迁移学习
为什么要?
源域样本与目标域样本分布有区别,目标域样本量不够
平时建模用的迁移学习场景
1、新开某个消费分期场景样本量少,需要用其他场景的数据建模
2、业务被迫停滞3个月再重启,大部分训练样本比较老旧,新的训练样本又不够
3、在某个新国家开展类似国内业务,因国情不同,部分特征分布不同
主要任务
缩小边缘分布之间和条件分布下的差异
迁移学习就是将知识从源域(Source)迁移到目标域(Targe)的过程
几个基本概念
Domain(域):有feature_space(特征空间)和probability(概率)两部分。所以当domain不同,有两种情况,可能是feature_space不同,也可能feature_space相同,但probability不同
Task(任务):有label space(标记空间)和objective predictictive funtion(目标预测函数)。当Task不同时,同上
Source(源):用于训练模型的域或任务
Targe(任务):用前者模型对自己的数据进行预测/分类/聚类等机器学习任务的域/任务
增量学习
主要关注的是灾难性遗忘(Catastrophic forgetting),平衡新知识与旧知识之间的关系。但我们可以用它来模拟神经网络中的finetune.
xgboost提供两种增量学习:
1、在当前迭代树的基础上增加新树,原树不变
2、当前迭代树结构不变,重新计算叶节点权重,同时也可增加新树
有什么用?
仿照神经网络中基于模型的迁移学习,先用一部分样本训练前几颗树,再用新样本学习后面的树;通常我们用源域与目标域的混合数据训练前几颗树,以得到更好的表达能力,最后用目标域的数据训练后几颗树。
举个例子
比如我们有大量英短银渐层的图片,和少量美短起司的照片,想训练一个判别当前的猫是不是美短起司的学习器。如果我们用英短银渐层图片来作为样本,显然训练的模型是不能用来判别美短起司的,用美短起司的样本来训练,样本量又太小。这时候我们可能会使用英短银渐层来训练一个卷积神经网络,然后将这个网络的中间结构取出来作为目标模型的前半部分,然后在少量的美短起司的样本上再继续学习后面的几层网络。熟悉卷积神经网络的同学可能知道,CNN的前几层主要学习的是轮廓和局部形状等共性特征。这样通过前面的学习,我们就知道了猫咪的共性,再通过对起司的学习得到细节上的差异。
深度学习迁移方法
模型再优化
层迁移
域对抗迁移
零样本学习
目前有突破的迁移学习算法
基于实例的迁移学习算法:代表有Dai等人提出的基于实例的 TrAdaBoost 迁移学习算法。当目标域中的样本被错误地分类之后,可以认为这个样本是很难分类的,因此增大这个样本的权重,在下一次的训练中这个样本所占的比重变大。如果源域中的一个样本被错误地分类了,可以认为这个样本对于目标数据是不同的,因此降低这个样本的权重,降低这个样本在分类器中所占的比重。
基于特征的迁移学习方法:基于特征选择的迁移学习方法是识别出源领域与目标领域中共有的特征表示,然后利用这些特征进行知识迁移。基于特征映射的迁移学习方法是把各个领域的数据从原始高维特征空间映射到低维特征空间,在该低维空间下,源领域数据与目标领域数据拥有相同的分布。这样就可以利用低维空间表示的有标签的源领域样本数据训练分类器,对目标测试数据进行预测。
基于模型的迁移学习方法:由源域学习到的模型应用到目标域上,再根据目标域学习新的模型。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类等方法寻找最优化的标定参数。比如 TRCNN等
如何实现
缩小训练集与测试集的边缘分布的距离,通常的做法是 清洗训练样本,去除一些异常点或者减少他们的权重。这样可以将训练样本的分布与测试样本的分布保持一致。
如果想减少条件分布的差异呢?用决策树举例子,我们还需要在决策树划分的每一层的样本中,重复上述过程,才可以保证条件概率分布也是相近的。
adaboost算法
迭代过程



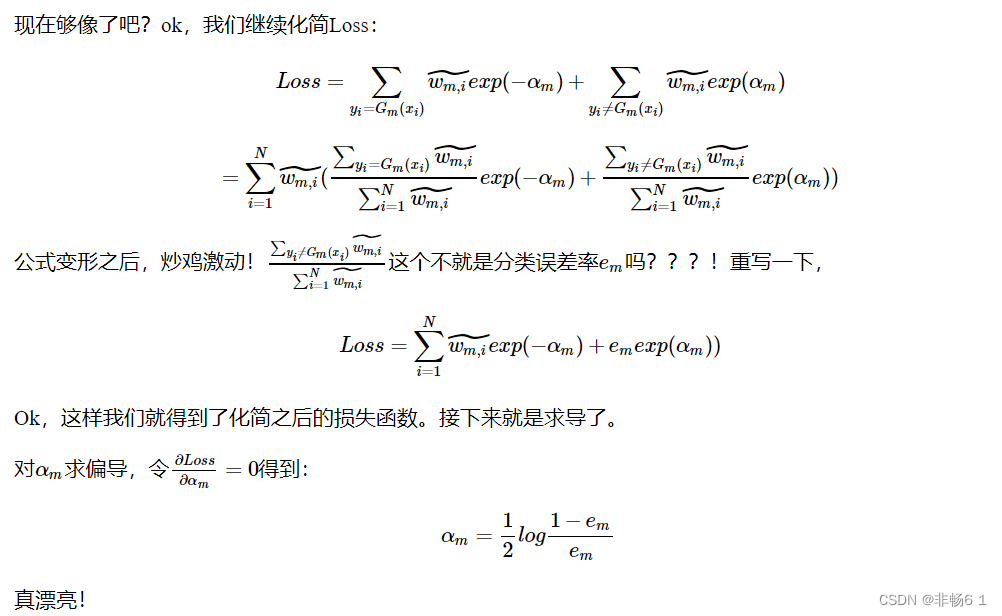
Tradeboost


案例:跨国家跨场景迁移模型
某知名金融公司在印度新展开的小额现金贷产品,积累了少量Labled样本(约1200条),用于建模样本量显然不够,考虑到虽然国家不同,但借款用户的本质大体相似。考虑从国内大额产品的存量客户上面做迁移,首先制作四个变量。制作变量时要保证国内与印度客群都有这个字段并且字段的含义能保证一致。所以当前的问题就变成了:将知识从国内样本(源域)迁移至只有少量样本的印度客群(目标域)。
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
import numpy as np
import random
import math
from sklearn.calibration import CalibratedClassifierCV
data = pd.read_excel('./data/tra_sample.xlsx')
data.head()
data.type.unique()
feature_lst = ['zx_score','msg_cnt','phone_num_cnt','register_days']
train = data[data.type == 'target'].reset_index().copy()
diff = data[data.type == 'origin'].reset_index().copy()
val = data[data.type == 'offtime'].reset_index().copy()
#trans_S, trans_A, label_S, label_A, test
train = train.loc[:1200]
trans_S = train[feature_lst].copy()
label_S = train['bad_ind'].copy()
trans_A = diff[feature_lst].copy()
label_A = diff['bad_ind'].copy()
val_x = val[feature_lst].copy()
val_y = val['bad_ind'].copy()
test = val_x.copy()
lr_model = LogisticRegression(C=0.1,class_weight = 'balanced',solver = 'liblinear')
lr_model.fit(trans_S,label_S)
y_pred = lr_model.predict_proba(trans_S)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(label_S,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(test)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
trans_data = np.concatenate((trans_A, trans_S), axis=0)
trans_label = np.concatenate((label_A, label_S), axis=0)
lr_model = LogisticRegression(C=0.3,class_weight = 'balanced',solver = 'liblinear')
lr_model.fit(trans_A,label_A)
y_pred = lr_model.predict_proba(trans_data)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(trans_label,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(test)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()import numpy as np
from sklearn import tree
#逻辑回归的学习率、权重的大小,影响整体收敛的快慢
#初始权重很重要
# H 测试样本分类结果
# TrainS 目标域样本
# TrainA 源域样本
# LabelS 目标域标签
# LabelA 源域标签
# Test 测试样本
# N 迭代次数
#计算weight
def calculate_P(weights, label):
total = np.sum(weights)
return np.asarray(weights / total, order='C')
#用逻辑回归作为基分类器,输出概率
def train_classify(trans_data, trans_label, test_data, P):
clf = LogisticRegression(C=0.3,class_weight = 'balanced',solver='liblinear')
clf.fit(trans_data, trans_label, sample_weight=P[:, 0])
return clf.predict_proba(test_data)[:,1],clf
#计算在目标域上面的错误率
def calculate_error_rate(label_R, label_H, weight):
total = np.sum(weight)
return np.sum(weight[:, 0] / total * np.abs(label_R - label_H))
#根据逻辑回归输出的score的得到标签,注意这里不能用predict直接输出标签
def put_label(score_H,thred):
new_label_H = []
for i in score_H:
if i <= thred:
new_label_H.append(0)
else:
new_label_H.append(1)
return new_label_H
#指定迭代次数,相当于集成模型中基模型的数量
N=500
trans_data = np.concatenate((trans_A, trans_S), axis=0)
trans_label = np.concatenate((label_A, label_S), axis=0)
row_A = trans_A.shape[0]
row_S = trans_S.shape[0]
row_T = test.shape[0]
test_data = np.concatenate((trans_data, test), axis=0)
# 初始化权重
weights_A = np.ones([row_A, 1])/row_A
weights_S = np.ones([row_S, 1])/row_S*2
weights = np.concatenate((weights_A, weights_S), axis=0)
bata = 1 / (1 + np.sqrt(2 * np.log(row_A / N)))
# 存储每次迭代的标签和bata值?
bata_T = np.zeros([1, N]) # 存每一次迭代的 error_rate / (1 - error_rate)
result_label = np.ones([row_A + row_S + row_T, N])
predict = np.zeros([row_T])
trans_data = np.asarray(trans_data, order='C')
trans_label = np.asarray(trans_label, order='C')
test_data = np.asarray(test_data, order='C')
best_ks = -1 #最优KS
best_round = -1 #最优基模型数量
best_model = -1 #最优模型
# 初始化结束
for i in range(N):
P = calculate_P(weights, trans_label)
result_label[:, i],model = train_classify(trans_data, trans_label,
test_data, P)
score_H = result_label[row_A:row_A + row_S, i]
pctg = np.sum(data.bad_ind)/len(data.bad_ind)
thred = pd.DataFrame(score_H).quantile(1-pctg)[0]
label_H = put_label(score_H,thred)
error_rate = calculate_error_rate(label_S, label_H,
weights[row_A:row_A + row_S, :])
if error_rate > 0.5:
error_rate = 0.5
if error_rate == 0:
N = i
break # 防止过拟合
# error_rate = 0.001
bata_T[0, i] = error_rate / (1 - error_rate)
# 调整目标域样本权重
for j in range(row_S):
weights[row_A + j] = weights[row_A + j] * np.power(bata_T[0, i],
(-np.abs(result_label[row_A + j, i] - label_S[j])))
# 调整源域样本权重
for j in range(row_A):
weights[j] = weights[j] * np.power(bata, np.abs(result_label[j, i] - label_A[j]))
y_pred = result_label[(row_A + row_S):,i]
fpr_lr_train,tpr_lr_train,_ = roc_curve(val_y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('test_ks : ',train_ks,'当前第',i+1,'轮')
if train_ks > best_ks :
best_ks = train_ks
best_round = i
best_model = modely_pred = best_model.predict_proba(trans_S)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(label_S,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = best_model.predict_proba(test)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()