一 前言
上次数据库支持了一个测试表的插入和查询,但是数据全部保存到磁盘中的,如果程序重启后,数据都会全部丢了,所以需要持久化到磁盘上,像sqlite一样,简单的将数据库的数据保存到一个磁盘文件上。
二 实现原理
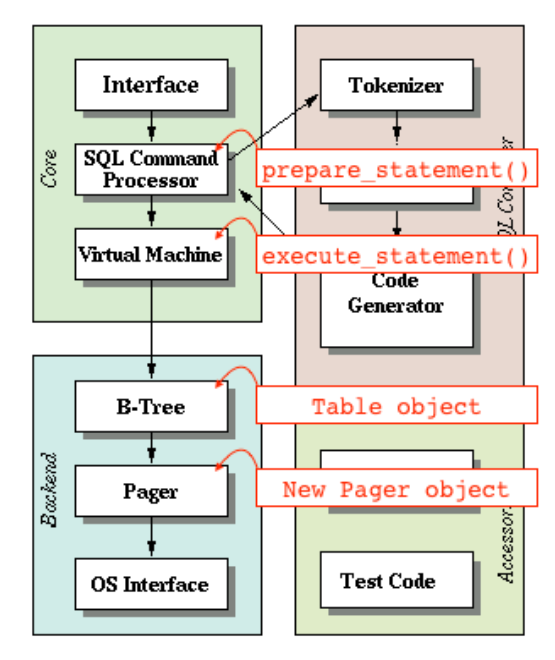
我们上次已经将数据库的数据持久化到一块4kB的内存块上,可以方便的将这块内存持久化到文件上即可,具体实现步骤:
我们定义一个抽象结构Pager,这是对文件结构和页面的综合抽象。具体如下:
typedef struct {
int file_descriptor;
uint32_t file_length;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
uint32_t num_rows;
Pager *pager;
} Table;操作数据的时候通过接口获取到对应的page内容,如果page存在,则直接使用,如果page不存在,则从文件中加载对应位置的4KB的数据保存到对应page中。
关闭数据库的时候,再将整个结果回写到磁盘上。
关键实现是通过lseek来定位文件的位置,存入文件的数据内容按照行数进行定位的,如同再内存中一样。
关闭数据的时候也是通过定位文件后,按照内存块形式直接写入到磁盘,挺简单,也挺神奇。
三 实现代码
首先Table的申请改变了,由原来的完全从内存读取,改成除了所需的内存外,还和打开文件关联起来。
253 Pager *pager_open(const char *filename)
254 {
// 打开文件,为可读可写,没有则创建
255 int fd = open(filename, O_RDWR | O_CREAT, S_IWUSR | S_IRUSR);
256 if (fd == -1) {
257 printf("Unable to open file.\n");
258 exit(EXIT_FAILURE);
259 }
// 定位到尾部 返回文件的大小
260 int file_length = lseek(fd, 0, SEEK_END);
// 申请Pager,且和文件关联
261 Pager *pager = (Pager*)malloc(sizeof(Pager));
262 pager->file_descriptor = fd;
263 pager->file_length = file_length;
264
265 for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
266 pager->pages[i] = NULL;
267 }
268 return pager;
269 }
304 Table *db_open(const char *filename)
305 {
306 Pager *pager = pager_open(filename);
307 uint32_t num_rows = pager->file_length / ROW_SIZE;
308 Table *table = (Table *)malloc(sizeof(Table));
309 table->pager = pager;
310 table->num_rows = num_rows;
311 return table;
312 }在数据库关闭的时候,将数据刷新到磁盘上,如下:
332 void db_close(Table *table)
333 {
334 Pager *pager = table->pager;
// 根据行数计算页面数量
335 uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
336 for (uint32_t i = 0; i < num_full_pages; i++) {
337 if (pager->pages[i] == NULL) {
338 break;
339 }
340 pager_flush(pager, i, PAGE_SIZE);
341 }
// 处理不够一页多余的行数
342 uint32_t num_add_rows = table->num_rows % ROWS_PER_PAGE;
343 if (num_add_rows > 0) {
344 uint32_t page_num = num_full_pages;
345 if (pager->pages[page_num] != NULL) {
346 pager_flush(pager, page_num, num_add_rows * ROW_SIZE);
347 free(pager->pages[page_num]);
348 pager->pages[page_num] = NULL;
349 }
350 }
351 int result = close(pager->file_descriptor);
352 if (result == -1) {
353 printf("Error closing db file.\n");
354 exit(EXIT_FAILURE);
355 }
356 for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
357 Pager *page = (Pager *) pager->pages[i];
358 if (page) {
359 free(page);
360 pager->pages[i] = NULL;
361 }
362 }
363 free(pager);
364 free(table);
365 }下面是比较核心的代码,就是将pager刷新到磁盘上,代码如下:
314 void pager_flush(Pager *pager, uint32_t page_num, uint32_t size)
315 {
316 if (pager->pages[page_num] == NULL) {
317 printf("Tried to flush null page.\n");
318 exit(EXIT_FAILURE);
319 }
// 根据页面数定位到文件的具体位置
320 off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
321 if (offset == -1) {
322 printf("Error seeking:%d\n", errno);
323 exit(EXIT_FAILURE);
324 }
// 将数据写入到文件,每次大部分写入一个Page大小,也可能写入部分
325 ssize_t byte_written = write(pager->file_descriptor, pager->pages[page_num], size);
326 if (byte_written == -1) {
327 printf("Error writing:%d", errno);
328 exit(EXIT_FAILURE);
329 }
330 }写入磁盘没问题,那读取的时候,读取的时候和内存读的时候也类似,只是改成从文件中读取:
282 ExecuteResult execute_select(Statement *statement, Table *table)
283 {
284 Row row;
285 for (uint32_t i = 0; i < table->num_rows; i++) {
// 将数据反序列化然后打印出来
286 deserialize_row(row_slot(table, i), &row);
287 print_row(&row);
288 }
289 return EXECUTE_SUCCESS;
290 }获取内存页面和页面的偏移量
244 void *row_slot(Table *table, uint32_t row_num)
245 {
// 定位页数
246 uint32_t page_num = row_num / ROWS_PER_PAGE;
// 获取页面
247 void *page = get_page(table->pager, page_num);
248 uint32_t row_offset = row_num % ROWS_PER_PAGE;
// 定位页内的行偏移量
249 uint32_t byte_offset = row_offset * ROW_SIZE;
250 return (char *)page + byte_offset;
251 }下面是读取文件的具体页面:
100 void *get_page(Pager *pager, uint32_t page_num)
101 {
102 if (page_num > TABLE_MAX_PAGES) {
103 printf("Tried to fetch page number out of bounds. %d>%d", page_num, TABLE_MAX_PAGES);
104 exit(EXIT_FAILURE);
105 }
106 if (pager->pages[page_num] == NULL) {
107 void *page = malloc(PAGE_SIZE);
108 uint32_t num_pages = pager->file_length / PAGE_SIZE;
109 if (pager->file_length % PAGE_SIZE) {
110 num_pages += 1;
111 }
// 从文件中读取一个页面大小,如果原来文件为0则忽略
112 if (page_num <= num_pages && pager->file_length != 0) {
113 lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
114 ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
115 if (bytes_read == -1) {
116 printf("Error reading file:%d\n", errno);
117 exit(EXIT_FAILURE);
118 }
119 }
120 pager->pages[page_num] = page;
121 }
122 return pager->pages[page_num];
123 }四 最终完整代码
#include <stdio.h>
#if defined(_MSC_VER)
#include <BaseTsd.h>
typedef SSIZE_T ssize_t;
#endif
#include <stdint.h>
#include <string.h>
#include <malloc.h>
#include <cstdlib>
#include <stdbool.h>
#include <errno.h>
#include <fcntl.h>
#include <unistd.h>
// #include <file.h>
#define EXIT_SUCCESS 0
#define MAX_LEN 1024
#pragma warning(disable : 4819)
#define COLUMN_USERNAME_SIZE 32
#define COLUMN_EMAIL_SIZE 255
#define TABLE_MAX_PAGES 100
typedef enum {
META_COMMAND_SUCCESS,
META_COMMAND_UNRECOGNIZED_COMMAND
} MetaCommandResult;
typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT, PREPARE_NEGATIVE_ID, PREPARE_STRING_TOO_LONG, PREPARE_SYNTAX_ERROR} PrepareResult;
typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
typedef struct {
uint32_t id;
char username[COLUMN_USERNAME_SIZE + 1];
char email[COLUMN_EMAIL_SIZE + 1];
} Row;
typedef struct {
int file_descriptor;
uint32_t file_length;
void *pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
uint32_t num_rows;
Pager *pager;
} Table;
typedef struct {
StatementType type;
Row row_to_insert;
} Statement;
typedef struct {
char *buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
const uint32_t ID_SIZE = size_of_attribute(Row, id);
const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
const uint32_t ID_OFFSET = 0;
const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
void db_close(Table *table);
InputBuffer *new_input_buffer()
{
InputBuffer *input_buffer = (InputBuffer *)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void *get_page(Pager *pager, uint32_t page_num)
{
if (page_num > TABLE_MAX_PAGES) {
printf("Tried to fetch page number out of bounds. %d>%d", page_num, TABLE_MAX_PAGES);
exit(EXIT_FAILURE);
}
if (pager->pages[page_num] == NULL) {
void *page = malloc(PAGE_SIZE);
uint32_t num_pages = pager->file_length / PAGE_SIZE;
if (pager->file_length % PAGE_SIZE) {
num_pages += 1;
}
if (page_num <= num_pages && pager->file_length != 0) {
lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
if (bytes_read == -1) {
printf("Error reading file:%d\n", errno);
exit(EXIT_FAILURE);
}
}
pager->pages[page_num] = page;
}
return pager->pages[page_num];
}
int getline_my(char **buffer, size_t *length, FILE *fd)
{
int i = 0;
char ch;
char buf[MAX_LEN] = {0};
while ((ch = fgetc(fd)) != EOF && ch != '\n') {
if (MAX_LEN - 1 == i) {
break;
}
buf[i++] = ch;
}
*length = i;
buf[i] = '\0';
*buffer = (char *)malloc(sizeof(char) * (i + 1));
strncpy(*buffer, buf, i + 1);
return i;
}
void print_row(Row *row)
{
printf("(%d,%s,%s)\n", row->id, row->username, row->email);
}
void read_input(InputBuffer *input_buffer)
{
ssize_t bytes_read =
getline_my(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
input_buffer->input_length = bytes_read ;
input_buffer->buffer[bytes_read] = 0;
}
void close_input_buffer(InputBuffer *input_buffer)
{
free(input_buffer->buffer);
free(input_buffer);
input_buffer = NULL;
}
///
MetaCommandResult do_meta_command(InputBuffer *input_buffer, Table *table)
{
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
}
PrepareResult prepare_insert(InputBuffer *input_buffer, Statement *statement)
{
statement->type = STATEMENT_INSERT;
char *keyword = strtok(input_buffer->buffer, " ");
char *id_string = strtok(NULL, " ");
char *username = strtok(NULL, " ");
char *email = strtok(NULL, " ");
if (id_string == NULL || username == NULL || email == NULL) {
return PREPARE_SYNTAX_ERROR;
}
int id = atoi(id_string);
if (id < 0) {
return PREPARE_NEGATIVE_ID;
}
if (strlen(username) > COLUMN_USERNAME_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
if (strlen(email) > COLUMN_EMAIL_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
statement->row_to_insert.id = id;
strcpy(statement->row_to_insert.username, username);
strcpy(statement->row_to_insert.email, email);
return PREPARE_SUCCESS;
}
PrepareResult prepare_statement(InputBuffer *input_buffer,
Statement *statement)
{
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
return prepare_insert(input_buffer, statement);
} else if (strncmp(input_buffer->buffer, "select", 6) == 0) {
statement->type = STATEMENT_SELECT;
return PREPARE_SUCCESS;
}
return PREPARE_UNRECOGNIZED_STATEMENT;
}
void serialize_row(Row *source, void *destination)
{
memcpy((char *)destination + ID_OFFSET, &(source->id), ID_SIZE);
memcpy((char *)destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
memcpy((char *)destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
}
void deserialize_row(void *source, Row *destination)
{
memcpy(&(destination->id), (char *)source + ID_OFFSET, ID_SIZE);
memcpy(&(destination->username), (char *)source + USERNAME_OFFSET, USERNAME_SIZE);
memcpy(&(destination->email), (char *)source + EMAIL_OFFSET, EMAIL_SIZE);
}
void *row_slot(Table *table, uint32_t row_num)
{
uint32_t page_num = row_num / ROWS_PER_PAGE;
void *page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}
Pager *pager_open(const char *filename)
{
int fd = open(filename, O_RDWR | O_CREAT, S_IWUSR | S_IRUSR);
if (fd == -1) {
printf("Unable to open file.\n");
exit(EXIT_FAILURE);
}
int file_length = lseek(fd, 0, SEEK_END);
Pager *pager = (Pager*)malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
}
return pager;
}
ExecuteResult execute_insert(Statement *statement, Table *table)
{
if (table->num_rows >= TABLE_MAX_ROWS) {
return EXECUTE_TABLE_FULL;
}
Row *row_to_insert = &(statement->row_to_insert);
serialize_row(row_to_insert, row_slot(table, table->num_rows));
table->num_rows += 1;
return EXECUTE_SUCCESS;
}
ExecuteResult execute_select(Statement *statement, Table *table)
{
Row row;
for (uint32_t i = 0; i < table->num_rows; i++) {
deserialize_row(row_slot(table, i), &row);
print_row(&row);
}
return EXECUTE_SUCCESS;
}
ExecuteResult execute_statement(Statement *statement, Table *table)
{
switch (statement->type) {
case (STATEMENT_INSERT):
return execute_insert(statement, table);
case (STATEMENT_SELECT):
return execute_select(statement, table);
}
}
Table *db_open(const char *filename)
{
Pager *pager = pager_open(filename);
uint32_t num_rows = pager->file_length / ROW_SIZE;
Table *table = (Table *)malloc(sizeof(Table));
table->pager = pager;
table->num_rows = num_rows;
return table;
}
void pager_flush(Pager *pager, uint32_t page_num, uint32_t size)
{
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page.\n");
exit(EXIT_FAILURE);
}
off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
if (offset == -1) {
printf("Error seeking:%d\n", errno);
exit(EXIT_FAILURE);
}
ssize_t byte_written = write(pager->file_descriptor, pager->pages[page_num], size);
if (byte_written == -1) {
printf("Error writing:%d", errno);
exit(EXIT_FAILURE);
}
}
void db_close(Table *table)
{
Pager *pager = table->pager;
uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
for (uint32_t i = 0; i < num_full_pages; i++) {
if (pager->pages[i] == NULL) {
break;
}
pager_flush(pager, i, PAGE_SIZE);
}
uint32_t num_add_rows = table->num_rows % ROWS_PER_PAGE;
if (num_add_rows > 0) {
uint32_t page_num = num_full_pages;
if (pager->pages[page_num] != NULL) {
pager_flush(pager, page_num, num_add_rows * ROW_SIZE);
free(pager->pages[page_num]);
pager->pages[page_num] = NULL;
}
}
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
exit(EXIT_FAILURE);
}
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
Pager *page = (Pager *) pager->pages[i];
if (page) {
free(page);
pager->pages[i] = NULL;
}
}
free(pager);
free(table);
}
void print_prompt()
{
printf("microdb > ");
}
int main(int argc, char **argv)
{
InputBuffer *input_buffer = new_input_buffer();
if (argc < 2) {
printf("Must supply a database filename.\n");
exit(EXIT_FAILURE);
}
char *filename = argv[1];
Table *table = db_open(filename);
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
switch (do_meta_command(input_buffer,table)) {
case (META_COMMAND_SUCCESS):
continue;
case (META_COMMAND_UNRECOGNIZED_COMMAND):
printf("Unrecognized command '%s'\n", input_buffer->buffer);
continue;
}
} else {
Statement statement;
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
case (PREPARE_STRING_TOO_LONG):
printf("String is too long.\n");
continue;
case (PREPARE_NEGATIVE_ID):
printf("ID must be positive.\n");
continue;
case (PREPARE_SYNTAX_ERROR):
printf("Syntax error. Could not parse statement.\n");
continue;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
switch (execute_statement(&statement, table)) {
case EXECUTE_SUCCESS:
printf("Executed.\n");
break;
case EXECUTE_TABLE_FULL:
printf("Error: Table full.\n");
break;
}
}
}
return 0;
}代码整体如上,代码最终在linux下编译,在windows下编译,需要改不少api,在linux下比较简单: g++ -g ./main.cpp 即可。
运行如下:
[root@localhost microdb]# ./a.out db.mb
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
Executed.
microdb > insert 6 d d@qq.com
Executed.
microdb > insert 7 f f@qq.com
Executed.
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
(6,d,d@qq.com)
(7,f,f@qq.com)
Executed.
microdb > insert 8 g g@qq.com
Executed.
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
(6,d,d@qq.com)
(7,f,f@qq.com)
(8,g,g@qq.com)
Executed.
microdb > .exit
[root@localhost microdb]# ./a.out db.mb
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
(6,d,d@qq.com)
(7,f,f@qq.com)
(8,g,g@qq.com)
Executed.
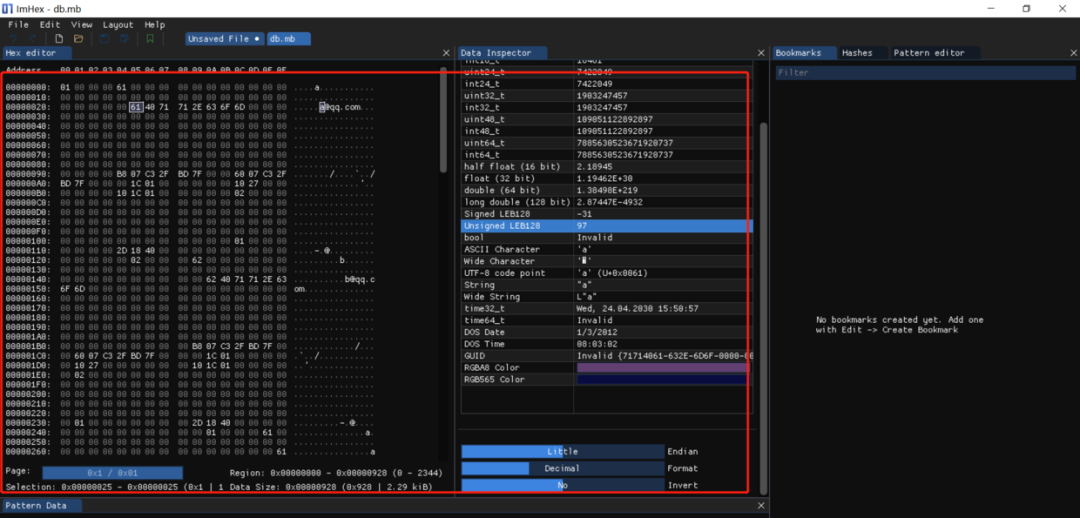
microdb > .exit五 查看下数据库文件内容
可以通过ImHex查看db.mb内容,展示如下,id为1,注意保存在四个字节的低位,为小头模式,如果是大头模式,则要考虑到如果保存的机器为大头模式,需要考虑字节序的问题。接着a为username,下一个字段email为a@qq.com,但是整个文件相当浪费空间了。