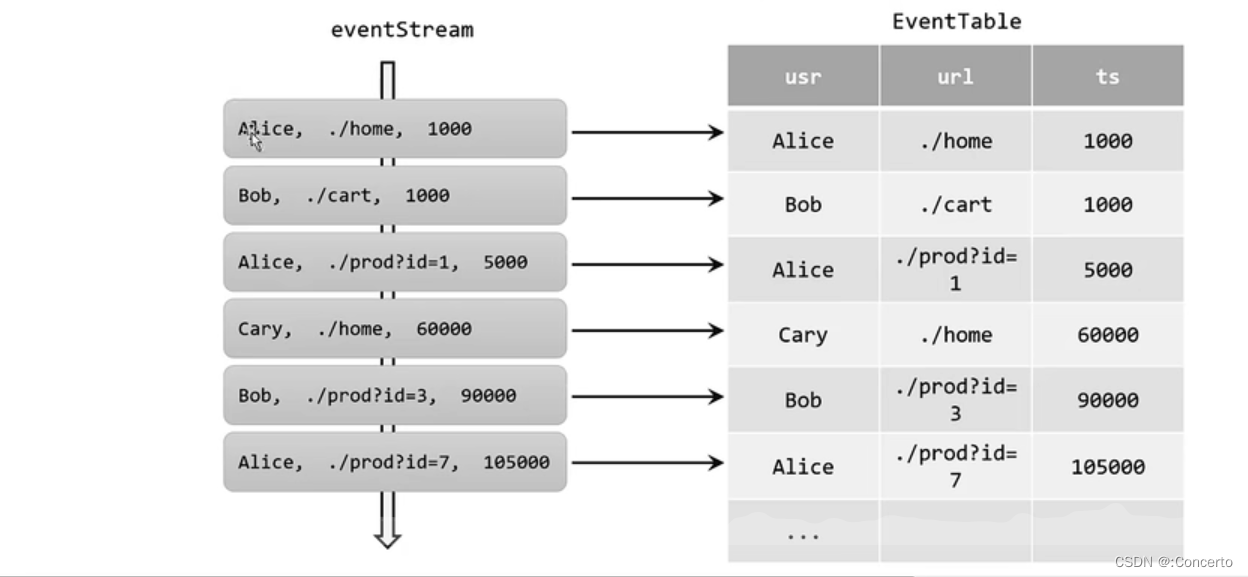
- 数据流到动态表的转换过程
用户点击的每一条数据都是动态表
- 表转成数据流
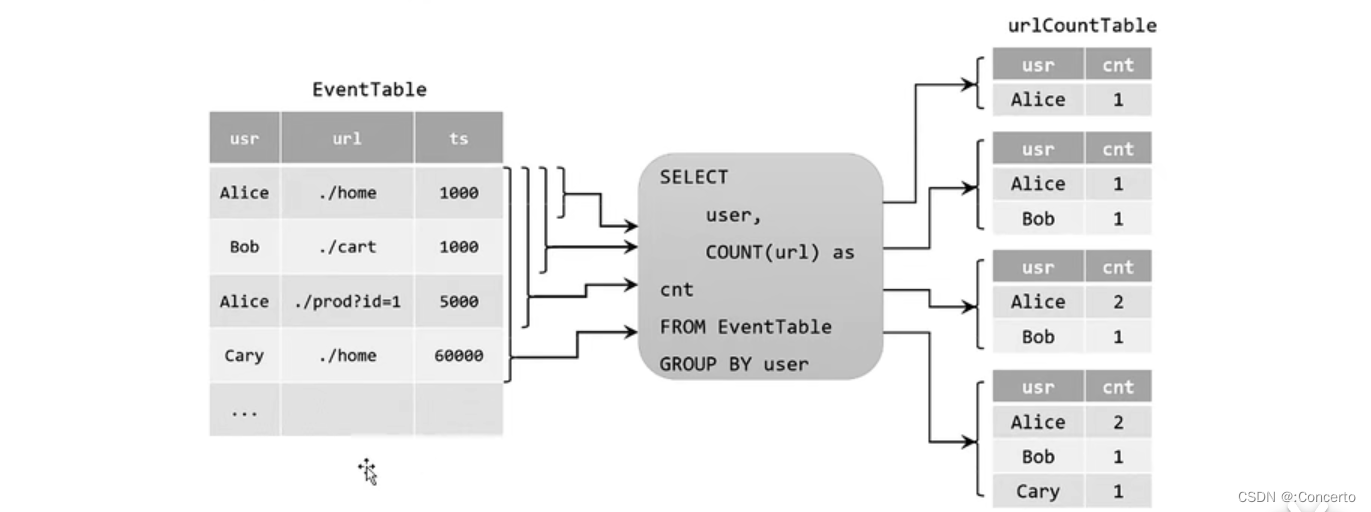
- 追加查询
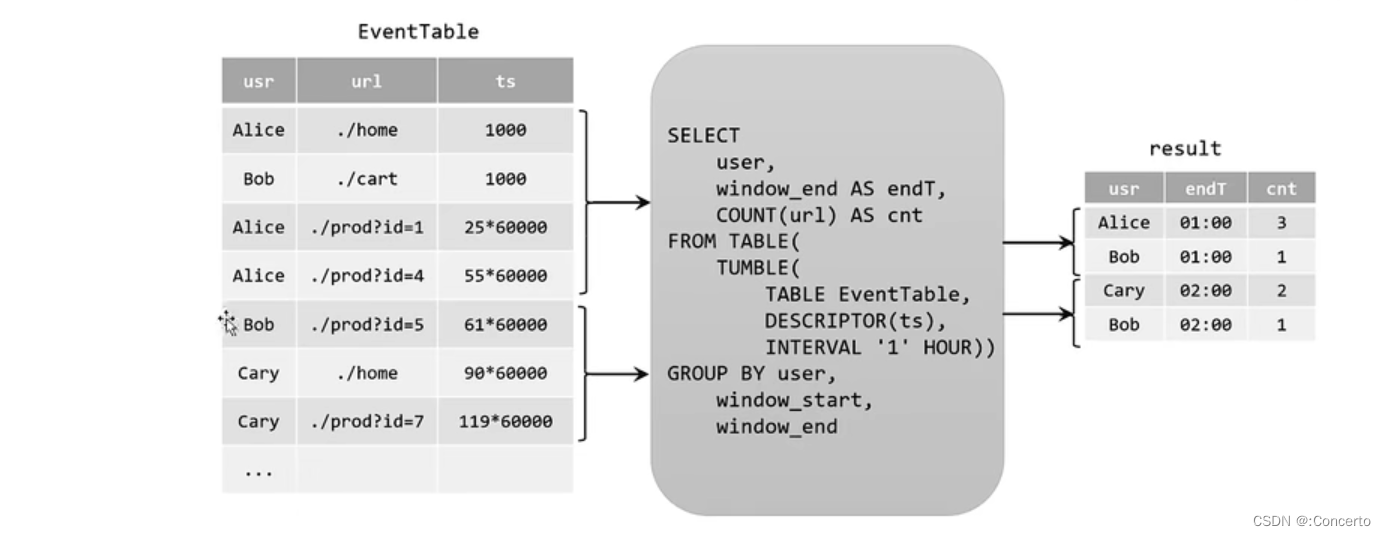
没update
- 查询限制
11.3.3 动态表编码成数据流
- 概念
- 追加流
仅追加流对应动态表的追加查询
- 撤回流
撤回流对应动态表的更新查询,具体编码如下:insert->add,delete->retract,update->retract+add
- 更新插入流
更新插入流:upsert更新插入 delete删除 但是upsert如何区分insert还是update呢?
通过唯一的key去判定,如果有key那就insert,没有的话就更新
11.4 事件属性和窗口
11.4.1 事件时间
- 在创建表的DDL中定义
- ts普通转换

注意下水位线咋写的
ts直接写上TIMESTAMP(3)类型就可以了,3表示毫秒精度
- 转成TIMESTAMP_LTZ
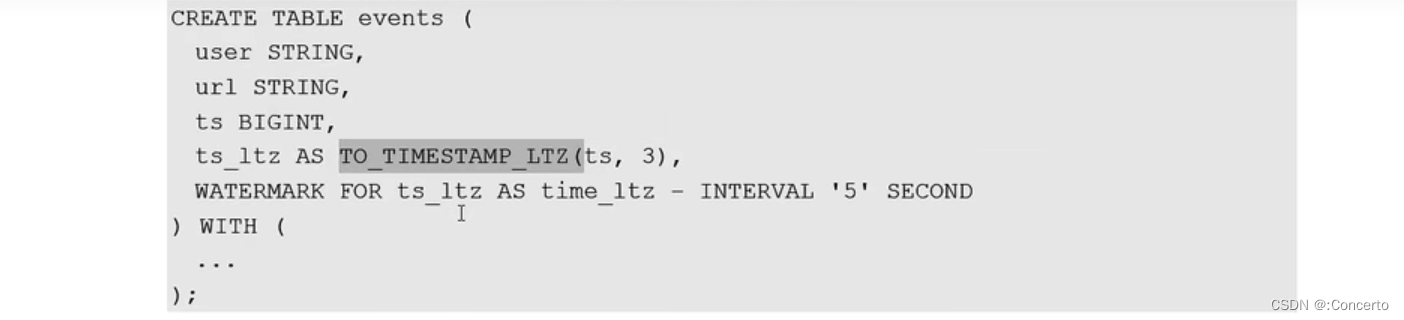
TIMESTAMP_LTZ是指的时间戳是“年-月-日-时-分-秒”的形式
- 代码案例
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))" +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
")";
}
}
- 在数据流转换成表的时候定义
在字段最后调用.rowtime()指定成时间属性,ts需要在流中定义好,即使二元组没有,相当于新建一个字段


- 代码案例
public class TimeAndWindowTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.在流转换成Table的时候定义时间属性
SingleOutputStreamOperator<Event> clickStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
Table clickTable = tableEnv.fromDataStream(clickStream, $("user"), $("url"), $("timestamp").as("ts"),
$("et").rowtime());
clickTable.printSchema();
}
}
结果
(
`user` STRING,
`url` STRING,
`ts` BIGINT,
`et` TIMESTAMP(3) *ROWTIME*
)
11.4.2 处理时间
- 在创建表的DDL中定义

ts是通过as proctime()新建的字段
- 在数据流转换成表中定义


新增字段调用.proctime()方法
11.4.3 窗口
- 分组窗口(旧版本)
- 分类
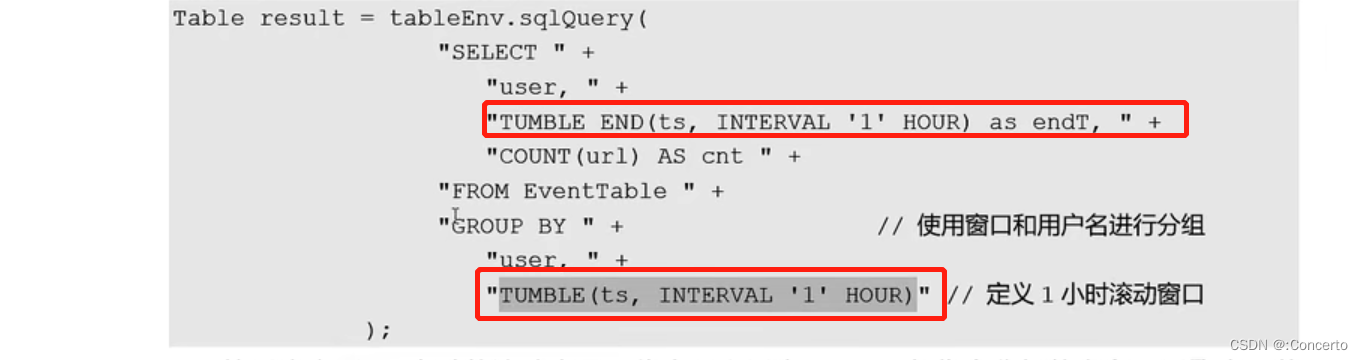
TUMBLE(),HOP(),SESSION()滚动/滑动/会话窗口
- 案例
TUMBLE(ts,INTERBAL '1' HOUR)
TUMBLE_END表示窗口结束的时间
- 窗口表值函数(新版本)

(1)滚动窗口
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
第一个参数是数据表,第二个是时间戳,第三个间隔时间
(2)滑动窗口
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
第三个滑动步长,第四个参数是窗口大小
(3) 累积窗口
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
11.5 聚合查询
11.5.1 分组聚合
- 运用
Table eventCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user
");
- 配置状态的生存时间(TTL)
- 运用
TableEnvironment tableEnv = ...
// 获取表环境的配置
TableConfig tableConfig = tableEnv.getConfig();
// 配置状态保持时间
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));
或者
TableEnvironment tableEnv = ...
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.state.ttl", "60 min");
- 代码
- csv数据
Mary,./home,1000
Alice,./cart,2000
Bob,./prod?id=100,3000
Bob,./cart,4000
Bob,./home,5000
Mary,./home,6000
Bob,./cart,7000
Bob,./home,8000
Bob,./prod?id=10,9000
Bob,./prod?id=10,11000
Bob,./prod?id=10,13000
Bob,./prod?id=10,15000
- 代码
public class TimeAndWindowTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.在流转换成Table的时候定义时间属性
SingleOutputStreamOperator<Event> clickStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
Table clickTable = tableEnv.fromDataStream(clickStream, $("user"), $("url"), $("timestamp").as("ts"),
$("et").rowtime());
//3.聚合查询转换
//3.1 分组聚合
Table aggTable = tableEnv.sqlQuery("select user_name,count(url) from clickTable group by user_name");
//3.2 分组窗口聚合
Table groupWindowResultTable = tableEnv.sqlQuery("select " +
" user_name,count(1) as cnt," +
" TUMBLE_END(et,INTERVAL '10' SECOND) as entT " +
" from clickTable group by user_name," +
" TUMBLE(et,INTERVAL '10' SECOND)");
//clickTable.printSchema();
- agg结果
agg> +I[Mary, 1]
agg> +I[Alice, 1]
agg> +I[Bob, 1]
agg> -U[Bob, 1]
agg> +U[Bob, 2]
agg> -U[Bob, 2]
agg> +U[Bob, 3]
agg> -U[Mary, 1]
agg> +U[Mary, 2]
agg> -U[Bob, 3]
agg> +U[Bob, 4]
agg> -U[Bob, 4]
agg> +U[Bob, 5]
agg> -U[Bob, 5]
agg> +U[Bob, 6]
agg> -U[Bob, 6]
agg> +U[Bob, 7]
agg> -U[Bob, 7]
agg> +U[Bob, 8]
agg> -U[Bob, 8]
agg> +U[Bob, 9]
- group window结果
group window:> +I[Mary, 2, 1970-01-01T08:00:10]
group window:> +I[Alice, 1, 1970-01-01T08:00:10]
group window:> +I[Bob, 6, 1970-01-01T08:00:10]
group window:> +I[Bob, 3, 1970-01-01T08:00:20]
表示Mary在第一个十秒之内有2次点击,Bob6次,Alice1次
在第二个窗口十秒中,Bob有3次
11.5.2 窗口聚合
- 代码
public class TimeAndWindowTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.在流转换成Table的时候定义时间属性
SingleOutputStreamOperator<Event> clickStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
Table clickTable = tableEnv.fromDataStream(clickStream, $("user"), $("url"), $("timestamp").as("ts"),
$("et").rowtime());
//4. 窗口聚合
//4.1 滚动窗口
Table tumbleWindowResultTable = tableEnv.sqlQuery("select user_name,count(1) as cnt," +
"window_end as endT " +
"from TABLE(" +
"TUMBLE(TABLE clickTable,DESCRIPTOR(et),INTERVAL '10' SECOND)) " +
"GROUP BY user_name,window_end,window_start");
//4.2 滑动窗口
Table hopWindowResultTable = tableEnv.sqlQuery("select user_name,count(1) as cnt," +
"window_end as endT " +
"from TABLE(" +
"HOP(TABLE clickTable,DESCRIPTOR(et),INTERVAL '5' SECOND,INTERVAL '10' SECOND)) " +
"GROUP BY user_name,window_end,window_start");
//4.2 累积窗口
Table cumulateResultTable = tableEnv.sqlQuery("select user_name,count(1) as cnt," +
"window_end as endT " +
"from TABLE(" +
"CUMULATE(TABLE clickTable,DESCRIPTOR(et),INTERVAL '5' SECOND,INTERVAL '10' SECOND)) " +
"GROUP BY user_name,window_end,window_start");
tableEnv.toChangelogStream(tumbleWindowResultTable).print("tumble window:");
tableEnv.toChangelogStream(hopWindowResultTable).print("hop window:");
tableEnv.toChangelogStream(cumulateResultTable).print("cumulate window:");
env.execute();
}
}
- tumble window结果
tumble window:> +I[Mary, 2, 1970-01-01T08:00:10]
tumble window:> +I[Alice, 1, 1970-01-01T08:00:10]
tumble window:> +I[Bob, 6, 1970-01-01T08:00:10]
tumble window:> +I[Bob, 3, 1970-01-01T08:00:20]
- hop window 结果
-5~5
hop window:> +I[Mary, 1, 1970-01-01T08:00:05]
hop window:> +I[Alice, 1, 1970-01-01T08:00:05]
hop window:> +I[Bob, 2, 1970-01-01T08:00:05]
0~10
hop window:> +I[Alice, 1, 1970-01-01T08:00:10]
hop window:> +I[Mary, 2, 1970-01-01T08:00:10]
hop window:> +I[Bob, 6, 1970-01-01T08:00:10]
5~15
hop window:> +I[Mary, 1, 1970-01-01T08:00:15]
hop window:> +I[Bob, 6, 1970-01-01T08:00:15]
10~20
hop window:> +I[Bob, 3, 1970-01-01T08:00:20]
15~25
hop window:> +I[Bob, 1, 1970-01-01T08:00:25]
- cumulate window
0~5
cumulate window:> +I[Mary, 1, 1970-01-01T08:00:05]
cumulate window:> +I[Alice, 1, 1970-01-01T08:00:05]
cumulate window:> +I[Bob, 2, 1970-01-01T08:00:05]
0~10
cumulate window:> +I[Alice, 1, 1970-01-01T08:00:10]
cumulate window:> +I[Mary, 2, 1970-01-01T08:00:10]
cumulate window:> +I[Bob, 6, 1970-01-01T08:00:10]
10~15
cumulate window:> +I[Bob, 2, 1970-01-01T08:00:15]
10~20
cumulate window:> +I[Bob, 3, 1970-01-01T08:00:20]
11.5.3 开窗(Over) 聚合
- 语法
SELECT
<聚合函数> OVER (
[PARTITION BY <字段 1>[, <字段 2>, ...]]
ORDER BY <时间属性字段>
<开窗范围>),
...
FROM ...
SELECT user, ts,
COUNT(url) OVER w AS cnt,
MAX(CHAR_LENGTH(url)) OVER w AS max_url
FROM EventTable
WINDOW w AS (
PARTITION BY user
ORDER BY ts
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
- 开窗范围
- 范围间隔
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
- 行范围
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
- 代码
- csv数据
Mary,./home,1000
Alice,./cart,2000
Bob,./prod?id=100,3000
Bob,./cart,4000
Bob,./home,5000
Mary,./home,6000
Bob,./cart,7000
Bob,./home,8000
Bob,./prod?id=10,9000
Bob,./prod?id=10,11000
Bob,./prod?id=10,13000
Bob,./prod?id=10,15000
- 代码
public class TimeAndWindowTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//2.在流转换成Table的时候定义时间属性
SingleOutputStreamOperator<Event> clickStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
Table clickTable = tableEnv.fromDataStream(clickStream, $("user"), $("url"), $("timestamp").as("ts"),
$("et").rowtime());
//开窗聚合over
Table overWindowResultTable = tableEnv.sqlQuery("select user_name,avg(ts) " +
"OVER(" +
"PARTITION BY user_name " +
"ORDER BY et " +
"ROWS BETWEEN 3 PRECEDING AND CURRENT ROW" +
") AS avg_ts " +
"FROM clickTable");
tableEnv.toChangelogStream(overWindowResultTable).print("over window:");
env.execute();
}
}
结果
over window:> +I[Mary, 1000]
over window:> +I[Alice, 2000]
over window:> +I[Bob, 3000]
over window:> +I[Bob, 3500] (3000+4000)/2
over window:> +I[Bob, 4000] (3000+4000+5000)/3
over window:> +I[Mary, 3500]
over window:> +I[Bob, 4750] (3000+4000+5000+7000)/4
over window:> +I[Bob, 6000] (4000+5000+7000+8000)/4
over window:> +I[Bob, 7250]
over window:> +I[Bob, 8750]
over window:> +I[Bob, 10250]
over window:> +I[Bob, 12000]
11.5.4 TopN案例
- 普通TopN
- 语法
SELECT ...
FROM (
SELECT ...,
343
ROW_NUMBER() OVER (
[PARTITION BY <字段 1>[, <字段 1>...]]
ORDER BY <排序字段 1> [asc|desc][, <排序字段 2> [asc|desc]...]
) AS row_num
FROM ...)
WHERE row_num <= N [AND <其它条件>]
- 案例
统计字符长度排序的前两个url
SELECT user, url, ts, row_num
FROM (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY user
ORDER BY CHAR_LENGTH(url) desc
) AS row_num
FROM EventTable)
WHERE row_num <= 2
- 运用
- 统计浏览次数最多的用户
public class TopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//普通TopN,选取当前用户中浏览量最大的两个
Table topNResultTable = tableEnv.sqlQuery
("SELECT user,cnt,row_num " +
"FROM (" +
" SELECT *,ROW_NUMBER() OVER (ORDER BY cnt DESC) AS row_num " +
"FROM (" +
"SELECT user,COUNT(url) AS cnt " +
"FROM clickTable GROUP BY user" +
")" +
") " +
"WHERE row_num <= 2");
tableEnv.toChangelogStream(topNResultTable).print("top2:");
env.execute();
}
}
结果
top2:> +I[Mary, 1, 1]
top2:> +I[Alice, 1, 2]
top2:> -U[Mary, 1, 1]
top2:> +U[Bob, 2, 1]
top2:> -U[Alice, 1, 2]
top2:> +U[Mary, 1, 2]
top2:> -U[Bob, 2, 1]
top2:> +U[Bob, 3, 1]
top2:> -U[Mary, 1, 2]
top2:> +U[Mary, 2, 2]
top2:> -U[Bob, 3, 1]
top2:> +U[Bob, 4, 1]
top2:> -U[Bob, 4, 1]
top2:> +U[Bob, 5, 1]
top2:> -U[Bob, 5, 1]
top2:> +U[Bob, 6, 1]
top2:> -U[Bob, 6, 1]
top2:> +U[Bob, 7, 1]
top2:> -U[Bob, 7, 1]
top2:> +U[Bob, 8, 1]
top2:> -U[Bob, 8, 1]
top2:> +U[Bob, 9, 1]
Process finished with exit code 0
- 统计一段时间内有最多访问行为的用户
public class TopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT," +
" et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000))," +//TO_TIMESTAMP要String,使用FROM_UNIXTIME转成string传入,ts/1000是秒
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +//水位线
" ) WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.csv',"+
" 'format' = 'csv'" +
") ";
tableEnv.executeSql(createDDL);
//窗口TopN,统计一段时间内的(前两名)活跃用户
String subQuery = "SELECT user,COUNT(url) AS cnt,window_start,window_end " +
"FROM TABLE(TUMBLE(TABLE clickTable,DESCRIPTOR(et),INTERVAL '10' SECOND))" +
" GROUP BY user,window_start,window_end";
Table windowTopNResultTable = tableEnv.sqlQuery("SELECT user,cnt,row_num,window_end " +
"FROM (" +
" SELECT *,ROW_NUMBER() OVER (" +
"PARTITION BY window_start,window_end " +
"ORDER BY cnt DESC) AS row_num " +
"FROM (" + subQuery +" ) )" +
"WHERE row_num <= 2");
tableEnv.toDataStream(windowTopNResultTable).print("window top n:");
env.execute();
}
}
结果
window top n:> +I[Bob, 6, 1, 1970-01-01T08:00:10]
window top n:> +I[Mary, 2, 2, 1970-01-01T08:00:10]
window top n:> +I[Bob, 3, 1, 1970-01-01T08:00:20]
11.6 联结查询
11.6.1 常规联结查询
- 等值内连接
- 等值外连接
这部分跟标准SQL一样呢,就不赘述啦
11.6.2 间隔联结查询
1.时间间隔限制
ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
案例
SELECT *
FROM Order o, Shipment s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
在流处理中,间隔联结查询只支持具有时间属性的“仅追加”(Append-only)表。