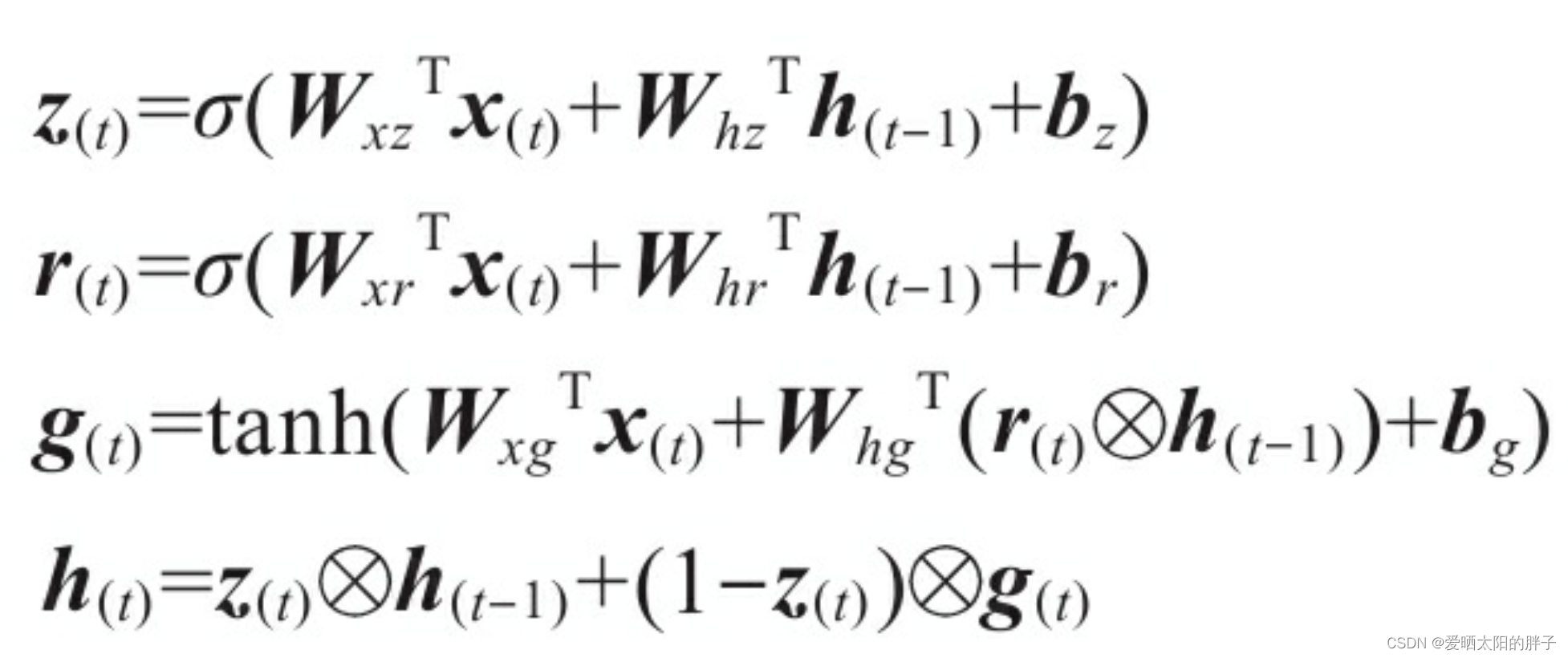刚接触深度学习半年的时间,这期间有专门去学习LSTM ,这几天读机器学习实战这本书的时候又遇到了,感觉写的挺好的,所以准备结合本书写一下总结方便日后回顾。如有错误,欢迎批评指正。
一、LSTM
优势:可在一定程度上解决RNN短期记忆的问题。
注:由于数据在遍历RNN时会经过转换,因此在每个时间步长都会丢失一些信息。一段时间后,RNN的状态几乎没有任何最初输入的痕迹。
1.1 LSTM神经元

如上图所示LSTM神经元存在两个状态向量:h(t)和c(t)(可将h(t)视为短期状态,c(t)视为长期状态) 首先,将当前输入向量x(t)和先前的短期状态h(t-1)馈入四个不同的全连接层(FC)。它们都有不同的目的:
-
主要层是输出g(t)的层:它通常的作用是分析当前输入x(t)和先前(短期)状态 h(t-1),得到本时间步的信息。
-
遗忘门(由f(t)控制):控制长期状态的哪些部分应当被删除。
-
输入门(由i(t)控制):控制应将g(t)的哪些部分添加到长期状态。
-
输出门(由o(t)控制):控制应在此时间步长读取长期状态的哪些部分并输出 到h(t)和y(t)。
如图1,LSTM神经元运用了三个sigmoid激活函数和一个tanh激活函数,
- Tanh 作用在于帮助调节流经网络的值,使得数值始终限制在 -1 和 1 之间。
- Sigmoid 激活函数与 tanh 函数类似,不同之处在于 sigmoid 是把值压缩到0~1 这样的设置有助于更新或忘记信息,可将其理解为比例(任何数乘以 0 都得 0,这部分信息就会剔除掉;同样的,任何数乘以 1 都得到它本身,这部分信息就会完美地保存下来)因记忆能力有限,记住重要的,忘记不重要的。
例子:以输入门为例,首先输入x(t)和先前(短期)状态 h(t-1),得到本时间步的信息向量g(t) = (g1(t),g2(t),g3(t)……gn(t))(其中n个神经元的个数,g1(t)取值范围为(-1,1)),然后与向量i(t)=(i1(t),i2(t),i3(t)……in(t))(ii(t)取值范围为(0,1))对应元素相乘,得到向量(g1(t)*i1(t), g2(t)*i2(t)……gn(t)*in(t)),即本时间步有用信息,然后把他加上长期记忆c(t-1)中进行保存。
总结:LSM关键的思想是网络可以学习长期状态下存储的内容、丢弃的内容以及从中读取的内容。当长期状态c(t-1)从左到右遍历网络时,可以看到它首先经过一个遗 忘门,丢掉了一些记忆,然后通过加法操作添加了一些新的记忆(由输入门选择的记忆)。结果c(t)直接送出来,无须任何进一步的转换。因此,在每个时间步长中,都会 丢掉一些记忆,并添加一些记忆。此外,在加法运算之后,长期状态被复制并通过tanh函数传输,然后结果被输出门滤波。这将产生短期状态h(t)(等于该时间步长的单元输出 y(t))。
1.2 LSTM计算公式
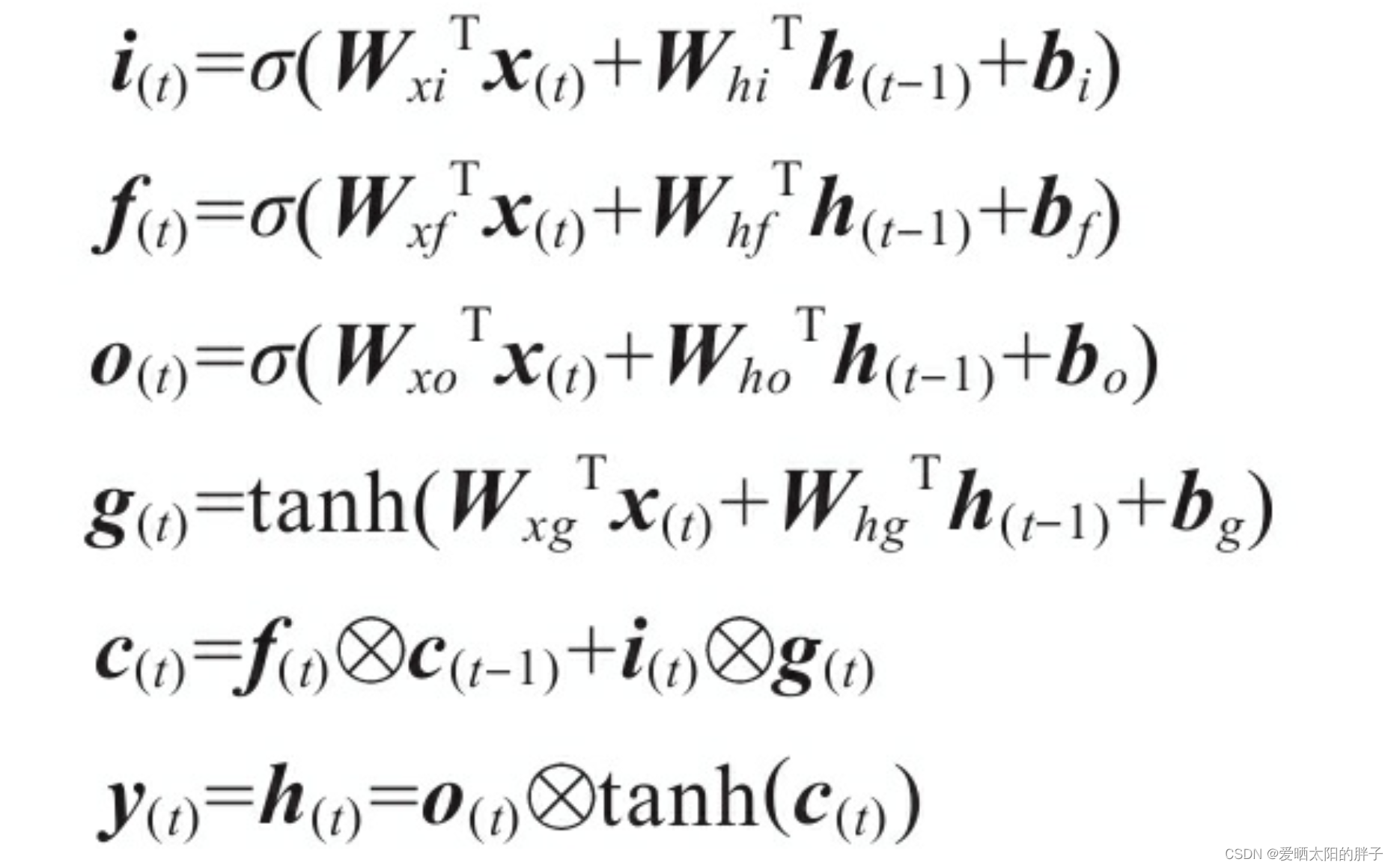
Wxi、Wxf、Wxo、Wxg是四层中的每层与输入向量x(t)连接的权重矩阵。
Whi、Whf、Who和Whg是四层中的每层与先前的短期状态h(t-1)连接的权重矩阵。
bi、bf、bo和bg是四层中每层的偏置项
1.3简单代码实现
如下所示:
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])二、GRU
2.1 GRU神经元
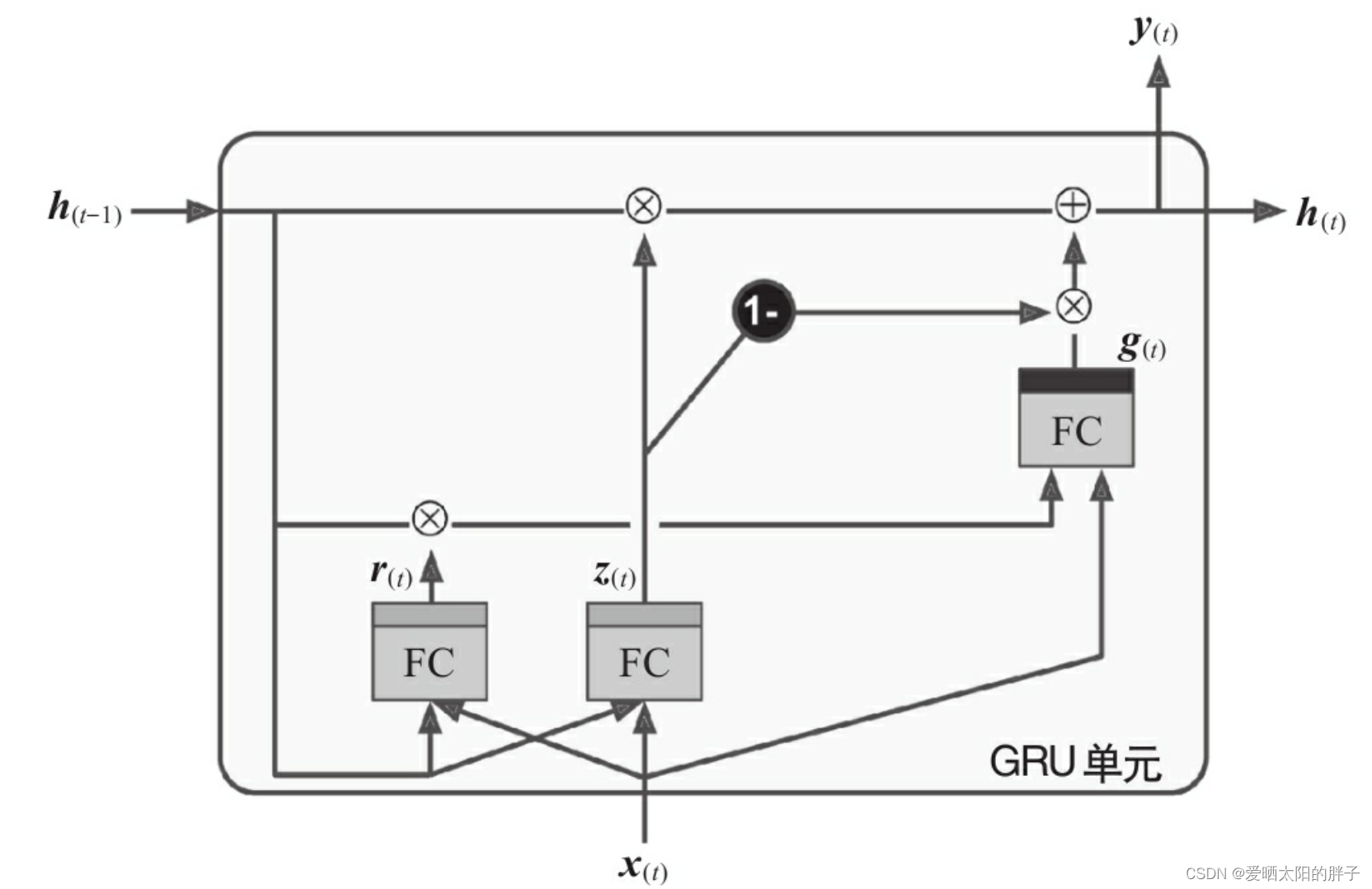
GRU单元是LSTM单元的简化版,并且保留遗忘门(保留有用记忆)和输入门(学习新知识)。
主要简化如下:
-
两个状态向量合并为一个向量h(t)。
-
单个门控制器z(t)控制遗忘门和输入门。
-
没有输出门(在每个时间步长都输出完整的状态向量)。
此外,GRU引入门控制器r(t)控制先前状态的哪一部分将显示给主要层(g(t))。
2.2 计算公式