多目标融合
权重分类目人群。
trick
normlize
- 不同Score之间含义、量级和分布差异较大:评分计算的不同部分的意义、范围和分布存在显著差异,这使得直接比较或融合它们的结果变得困难。
- 显式反馈(如点赞率)存在用户间差异:不同用户的显式反馈(如点赞率)有很大差异,很难用统一的权重来处理它们。这意味着一种通用的方法可能无法对所有用户都有效。
- 依赖于模型预估值的绝对大小:当前方法依赖于预测值的绝对大小,当预测值的分布发生改变时,可能需要重新进行调整或校准。
多目标分数normalize
off-policy
1.手工融合,网格搜索和随机搜索是常采用的方法。
网格搜索(Grid Search)网格搜索是一种遍历所有超参数组合的方法,通常用于小规模的超参数空间。
随机搜索(Random Search)随机搜索则是在超参数空间内进行随机采样,这对于大规模超参数空间较为有效。
2.树模型拟合。
树模型规则Ensemble融合
● 使用GBDT模型,引入pXtr、画像和统计类特征,拟合组合label:
● 采用加权Logloss:
● 上下滑无负样本,通过拷贝正样本实现对目标无偏估计;
● 等价于将叶子结点转换为打分规则,得到打分的Ensemble,也叫RuleFit。
● 该方法的缺点是树模型表达能力有限,且无法online learning。
3.超参ltr
首先,介绍一个简单的双塔形式的DNN,如上图右侧网络结构所示,视频塔直接把各种个性化预估值拼在一起,形成一个24维向量;用户塔的顶层向量通过网络学习,产出一个24维向量。最后,对视频塔和用户塔产出的向量做内积,损失函数采用加权Logloss:
由此,相当于通过学习线性加权的超参数去拟合最终的组合收益。其次,用户特征选用了一种比较轻量级的方式,比如对用户划分不同的时间窗口:过去1分钟、5分钟、15分钟、…、2小时,每个时间窗内,对推荐给他的视频,根据用户的反馈拼接成一个向量,这些反馈包括有效播放、点赞、关注、分享、下载、观看时长等,最后,将各时间窗口对应的反馈向量和ID类特征一起输入到用户侧网络。
4.端到端ltr
上述双塔形式的DNN及其轻量级的特征表达,依然限制了模型的表达能力。继而,考虑端到端学习,主要尝试了Pointwise和Pairwise两种形式。
1.对于Pointwise形式,把user_id、行为序列等都作为原始输入特征,同时,融入pXtr特征,使用精排模型来学习最终的组合收益。因为这种方式支持更复杂的特征抽取和网络结构,如attention结构,所以模型的表达能力更强。
5.对于Pairwise形式,在一次用户请求返回的6个视频之间,对每种目标都如下操作:先通过该目标的正样本和负样本构造偏序对,再使用DNN网络学习偏序对的打分,对打分做sigmoid变换,最后通过交叉熵损失产出loss。下述公式表示的是like目标:
● 优点 离线方法是off-policy的方法,数据利用率高(100%样本都可以被使用),且模型的自由度和复杂度较高,可以容纳item embedding并使用稀疏特征,可以训练千亿规模的参数。
● 缺点 优化的离线AUC无法直接反映业务指标。因为这个过程做了很多简化,推荐系统不是精排之后就直接对接用户了,中间还有重排(比如多样性)等的影响,甚至还有一些商业化/运营流量的混排融合,所以该方法难以考虑到线上复杂多模块间的完整影响。此外,线下训练数据和线上数据也存在分布不一致的问题。
6.进化策略(Evolutionary Strategy)
爱奇艺采用的PSO进化优化算法
粒子群算法Particle Swarm Optimization详解
Evolution Strategies
7.强化学习(Reinforcement Learning)
利用强化学习算法,如 Q-learning 或深度强化学习,来搜索超参数空间。
on-policy
在线超参数学习算法基于探索与利用机制
探索:会在baseline附近探索生成N组参数,传给推荐系统后获得这N组参数对应的展现给用户的差异化排序结果,从而获得不同用户的反馈。
收集这些反馈日志并做收益(reward)统计,衡量在每组参数下,时长和互动指标相比基线的涨跌幅度。比如,观看时长涨了3%,而点赞跌了5%。此外,这里区分了收益项和约束项:
- 收益项是主要优化目标,比如视频观看时长、个人页停留时长、评论区的时长等。
- 约束项包括各种互动,比如播放、点赞、关注等。约束项使用非线性约束:阈值内做线性的弱衰减,可以用一些约束轻微的去兑换时长;超出阈值的做指数强衰减,避免约束项过分被损害。
最终送给BayesOpt/ES/CEM等调参算法产生下一组更好的参数。经过不停迭代,参数就会向一个多目标协调最优的方向前进。
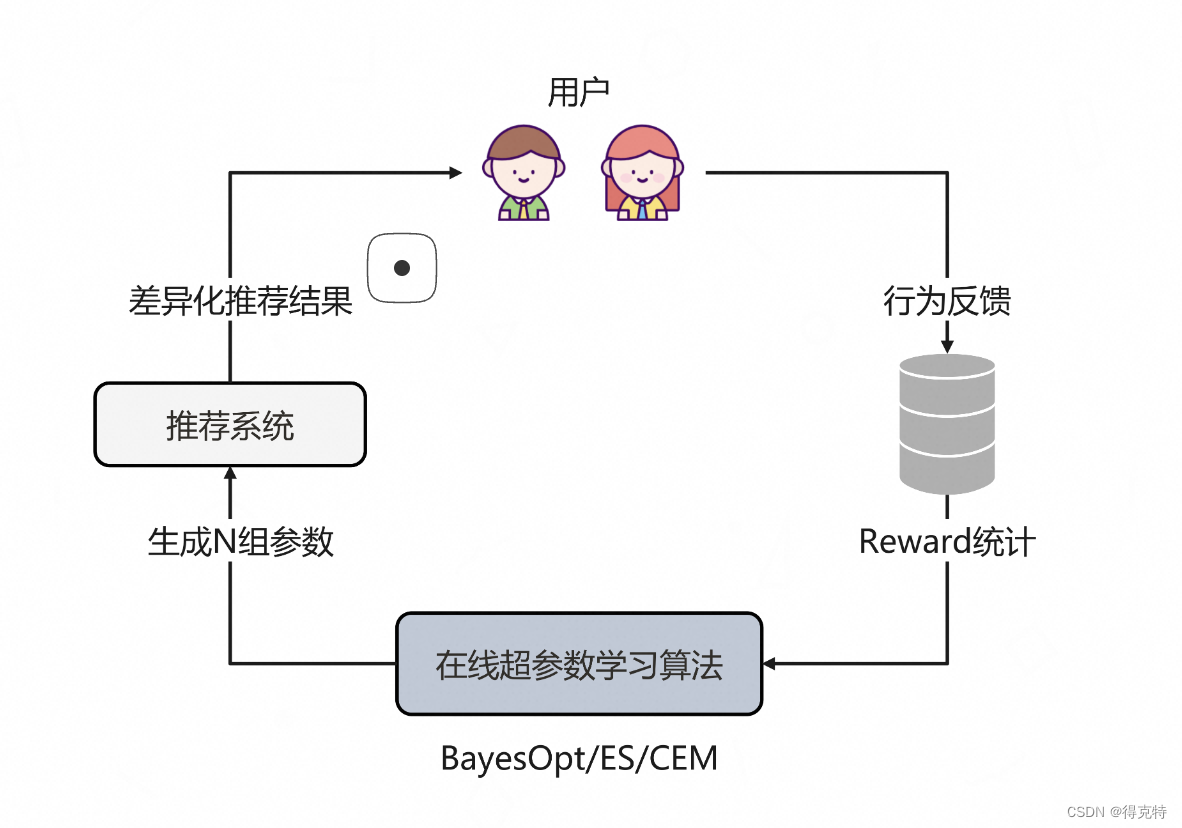
在线的超参数学习方法具有以下优缺点:
● 优点 直接优化线上指标,灵活性高且反馈迅速,并且可以把推荐系统当做一个黑盒,无需关心内部细节。且可以做多场景联合优化,不限于ranking,在召回等场景也可以用。
● 缺点 需要在线上划分出一部分探索流量(大约5%),从而影响少部分用户体验,且由于数据稀疏,受噪声影响较大,尤其是一些稀疏的动作标签,比如分享、下载、收藏等;能容纳的参数量较小,一般几十到数百,相对离线学习的参数规模小很多。
1.CEM(Cross-Entropy Method)
CEM是一种基于采样和统计的全局优化算法,通过迭代优化一个概率分布,从而找到目标函数的最优解。其基本步骤如下:
初始化分布:选择一个初始的概率分布,例如高斯分布,随机设置一个
n
n
n维均值向量
μ
\mu
μ, n维方差向量
θ
2
\theta^2
θ2。分别对应于
W
W
W的每一维。
采样候选解:从该分布中采样一批候选解,计算reward。
选择topk样本:根据目标函数值选择表现最好的前
k
k
k的样本。
更新分布参数:使用topk样本来更新概率分布的参数,并对方差做微小扰动(防止过早陷入局部最优),得到新的高斯分布。
μ
i
′
=
1
M
∑
s
∈
S
θ
i
(
s
)
σ
i
′
2
=
1
M
∑
s
∈
S
(
θ
i
(
s
)
−
μ
i
′
)
2
\mu_{i}' = \frac{1}{M} \sum_{s \in S} \theta_{i}^{(s)} \\ \sigma_{i}'^2 = \frac{1}{M} \sum_{s \in S} \left( \theta_{i}^{(s)} - \mu_{i}' \right)^2
μi′=M1∑s∈Sθi(s)σi′2=M1∑s∈S(θi(s)−μi′)2
重复迭代:重复以上步骤,直到收敛或达到预定的迭代数。
该算法的优点是简洁、高效,超参很少;
0阶方法,TopK选取只依赖Reward的序,不需要对Reward的数值大小进行建模,对噪声更近鲁棒;
参数通过高斯分布扰动探索,偏离基线越多的参数选中的概率越小,线上指标相对平稳。
2.贝叶斯优化算法
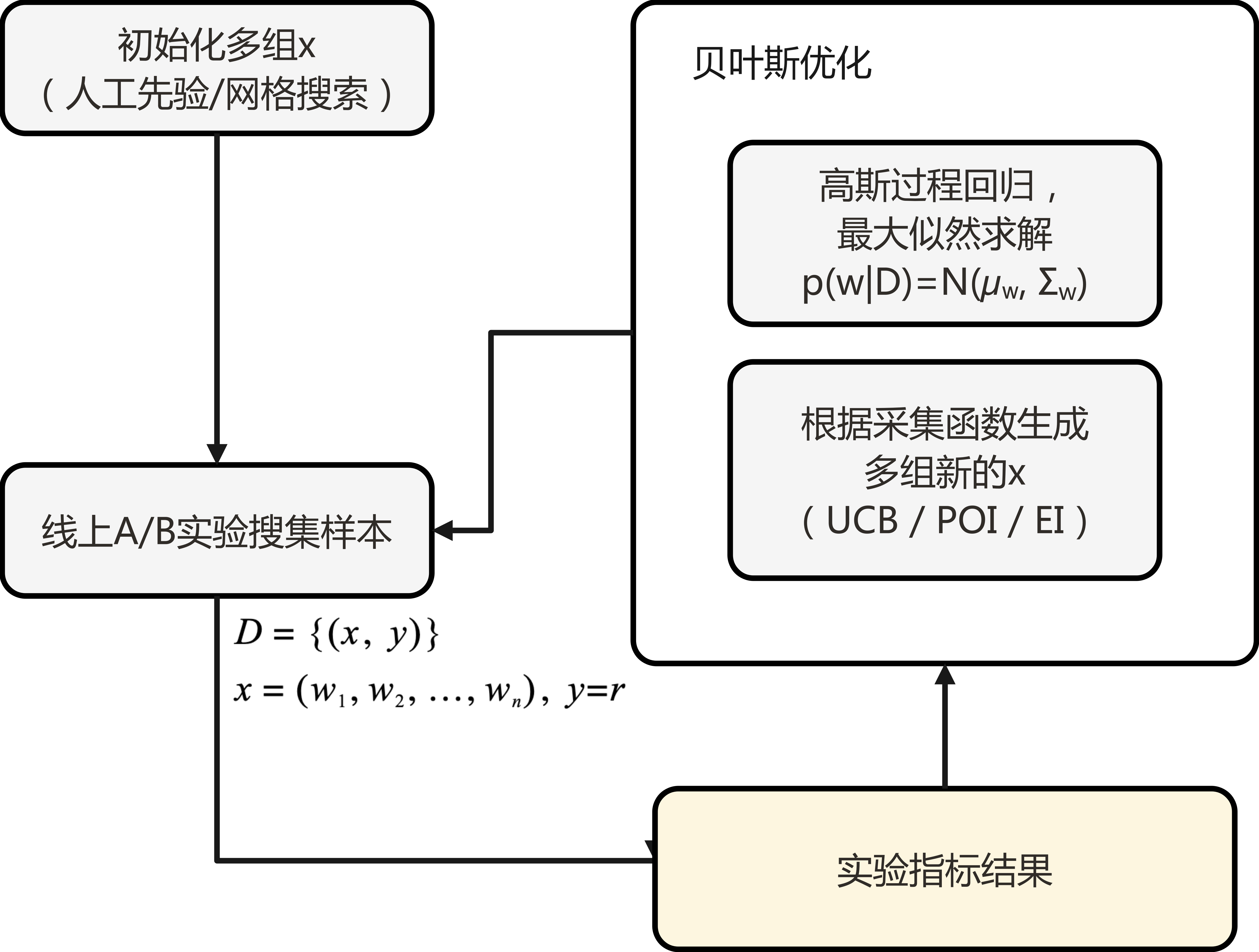
贝叶斯优化的基本思想在于由于真实优化函数计算量太大或是个黑盒(比如推荐场景中用户的真实反馈收益),我们需要用一个代理函数(surrogate function) 来近似它。而在代理函数周围可能是最小值点的附近,或者是在还没有采样过的区域采样新的点之后,我们就可以更新代理函数,使之不断逼近目标函数。我们常采用高斯过程(Gaussian process, GP) 来建模概率代理函数的分布,然后再设计一个采集函数(acquisition function),基于高斯过程回归的结果来计算下一组可能更优的采样点(使采集函数最大化)。
注意:这里之所以使采集函数最大化,而不是直接使代理函数最大化,因为直接优化代理函数过于目光短浅了,因为我们还要考虑不确定性。事实上,这也是一种探索(exploration)机制的体现。贝叶斯优化与网格搜索的不同之处在于,它在尝试新的超参数组合时会考虑之前的评估结果(即利用了证据,即evidence的信息来估计代理函数的后验分布),并基于代理函数来求解采集函数的极值,从而确定下一个采样点。
贝叶斯优化包含两个关键组成部分:
- 概率代理模型 用于对代理函数的分布进行建模,在迭代开始前初始化为一个指定的先验分布。常用的概率代理模型有:高斯过程(GP)、树形Parzen估计器(tree-structured parzen estimator, TPE)、神经网络、决策树等。
- 采集函数 采集函数用于衡量每一个点值得探索的程度。每轮迭代算法会基于现有的高斯过程,从候选集中选择下一步的迭代点以使得采集函数最大化。贝叶斯优化效果受采集函数的影响较大,选择不合适的话容易陷入局部最优解。采集函数的选取可以看做一个探索-利用问题,常用采集函数包括置信区间上界(Upper Confidence Bound, UCB)方法、POI方法、EI方法等(其中最为简单易用的是UCB方法)。
首先,算法会初始化一个代理函数的先验分布,然后开始迭代。算法的第t步迭代的伪代码描述如下:
- 通过优化采集函数 u u u以获得 x t + 1 = a r g m a x x u ( x ∣ D t ) x^{t+1}=argmax_x u(x|D^t) xt+1=argmaxxu(x∣Dt)
- 通过用户的在线反馈收益 r r r(对应贝叶斯优化中的目标函数)得到 y t + 1 y^{t+1} yt+1
- 对数据进行增广 D t + 1 = { D t , ( x t + 1 , y t + 1 ) } D^{t+1}=\{D^t, (x^{t+1},y^{t+1})\} Dt+1={Dt,(xt+1,yt+1)}
- 更新概率代理模型(如高斯过程回归),得到一个代理函数的后验分布(做为下一步迭代的先验分布)。
算法流程示意图如下:
3.进化策略(ES)算法
占位。
多目标排序在快手短视频推荐中的实践
推荐系统:精排多目标融合与超参数学习方法
Reinforcing User Retention in a Billion Scale Short Video Recommender System
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
如何评价快手的RLUR模型?