"啊~所有经历给它赋予魔力。"
很久没更新过C专栏的文章了,借复习(review)的机会,本节的内容针对我们一些常见、常用的C库函数的模拟实现。
“当你行走了一段时间后,回头往往那不管是起初咿咿呀呀胡乱踩陷的小坑时,还是之后慢慢地、熟练地避开了水洼、泥淖,不同的时段,不同的境地,回首那时的稚嫩与热情,我想总该会留下些感慨和欣慰。”
一、strlen
strlen - calculate the length of a string
#include <string.h>
size_t strlen(const char *s);
我们都知道,strlen函数,求的是一个字符串的长度。那么当它遇到"\0"时,就结束。
因为在C中,字符串结束的标志是以"\0"结尾。
(1)Count计数法
这个方法比较简单,也很好想。我们在函数体内定义一个count计数器,当*str !='\0'时,++count。并将count 作为返回值返回。
size_t my_strlen1(const char* str)
{
//记录字符串的长度
size_t count = 0;
while(*str !='\0')
{
count++;
str++;
}
return count;
}(2)递归求长度
我们通过访问str的每个字符,将下一个字符串的地址传递给递归函数并+1。不过值得注意的是,不能写成str++,这样会造成死循环。
size_t my_strlen2(const char* str)
{
if(*str == '\0') {
return 0;
}
else{
//return 1 + my_strlen2(str+1);
return 1 + my_strlen2(++str);
}
}(3)指针减法
我想,我们可能很少用到这个小小的知识点。那就是指针虽然不能做加法 但是能做减法。我们来看看下面的代码。
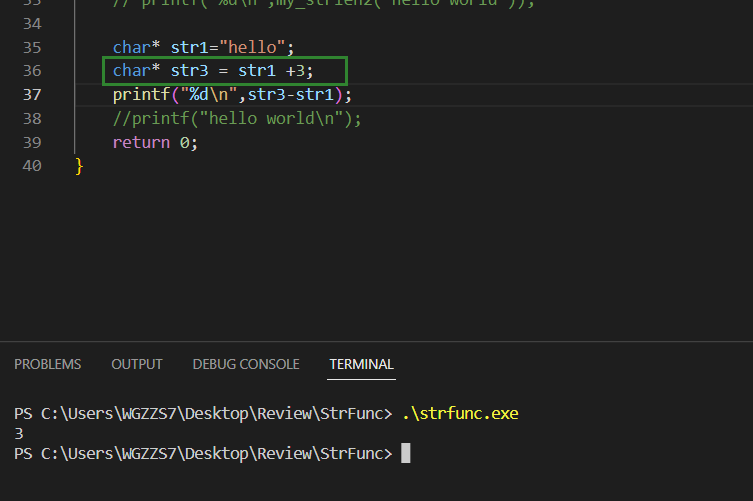
当指针-指针,得到的结果是,这个区域之间的个数。凭着这个知识点,也就有下面的代码了。
size_t my_strlen3(const char* str)
{
const char* end = str;
while(*end)
{
end++;
}
return end-str;
}(4)测试
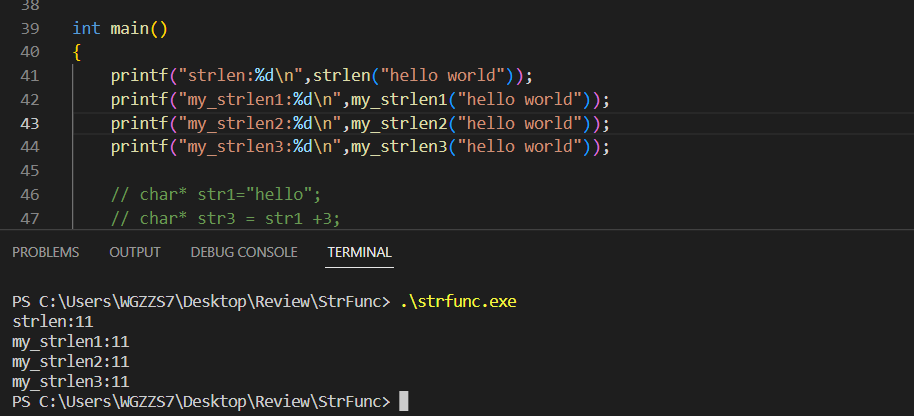
与库函数的strlen求得的结果一致。
二、strcpy\strncpy
strcpy, strncpy - copy a string
#include <string.h>
char *strcpy(char *dest, const char *src);
char *strncpy(char *dest, const char *src, size_t n);
strcpy:
The strcpy() function copies the string pointed to by src, including the terminating null byte ('\0'), to the buffer pointed to by dest. The strings may not overlap, and the destination string dest must be large enough to receive the copy.
strcpy()会将包含'\0'终止的部分从 指向src指针处 拷贝复制到 dest指针指向的缓冲区。dest的缓冲区必须足够大,从而有足够的空间容纳拷贝的大小。
注:这里的"The strings may not overlap",指的是 字符串不能重叠
strncpy:
The strncpy() function is similar, except that at most n bytes of src are copied. Warning: If there is no null byte among the first n bytes of src, the string placed in dest will not be null-terminated.
strncpy()指的是最多拷贝赋值n个 src的字节。注意:如果如果src中的n个字节中没有'\0',那么拷贝到dest缓冲区中的也没有'\0'。
RETURN VAL:
The strcpy() and strncpy() functions return a pointer to the destination string dest.
两个函数的返回值,都是指向dest的指针。
(1)strcpy
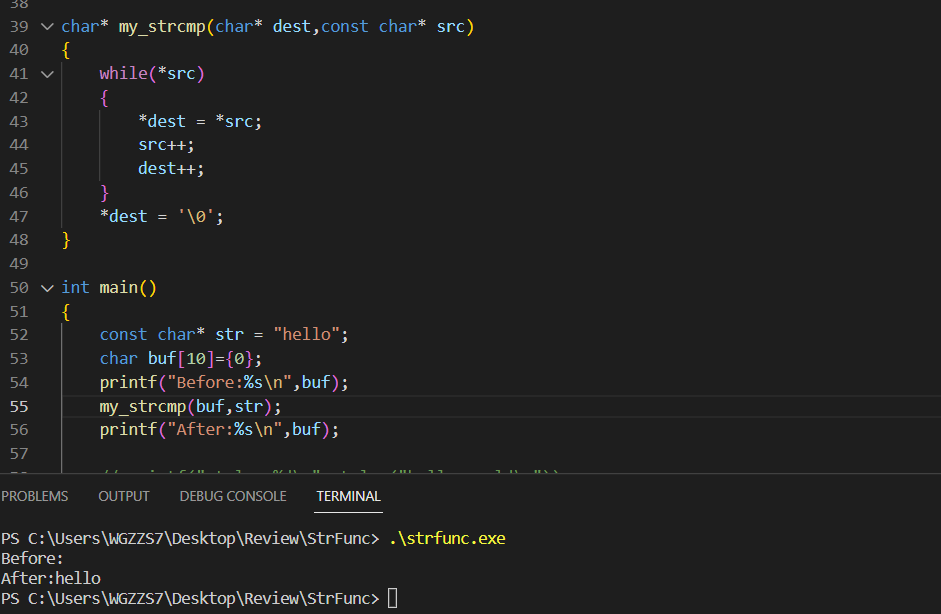
我们第一次这样写,是以src为基准将src的字符拷贝到dest。那么也就意味着,当src走到'\0'时,那么字符串拷贝的工作也就做完了。最后也就给dest添上'\0'即可。但是这样从代码上感觉很复杂呢?既然要拷贝src -> dest。直接赋值岂不美哉? 为此我们进行了如下的优化:
char* my_strcpy(char* dest,const char* src)
{
//保证代码安全性
assert(dest && src);
char* ret = dest;
while(*dest++ = *src++){
//do nothing
}
return ret;
}当src走到'\0',并且把'\0'赋值给dest。但是此时的结果为0,0为假,循环自然就会结束。
测试;
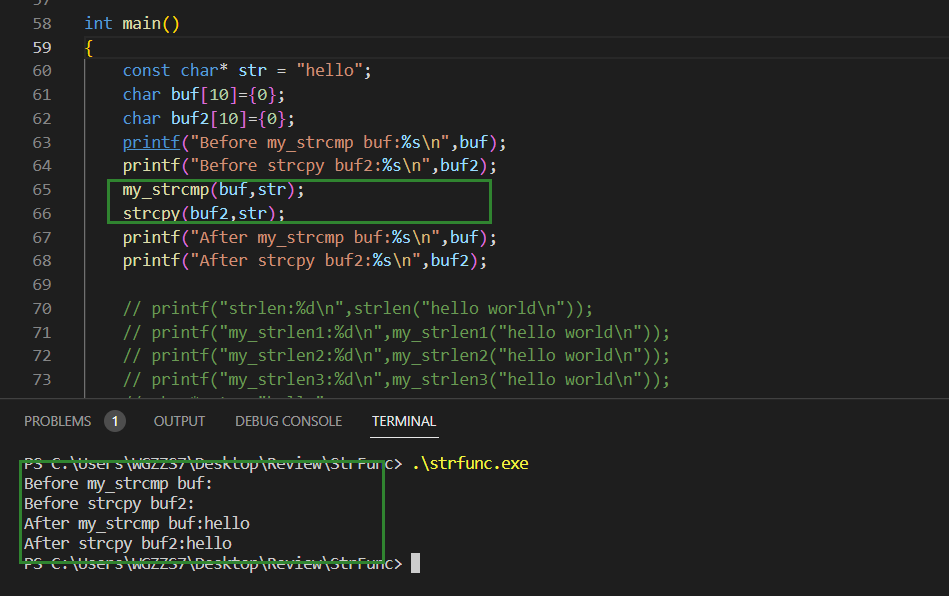
(2)strncpy
char* my_strncpy(char* dest,const char* src,size_t n)
{
assert(dest && src);
//记录拷贝个数
size_t i =0;
for(;i<n && src[i] !='\0';++i)
{
dest[i] = src[i];
}
//如果拷贝的src中不包含'\0'也就不拷贝
for(;i<n;i++)
{
dest[i] ='\0';
}
return dest;
}在循环赋值的时候,也就不仅仅以*src = '\0'作为 结束循环的依据。如果拷贝n的字节中包含'\
0',那么下面一个循环就会处理。

测试;
三、strcat
strcat, strncat - concatenate two strings
#include <string.h>
char *strcat(char *dest, const char *src);
char *strncat(char *dest, const char *src, size_t n);
The strcat() function appends the src string to the dest string, overwriting the terminating null byte ('\0') at the end of dest, and then adds a terminating null byte. The strings may not overlap, and the dest string must have enough space for the result. If dest is not large enough, program behavior is unpredictable; buffer overruns are a favorite avenue for attacking secure programs.
strcat()将src字符串附加到dest字符串,并覆盖掉dest最后的中的'\0',并在增加后的末尾添上'\0'。字符串不能重叠,dest字符串必须有足够的空间用于结果。缓冲区溢出是不可控的。
strncat() function is similar, except that
* it will use at most n bytes from src; and
* src does not need to be null-terminated if it contains n or more bytes.
As with strcat(), the resulting string in dest is always null-terminated.
If src contains n or more bytes, strncat() writes n+1 bytes to dest (n from src plus the terminating null byte). Therefore, the size of dest must
be at least strlen(dest)+n+1.
strncat()的功能也相似,只不过多了两个特点:
①使用src的n个字符 ②如果src包含n个字节或者更多,那么就不需要以'\0'结尾。
src包含n个或者更多,strncat向 dest 写入的字节为 n+1。因此,至少dest的空间存留为strlen(dest)+1。
(1)strcat
strcat是从dest的末尾附加src,并且会将原来的'\0'覆盖上。
char* my_strcat(char* dest,const char* src)
{
assert(dest);
char* ret = dest;
//移动到'\0'
while(*++dest){
//do nothing
//dest++
}
//赋值
while(*dest++=*src++){
//do nothing
}
return ret;
}第一个while里的dest不能写成后置++;因为它是先判断再++,也就是当判断到*dest == '\0'的时候,dest已经是走到了'\0'的后一个了。在后面也就覆盖不了原dest中的'\0'。
测试;

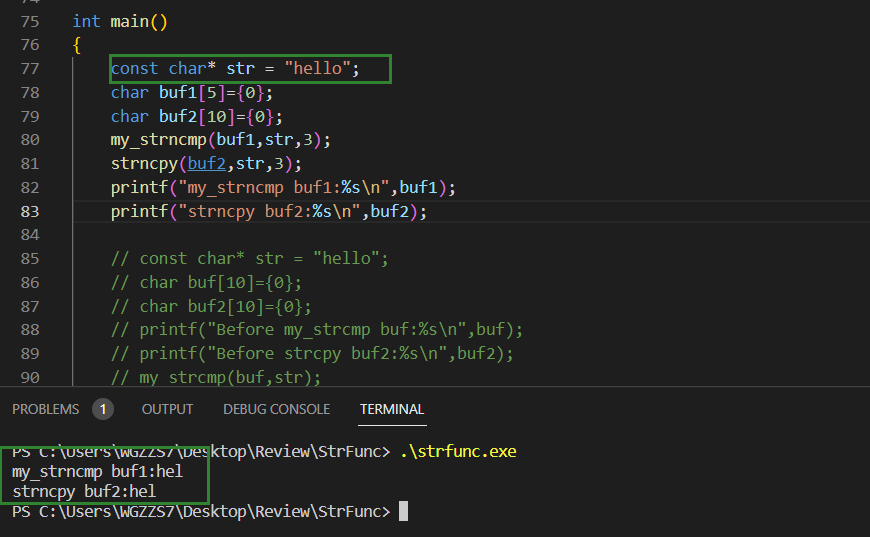
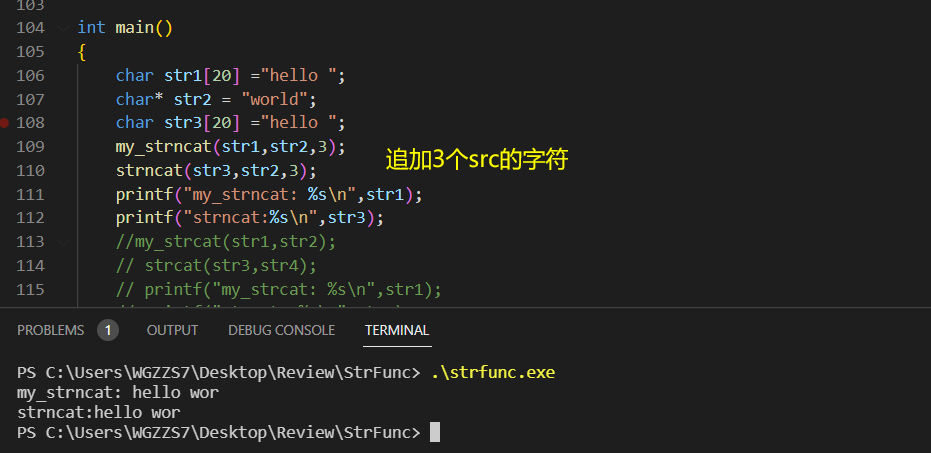
(2)strncat
与strncat实现类似,其中结束条件可以参考strncpy。
char* my_strncat(char* dest,const char* src,size_t n)
{
assert(dest);
//dest的末尾
size_t dest_len = strlen(dest);
size_t i = 0;
for(;i < n && src[i] !='\0';++i)
{
dest[dest_len+i] = src[i];
}
dest[dest_len+i] = '\0';
return dest;
}测试;
四、strcmp
strcmp - compare two strings
#include <string.h>
int strcmp(const char *s1, const char *s2);
The strcmp() function compares the two strings s1 and s2. It returns an integer less than, equal to, or greater than zero if s1 is found, respectively, to be less than, to match, or be greater than s2.
strcmp()比较s1、s2两个字符串的大小。如果发现s1分别小于、匹配、或者大于s2,那么就会相应地返回一个小于、等于、大于0 的整数。
RETURN VAL:
The strcmp() functions return an integer less than, equal to, or greater than zero if s1 (or the first n bytes thereof) is found,respectively, to be less than, to match, or be greater than s2.
如果s1(或其前n个字节)分别小于、匹配或大于s2,则strcmp()函数返回一个小于、等于或大于零的整数。
字符串比较函数想必诸位读者并不陌生,它实质比较的是 每个字符的ASCII码和字符串长度。
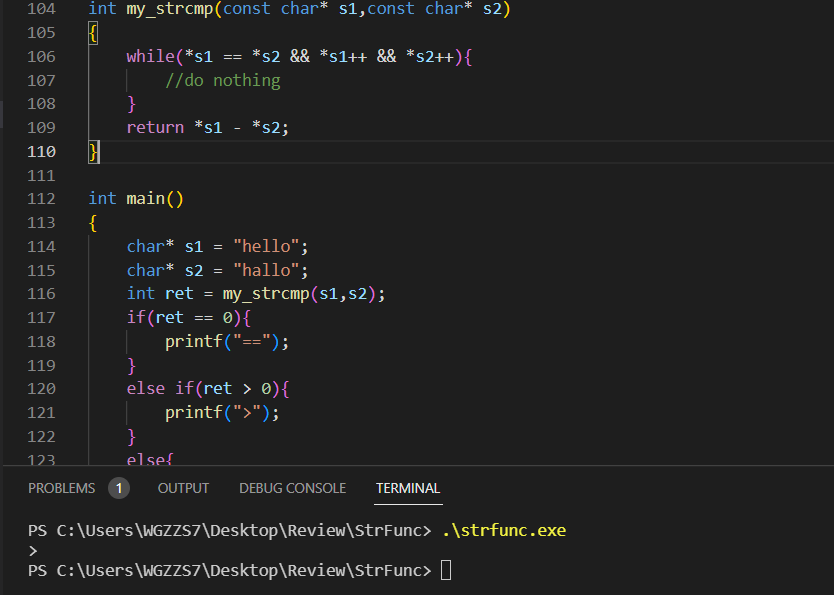
int my_strcmp1(const char* s1,const char* s2)
{
assert(s1);
assert(s2);
while(*s1 == *s2 && *s1++ && *s2++){
//do nothing
}
return *s1 - *s2;
}
测试;
五、strstr
strstr locate a substring
#include <string.h>
char *strstr(const char *haystack, const char *needle);
The strstr() function finds the first occurrence of the substring needle in the string haystack. The terminating null bytes ('\0') are not compared.
strstr()会查找第一次出现在haystack的子串指针。最后的'\0'不会参与查找。
Return Val:
strstr() functions return a pointer to the beginning of the substring, or NULL if the substring is not found.
strstr() 会返回一个指向这个子串的起始地址,如果返回NULL,则是不是该string的子串。
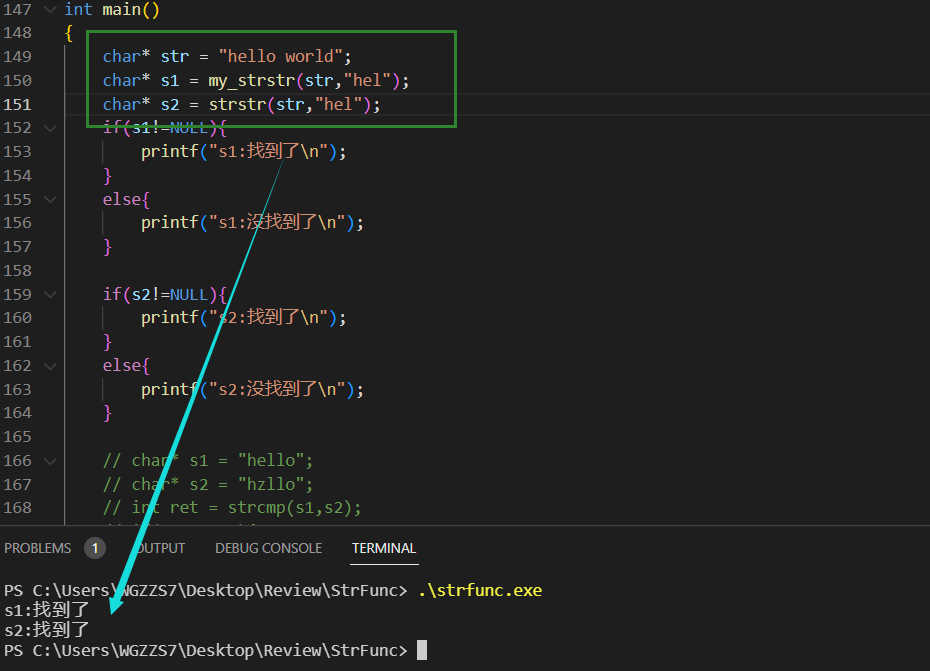
char* my_strstr(const char* haystack,const char* needle)
{
assert(haystack && needle);
//可以认为 空是 任何字串的子串
if(needle == NULL) return (char*)(haystack);
//标志字串是否结束
char* start = (char*)haystack;
char* end;
//指向needle的指针
char* begin;
while(*start)
{
//start1指向的是 needle的开头
//start2指向的是 haystack的前一个
begin = (char*)needle;
end = start;
while(*begin && *end && *end == *begin)
{
//此时[ptr,start2]就是 子串区间
end++;
begin++;
}
//什么时候说明找到子串了?
//当begin == '\0'时 走到了needle的末尾
if(*begin == '\0')
{
return start;
}
start++;
}
}strstr的实现稍显复杂。毕竟这里面的代码用了三个指针。一个指针控制要找的子串,另外两个指针控制haystack里的字串的遍历。
测试;

六、memcpy
memcpy - copy memory area
#include <string.h>
void *memcpy(void *dest, const void *src, size_t n);
The memcpy() function copies n bytes from memory area src to memory area dest. The memory areas must not overlap. Use memmove(3) if the memory areas do overlap.
memcpy()函数将n个字节从内存区域src复制到内存区域dest。如果内存区域重叠,请使用memmove(3)。
RETURN VALUE
The memcpy() function returns a pointer to dest.
返回一个指向dest的指针
我们刚刚学了strcpy,现在又来了个memcpy,那么这两货有什么联系呢? 至少在我浅薄的知识的认知里,有屁的联系!从函数的设计上就可以斩断这妄想,我们可以看到memcpy的参数不再像strcpy的参数是char*\const char*。为什么? 不还是因为strcpy针对的是字符串拷贝使用环境,有指针底子的就知道,void* 是很出色的指针设计。它可以接受任意指针,也可以给任意指针赋值。但唯一禁止的操作,是对其进行"*"。memcpy针对的是内存级的拷贝赋值,对象不单单是一个char类型这么简单,可能是一个int、double,也可能是一个抽象的结构体对象……
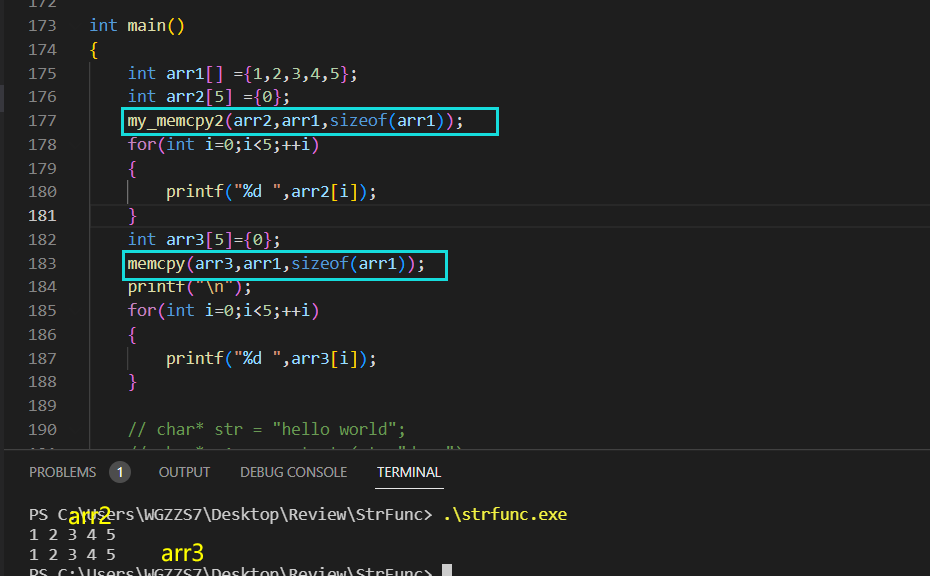
void* my_memcpy1(void* dest,const void* src,size_t n)
{
assert(dest && src);
char* s1 = (char*)dest;
char* s2 = (char*)src;
while(n--)
{
*s1++ = *s2++;
}
return dest;
}
void* my_memcpy2(void* dest,void* src,size_t count)
{
assert(dest && src);
void* ret = dest;
while(count--){
*(char*)dest = *(char*)src;
dest =(char*)dest+1;
src= (char*)src+1;
}
return ret;
}上面的有两种写法,当然其实差别不大。就是看起来不一样吧罢了。
为什么拷贝要换算成char类型???
我们根据刚刚比较strcpy 与 memcpy,我们发现它们因为适用于不同的场景,一个的参数选择了char*,一个的参数选择了void*,但是为什么在函数体内实现又把它转换为char* 了呢?这里涉及的技巧,又来自对"*"的理解。
“*”向后读取的大小,取决于指针类型。换句话说,如果是指针类型是int,double当"*"时,向后访问的字节分别是4byte、8byte。
由此,不管你要拷贝的是double类型的数据类型,还是int类型的数据类型,不用关心"*"时到底该访问几个字节,而是统一用char指针类型,1byte1byte地拷贝复制。 从而有效应对任何场景、情况。这也是为什么,memcpy简介中,n是以byte为单位的原因。
测试;
七、memove
我觉得不安逸,我现在就想在原地拷贝。arr的范围为{1,2,3,4,5,6,7,8,9,10};此时我要从3开始,从原数组原地向后拷贝5个字节。
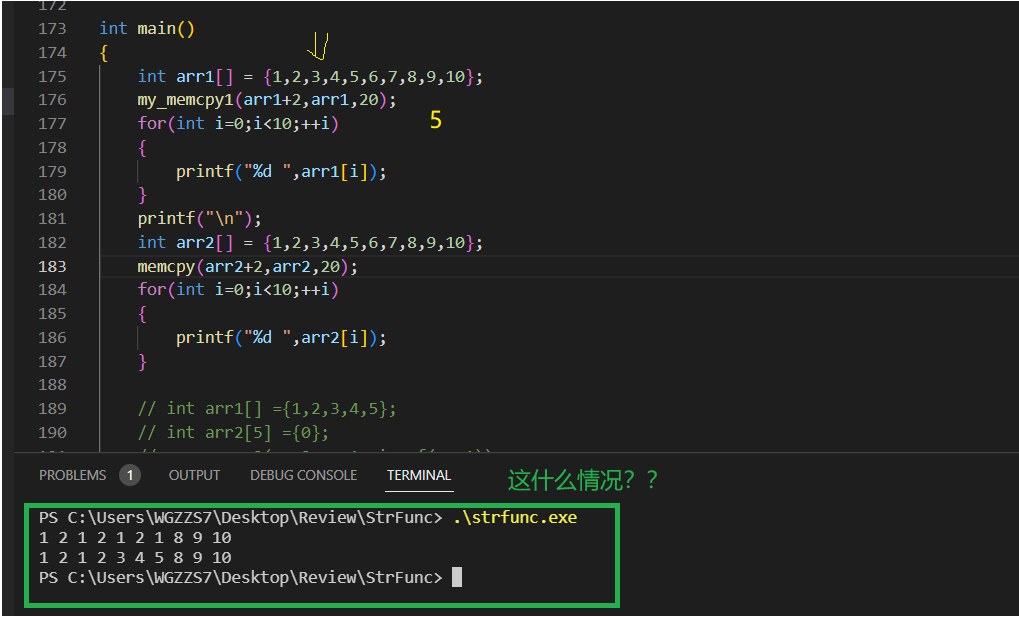

为什么在memcpy内存不重叠的问题上,两个方法的结果一样,当存在原地拷贝的时候,得到的结果就不一样了呢?其实不是我们实现错误了,而是微软库针对memcpy的实现是和我们不一样的,它的memcpy实现,是参照了memmove的实现方式。这也是为什么说,当地址重叠时,更倾向用memmove。但事实上,这两个函数的功能确乎有些冗余。我想,也就能解释通为什么库里的memcpy也能独立解决dest、src相overlap的问题。
memmove - copy memory area
#include <string.h>
void *memmove(void *dest, const void *src, size_t n);
The memmove() function copies n bytes from memory area src to memory area dest. The memory areas may overlap: copying takes place as though the bytes in src are first copied into a temporary array that does not overlap src or dest, and the bytes are then copied from the temporary array to dest.
memmove()将拷贝n个字节从src内存区域到dest内存区域。内存区域可能会发生重叠。当复制发生时,当遇到src与dest重叠,会把src先拷贝到临时数组(不与dest重叠),在那之后,再将临时数组里的内容拷贝进dest中。
RETURN VALUE
The memmove() function returns a pointer to dest.
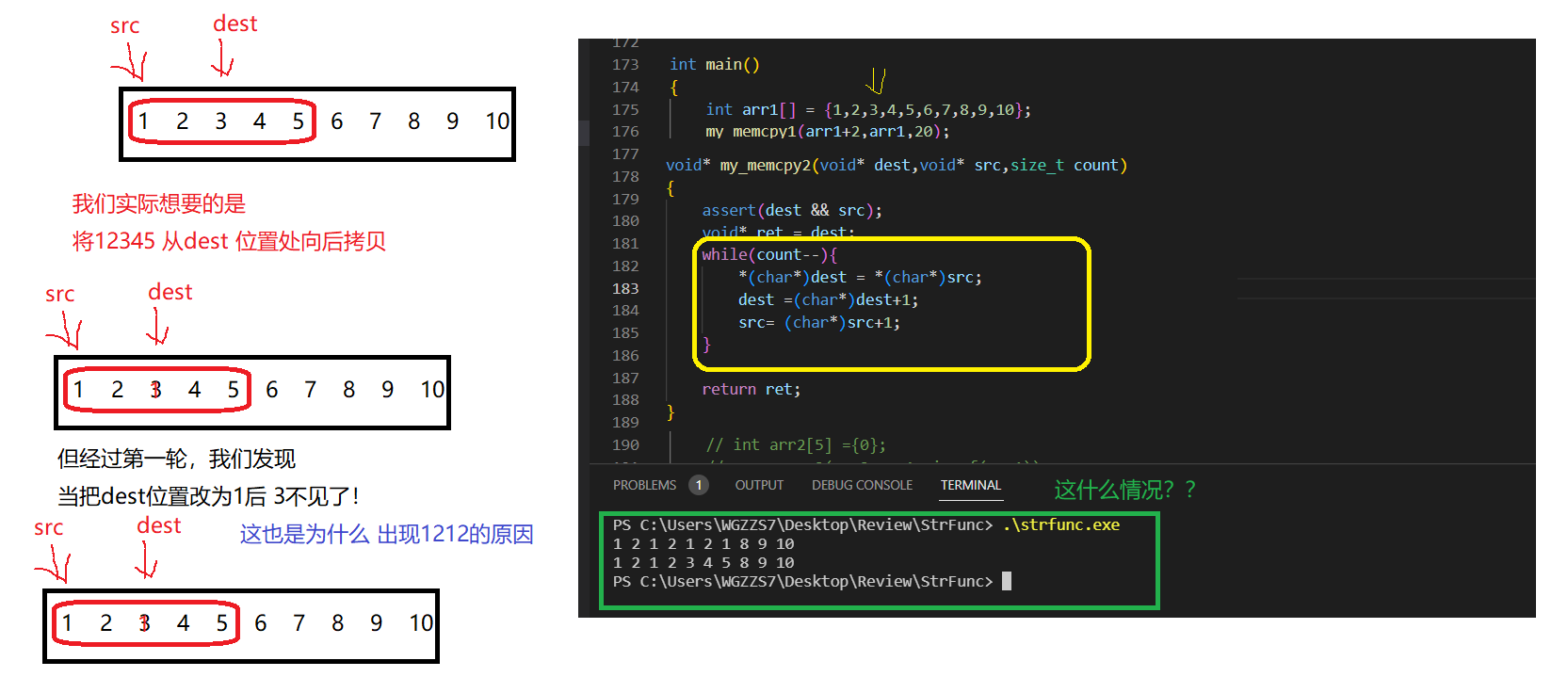
由此,src与dest在处于overlap条件下,其位置前后就很有讲究。

我们自然而然得出了两个表达式, if(dest >= (char*)src + count || dest <= src)。
满足这个表达式,那就是普通的memcpy。没啥好聊的。
但是不满足呢?如何处理呢?

还有一种理解或者可以这样理解:if(dest < src) else //src>=dest
void* my_memmove(void* dest,const void* src,size_t count)
{
void* ret = dest;
if(dest <= src || (char*)dest >= (char*)src + count){
//不存在lapover
while(count--)
{
*(char*)dest= *(char*)src;
dest=(char*)dest +1;
src=(char*)src+1;
}
}
else{
//存在lapover
//更新dest 与 src
dest = (char*)dest + count - 1;
src = (char*)src + count - 1;
while(count--){
*(char*)dest = *(char*)src;
dest=(char*)dest-1;
src=(char*)src-1;
}
}
return ret;
}测试;
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~