前言
之前发布的博客LangGraph开发Agent智能体应用【NL2SQL】-CSDN博客,留了一个问题,对于相对复杂的sql(leetcode中等难度的sql题),gpt4o就力不从心了。这篇文章来讲一下优化
什么是few-shot
使用这些少量的、调整后的样本对预训练模型进行微调
其实就是给LLM少量示例
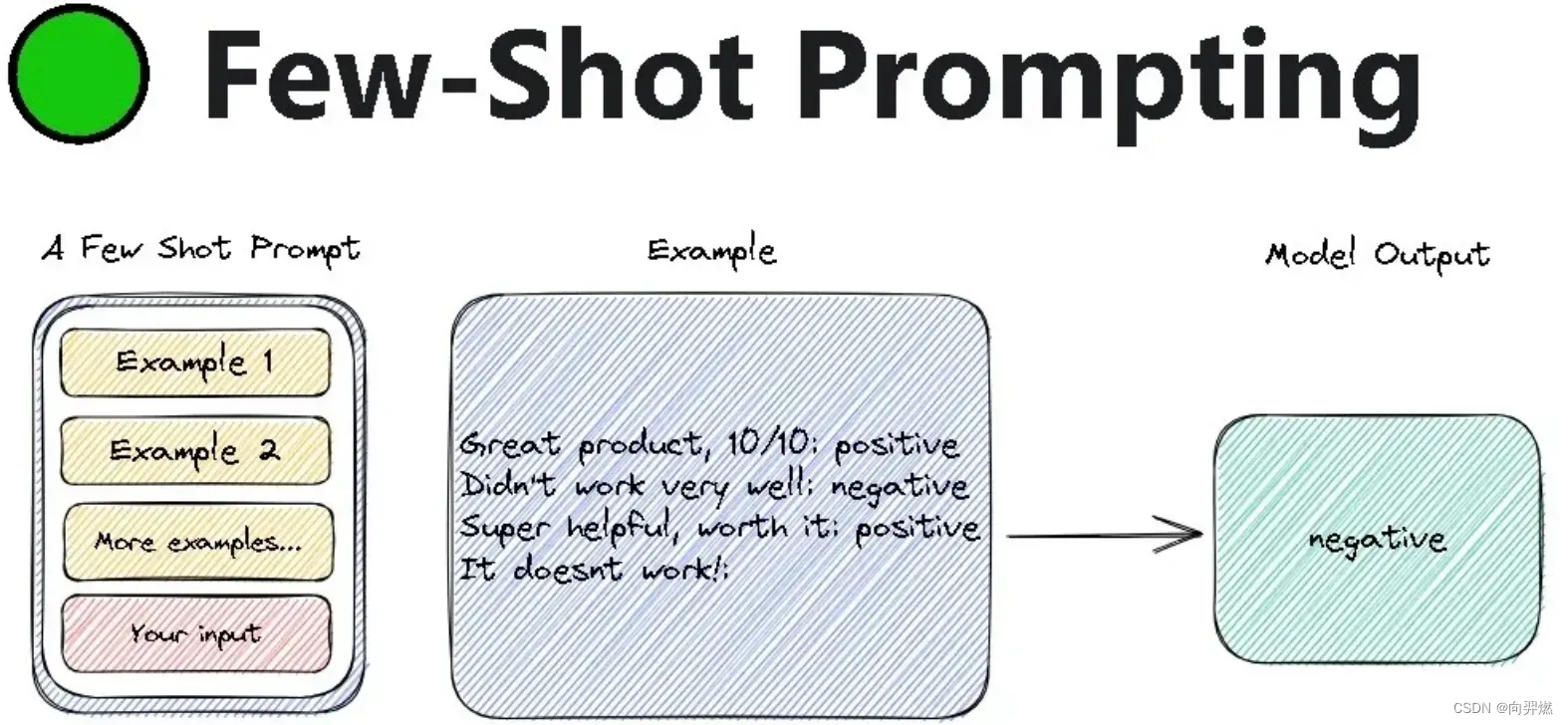
关于few-shot的研究:
https://medium.com/ubiai-nlp/step-by-step-guide-to-mastering-few-shot-learning-a673054167a0
实现few-shot的方式
1.prompt:最简单的当然是在prompt上写几个例子,作为上下文,当LLM被问到类似的问题的时候,就会参照你的上下文中的例子。
2.RAG:如果你觉得上下文的token数量有限,不可能吧所有例子写在prompt中,可以通过RAG的形式,把各种场景的sql案例做成Wiki文档,通过嵌入模型转换成向量表示,存储在向量数据库中,用户提问的时候通过向量召回策略找到相应的知识作为上下文,同样也可以实现优化。
我们一般在测试环境用prompt优化,在生产环境用prompt+RAG的方式
如果在测试中,确认了prompt能实现优化,那在生成环境中只是对应的加了一层向量化召回操作而已,所以本文也只讲prompt优化的操作案例
PS:使用LangChain实现RAG,这篇文章中有完整代码:LangChain开发LLM应用【入门指南】_langchain 开发社区-CSDN博客
代码:用prompt实现few-shot优化
PS:下文代码,是对LangGraph开发Agent智能体应用【NL2SQL】-CSDN博客的改进优化,可能存在重复内容。
第一步:定义工具集合
LangChain 和 LangGraph是打通的(准确的说,LangGraph是LangChain生态的高级框架)
所以我们可以直接使用LangChain的工具集 SQLDatabaseToolkit
如果你愿意深入看看源码,就知道这个工具集里有四个工具:
执行sql:QuerySQLDataBaseTool
查看表详情:InfoSQLDatabaseTool
sql语法检查:QuerySQLCheckerTool
查看所有表:ListSQLDatabaseTool
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_openai import ChatOpenAI
from sqlalchemy import create_engine
from langchain_community.utilities import SQLDatabase
# 数据库连接信息
username = 'root'
password = 'MyNewPass1!'
host = 'desk04v.mlprod.bjpdc.qihoo.net'
port = '3306'
database = 'test'
engine = create_engine(f'mysql+mysqlconnector://{username}:{password}@{host}:{port}/{database}')
db = SQLDatabase(engine)
toolkit = SQLDatabaseToolkit(db=db, llm=ChatOpenAI(temperature=0))
context = toolkit.get_context()
tools = toolkit.get_tools()第二步:定义LLM节点,并加入到图中
让LLM绑定工具,一定要绑定,就像你需要告诉LLM,可以使用哪些工具,LLM才会生成调用计划
prompt优化内容:
1.首先告诉agent它的定位是一个SQL编码助手
2.按照 问题、思路、答案 给他相应提示(我试了很多方式,这种方式效果最好,问题部分要包含表的DDL最佳)
3.告诉agent,你希望的输出形式
格式如下:(当然还有优化空间,期待你自己尝试更丰富的提示语)
"system",
"""你是一名精通 SQL 的编码助理。\n
这是参考文档: \n ------- \n
# 如何找到各部门最高工资的员工
## 问题:
{...}
## 思路:
{...}
## 答案:
{...}
\n ------- \n
根据以上提供的文档,作为参考生成sql查询数据以回复用户的问题 \n
用中文回复,并且最后以表格形式输出。\n
以下是用户问题:""",代码如下:
from typing import Annotated
from langchain_openai import ChatOpenAI
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages,AnyMessage
from langchain_core.runnables import Runnable, RunnableConfig
from langchain_core.prompts import ChatPromptTemplate
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
graph_builder = StateGraph(State)
# expt_llm = "gpt-4-1106-preview"
expt_llm = "gpt-4o"
llm = ChatOpenAI(temperature=0, model=expt_llm)
class Assistant:
def __init__(self, runnable: Runnable):
self.runnable = runnable
def __call__(self, state: State, config: RunnableConfig):
while True:
passenger_id = config.get("passenger_id", None)
state = {**state, "user_info": passenger_id}
result = self.runnable.invoke(state)
# If the LLM happens to return an empty response, we will re-prompt it
# for an actual response.
if not result.tool_calls and (
not result.content
or isinstance(result.content, list)
and not result.content[0].get("text")
):
messages = state["messages"] + [("user", "Respond with a real output.")]
state = {**state, "messages": messages}
else:
break
return {"messages": result}
# Grader prompt
code_gen_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""你是一名精通 SQL 的编码助理。\n
这是参考文档: \n ------- \n
# 如何找到各部门最高工资的员工
## 问题:查找出每个部门中薪资最高的员工
表: Employee
CREATE TABLE Employee (
id INT PRIMARY KEY,
name VARCHAR(255),
salary INT,
departmentId INT
);
表: Department
CREATE TABLE Department (
id INT PRIMARY KEY,
name VARCHAR(255)
);
## 思路:
2. 对工资按部门行分组,并找到每个部门最大的工资。
3. 从工资中筛选出每个部门最大的工资的员工信息。
## 答案:
SELECT
Department.name AS 'Department',
Employee.name AS '
Employee',
Salary
FROM
Employee
JOIN
Department ON Employee.DepartmentId = Department.Id
WHERE
(Employee.DepartmentId , Salary) IN
( SELECT
DepartmentId, MAX(Salary)
FROM
Employee
GROUP BY DepartmentId
)
;
\n ------- \n
根据以上提供的文档,作为参考生成sql查询数据以回复用户的问题 \n
用中文回复,并且最后以表格形式输出。\n
以下是用户问题:""",
),
("placeholder", "{messages}"),
]
)
assistant_runnable = code_gen_prompt | llm.bind_tools(tools)
graph_builder.add_node("assistant", Assistant(assistant_runnable))第三步:定义工具节点,并加入到图中
import json
from langchain_core.messages import ToolMessage
class BasicToolNode:
"""运行最后一个AIMessage中请求的工具"""
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
tool_node = BasicToolNode(tools=tools)
graph_builder.add_node("tools", tool_node)第四步:定义“边”
add_edge方法是直接定义“边”,在例子中表示tools -> assistant
add_conditional_edges方法是增加条件路由“边”,在例子中表示assistant根据情况 -> tools 或者 -> __end__
from typing import Literal
def route_tools(
state: State,
) -> Literal["tools", "__end__"]:
"""如果最后一条消息,在conditional_edge中使用路由到ToolNode,就调用工具。否则,路线到终点。"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"在tool_edge的输入状态中没有找到消息: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return "__end__"
# The `tools_condition` function returns "tools" if the chatbot asks to use a tool, and "__end__" if
# it is fine directly responding. This conditional routing defines the main agent loop.
graph_builder.add_conditional_edges(
"assistant",
route_tools,
# The following dictionary lets you tell the graph to interpret the condition's outputs as a specific node
# It defaults to the identity function, but if you
# want to use a node named something else apart from "tools",
# You can update the value of the dictionary to something else
# e.g., "tools": "my_tools"
{"tools": "tools", "__end__": "__end__"},
)
# Any time a tool is called, we return to the chatbot to decide the next step
graph_builder.add_edge("tools", "assistant")
graph_builder.set_entry_point("assistant")
graph = graph_builder.compile()第五步:把图画出来(非必需)
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except:
# This requires some extra dependencies and is optional
pass效果如下:
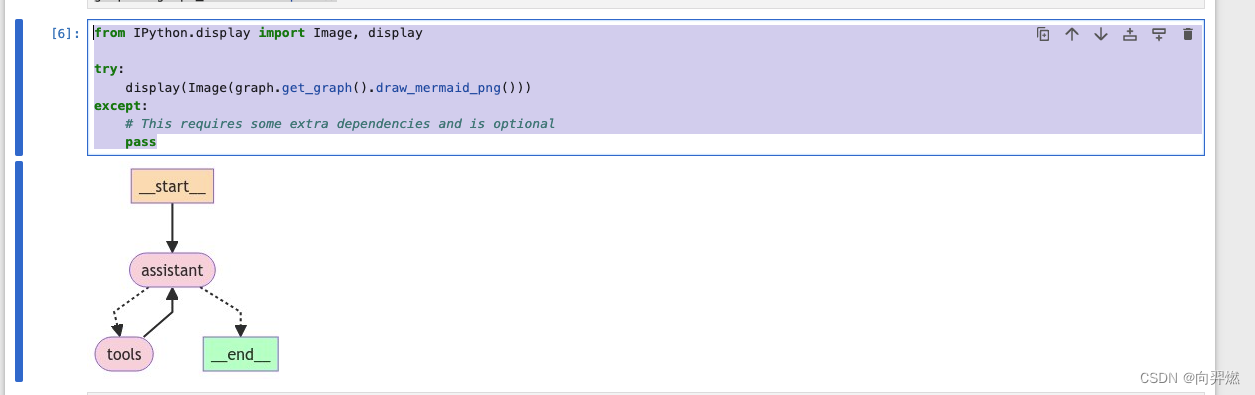
整个流程很简单,用大白话讲,就是:
把提问信息传给LLM,LLM决定用什么工具,然后graph就调用工具返回结果传给LLM,LLM拿到结果后有可能继续调用工具,也有可能直接输出答案,如此循环或者终止。
第六步:执行
这次不用流式执行了,直接执行看看效果
question = "找到5月的各地区的运费最贵的用户"
result = graph.invoke({"messages": [("user", question)], "iterations": 0})
for massage in result['messages']:
print('-------------'+massage.type+'-------------')
print(str(massage).replace('\\n', '\n'))效果如下:
-------------human-------------
content='找到5月的各地区的运费最贵的用户' id='709625d7-9f3a-43ae-b790-e5ed3b013e81'
-------------ai-------------
content='要查找5月份各地区运费最贵的用户,我们需要先了解数据库中涉及到的表结构。具体需求中涉及到的表可能包括用户表、订单表、运费表等。
首先,我们需要确认数据库中有哪些表存在。然后,我们获取各表的结构和一些示例数据来确定数据关系。
### 第一步:列出数据库中的所有表
我将查询数据库中的所有表名称,然后我们可以根据表名确定下一步的操作。' additional_kwargs={'tool_calls': [{'id': 'call_b0eREszlI46eZE5mNTHC97t8', 'function': {'arguments': '{}', 'name': 'sql_db_list_tables'}, 'type': 'function'}]} response_metadata={'token_usage': {'completion_tokens': 116, 'prompt_tokens': 613, 'total_tokens': 729}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run-7f039c24-24a5-47d1-b672-8c08e37704a3-0' tool_calls=[{'name': 'sql_db_list_tables', 'args': {}, 'id': 'call_b0eREszlI46eZE5mNTHC97t8'}] usage_metadata={'input_tokens': 613, 'output_tokens': 116, 'total_tokens': 729}
-------------tool-------------
content='"arbitraments, courses, orders, scores, sink_chunjun_1, source_chunjun_1, students, test_binlog_1"' name='sql_db_list_tables' id='05781c74-d440-4247-8c4a-e6de0f59f816' tool_call_id='call_b0eREszlI46eZE5mNTHC97t8'
-------------ai-------------
content='已获取到的表名如下:
- arbitraments
- courses
- orders
- scores
- sink_chunjun_1
- source_chunjun_1
- students
- test_binlog_1
根据需求,可能的相关表为 `orders`。接下来我们获取 `orders` 表的结构和一些示例数据。' additional_kwargs={'tool_calls': [{'id': 'call_7EzpUDEZukFGcsmkkgLv2MGY', 'function': {'arguments': '{"table_names":"orders"}', 'name': 'sql_db_schema'}, 'type': 'function'}]} response_metadata={'token_usage': {'completion_tokens': 93, 'prompt_tokens': 776, 'total_tokens': 869}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run-af1f799a-6302-40ea-9fdf-dccf862d25af-0' tool_calls=[{'name': 'sql_db_schema', 'args': {'table_names': 'orders'}, 'id': 'call_7EzpUDEZukFGcsmkkgLv2MGY'}] usage_metadata={'input_tokens': 776, 'output_tokens': 93, 'total_tokens': 869}
-------------tool-------------
content='"\
CREATE TABLE orders (\
\\torder_id INTEGER NOT NULL COMMENT \'\\u8ba2\\u5355ID\', \
\\tcustomer_id VARCHAR(255) COMMENT \'\\u5ba2\\u6237ID\', \
\\temployee_id INTEGER COMMENT \'\\u5458\\u5de5ID\', \
\\torder_date DATE COMMENT \'\\u8ba2\\u5355\\u65e5\\u671f\', \
\\trequired_date DATE COMMENT \'\\u8981\\u6c42\\u4ea4\\u8d27\\u65e5\\u671f\', \
\\tshipped_date DATE COMMENT \'\\u53d1\\u8d27\\u65e5\\u671f\', \
\\tshipper_id INTEGER COMMENT \'\\u53d1\\u8d27\\u65b9\\u5f0f\', \
\\tfreight DECIMAL(10, 2) COMMENT \'\\u8fd0\\u8d39\', \
\\tship_name VARCHAR(255) COMMENT \'\\u6536\\u8d27\\u4eba\\u540d\\u79f0\', \
\\tship_address VARCHAR(255) COMMENT \'\\u6536\\u8d27\\u5730\\u5740\', \
\\tship_city VARCHAR(255) COMMENT \'\\u6536\\u8d27\\u57ce\\u5e02\', \
\\tship_region VARCHAR(255) COMMENT \'\\u6536\\u8d27\\u5730\\u533a\', \
\\tship_postal_code VARCHAR(255) COMMENT \'\\u6536\\u8d27\\u90ae\\u7f16\', \
\\torder_status VARCHAR(50) COMMENT \'\\u8ba2\\u5355\\u72b6\\u6001\', \
\\tsnapshot_timestamp TIMESTAMP NULL COMMENT \'\\u5feb\\u7167\\u65f6\\u95f4\\u6233\' DEFAULT CURRENT_TIMESTAMP, \
\\tPRIMARY KEY (order_id)\
)ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci DEFAULT CHARSET=utf8mb4\
\
/*\
3 rows from orders table:\
order_id\\tcustomer_id\\temployee_id\\torder_date\\trequired_date\\tshipped_date\\tshipper_id\\tfreight\\tship_name\\tship_address\\tship_city\\tship_region\\tship_postal_code\\torder_status\\tsnapshot_timestamp\
1\\tCUST001\\t1\\t2024-05-01\\t2024-05-05\\t2024-05-03\\t1\\t100.50\\t\\u5f20\\u4e09\\t\\u5317\\u4eac\\u5e02\\u671d\\u9633\\u533a\\u5efa\\u56fd\\u8def100\\u53f7\\t\\u5317\\u4eac\\t\\u534e\\u5317\\t100022\\t\\u5df2\\u53d1\\u8d27\\t2024-06-04 17:05:11\
2\\tCUST002\\t2\\t2024-05-02\\t2024-05-06\\t2024-05-04\\t2\\t200.75\\t\\u674e\\u56db\\t\\u4e0a\\u6d77\\u5e02\\u6d66\\u4e1c\\u65b0\\u533a\\u4e16\\u7eaa\\u5927\\u9053200\\u53f7\\t\\u4e0a\\u6d77\\t\\u534e\\u4e1c\\t200120\\t\\u5df2\\u53d1\\u8d27\\t2024-06-04 17:05:11\
3\\tCUST003\\t3\\t2024-05-03\\t2024-05-07\\t2024-05-05\\t3\\t150.00\\t\\u738b\\u4e94\\t\\u5e7f\\u5dde\\u5e02\\u5929\\u6cb3\\u533a\\u4f53\\u80b2\\u897f\\u8def300\\u53f7\\t\\u5e7f\\u5dde\\t\\u534e\\u5357\\t510620\\t\\u5df2\\u53d1\\u8d27\\t2024-06-04 17:05:11\
*/"' name='sql_db_schema' id='fbd1c79c-2d0f-4f0c-a222-f21cb8c74f29' tool_call_id='call_7EzpUDEZukFGcsmkkgLv2MGY'
-------------ai-------------
content="根据获取到的 `orders` 表结构和示例数据,表格的定义如下:
```sql
CREATE TABLE orders (
\torder_id INTEGER NOT NULL COMMENT '订单ID',
\tcustomer_id VARCHAR(255) COMMENT '客户ID',
\temployee_id INTEGER COMMENT '员工ID',
\torder_date DATE COMMENT '订单日期',
\trequired_date DATE COMMENT '要求交货日期',
\tshipped_date DATE COMMENT '发货日期',
\tshipper_id INTEGER COMMENT '发货方式',
\tfreight DECIMAL(10, 2) COMMENT '运费',
\tship_name VARCHAR(255) COMMENT '收货人名称',
\tship_address VARCHAR(255) COMMENT '收货地址',
\tship_city VARCHAR(255) COMMENT '收货城市',
\tship_region VARCHAR(255) COMMENT '收货地区',
\tship_postal_code VARCHAR(255) COMMENT '收货邮编',
\torder_status VARCHAR(50) COMMENT '订单状态',
\tsnapshot_timestamp TIMESTAMP NULL COMMENT '快照时间戳' DEFAULT CURRENT_TIMESTAMP,
\tPRIMARY KEY (order_id)
) ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci DEFAULT CHARSET=utf8mb4;
```
我们可以通过以下SQL查询来找到5月份各地区运费最贵的用户:
```sql
SELECT
ship_region AS '地区',
ship_name AS '收货人',
MAX(freight) AS '运费'
FROM
orders
WHERE
MONTH(order_date) = 5
GROUP BY
ship_region
ORDER BY
MAX(freight) DESC;
```
接下来我会检查该SQL查询的正确性。" additional_kwargs={'tool_calls': [{'id': 'call_lU2ZUOBGYxFgZanTwDR2EyAL', 'function': {'arguments': '{"query":"SELECT\
ship_region AS \'地区\',\
ship_name AS \'收货人\',\
MAX(freight) AS \'运费\'\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
ORDER BY\
MAX(freight) DESC;"}', 'name': 'sql_db_query_checker'}, 'type': 'function'}]} response_metadata={'token_usage': {'completion_tokens': 427, 'prompt_tokens': 1758, 'total_tokens': 2185}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run-5e6c38ed-60dc-4c4f-91c0-b8b044ee13cc-0' tool_calls=[{'name': 'sql_db_query_checker', 'args': {'query': "SELECT
ship_region AS '地区',
ship_name AS '收货人',
MAX(freight) AS '运费'
FROM
orders
WHERE
MONTH(order_date) = 5
GROUP BY
ship_region
ORDER BY
MAX(freight) DESC;"}, 'id': 'call_lU2ZUOBGYxFgZanTwDR2EyAL'}] usage_metadata={'input_tokens': 1758, 'output_tokens': 427, 'total_tokens': 2185}
-------------tool-------------
content='"SELECT\
ship_region AS \'\\u5730\\u533a\',\
ship_name AS \'\\u6536\\u8d27\\u4eba\',\
MAX(freight) AS \'\\u8fd0\\u8d39\'\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
ORDER BY\
MAX(freight) DESC;"' name='sql_db_query_checker' id='295317ff-239d-47c1-8ece-cd9bab4f5e9c' tool_call_id='call_lU2ZUOBGYxFgZanTwDR2EyAL'
-------------ai-------------
content='SQL查询验证通过,查询语句是正确的。接下来执行查询,以获取5月份各地区运费最贵的用户信息。' additional_kwargs={'tool_calls': [{'id': 'call_BfkKHzNS4uJs50tFF44Te4rd', 'function': {'arguments': '{"query":"SELECT\
ship_region AS \'地区\',\
ship_name AS \'收货人\',\
MAX(freight) AS \'运费\'\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
ORDER BY\
MAX(freight) DESC;"}', 'name': 'sql_db_query'}, 'type': 'function'}]} response_metadata={'token_usage': {'completion_tokens': 113, 'prompt_tokens': 2285, 'total_tokens': 2398}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run-ede8e56e-7b4f-407c-a25e-098a04280b9b-0' tool_calls=[{'name': 'sql_db_query', 'args': {'query': "SELECT
ship_region AS '地区',
ship_name AS '收货人',
MAX(freight) AS '运费'
FROM
orders
WHERE
MONTH(order_date) = 5
GROUP BY
ship_region
ORDER BY
MAX(freight) DESC;"}, 'id': 'call_BfkKHzNS4uJs50tFF44Te4rd'}] usage_metadata={'input_tokens': 2285, 'output_tokens': 113, 'total_tokens': 2398}
-------------tool-------------
content='"Error: (mysql.connector.errors.ProgrammingError) 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column \'test.orders.ship_name\' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by\
[SQL: SELECT\
ship_region AS \'\\u5730\\u533a\',\
ship_name AS \'\\u6536\\u8d27\\u4eba\',\
MAX(freight) AS \'\\u8fd0\\u8d39\'\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
ORDER BY\
MAX(freight) DESC;]\
(Background on this error at: https://sqlalche.me/e/20/f405)"' name='sql_db_query' id='e25be985-9bad-465e-8978-cc21cfeb3135' tool_call_id='call_BfkKHzNS4uJs50tFF44Te4rd'
-------------ai-------------
content="查询出现问题,主要是由于在 `GROUP BY` 语句中使用了非聚合的 `ship_name` 列,不符合 `sql_mode=only_full_group_by` 模式的要求。为了解决这个问题,我们需要将查询调整为在获取每个地区最大运费后进行连接,来获取对应的 `ship_name`。
调整后的查询语句如下:
```sql
WITH MaxFreightByRegion AS (
SELECT
ship_region,
MAX(freight) AS max_freight
FROM
orders
WHERE
MONTH(order_date) = 5
GROUP BY
ship_region
)
SELECT
o.ship_region AS '地区',
o.ship_name AS '收货人',
o.freight AS '运费'
FROM
orders o
JOIN
MaxFreightByRegion mfr
ON
o.ship_region = mfr.ship_region AND o.freight = mfr.max_freight;
```
接下来,我会检查该SQL查询的正确性。" additional_kwargs={'tool_calls': [{'id': 'call_laMBSqekT8xY7FRfQk2D1GsR', 'function': {'arguments': '{"query":"WITH MaxFreightByRegion AS (\
SELECT\
ship_region,\
MAX(freight) AS max_freight\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
)\
SELECT\
o.ship_region AS \'地区\',\
o.ship_name AS \'收货人\',\
o.freight AS \'运费\'\
FROM\
orders o\
JOIN\
MaxFreightByRegion mfr\
ON\
o.ship_region = mfr.ship_region AND o.freight = mfr.max_freight;"}', 'name': 'sql_db_query_checker'}, 'type': 'function'}]} response_metadata={'token_usage': {'completion_tokens': 370, 'prompt_tokens': 2587, 'total_tokens': 2957}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run-d0d85b36-472f-4eb2-bb7a-6591f8b68795-0' tool_calls=[{'name': 'sql_db_query_checker', 'args': {'query': "WITH MaxFreightByRegion AS (
SELECT
ship_region,
MAX(freight) AS max_freight
FROM
orders
WHERE
MONTH(order_date) = 5
GROUP BY
ship_region
)
SELECT
o.ship_region AS '地区',
o.ship_name AS '收货人',
o.freight AS '运费'
FROM
orders o
JOIN
MaxFreightByRegion mfr
ON
o.ship_region = mfr.ship_region AND o.freight = mfr.max_freight;"}, 'id': 'call_laMBSqekT8xY7FRfQk2D1GsR'}] usage_metadata={'input_tokens': 2587, 'output_tokens': 370, 'total_tokens': 2957}
-------------tool-------------
content='"WITH MaxFreightByRegion AS (\
SELECT\
ship_region,\
MAX(freight) AS max_freight\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
)\
SELECT\
o.ship_region AS \'\\u5730\\u533a\',\
o.ship_name AS \'\\u6536\\u8d27\\u4eba\',\
o.freight AS \'\\u8fd0\\u8d39\'\
FROM\
orders o\
JOIN\
MaxFreightByRegion mfr\
ON\
o.ship_region = mfr.ship_region AND o.freight = mfr.max_freight;"' name='sql_db_query_checker' id='2c298552-48e0-4797-a1cd-1d51699a29c8' tool_call_id='call_laMBSqekT8xY7FRfQk2D1GsR'
-------------ai-------------
content='查询验证通过。接下来执行查询,以获取5月份各地区运费最贵的用户信息。' additional_kwargs={'tool_calls': [{'id': 'call_rGkKrh5iGkF8A2OPCMjlc1RM', 'function': {'arguments': '{"query":"WITH MaxFreightByRegion AS (\
SELECT\
ship_region,\
MAX(freight) AS max_freight\
FROM\
orders\
WHERE\
MONTH(order_date) = 5\
GROUP BY\
ship_region\
)\
SELECT\
o.ship_region AS \'地区\',\
o.ship_name AS \'收货人\',\
o.freight AS \'运费\'\
FROM\
orders o\
JOIN\
MaxFreightByRegion mfr\
ON\
o.ship_region = mfr.ship_region AND o.freight = mfr.max_freight;"}', 'name': 'sql_db_query'}, 'type': 'function'}]} response_metadata={'token_usage': {'completion_tokens': 168, 'prompt_tokens': 3120, 'total_tokens': 3288}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run-4b1f91af-f458-45b2-97fa-593d143451ba-0' tool_calls=[{'name': 'sql_db_query', 'args': {'query': "WITH MaxFreightByRegion AS (
SELECT
ship_region,
MAX(freight) AS max_freight
FROM
orders
WHERE
MONTH(order_date) = 5
GROUP BY
ship_region
)
SELECT
o.ship_region AS '地区',
o.ship_name AS '收货人',
o.freight AS '运费'
FROM
orders o
JOIN
MaxFreightByRegion mfr
ON
o.ship_region = mfr.ship_region AND o.freight = mfr.max_freight;"}, 'id': 'call_rGkKrh5iGkF8A2OPCMjlc1RM'}] usage_metadata={'input_tokens': 3120, 'output_tokens': 168, 'total_tokens': 3288}
-------------tool-------------
content='"[(\'\\u534e\\u5317\', \'\\u5f20\\u4e09\', Decimal(\'100.50\')), (\'\\u534e\\u4e1c\', \'\\u90d1\\u5341\', Decimal(\'300.80\')), (\'\\u534e\\u5357\', \'\\u738b\\u4e94\', Decimal(\'150.00\')), (\'\\u897f\\u5357\', \'\\u5468\\u516b\', Decimal(\'250.60\')), (\'\\u534e\\u4e2d\', \'\\u738b\\u5341\\u4e00\', Decimal(\'220.30\')), (\'\\u897f\\u5317\', \'\\u5218\\u5341\\u4e8c\', Decimal(\'170.95\'))]"' name='sql_db_query' id='16dbc292-ac35-4de0-9061-b64b6a37897c' tool_call_id='call_rGkKrh5iGkF8A2OPCMjlc1RM'
-------------ai-------------
content='已成功查询到5月份各地区运费最贵的用户信息,具体结果如下:
| 地区 | 收货人 | 运费 |
|-------|--------|----------|
| 华北 | 张三 | 100.50 |
| 华东 | 郑十 | 300.80 |
| 华南 | 王五 | 150.00 |
| 西南 | 周八 | 250.60 |
| 华中 | 王十一 | 220.30 |
| 西北 | 刘十二 | 170.95 |
这些数据展示了每个地区运费最高的用户及具体的运费金额。' response_metadata={'token_usage': {'completion_tokens': 149, 'prompt_tokens': 3456, 'total_tokens': 3605}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-b6f27960-3413-42cb-b5c9-51de7aba7300-0' usage_metadata={'input_tokens': 3456, 'output_tokens': 149, 'total_tokens': 3605}总结
few-shot可以针对复杂的特定场景进行调优
比如:计算留存、计算漏斗、开窗查询等
如果在测试中,确认了prompt能实现优化,那在生成环境中只是对应的加了一层向量化召回操作而已,所以本文也只讲prompt优化的操作案例
参考
🦜🕸️LangGraph - LangGraph
Introduction | 🦜️🔗 LangChain
关于few-shot的研究
https://medium.com/ubiai-nlp/step-by-step-guide-to-mastering-few-shot-learning-a673054167a0相关博客:
LangChain开发LLM应用【入门指南】_langchain 开发社区-CSDN博客
LangGraph开发Agent智能体应用【基础聊天机器人】-CSDN博客
LangGraph开发Agent智能体应用【NL2SQL】-CSDN博客




![[数据集][目标检测]厨房积水检测数据集VOC+YOLO格式88张2类别](https://img-blog.csdnimg.cn/direct/352bef1e5aea4356a625c493955ade0f.png)