前文,我们实现了认识了链表这一结构,并实现了无头单向非循环链表,接下来我们实现另一种常用的链表结构,带头双向循环链表。如有仍不了解单向链表的,请看这一篇文章(7条消息) 【数据结构和算法】认识线性表中的链表,并实现单向链表_小王学代码的博客-CSDN博客
目录
前言
一、带头双向循环链表是什么?
二、实现带头双向循环链表
1.结构体和要实现函数
2.初始化和打印链表
3.头插和尾插
4.头删和尾删
5.查找和返回结点个数
6.在pos位置之前插入结点
7.删除指定pos结点
8.摧毁链表
三、完整代码
1.DSLinkList.h
2.DSLinkList.c
3.test.c
总结
前言
带头双向循环链表,是链表中最为复杂的一种结构,我们主要实现的功能为,头插尾插,头删尾删,初始化、打印、指定pos位置插入结点或者删除结点、寻找结点、摧毁链表等函数。
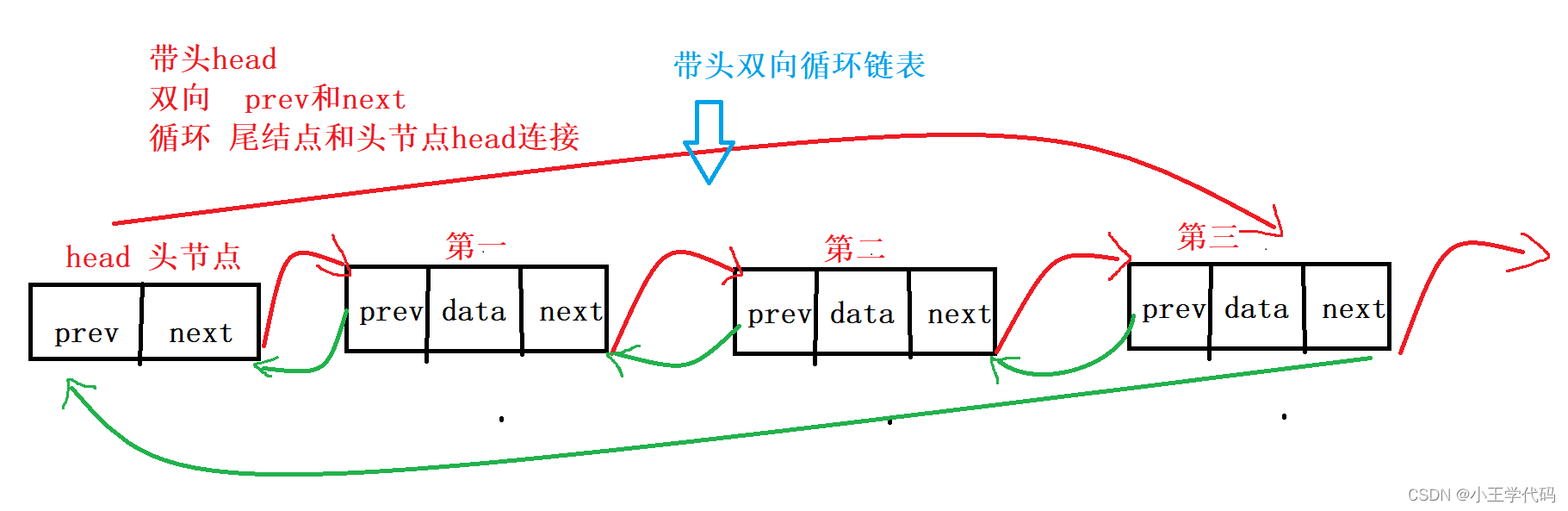
一、带头双向循环链表是什么?
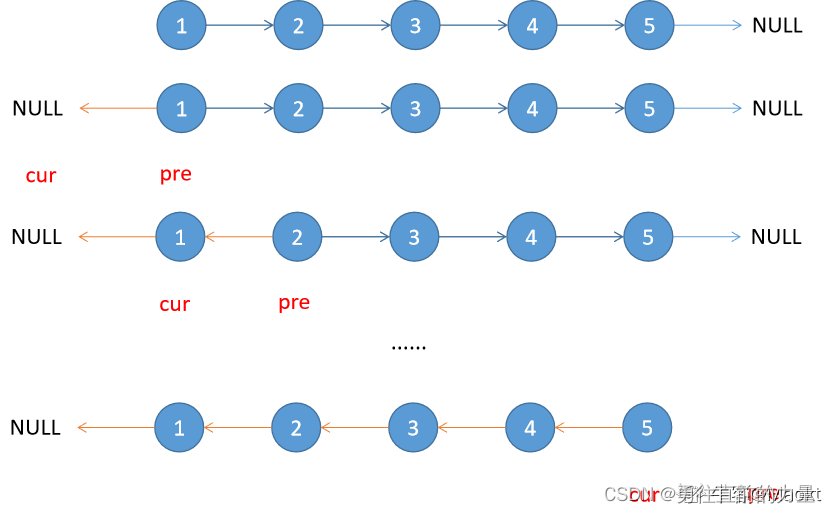
如图所示:
二、实现带头双向循环链表
1.结构体和要实现函数
结构体如下:
typedef struct DSLDataType;
//定义双向链表的结构体
//双向链表每一个节点都有一个前驱节点和后继节点,可以根据节点获得其前后的节点
typedef struct DSListNode {
struct DSListNode* prev;//前驱节点
struct DSListNode* next;//后继节点
int value;//数据域
}DSLNode;//重定义相比单向链表,多一个指针域prev,指向前面的结点地址
实现功能的函数:
//初始化
DSLNode*ListInit();
//打印链表
void ListPrint(DSLNode* ps);
//尾部插入
void ListPushBack(DSLNode* ps, int data);
//头部插入
void ListPushFront(DSLNode* ps, int data);
//尾部删除
void ListPopBack(DSLNode* ps);
//头部删除
void ListPopFront(DSLNode* ps);
//判空
bool ListEmpty(DSLNode* ps);
//返回链表节点个数
int Listsize(DSLNode* ps);
//寻找指定元素,返回对应的节点
DSLNode* ListFind(DSLNode* ps, int data);
//在pos之前插入节点
void ListInsert(DSLNode* pos, int data);
//删除pos位置结点
void ListEarse(DSLNode* pos);
//摧毁链表
void ListDestory(DSLNode* ps);2.初始化和打印链表
//对于函数的实现
//初始化
DSLNode* ListInit() {
//初始化创建链表
//创建新节点
DSLNode* num = (DSLNode*)malloc(sizeof(DSLNode));
//判断是否创建成功
if (num == NULL) {
perror("malloc fail\n");
exit(-1);
}
num->prev = num;
num->next = num;//作为头节点,前驱和后驱结点都指向自己
return num;
}
//打印链表
void ListPrint(DSLNode* ps) {
assert(ps);//断言
DSLNode* cur = ps->next;
printf("phead->");
while (cur != ps) {//双向链表,回到ps,就表示转了一圈
printf("%d->", cur->value);
cur = cur->next;
}
printf("NULL\n");
}
3.头插和尾插
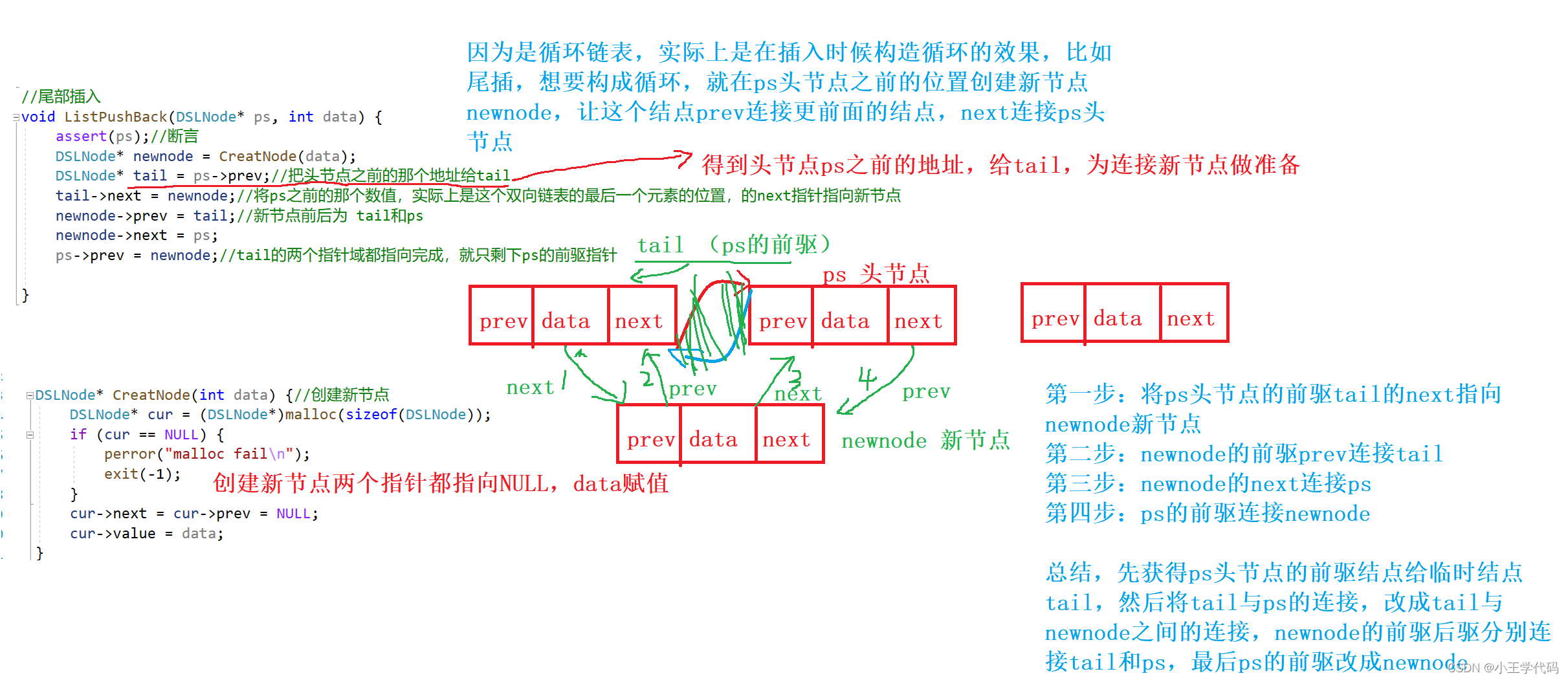
尾插如图所示:
代码如下:
DSLNode* CreatNode(int data) {//创建新节点
DSLNode* cur = (DSLNode*)malloc(sizeof(DSLNode));
if (cur == NULL) {
perror("malloc fail\n");
exit(-1);
}
cur->next = cur->prev = NULL;
cur->value = data;
}
//尾部插入
void ListPushBack(DSLNode* ps, int data) {
assert(ps);//断言
DSLNode* newnode = CreatNode(data);
DSLNode* tail = ps->prev;//把头节点之前的那个地址给tail
tail->next = newnode;//将ps之前的那个数值,实际上是这个双向链表的最后一个元素的位置,的next指针指向新节点
newnode->prev = tail;//新节点前后为 tail和ps
newnode->next = ps;
ps->prev = newnode;//tail的两个指针域都指向完成,就只剩下ps的前驱指针
}头插如图所示: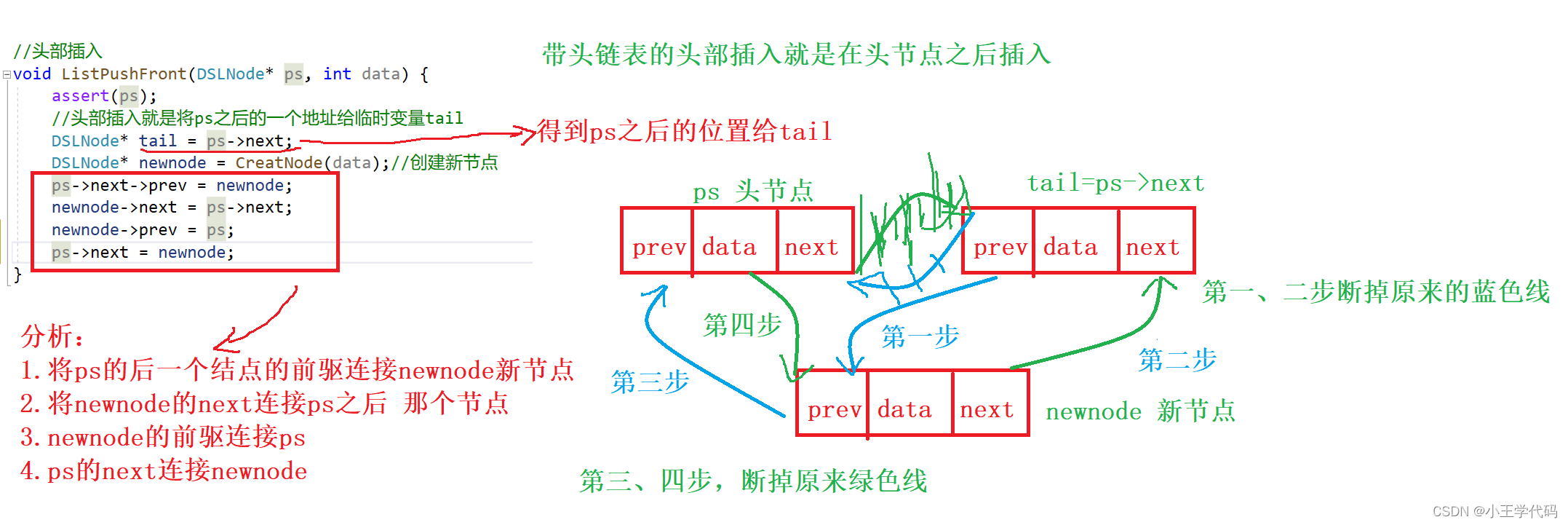 代码如下:
代码如下:
//头部插入
void ListPushFront(DSLNode* ps, int data) {
assert(ps);
//头部插入就是将ps之后的一个地址给临时变量tail
DSLNode* tail = ps->next;
DSLNode* newnode = CreatNode(data);//创建新节点
ps->next->prev = newnode;
newnode->next = ps->next;
newnode->prev = ps;
ps->next = newnode;
}
4.头删和尾删
尾部删除如图所示: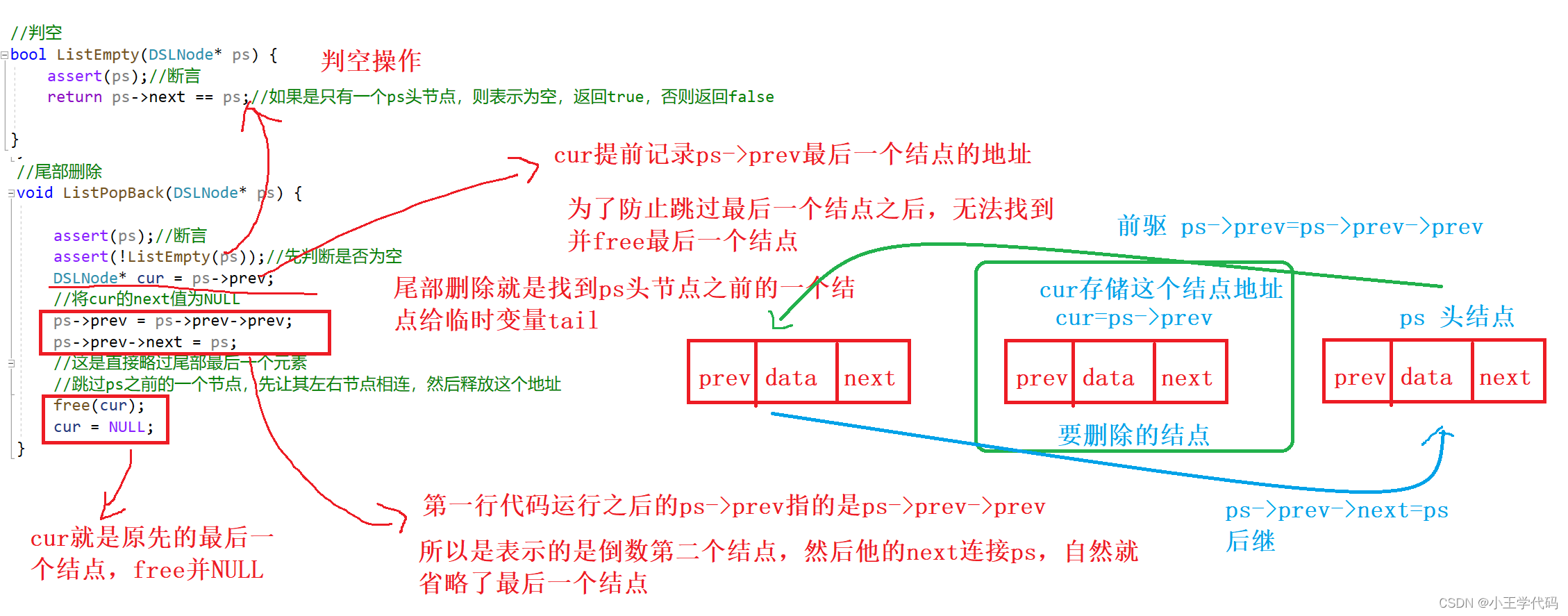
代码如下:
//判空
bool ListEmpty(DSLNode* ps) {
assert(ps);//断言
return ps->next == ps;//如果是只有一个ps头节点,则表示为空,返回true,否则返回false
}
//尾部删除
void ListPopBack(DSLNode* ps) {
assert(ps);//断言
assert(!ListEmpty(ps));//先判断是否为空
DSLNode* cur = ps->prev;
//将cur的next值为NULL
ps->prev = ps->prev->prev;
ps->prev->next = ps;
//这是直接略过尾部最后一个元素
//跳过ps之前的一个节点,先让其左右节点相连,然后释放这个地址
free(cur);
cur = NULL;
}头部删除如图所示:

代码如下:
//头部删除
void ListPopFront(DSLNode* ps) {
assert(ps);
assert(!ListEmpty(ps));
DSLNode* cur = ps->next;
//头删 是将头节点之后的第一个节点删除释放空间
ps->next = ps->next->next;
ps->next->prev = ps;
free(cur);
cur = NULL;
}5.查找和返回结点个数
查找:返回一个结点,根据data数值域,来返回第一个遇到的结点cur,若没有返回NULL
//返回链表节点个数
int Listsize(DSLNode* ps) {
assert(ps);
int count = 0;
DSLNode* cur = ps->next;
while (cur != ps) {
count++;
cur = cur->next;
}
return count;
}
//查找
DSLNode* ListFind(DSLNode* ps, int data) {
assert(ps);
DSLNode* cur = ps->next;
while (cur != ps) {
if (cur->value == data) {
return cur;
}
}
return NULL;//NULL表示不存在
}6.在pos位置之前插入结点
如图所示:

代码如下:
//插入节点
void ListInsert(DSLNode* pos, int data) {
assert(pos);
//pos三种可能
//1.空链表
//2.只有一个节点
DSLNode* cur = pos->prev;
//双向链表可以直接找到pos之前的位置,单向链表只能进行循环
DSLNode* newnode = CreatNode(data);
pos->prev = newnode;//把新节点newnode的位置给pos的prev
newnode->prev = cur;//cur表示的是创建new节点之前的时候pos之前的结点
cur->next = newnode;
newnode->next = pos;
//另一种不使用cur的方法
//newnode->next = pos;
//pos->prev->next = newnode;
//newnode->prev = pos->prev;
//pos->prev = newnode;
}
7.删除指定pos结点
如图所示:

代码如下:
//删除指针
void ListEarse(DSLNode* pos) {
assert(pos);
DSLNode* cur = pos->prev;
DSLNode* tail = pos->next;
cur->next = tail;//两者相互指向,最后释放pos空间
tail->prev = cur;
free(pos);
pos = NULL;
}8.摧毁链表
两种方式,可以直接使用二级指针,也可以使用一级指针一个一个free和NULL
//摧毁链表
void ListDestory(DSLNode* ps) {
//可以设计二级指针直接将ps地址滞空为NULL
//这里还是使用一级指针
assert(ps);
DSLNode* cur = ps->next;
while (cur != ps) {
DSLNode* tail = cur->next;//这个地方就是一个精彩的地方
free(cur);//使用临时变量tail得到cur的下一个地址,然后再free cur
cur = tail;//tail这个时候就是cur 的下一个结点
}
free(ps);
ps = NULL;
}
void ListDestory2(DSLNode** ps) {
assert(ps);
free(ps);//二级指针直接free
*ps = NULL;
}三、完整代码
1.DSLinkList.h
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<assert.h>
#include<stdbool.h>
typedef struct DSLDataType;
//定义双向链表的结构体
//双向链表每一个节点都有一个前驱节点和后继节点,可以根据节点获得其前后的节点
typedef struct DSListNode {
struct DSListNode* prev;//前驱节点
struct DSListNode* next;//后继节点
int value;//数据域
}DSLNode;//重定义
//创建头节点,并将tail和head都指向第一个节点
struct DSList {
struct DSListNode* tail;
struct DSListNode* head;
unsigned int len;//表示链表的长度
};
//初始化
DSLNode*ListInit();
//打印链表
void ListPrint(DSLNode* ps);
//尾部插入
void ListPushBack(DSLNode* ps, int data);
//头部插入
void ListPushFront(DSLNode* ps, int data);
//尾部删除
void ListPopBack(DSLNode* ps);
//头部删除
void ListPopFront(DSLNode* ps);
//判空
bool ListEmpty(DSLNode* ps);
//返回链表节点个数
int Listsize(DSLNode* ps);
//寻找指定元素,返回对应的节点
DSLNode* ListFind(DSLNode* ps, int data);
//在pos之前插入节点
void ListInsert(DSLNode* pos, int data);
//删除pos位置结点
void ListEarse(DSLNode* pos);
//摧毁链表
void ListDestory(DSLNode* ps);
2.DSLinkList.c
#define _CRT_SECURE_NO_WARNINGS
#include"DSLinkList.h"
//对于函数的实现
//初始化
DSLNode* ListInit() {
//初始化创建链表
//创建新节点
DSLNode* num = (DSLNode*)malloc(sizeof(DSLNode));
//判断是否创建成功
if (num == NULL) {
perror("malloc fail\n");
exit(-1);
}
num->prev = num;
num->next = num;
return num;
}
//打印链表
void ListPrint(DSLNode* ps) {
assert(ps);//断言
DSLNode* cur = ps->next;
printf("phead->");
while (cur != ps) {//双向链表,回到ps,就表示转了一圈
printf("%d->", cur->value);
cur = cur->next;
}
printf("NULL\n");
}
DSLNode* CreatNode(int data) {//创建新节点
DSLNode* cur = (DSLNode*)malloc(sizeof(DSLNode));
if (cur == NULL) {
perror("malloc fail\n");
exit(-1);
}
cur->next = cur->prev = NULL;
cur->value = data;
}
//尾部插入
void ListPushBack(DSLNode* ps, int data) {
assert(ps);//断言
DSLNode* newnode = CreatNode(data);
DSLNode* tail = ps->prev;//把头节点之前的那个地址给tail
tail->next = newnode;//将ps之前的那个数值,实际上是这个双向链表的最后一个元素的位置,的next指针指向新节点
newnode->prev = tail;//新节点前后为 tail和ps
newnode->next = ps;
ps->prev = newnode;//tail的两个指针域都指向完成,就只剩下ps的前驱指针
}
//头部插入
void ListPushFront(DSLNode* ps, int data) {
assert(ps);
//头部插入就是将ps之后的一个地址给临时变量tail
DSLNode* tail = ps->next;
DSLNode* newnode = CreatNode(data);//创建新节点
ps->next->prev = newnode;
newnode->next = ps->next;
newnode->prev = ps;
ps->next = newnode;
}
//判空
bool ListEmpty(DSLNode* ps) {
assert(ps);//断言
return ps->next == ps;//如果是只有一个ps头节点,则表示为空,返回true,否则返回false
}
//返回链表节点个数
int Listsize(DSLNode* ps) {
assert(ps);
int count = 0;
DSLNode* cur = ps->next;
while (cur != ps) {
count++;
cur = cur->next;
}
printf("\n");
return count;
}
//尾部删除
void ListPopBack(DSLNode* ps) {
assert(ps);//断言
assert(!ListEmpty(ps));//先判断是否为空
DSLNode* cur = ps->prev;
//将cur的next值为NULL
ps->prev = ps->prev->prev;
ps->prev->next = ps;
//这是直接略过尾部最后一个元素
//跳过ps之前的一个节点,先让其左右节点相连,然后释放这个地址
free(cur);
cur = NULL;
}
//头部删除
void ListPopFront(DSLNode* ps) {
assert(ps);
assert(!ListEmpty(ps));
DSLNode* cur = ps->next;
//头删 是将头节点之后的第一个节点删除释放空间
ps->next = ps->next->next;
ps->next->prev = ps;
free(cur);
cur = NULL;
}
//查找
DSLNode* ListFind(DSLNode* ps, int data) {
assert(ps);
DSLNode* cur = ps->next;
while (cur != ps) {
if (cur->value == data) {
return cur;
}
}
return NULL;//NULL表示不存在
}
//插入节点
void ListInsert(DSLNode* pos, int data) {
assert(pos);
//pos三种可能
//1.空链表
//2.只有一个节点
DSLNode* cur = pos->prev;
//双向链表可以直接找到pos之前的位置,单向链表只能进行循环
DSLNode* newnode = CreatNode(data);
pos->prev = newnode;//把新节点newnode的位置给pos的prev
newnode->prev = cur;//cur表示的是创建new节点之前的时候pos之前的结点
cur->next = newnode;
newnode->next = pos;
//另一种不使用cur的方法
//newnode->next = pos;
//pos->prev->next = newnode;
//newnode->prev = pos->prev;
//pos->prev = newnode;
}
//删除指针
void ListEarse(DSLNode* pos) {
assert(pos);
DSLNode* cur = pos->prev;
DSLNode* tail = pos->next;
cur->next = tail;//两者相互指向,最后释放pos空间
tail->prev = cur;
free(pos);
pos = NULL;
}
//摧毁链表
void ListDestory(DSLNode* ps) {
//可以设计二级指针直接将ps地址滞空为NULL
//这里还是使用一级指针
assert(ps);
DSLNode* cur = ps->next;
while (cur != ps) {
DSLNode* tail = cur->next;
free(cur);
cur = tail;
}
free(ps);
ps = NULL;
}
void ListDestory2(DSLNode** ps) {
assert(ps);
free(ps);
*ps = NULL;
}3.test.c
#define _CRT_SECURE_NO_WARNINGS
#include"DSLinkList.h"
void test()
{
DSLNode* phead = ListInit();//初始化
ListPushBack(phead, 1);
ListPushBack(phead, 2);
ListPushBack(phead, 3);
ListPushBack(phead, 4);
ListPushBack(phead, 5);//检验尾插
ListPrint(phead);//打印
ListPushFront(phead, 10);
ListPushFront(phead, 20);
ListPushFront(phead, 30);
ListPushFront(phead, 40);
ListPushFront(phead, 50);//检验头插
ListPrint(phead);//打印
printf("%d\n", Listsize(phead));//检验返回结点个数
ListPopBack(phead);
ListPopBack(phead);
ListPopBack(phead);
ListPopBack(phead);
ListPopBack(phead);//尾删
ListPopFront(phead);
ListPopFront(phead);
ListPopFront(phead);
ListPopFront(phead);
ListPopFront(phead);//头删
ListPrint(phead);//打印
ListInsert(phead->next, 10);//pos指定结点之前插入newnode新节点
ListPrint(phead);//打印
}
int main()
{
test();
return 0;
}总结
我们本文主要讲解了,链表中最为复杂的带头双向循环链表的使用和代码实现,实现了头插尾插,头删尾删,初始化、打印、指定pos位置插入结点或者删除结点、寻找结点、摧毁链表等函数。并做了板书图示解释相应函数的流程,附带完整代码,以便帮助大家更好的理解。
接下来我们就要进行栈和队列的学习,本文不足之处,欢迎大佬指导一二,让我们开始新章节的学习!!!