一 背景描述
1.1 问题产生
在分布式系统中,怎么使用全局唯一id?
在分布式是,微服务的架构中,或者大数据分库分表中,多个不同节点怎么保持每台机器生成的主键id不重复,具有唯一性?
- 方案1:mysql的自增主键; 设定一定的步长;如3台机器,3台节点初始值1,2,3,步长为3;机器A:1,4,7,10;机器B:2,5,8,11; 机器c:3,6,9,12
- 方案2:使用uuid,无序且生成的串比较长,与mysql官方建议尽量使用较短的字符串冲突
- 使用redis的原子性性产生主键,但是使用过程前期比较麻烦,需要搭建配置一堆东西。
这时,雪花算法是其中一个用于解决分布式 id 的高效方案,也是许多互联网公司在推荐使用的。
二 雪花算法
2.1 雪花算法
雪花算法:解决分布式高并发集群中,提供产生全局唯一的id,就是生成一个的 64 位比特位的 long 类型的唯一 id。
2.2 雪花算法的结构

最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
接下来 41 位存储毫秒级时间戳,2^41/(1000*60*60*24*365)=69,大概可以使用 69 年。
再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
2.3 雪花算法的使用
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
2.4 案例
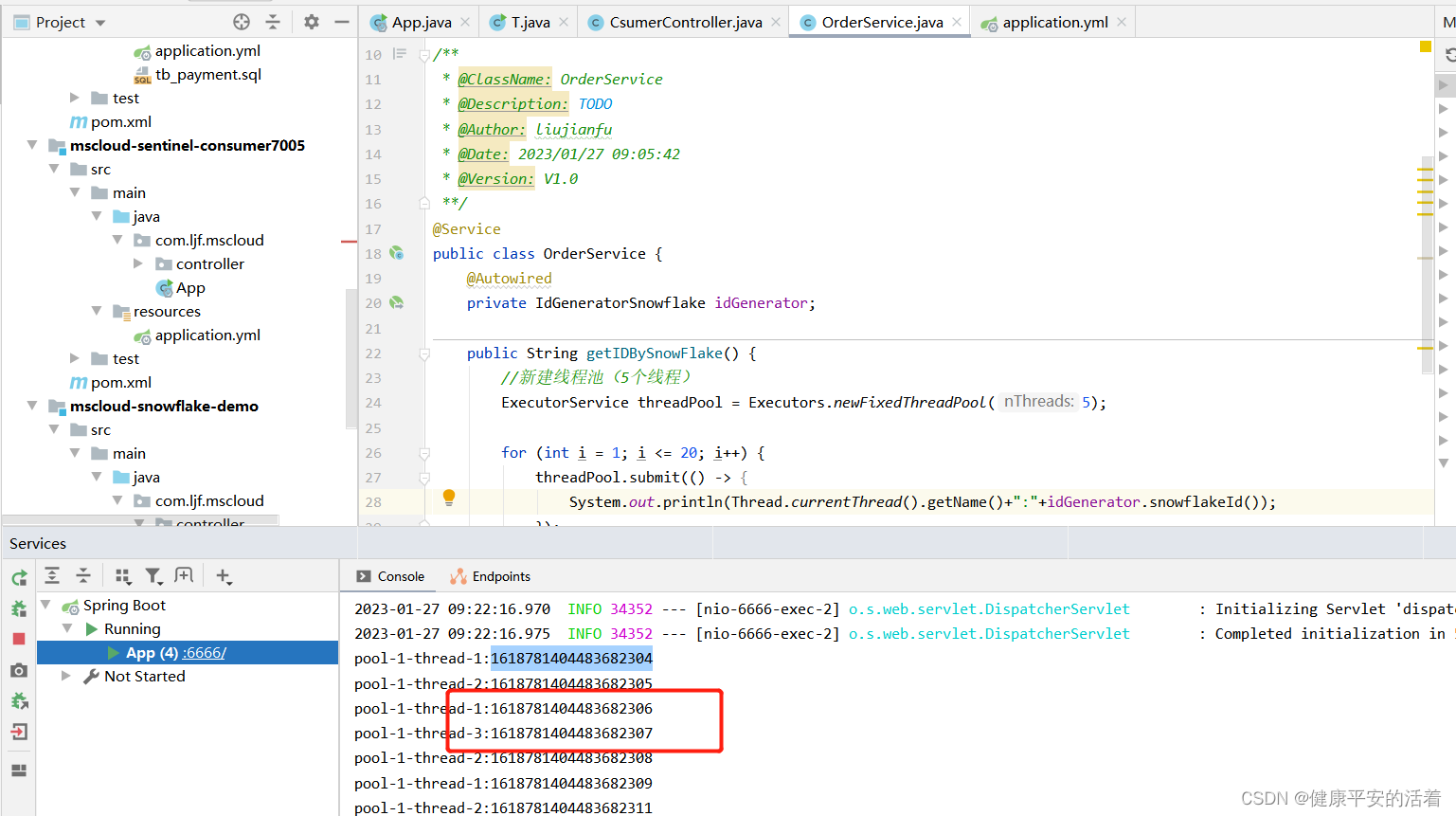
2.5 优缺点
优点:
高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
一般分布式ID只要求趋势递增,并不会严格要求递增,90%的需求都只要求趋势递增)
缺点:
服务器时钟回拨时可能会生成重复 id,解决办法:
百度开源的分布式唯一ID生成器UidGenerator
Leaf-- 美团点评分布式ID生成系统