文章目录
- 一般流程
- 问题引入
- 数据集与测试集
- 过拟合与泛化
- 开发集
- 监督学习和非监督学习
- 问题分析
- 训练集、验证集、测试集
- 模型设计
- 模拟训练过程
- 课程代码
- 课后习题代码
课程来源: 链接
文档参考: 链接
以及 BirandaのBlog!
一般流程
对于一般的线性模型来说,分析问题的格式一般为:
- 搜集数据
- 选择模型
- 神经训练
- 开始推理
问题引入
对于某同学平时花费x小时,期末得到的分数y的图表:
| x(小时) | y(分) |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | ? |
求问在平时花费4小时的情况下,最终的成绩为?
数据集与测试集
详细见:链接
数据集拿到后一般划分为两部分,训练集和测试集,然后使用训练集的数据来训练模型,用测试集上的误差作为最终模型在应对现实场景中的泛化误差。
我们可以使用训练集的数据来训练模型,然后用测试集上的误差作为最终模型在应对现实场景中的泛化误差。有了测试集,我们想要验证模型的最终效果,只需将训练好的模型在测试集上计算误差,即可认为此误差即为泛化误差的近似,我们只需让我们训练好的模型在测试集上的误差最小即可。
过拟合与泛化
下面拿小猫图像识别做例子,说明一下过拟合和泛化的概念;
过拟合: 在训练集上匹配度很好,但是太过了,把噪声什么的也学进来了。
泛化能力: 对于没见过的图像也能进行识别,这是我们所需要的。
开发集
有时候无法看到测试集,我们又人为地把数据集划分一部分出来作为验证评估,称为“开发集”。
监督学习和非监督学习
有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
问题分析
数据集需要交付给算法模型进行训练,利用所训练的模型,在获得新的数据时可以获得相应的输出。(监督学习)
训练集、验证集、测试集
按照上面的介绍很简单就可以得出1和2当作训练集,3当作验证集,4当作测试集。
模型设计
线性模型的基本模型 y ^ = ω x + b \widehat y=\omega x+b y =ωx+b,其中的 ω \omega ω和 b b b是模型中的参数,训练模型的过程即为确定模型中参数的过程
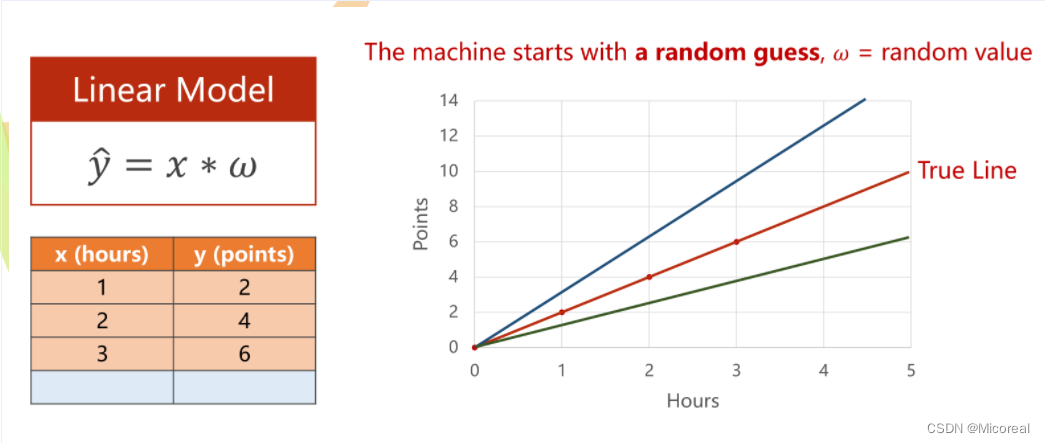
在本模型中设置成 y ^ = ω x \widehat y=\omega x y =ωx,对于不同的 ω \omega ω有不同的线性模型及图像与之对应。
模拟训练过程
在模型训练中会先随机取得一个值,继而计算其和标准量之间的偏移量,从而判断当前模型是否符合预期。
记实际值为
y
(
x
)
y(x)
y(x),模型对应的预测值为
y
^
(
x
)
\widehat y(x)
y
(x),则其中的偏移量为
∣
y
^
(
x
)
−
y
(
x
)
∣
\left|\widehat y(x)-y(x)\right|
∣y
(x)−y(x)∣,以此来代表模型估计值对原值的误差。
通常,该公式定义为Training Loss (Error)
l
o
s
s
=
(
y
^
−
y
)
2
=
(
ω
x
−
y
)
2
loss = (\widehat y - y)^2 = (\omega x - y)^2
loss=(y
−y)2=(ωx−y)2
原题目中的几种
ω
\omega
ω所对应的Loss如下
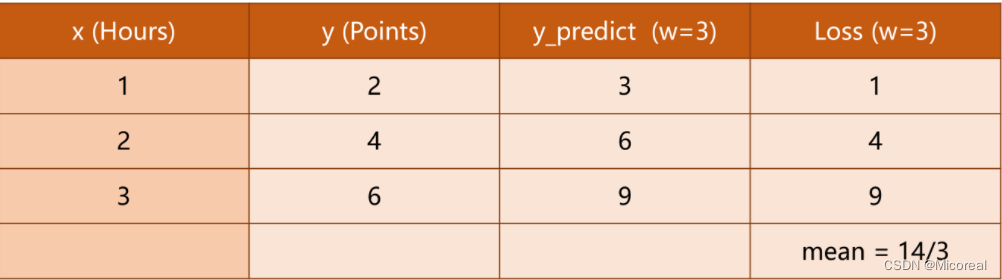
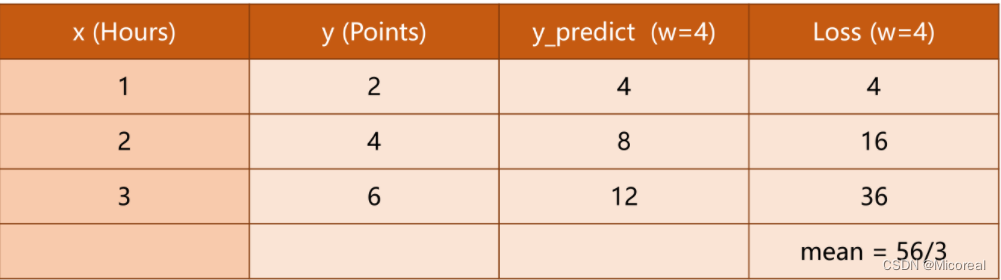
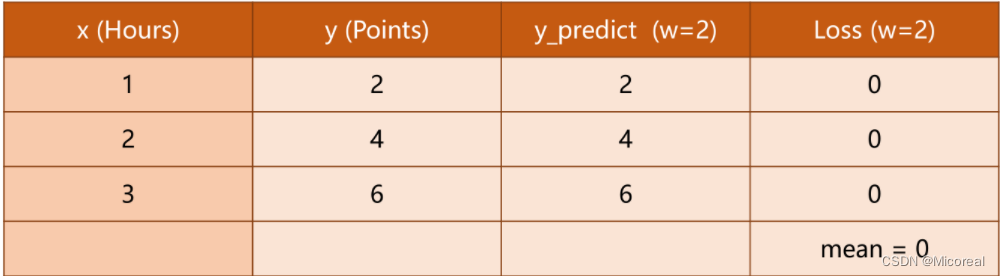
其中的每行为
w
w
w不同时的单个样本的损失,最后一行为平均损失。
对于单个样本,有loss可用于指代样本误差。对于所有样本,可同理用(MSE)来指代整体样本的平均平方误差(均方差cost)
c
o
s
t
=
1
N
∑
n
=
1
N
(
y
^
n
−
y
n
)
2
cost = \frac{1}{N} \displaystyle\sum_{n=1}^{N}(\widehat y_n-y_n)^2
cost=N1n=1∑N(y
n−yn)2
由cost的计算公式可知,当平均损失为0时,模型最佳,但由于仅当数据无噪声且模型完美贴合数据的情况下才会出现这种情况,因此模型训练的目的应当是尽可能小,而非找到误差为0的情况。
课程代码
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
#前馈计算
def forward(x):
return x * w
#求loss
def loss(x, y):
y_pred = forward(x)
return (y_pred-y)*(y_pred-y)
w_list = []
mse_list = []
#从0.0一直到4.1以0.1为间隔进行w的取样
for w in np.arange(0.0,4.1,0.1):
print("w=", w)
l_sum = 0
for x_val,y_val in zip(x_data,y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val,y_val)
l_sum += loss_val
print('\t',x_val,y_val,y_pred_val,loss_val)
print("MSE=",l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
#绘图
plt.plot(w_list,mse_list)
plt.ylabel("Loss")
plt.xlabel('w')
plt.show()
输出结果:
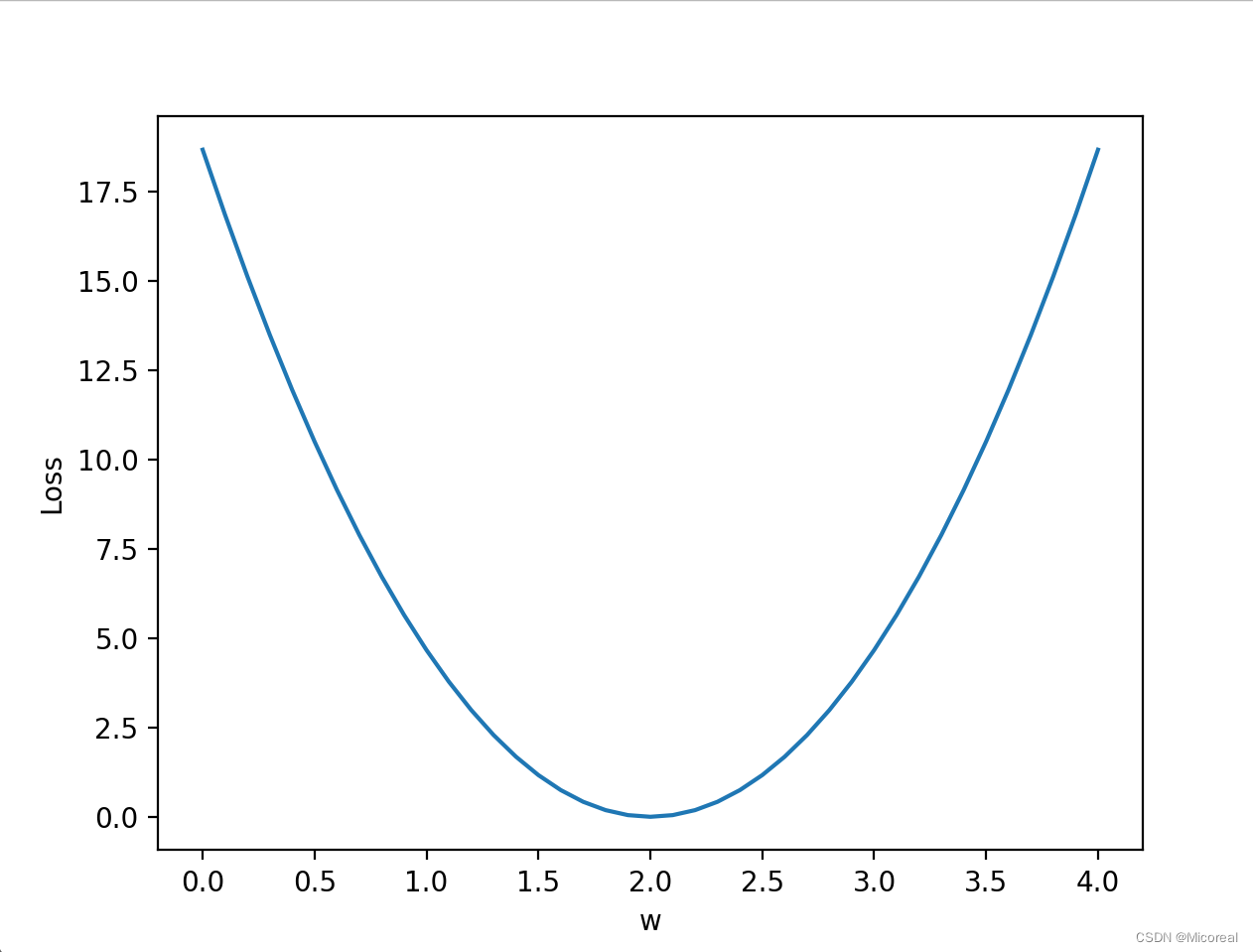
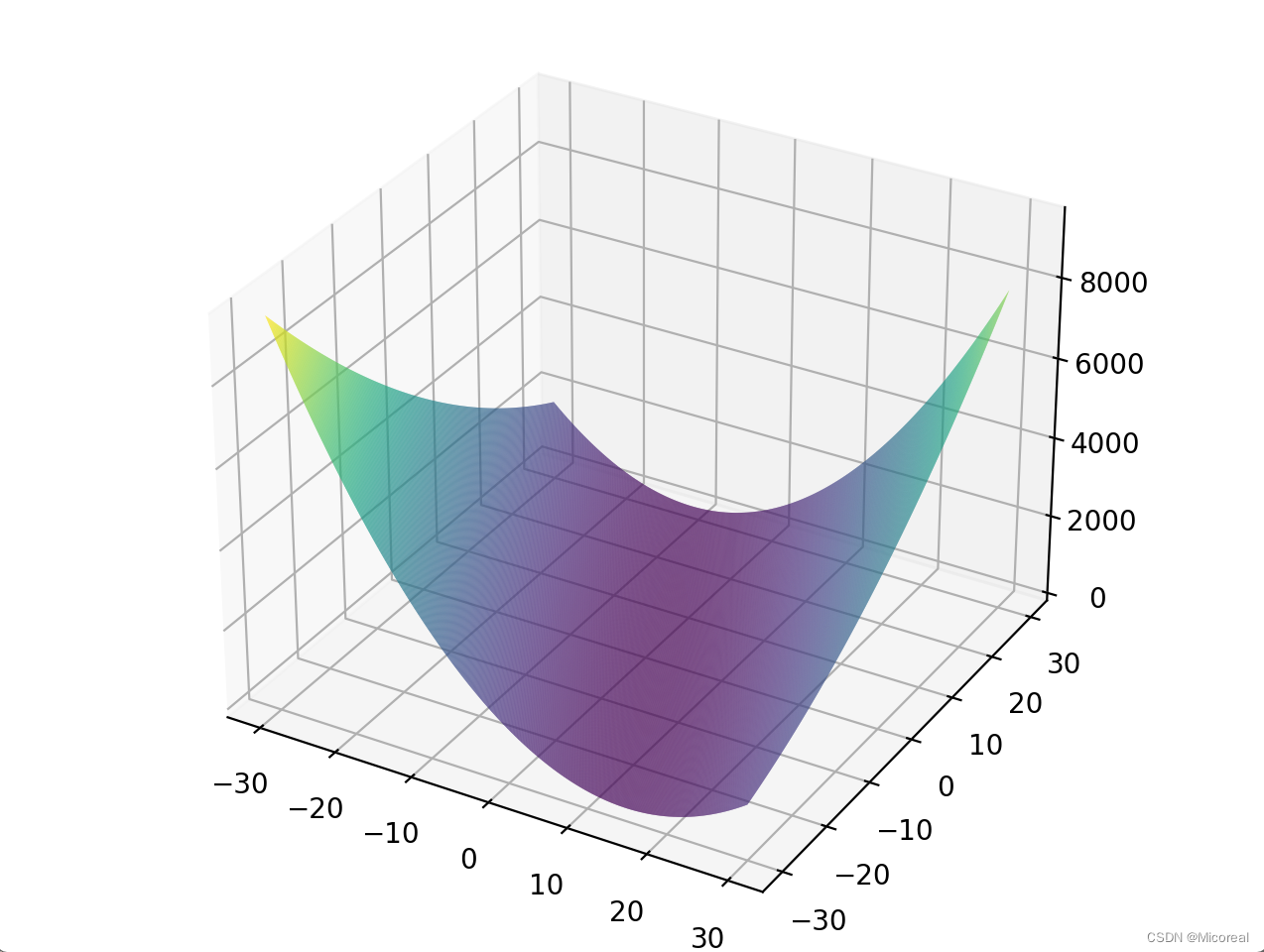
课后习题代码
前提知识:3d绘图链接
import numpy as np
import matplotlib.pyplot as plt;
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
#线性模型
def forward(x,w,b):
return x * w+ b
#损失函数
def loss(x, y,w,b):
y_pred = forward(x,w,b)
return (y_pred - y) * (y_pred - y)
def mse(w,b):
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val,w,b)
loss_val = loss(x_val, y_val,w,b)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum / 3)
return l_sum/3
#迭代取值,计算每个w取值下的x,y,y_pred,loss_val
mse_list = []
##画图
##定义网格化数据
b_list=np.arange(-30,30,0.1)
w_list=np.arange(-30,30,0.1);
##生成网格化数据
xx, yy = np.meshgrid(b_list, w_list,sparse=False, indexing='xy')
##每个点的对应高度
zz=mse(xx,yy)
fig = plt.figure()
ax = Axes3D(fig)
x = np.arange(-4, 4, 0.25)
y = np.arange(-4, 4, 0.25)
x, y = np.meshgrid(x, y)
r = np.sqrt(x**2 + y**2)
z = np
ax.plot_surface(xx, yy, zz, rstride=1, cstride=1, cmap=cm.viridis)
plt.show()
输出结果: