作者:@小萌新
专栏:@C++进阶
作者简介:大二学生 希望能和大家一起进步!
本篇博客简介:介绍并模拟实现哈希的应用 – 布隆过滤器
布隆过滤器
- 布隆过滤器的提出
- 布隆过滤器的概念
- 布隆过滤器的实现
- 框架与算法
- 插入函数
- 查找函数
- 删除函数
- 布隆过滤器的优点
- 布隆过滤器的缺点
- 布隆过滤器的使用场景
布隆过滤器的提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那 些已经存在的记录。 如何快速查找呢?
这里提出三种解决方案
- 使用哈希表来储存用户记录 但是哈希表来储存的会浪费许多空间
- 使用位图来储存用户记录 但是位图只能储存整型数据 如果是字符串类型的数据便无法处理了
- 将哈希和位图相结合 即布隆过滤器
布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
- 布隆过滤器其实是位图的变形和延申 我们无法解决哈希冲突 但是可以采取一些措施来降低误判率
- 当一个数据被映射到位图中时 布隆过滤器会使用多种哈希算法将其映射到多个位置 当我们判断一个数是否在位图中的时候需要再通过多种哈希算法判断多个位置是否都存在 否则该数据不存在
- 布隆过滤器判断存在是一种可能性事件 因为有可能多个位置全部发生哈希冲突
- 布隆过滤器判断不存在是一种必然时间 因为只要有一个位置不存在就说明该位置没有被映射过 即该数据不存在
下面我们给出一张图来展示布隆过滤器的一些特点
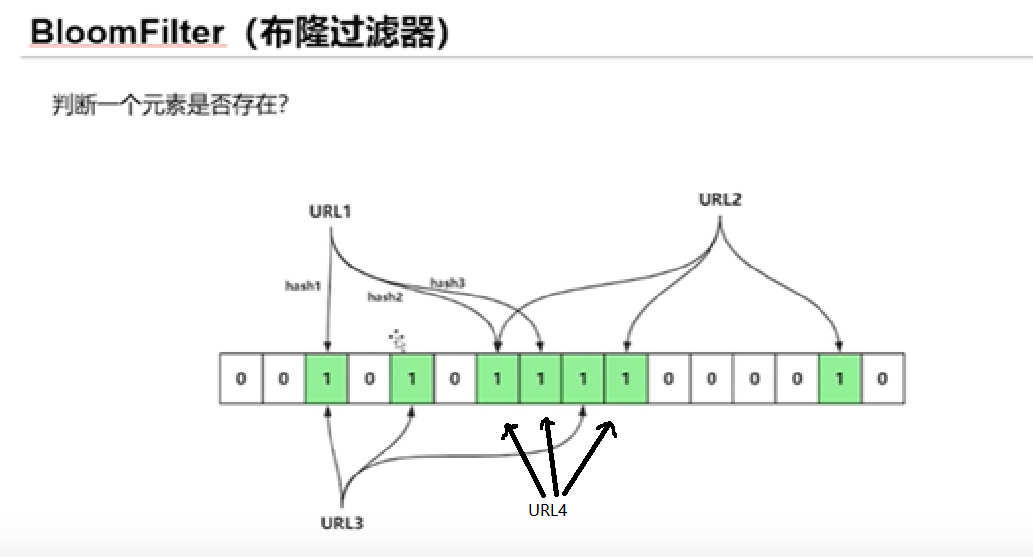
我们假设数据的插入顺序是 URL1 2 3 4
URL1 2 3 插入的时候都通过hash算法找到了没有被设置的位 所以说都顺利插入成功了
但是轮到了URL4插入的时候通过hash算法算出来的三个位置缺都被设置了 因此会造成插入失败 但是实际上该数据并不存在
这也就是我们说的误判的情况
那么这里就会抛出来一个问题了 一个误判率很高的容器是我们不想要的 那么我们应该如何降低误判率呢
这里涉及到两个方面
- 布隆过滤器的大小
如果布隆过滤器的大小过小 则很快就会被填满 从而导致误判率升高
- 哈希算法的个数
如果哈希算法的个数过多 则会导致布隆过滤器中被设置的位数过多 造成误判率的上升
而如果哈希算法的个数过少 也会导致误判率的上升
所以说哈希算法的个数一般控制在2~3个比较合适
布隆过滤器的实现
框架与算法
布隆过滤器可以被实现位一个模板类
因为插入布隆过滤器的元素大部分情况下是字符串 所以我们可以将缺省值设置为string类
如果是其他类型的参数我们只要提供对应的算法将其转化为整型即可
代码表示如下
template<size_t N , class K = string ,
class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
Hash1 h1;
Hash2 h2;
Hash3 h3;
public:
// ...
private:
bitset<N> _bs;
};
我们使用的三种算法分别是BKDRHash算法 APHash算法和DJBHash算法
我们写出这三种算法的类并且给出它们的仿函数
struct BKDRHash
{
size_t operator()(const string& s)
{
size_t value = 0;
for (auto x : s)
{
value = value * 131 + x;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t value = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
value ^= ((value << 7) ^ s[i] ^ (value >> 3));
}
else
{
value ^= (~((value << 11) ^ s[i] ^ (value >> 5)));
}
}
return value;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
if (s.empty())
{
return 0;
}
size_t value = 5381;
for (auto ch : s)
{
value += (value << 5) + ch;
}
return value;
}
};
插入函数
布隆过滤器的插入很简单 我们这里不考虑是否之前存在数据的影响
要插入一个数据就将通过哈希函数计算出来的位置设置位
// 插入
void Insert(const K& k)
{
size_t i1 = h1(k) % N;
size_t i2 = h2(k) % N;
size_t i3 = h3(k) % N;
// 设置位
_bs.set(i1);
_bs.set(i2);
_bs.set(i3);
}
我们这里使用了三种哈希算法类创建出来的对象调用仿函数来处理数据
当然如果不想创建对象也可以使用匿名对象的方式来使用 代码表示如下
size_t i1 = Hash1()(k);
查找函数
布隆过滤器的查找的关键是判断不存在的位
如果有位不存在 那么它一定不存在
如果全部位存在 那么它可能存在
// 查找
bool Test(const K& k)
{
size_t i1 = h1(k) % N;
size_t i2 = h2(k) % N;
size_t i3 = h3(k) % N;
if (_bs.test(i1) == false)
{
return false;
}
if (_bs.test(i2) == false)
{
return false;
}
if (_bs.test(i3) == false)
{
return false;
}
return true;
}
删除函数
布隆过滤器的删除函数是不存在的
因为删除一个数据会影响其他数据的真实性
并且这个数据也不一定存在 只是有可能存在
那么我如何能够让布隆过滤器支持删除呢
- 保证删除后不会影响到其他数据 将位图中的每个bit位置设置一个对应的计数值 插入++ 删除–
- 保证删除的数据一定存在 当我们觉得这个数据可能存在的时候 遍历整个数据库查找这个数据 验证它是否存在
但是布隆过滤器没有提供删除函数 这是为什么呢?
因为布隆过滤器本身就是为了提高效率和节省空间被发明出来的
如果我们将每个bit位置设置一个对应的计数值 对于空间会有一个极大的消耗
磁盘的读取数据是很慢的 如果我们每次删除都要读取一遍磁盘这对于效率又是一个极大的消耗
考虑以上种种因素 布隆过滤器不设置删除成员函数
布隆过滤器的优点
- 增加和查找的时间复杂度是O(K) K一般为常数 和数据量大小无关
- 哈希函数之间相互没有关联 方便硬件进行计算
- 布隆过滤器本身不需要储存元素 对于某些需要保密性的场景有很大优势
- 布隆过滤器对比其他传统的数据存储结构 空间比较节省
- 数据量很大的时候布隆过滤器可以表示全集 其他的数据结构不能
- 使用同一组哈希函数的布隆过滤器可以进行交 并 差集运算
布隆过滤器的缺点
- 最致命的当然是存在误判的可能性
- 不能删除元素
- 不能够读取数据
布隆过滤器的使用场景
布隆过滤器的使用场景有一个大前提 那就是它的误判不会对业务逻辑有很大的影响
比如说当我们重新改变我们的用户名字的时候(网站规则用户名字不能重复)
- 如果不使用布隆过滤器就要使用红黑树这样的结构来存储用户的名字 当用户数量很大的时候这样子左是极其浪费空间的 因为我们只需要判断在不在就好了
- 我们使用布隆过滤器 判断不存在是不可能误判的 如果不存在则表示这个用户名字可以使用
- 因为规则规定了用户名字不能重复 如果重复的话可能会引起一些系统bug 所以说假设用户名字在布隆过滤器中被判断为可能存在 那么不管这个用户名字是否存在 就可以直接告诉用户该用户名已存在 请用户重新输入