今天,我将带来数据结构的排序算法,排序算法作为校招中常考知识点之一,我们必须要熟练的掌握它,对自己提出高要求,才能有高回报。
目录
- 排序的概念和应用
- 内部排序和外部排序
- 排序算法需要掌握的知识
- 插入排序
- 1.直接插入排序
- 2.希尔排序
- 选择排序
- 1.直接选择排序
- 2.堆排序
- 交换排序
- 1.冒泡排序
- 2.快速排序
- 2.1 hoare版本
- 2.2 挖坑法
- 2.3 前后指针版本
- 2.4 三数取中优化和小区间优化
- 2.4.1 三数取中优化
- 2.4.2 小区间优化
- 2.4.3 含三数取中优化和小区间优化的hoare版本的代码
- 2.4.4 含三数取中优化和小区间优化的挖坑法版本的代码
- 2.4.5 含三数取中优化和小区间优化的前后指针版本的代码
- 2.5 快速排序非递归版本
- 2.6 快速排序优化之三目并排
- 2.7 对于快速排序在秋招中的建议
- 归并排序
- 递归版本
- 非递归版本
- 基数排序
- 计数排序
- 文件外排序
- 测试排序的代码
- 校招考核范围
排序的概念和应用
排序的概念:
排序,就是就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
在生活中,排序的应用是非常的广泛的,比如在我们高考前,我们会在网上搜寻大学的排名,或者在双十一等日子,我们在淘宝挑着想要购买的电脑,它们都按照着一个关键字的大小来进行排序的,如大学排行榜按高考成绩,淘宝显示的电脑顺序按价格或者好评率。
大学排行榜
淘宝
由此可见,排序算法是多么的重要,那么,我们开始算法的教学吧。
内部排序和外部排序
概念:
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
简单来说,当我们需要排序的数据远远大于内存所能存放的最大空间,我们只能通过某种方式直接对磁盘存储的数据进行排序,称之为外部排序。如果,我们需要排序的数据量小,可以拿到内存进行排序,称之为内部排序
排序算法需要掌握的知识
1.在学习完八大排序后,我们必须熟练的掌握它们的思想,并且能够熟悉它们的代码实现。
2.我们必须要理解它们对应的时间复杂度和空间复杂度。
至于时间复杂度和空间复杂度的讲解,我在前面的文章已经提到,下面是
传送门
时间复杂度和空间复杂度(以题目的方式来介绍和分析)
3.我们必须掌握每个排序算法的稳定性。
稳定性的概念:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
如:我们需要排序序列,1 2 3 2,黑色字体的2在浅色字体2的后面。
如果我们排序后,结果为1 2 2 3,即两个数字2的顺序没有被打乱,依然是黑色字体的2在浅色字体2的后面,那么该排序算法就是稳定的。
如果排序后的序列为1 2 2 3,即两个数字2的顺序被打乱,黑色字体的2在浅色字体2的前面,那么该排序算法就是不稳定的。
插入排序
1.直接插入排序
假设我要让一个乱序的数组变成升序,那么我将从第二个元素开始,依次跟前面的元素进行比较。
过程如下:
我选择第二个元素跟第一个元素进行比较,如果,第二个元素小于第一个元素,则进行交换,如果是第二个元素大于第一个元素或者相等,则不进行交换。
这一套下来,前两个元素已经升序了。
接下来,我选择第三个元素,依次跟第二、第一个元素进行比较,依然是第三个元素小,就进行交换。
直到比较完最后一个元素,那么数组就变成升序了。
以下是动图:
下面是代码实现:
#include<stdio.h>
void InsertSort(int* arr,int n)
{
for (int i = 0; i < n - 1; i++) //考虑tmp最后要取到最后一个元素,即n-1,i最大为n-2,保证i+1最大为 n - 1
{
int end = i;
int tmp = arr[end + 1];//保存取出来的值
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + 1] = arr[end]; //相当于前一个元素小,向后移
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
int main()
{
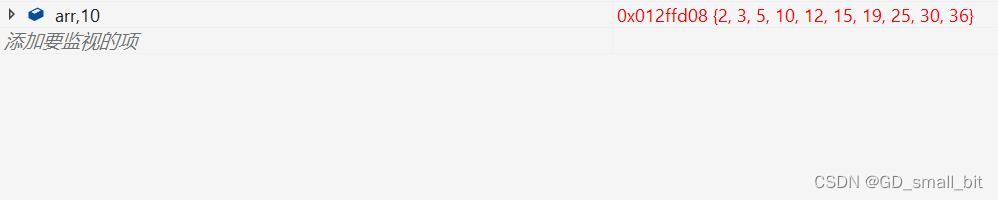
int arr[] = {10,2,19,3,12,25,15,36,30,5};
InsertSort(arr,sizeof(arr)/sizeof(arr[0]));
return 0;
}
排序前:

排序后:
直接插入排序的时间复杂度分析
最坏的情况:当我们要对数组进行排为升序的时候,初始数组为降序;当我们要排降序的时候,初始数组为升序。
上面的两种情况导致了,我们对每一个元素都需要往前进行调整多次。
如:5 4 3 2 1
我们要把它排成升序,按照直接插入排序。
第一趟结果4 5 3 2 1,4往前调整1次
第二趟结果3 4 5 2 1,3往前调整2次
第三趟结果2 3 4 5 1,2往前调整3次
第三趟结果1 2 3 4 5,1往前调整4次
如果上面调整次数有点不清楚,可以看上面的动图。
在上面的直接插入排序的代码中,有for循环和while循环。
当for循环第一次进入时,即为第一趟排序,因为要排序前两个元素;第二次进入时,即为第二趟排序,因为要排序前三个元素,所以for循环即为该排序的趟数。
当while循环第一次进入时,即为某一趟的第一次调整,第二次进入时,即为某一趟的第二次调整,所以while循环即为该排序的调整次数。
综上,排序第几趟与for循环第几次相关,调整次数与while循环次数相关。
在上面的排序数组5 4 3 2 1中,我们还可以发现,排序第一趟,调整一次,排序第二趟,调整两次,即第几趟排序,就调整几次。综上,for循环第几次进入,就相应的进行几次while循环。

总共循环次数为1 + 2 + 3 + …… + n = n^2/2 + n /2
由大O渐表示法可得,最坏的情况的时间复杂度为:O(N^2)。
值得注意的是,上面的for循环是第几次进入,所以计算循环次数即为每进入一次for循环后,进行的while循环个数。
最好的情况:当我们要排序升序时,初始数组是升序或者接近升序;当我们要排序降序时,初始数组是降序或者是接近降序。
此时,我们的每趟排序的调整次数都是0或者接近于都是0,即while循环大多数都是进入,然后直接break出来,即接近于都是循环1次。

循环次数:n次。
由大O渐表示法可得,最好的情况的时间复杂度是:O(N)。
值得注意的是,上面的for循环是第几次进入,所以计算循环次数即为每进入一次for循环后,进行的while循环个数。
由时间复杂度和空间复杂度(以题目的方式来介绍和分析)的文章可以得知,时间复杂度都是按最坏的情况,所以直接插入排序的时间复杂度是:O(N^2)。
直接插入排序的空间复杂度分析
由于直接插入排序的开辟的空间为常量级,所以空间复杂度为O(1)。
直接插入排序的稳定性分析
稳定性:稳定。
原因如下:我们在排序数组时,可以让数字在比对的过程中,如果相等就不要替换,直接插入到该数字的后面的位置,保证该排序的稳定性。
如:1 2 3 2
第一次调整,1 2 2 3 后
两个数字2相等,但是我们不要进行交换,保证直接插入排序算法的稳定性。
总结:
直接插入排序中:
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:稳定
2.希尔排序
希尔排序跟直接插入排序相比,增加了一个预排序的过程,来达到优化直接插入排序的效果。
在预排序中,增加了一个gap值,这个gap值是用来分组的。如下:
假设一个数组有10个元素,我们要排为升序,gap值为4,那么相同组中的元素,中间隔4个其他组的元素,如下图:
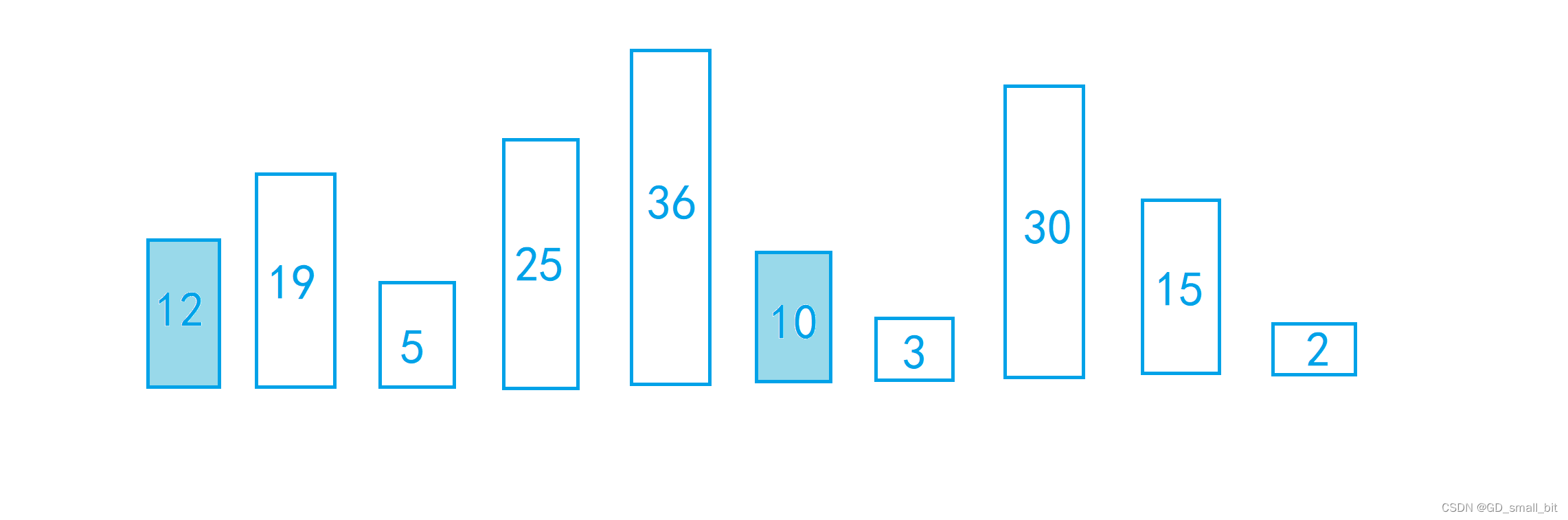
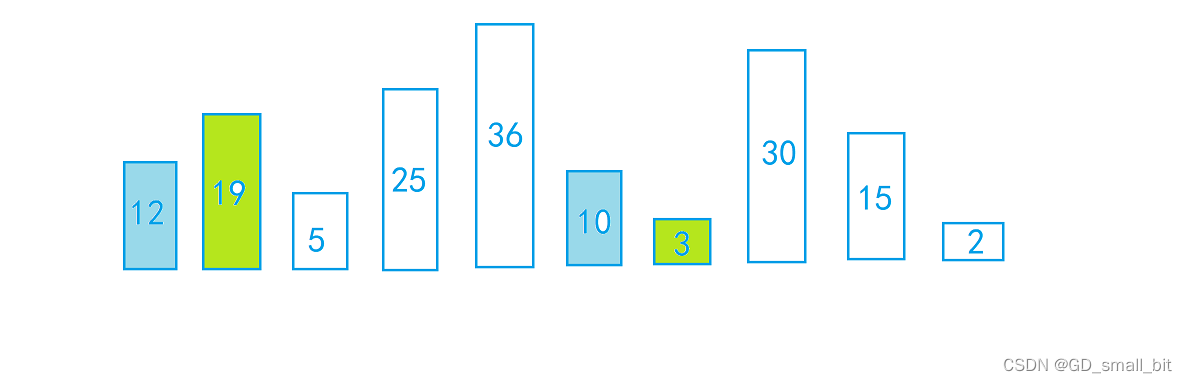

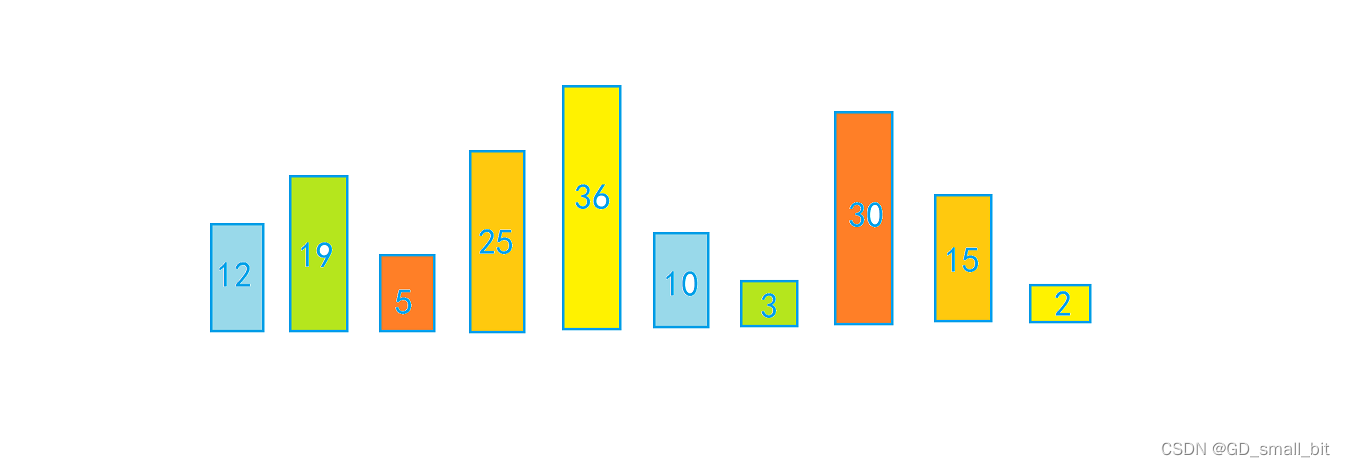
上面的图片就已经是分组完成的了,那么分组有什么用呢?接下来,我来解答这个问题。
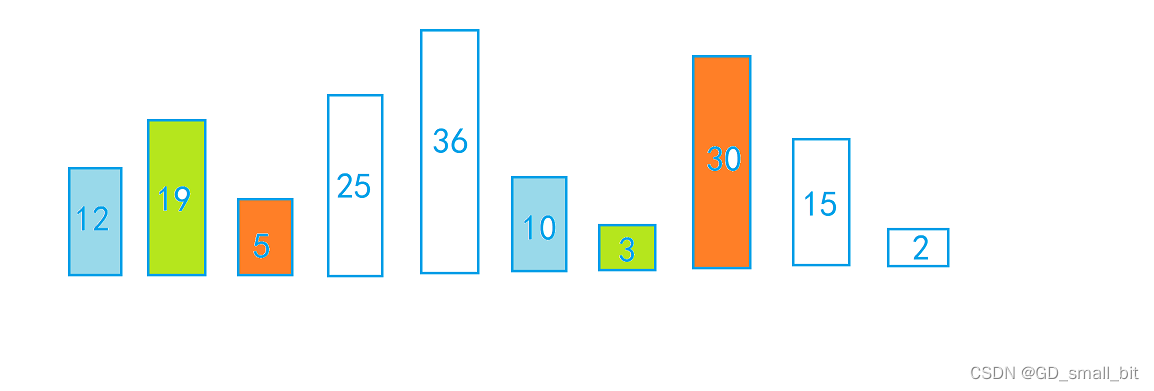
在上面的分组完成的图片中,我们可以确定有5组,每组有2个元素,那么在比对的过程中,我们只让组中元素进行比对,比如蓝色组只在蓝色组内比较,红色组只在红色组内比较,如下图:
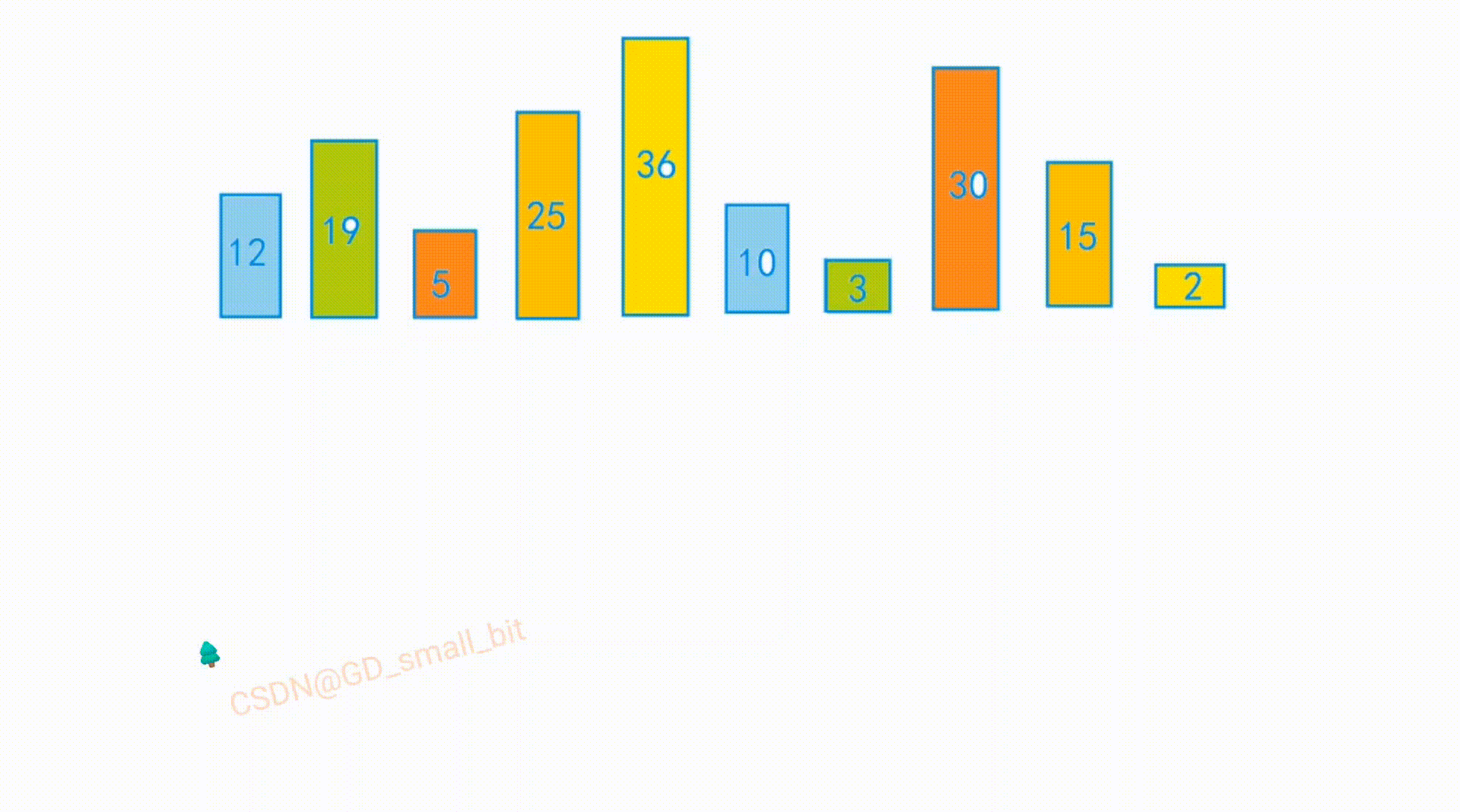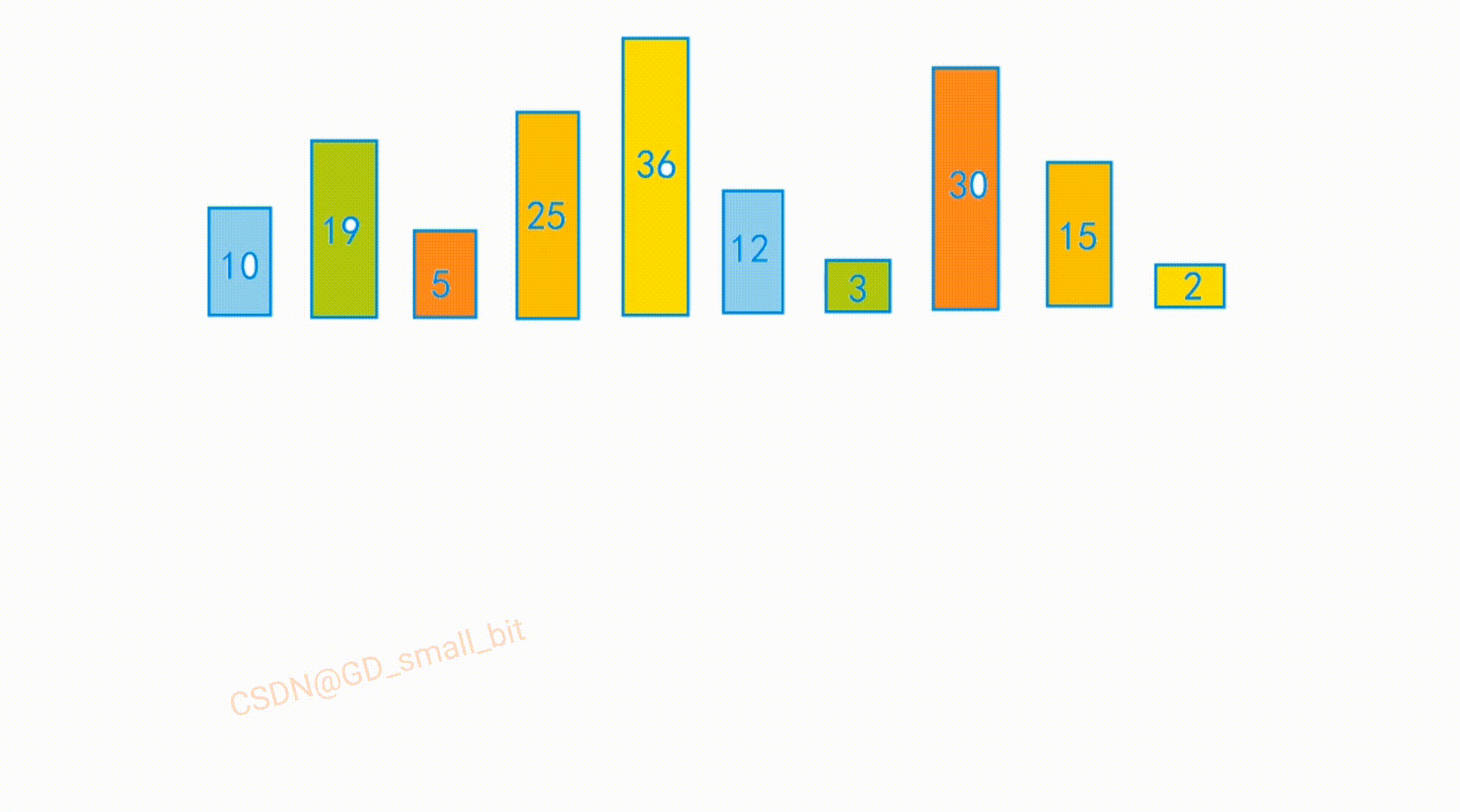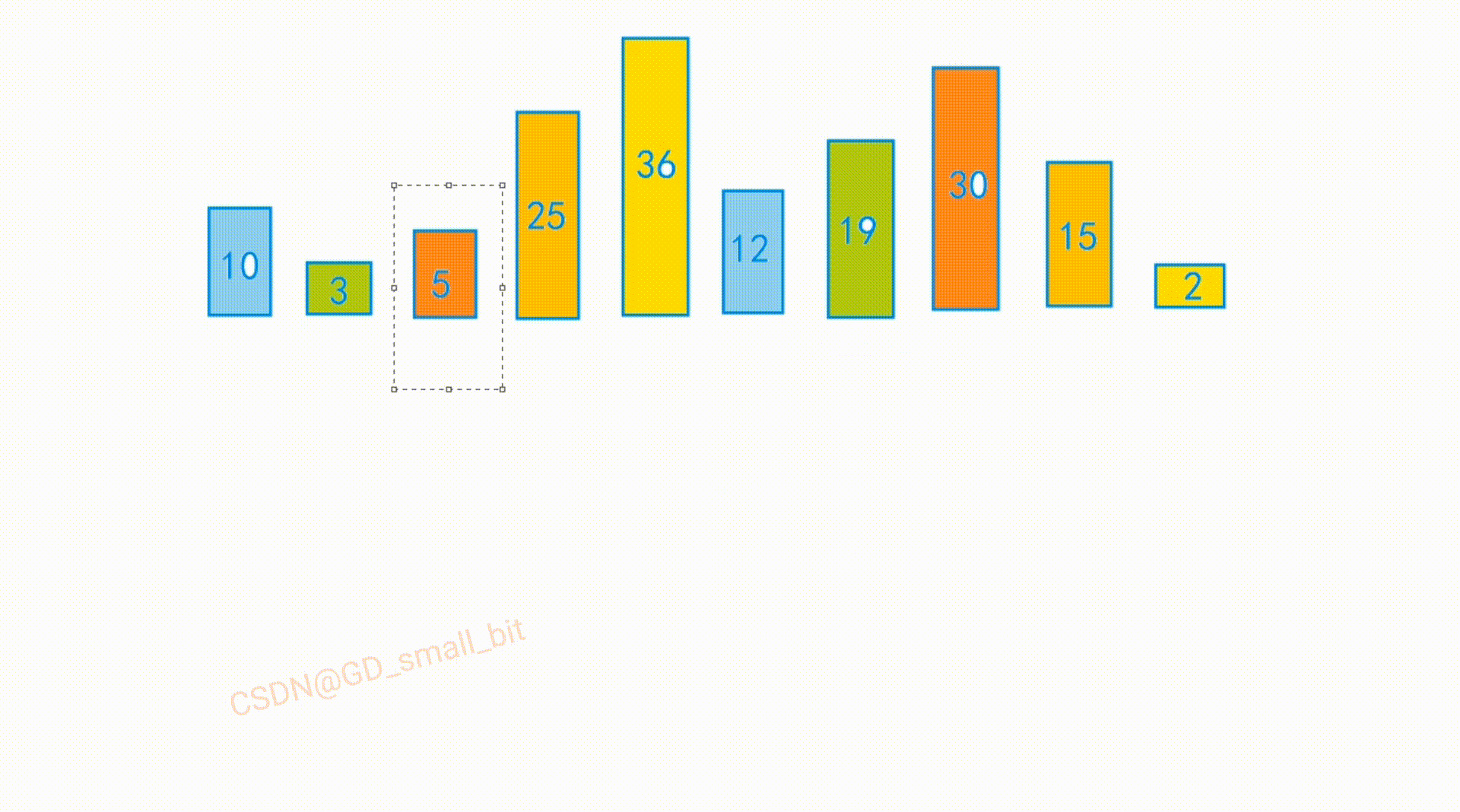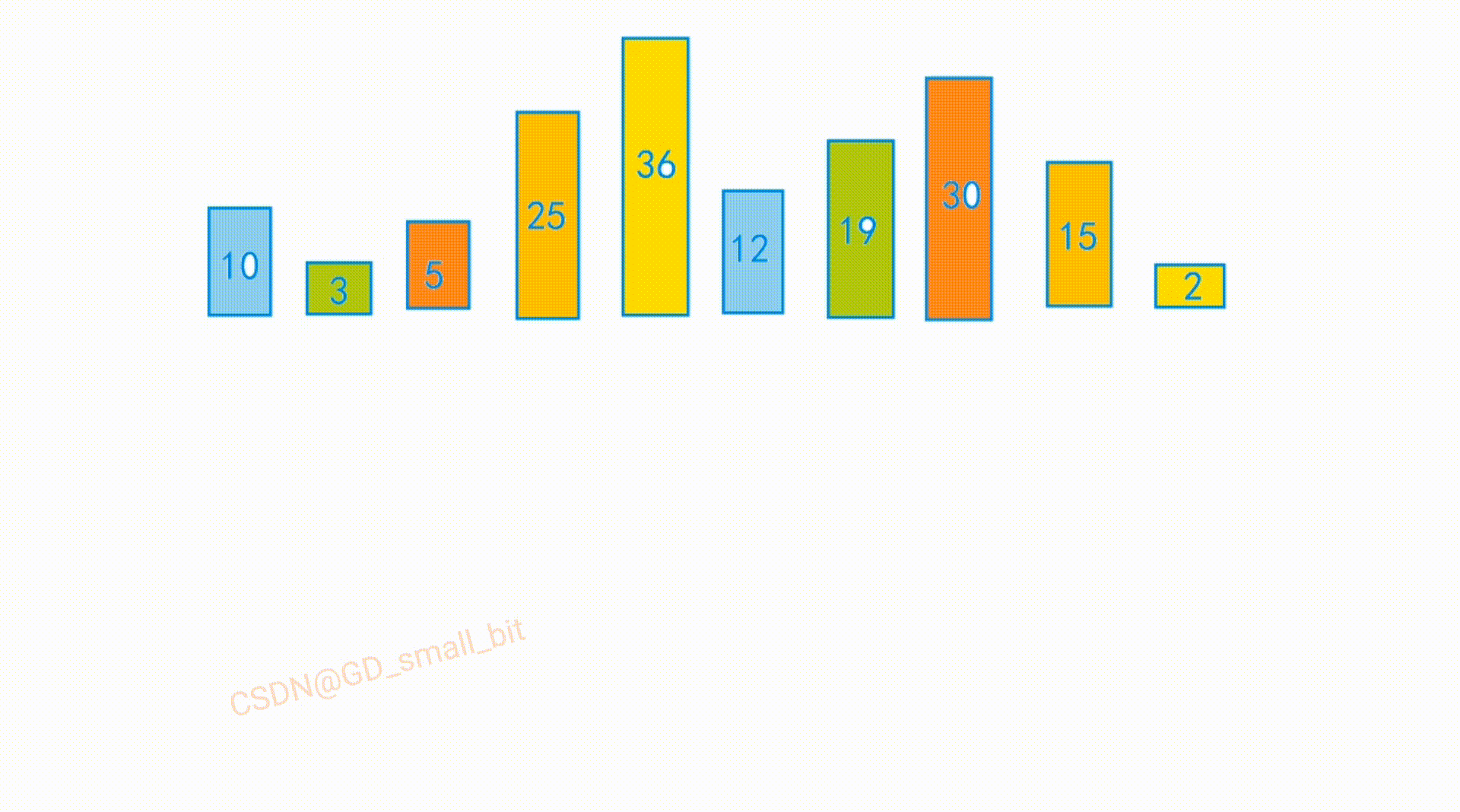
那么,我们什么时候比对完成呢,毫无疑问,当比对掉所有的组,即比对完黄色的那一组,我们就已经比对完了。
比对完的结果如下:
在此次的预排序中,我们让大的元素一下跳跃几步到后面,小的元素一下跳跃几步到前面,最典型的还是数值2和数值3,只一步就跳到了前面。为直接插入排序做好了准备,防止某些元素在直接插入排序中,移动过多,拉低了整体排序的效率。
上面的讲解中,我们已经知道了预排序的gap是用来分组的,并且搞懂了是如何分组的,还有知道了是在组内元素进行比对的,还有搞懂了预排序中组内比对的好处。
接下来,我们就要搞懂gap的整个取值过程。
在最开始的过程中,gap初始化为n(数组元素个数),注意初始化后是为了公式求值,而不是gap的第一次值就是n。
接下来,gap = gap / 3 + 1
每取到一个gap值,就进行一次分组,组内比对,比对完,按公式改变gap的值,直到gap的值为1时,预排序结束,直接插入排序开始,这就是希尔排序的过程。
以下是动图
代码如下:
#include<stdio.h>
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap > 1)//当gap等于2进入循环,就可以取到1了,循环条件改为大于等于1,会死循环
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)//当gap为1时,n - gap的值是n - 1,满足后面的直接插入排序对i的要求
{
int end = i;
int tmp = arr[end + gap];
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}
int main()
{
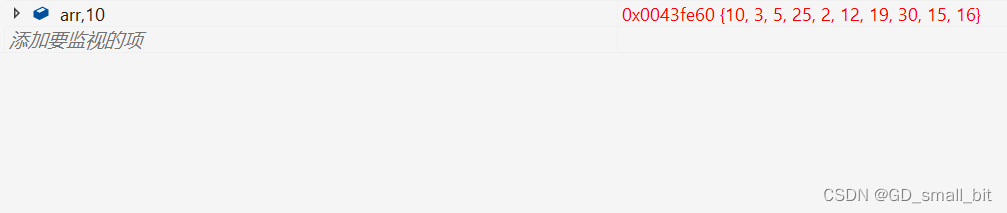
int arr[] = {10,3,5,25,2,12,19,30,15,16};
ShellSort(arr,sizeof(arr)/sizeof(arr[0]));
return 0;
}
排序前:

排序后:

希尔排序的时间复杂度分析
希尔排序的时间复杂度的分析较为困难,下面截至一本书。
《数据结构(C语言版)》— 严蔚敏

在希尔排序的时间复杂度分析中,还进行了大量的实验,我们直接记住结论就行。
希尔排序的时间复杂度:O(N^1.3)。
希尔排序的空间复杂度分析
由于希尔排序开辟的空间是常量级的,所以希尔排序的时间复杂度是:O(1)。
希尔排序的稳定性
由于在预排序中,相同的数字可能不在同一组中,那么进行组内交换时可能会改变相同数字的位置,所以希尔排序是不稳定的。
希尔排序的稳定性:不稳定。
总结:
希尔排序中:
时间复杂度:O(N^1.3)
空间复杂度:O(1)
稳定性:不稳定
选择排序
1.直接选择排序
直接选择排序是查找到序列中最小的值和最大的值,然后如果要排序升序的话,就将最小值和第一个元素交换,将最大值和最后一个元素交换。然后排除掉第一个元素和最后一个元素,继续寻找最小值和最大值,分别与第二个元素和倒数第二个元素进行交换,依次下去,直到数组有序。
比如,我要在一个数组中排序为升序,并且排序为升序,该数组的长度为n。(我们采用begin和end来表示需要排序的范围,比如最开始时,begin等于0,end等于数组元素减一,排序范围为全部的元素,当进行第一趟排序后,begin等于1,end等于n-2,排序掉第一个元素和倒数第一个元素)
下面是动图
下面是代码实现:
void swap(int* a,int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void SelectSort(int* arr,int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int Mini = begin, Maxi = end;
for (int i = begin; i <= end; i++)
{
if (arr[i] < arr[Mini])
{
Mini = i;
}
if (arr[i] > arr[Maxi])
{
Maxi = i;
}
}
swap(&arr[begin],&arr[Mini]);
if (begin == Maxi) //调整,最大值因为上面的交换由begin下标所在的位置变为了Minx下标所在的位置
Maxi = Mini;
swap(&arr[Maxi],&arr[end]);
begin++;
end--;
}
}
int main()
{
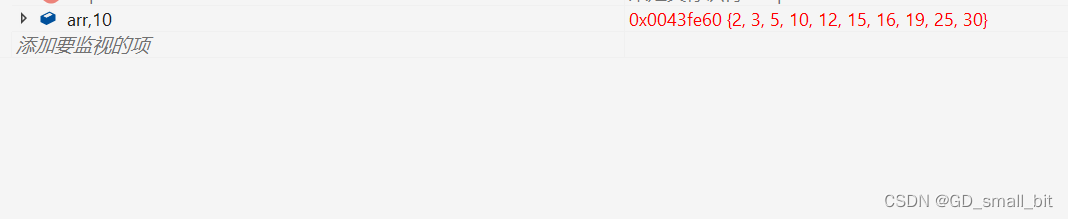
int arr[] = { 10,3,5,25,2,12,19,30,15,16 };
SelectSort(arr, sizeof(arr) / sizeof(arr[0]));
return 0;
}
排序前:
排序后:
直接选择排序的时间复杂度分析
观察代码可以得知,有两层循环,但是我们不能认为认为两层循环,该排序的时间复杂度就是:O(N^2),有时候结果不是这样。
假设排序数组中,数组的元素个数是n。
第一趟排序中,begin的值为0,end的值为n-1,那么在寻找最大值和最小值的比较次数是n。
第二趟排序中,begin的值为1,end的值为n-2,那么在寻找最大值和最小值的比较次数是n-2。
第三趟排序中,begin的值为2,end的值为n-3,那么在寻找最大值和最小值的比较次数是n-4。
……
第n/2趟排序中,begin的值为n/2-1,end的值为n/2,那么在寻找最大值和最小值的比较次数是2。
第几趟排序即为代码中while循环中的第几次循环,比较次数即为for循环的第几次循环。

所以总共循环(比较)n + (n-2)+ (n-4) + …… + 1 = n^2
直接选择排序的时间复杂度是:O(N^2)。
直接选择排序的空间复杂度
直接选择排序开辟的空间为常量级,所以直接选择排序的空间复杂度是:O(1)。
直接选择排序的稳定性
直接选择排序的稳定性:不稳定。因为在选择最值时,直接往begin或者end位置替换的时候,会打乱相同数值的顺序。
比如:1 4 4 3排序升序,在第一趟的排序中,4做为从左往右找到的第一个最大值,直接与end位置交换,即与3进行交换,结果为1 3 4 4,那么,两个数字4的位置就乱了。
总结:
直接选择排序中:
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:不稳定
2.堆排序
在堆排序中,我们首先要进行建堆,建堆算法在前面的文章中我已经进行分析了,下面是传送门。
<<数据结构>>向上调整建堆和向下调整建堆的分析(特殊情况,时间复杂度分析,两种建堆方法对比,动图)
在上面的文章中,我已经对向上建堆和向下建堆进行了对比,所以,在这里的堆排序中的建堆算法,我选择向下调整建堆。
排序升序,建大堆
排序降序,建小堆
如果我们要对一个数组进行堆排序,将这个数组排为了升序,那么我们应该先建为大堆,此时,堆顶就是最大的元素,我们将堆顶的元素与堆尾部的元素交换,然后排除掉堆尾部,重新调整堆,此时,这个堆最大的元素就在后面了,持续下去。在这种方法下,大的元素将一直往后面移动,直到把所有的元素排序完成。
同理,如果我们要对一个数组进行堆排序,将这个数组排为了降序,那么我们应该先建为小堆,此时,堆顶就是最小的元素,我们将堆顶的元素与堆尾部的元素交换,然后排除掉堆尾部,重新调整堆,此时,这个堆最小的元素就在后面了,持续下去。在这种方法下,小的元素将一直往后面移动,直到把所有的元素排序完成。
下面,我以排序升序为例子。
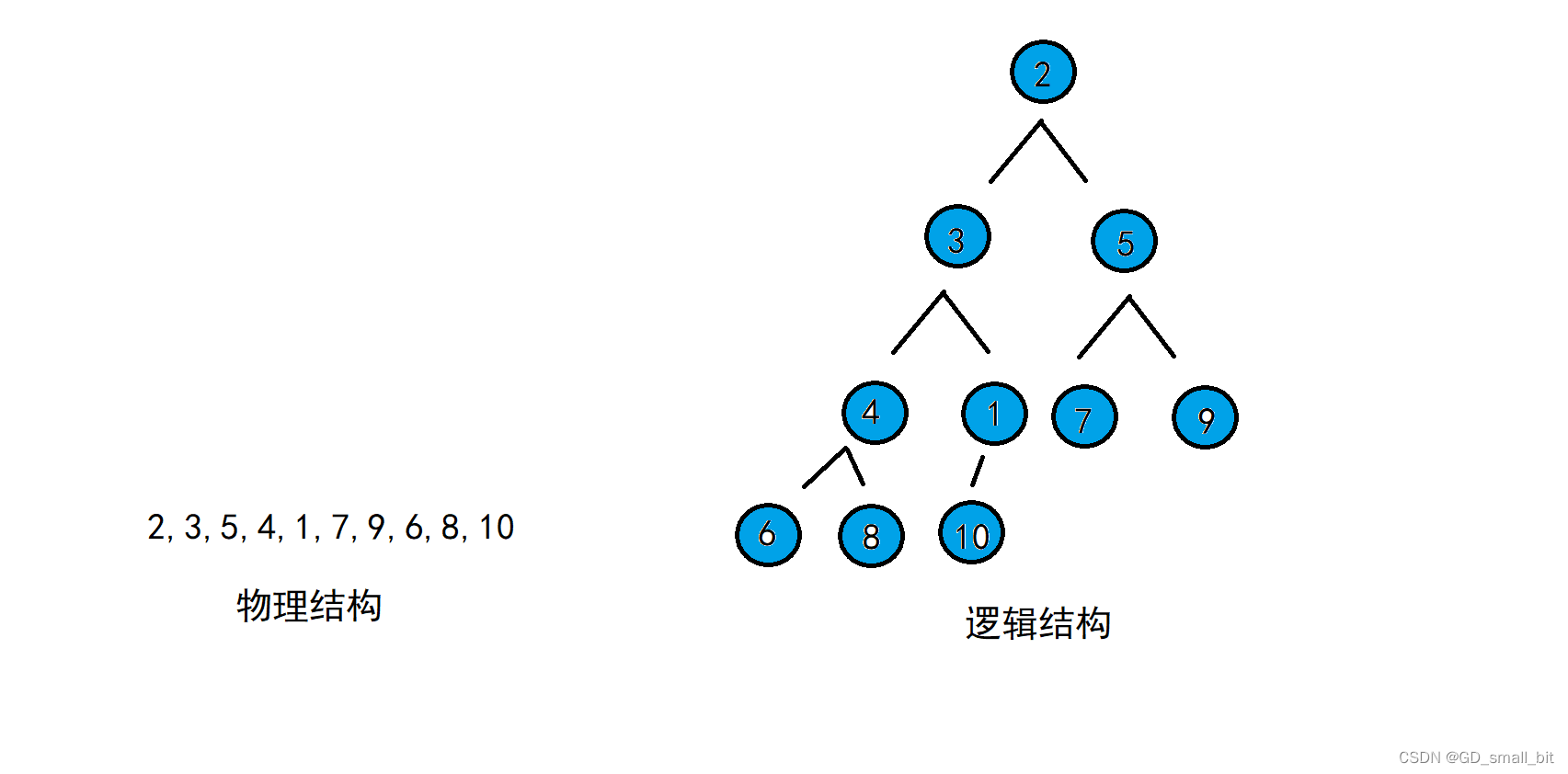
如上面数组中,我将该数组排为升序(采用向下建堆),下面是动图
下面是代码:
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//向下调整
void AdjustDown(int* arr, int n ,int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && arr[child + 1] > arr[child])//注意child + 1 < n
{
child++;
}
if (arr[child] > arr[parent])
{
swap(&arr[child],&arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* arr, int n)
{
//向下建堆算法
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr,n,i);
}
int end = n - 1;
while (end > 0)
{
swap(&arr[0],&arr[end]);
AdjustDown(arr,end,0);
end--;
}
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
HeapSort(arr, sizeof(arr) / sizeof(arr[0]));
return 0;
}
排序前:

排序后:

堆排序的时间复杂度

可能有人认为,有的结点调整的高度次数远小于我们所计算的高度次数,导致计算结果过大,但是,时间复杂度本身就不是一个准确的计算,如大O渐进表示法就规定省略一些计算表达式中的细节。
堆排序的空间复杂度
堆排序开辟的空间为常量级,所以空间复杂度是:O(1)。
堆排序的稳定性
不稳定,堆顶和堆底元素交换,向下调整,这些都可能打乱相同数字的顺序。
总结:
堆排序中:
时间复杂度为:O(N*logN)
空间复杂度为:O(1)
稳定性:不稳定
交换排序
1.冒泡排序
冒泡排序是我们在编程学习中的老相识了,我就直接上动图了,如果还是不熟悉的,可以看看这篇文章,下面是传送门
冒泡排序(详细)
如果感觉可以的话,那么就直接往下看吧。
下面是动图。
下面是代码:
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void BubbleSort(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
swap(&arr[j],&arr[j + 1]);
}
}
}
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
BubbleSort(arr, sizeof(arr) / sizeof(arr[0]));
return 0;
}
排序前:

排序后:

如果需要代码注释,可前往上面冒泡排序的传送门,那篇文章有详细的代码注释。
冒泡排序的时间复杂度

循环次数满足等差数列,总共循环(n-1) + (n-2) + (n-3) + … + 2 + 1 = (n^2 + n) / 2
由大O渐进表示法可得,冒泡排序的时间复杂度是:O(N^2)。
冒泡排序的空间复杂度
由于冒泡排序开辟的空间为常量级,所以冒泡排序的空间复杂度是:O(1)。
冒泡排序的稳定性
稳定,因为我们可以控制在比对的过程中,如果两个数相等,就不交换它们的位置,来保证相同数字的位置不会变换。
总结:
冒泡排序中:
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:稳定
2.快速排序
快速排序的知识点还是相对比较多的,它有三个版本,分别是hoare版本,挖坑法,前后指针法,并且我们还需要掌握它的非递归版本,并且还有三种优化方法,分别是三数取中,小区间优化,三目并排。
不着急,我依次深入地进行讲解。
2.1 hoare版本
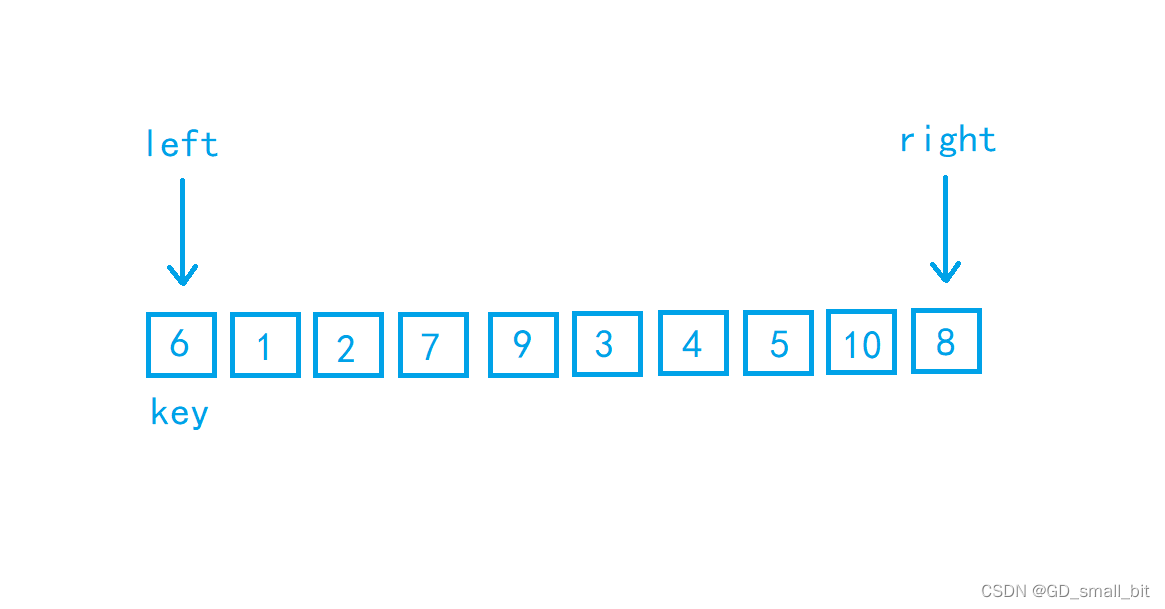
上面就是快速排序的hoare版本的准备阶段。
left和right是用来遍历数组的,left要找到比key大的数,如果找到就停下来,right要找比key小的数,如果找到也要停下来,此时交换left和right指向的值,接下来,left和right重复以上动作,直到相遇,这时,将key的值与left和right相遇的点进行交换,此时,key的值就排序到了正确的位置,以key为中点,分成左右数组,分别在左右数组中重复以上动作。
key可以选择最左边的数或者最右边的数,如果key选择最左边的数,那么right先走;如果key选择最右边的数,那么left先走。
因为分成左右数组再进行排序,采用的是递归,所以下面动图我以递归逻辑展示。
动图前的准备:

结果图:
下面是代码:
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void QuickSort(int* arr, int begin, int end)
{
if (begin >= end)
return;
int keyi = begin; //单趟
int left = begin, right = end;
while (left < right)
{
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
swap(&arr[left],&arr[right]);
}
swap(&arr[keyi],&arr[left]);
keyi = left;
QuickSort(arr,begin,keyi - 1);//分左右数组
QuickSort(arr,keyi + 1,end);
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr,0,sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:
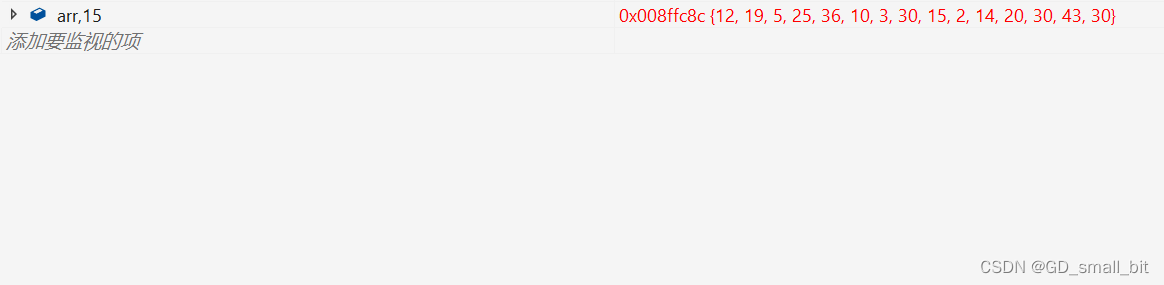
排序后:
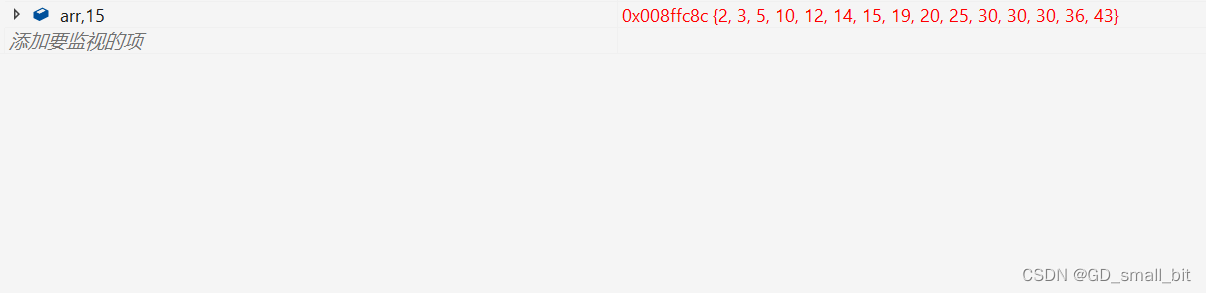
2.2 挖坑法
快速排序挖坑法相比hoare版本,只是多找了个空间去存储着key,然后将原本存储key的值的地方作为第一个坑,然后left依然寻找比key大的值,right去寻找key小的值,再依次进行填坑,最后将key的值存储到left和right相遇的地方。
下面直接看动图

结果图:
动图中间有一句left寻找比key小的值,应该改为寻找比key大的值(这句话的字体较大,就出现一次)
下面是代码:
void QuickSort(int* arr,int begin,int end)
{
if (begin >= end)
return;
int left = begin, right = end;
int hole = begin, keyi = arr[hole];
while (left < right) //单趟
{
while (left < right && arr[right] >= keyi)
{
right--;
}
arr[hole] = arr[right];
hole = right;
while (left < right && arr[left] <= keyi)
{
left++;
}
arr[hole] = arr[left];
hole = left;
}
arr[hole] = keyi;
QuickSort(arr,begin,hole - 1);
QuickSort(arr,hole + 1,end);//分为左右数组
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr,0,sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:
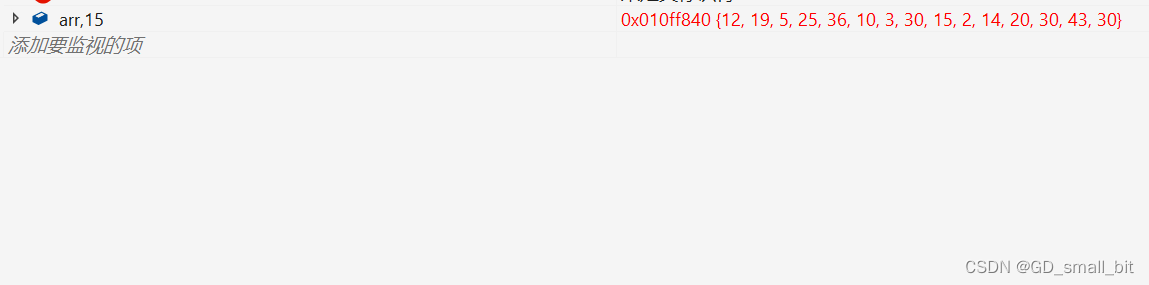
排序后:

2.3 前后指针版本
在这个版本,我们选择最左边的元素为key,然后最左边的元素还作为prev,第二个元素作为cur,cur往后找比prev小的元素,如果找到了就停下来,将prev加加一下,再交换prev和cur的值,循环下去,直到cur把所有的元素都遍历完,此时不移动prev的位置,交换key和prev的值,单趟排序结束,分为左右数组,再进行相应的操作。
动图

结果图:
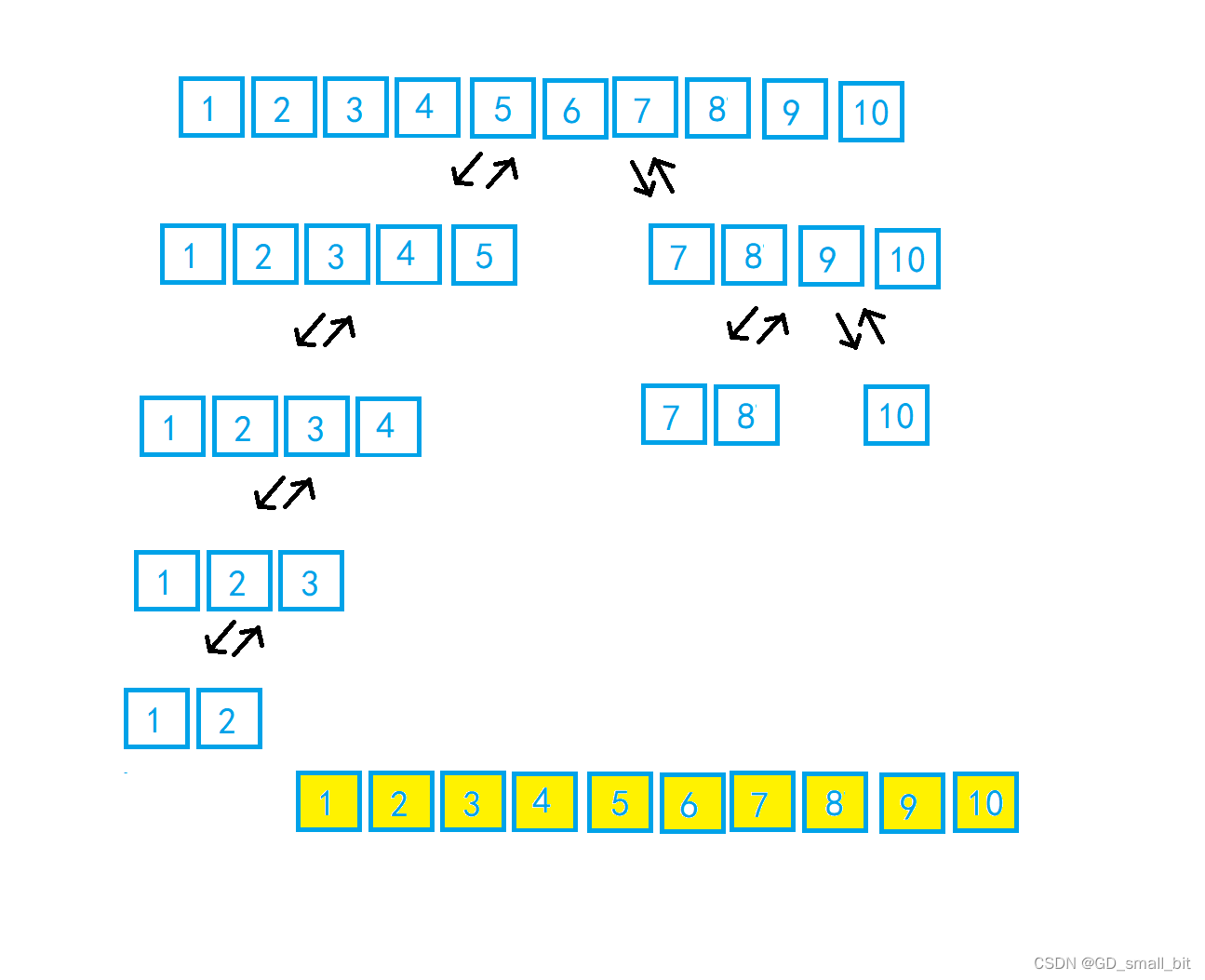
下面是代码:
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void QuickSort(int* arr, int begin, int end)
{
if (begin >= end)
return;
int keyi = begin;
int prev = begin, cur = prev + 1;
while (cur <= end)
{ //++prev指向的值与cur指向的值相等,不交换,提升效率
if(arr[cur] < arr[keyi] && ++prev != cur)//cur指向的值小于keyi指向的值,停下来,交换cur指向的值和prev指向的值
{
swap(&arr[prev],&arr[cur]);
}
cur++; //cur一直往后走
}
swap(&arr[keyi],&arr[prev]);//cur遍历完数组,keyi指向的值和prev指向的值进行交换
keyi = prev;
QuickSort(arr,begin,keyi - 1);
QuickSort(arr,keyi + 1,end);
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:

排序后:

2.4 三数取中优化和小区间优化
2.4.1 三数取中优化
如果是没有加入三数取中优化,那么快排在应对有序数组时,排序速度将大大降低,下面我来解释一下。
假设快排中,每趟key都是中间插入的话,那么就有下图的情况。
由于每一趟递归中,left和right分别从左右两端开始遍历数组,那么,实际上,遍历的元素个数是N。递归的深度是以2为底,N的对数,而且每一层遍历的元素个数是N(差值可忽略),所以时间复杂度为两者的乘积,即时间复杂度是:O(N*logN)。
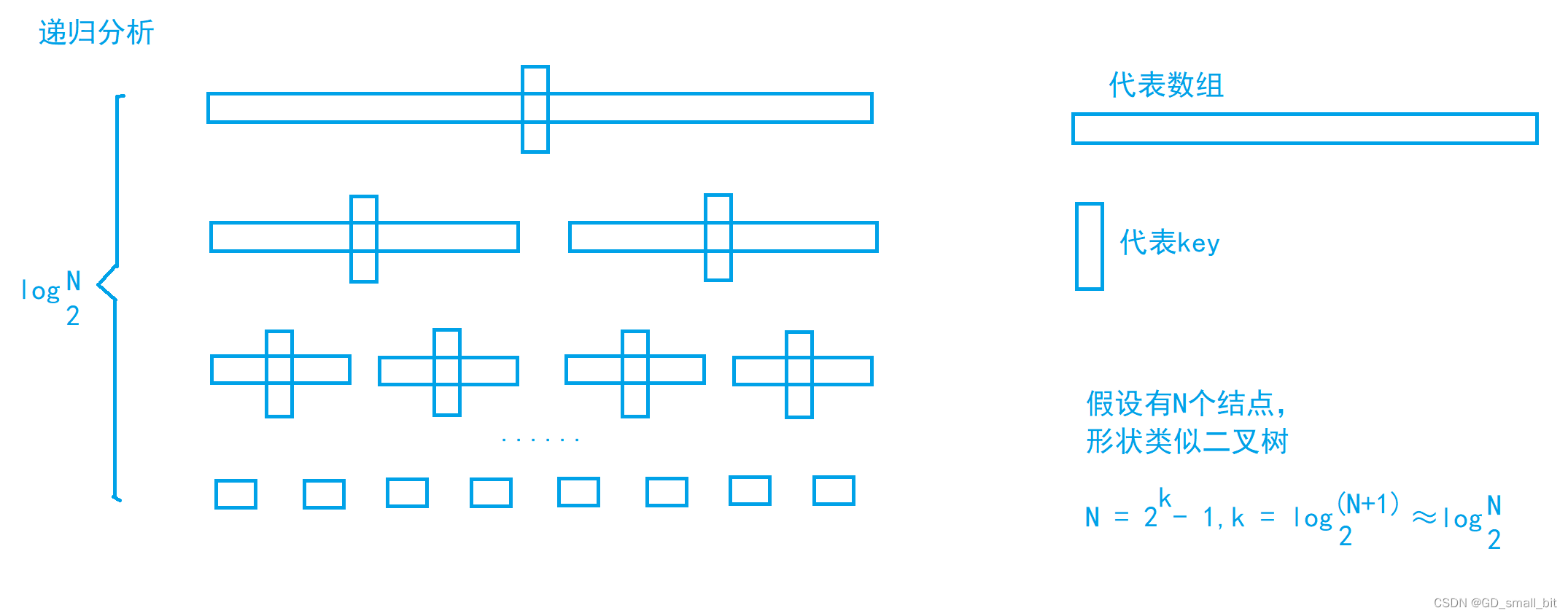
假设在有序或者接近有序的话,key每次的选取都是最大值或者最小值,那么会出现以下的情况。
遍历的元素满足等差数列,N + (N - 1) + (N - 2) + (N - 3) + … + 2 + 1 = n(n+1)/2,所以时间复杂度是:O(N^2)。这里的快速排序的时间复杂度竟然赶上了冒泡排序。
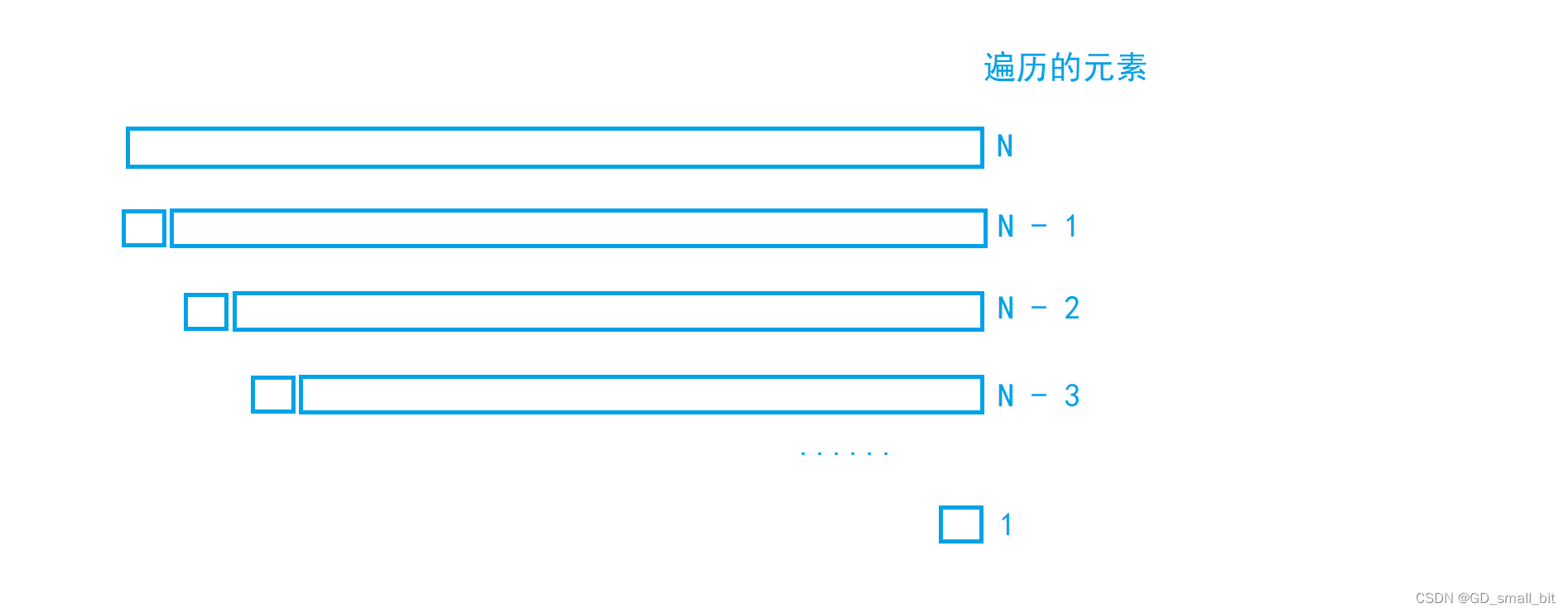
三数取中就是为了应对有序数组和接近有序数组而出现的,它是对最左边、最右边、最中间的三个值进行比对,排除掉最大值和最小值,选择了中间的那个数作为key,在三数取中优化下,上面快排的时间复杂度是O(N^2)的情况就不会出现了。
在有些三数取中的代码下,并不是直接取最左边、最右边、最中间的值,而是取最左边、随机位置、最右边的三个值来进行比对,排除最大值、最小值,选择中间的那个值作为key。
下面是三数取中的代码:
int GetMidIndex(int* arr, int begin, int end)
{
int mid = (begin + end) / 2; //选最左边、最中间、最右边的值
//int mid = begin + rand()%(end - begin); //选最左边、随机位置、最右边的值
if (arr[mid] < arr[begin])
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[end] > arr[begin])
{
return begin;
}
else
{
return end;
}
}
else //arr[mid] > arr[begin]
{
if (arr[begin] > arr[end])
{
return begin;
}
else if (arr[mid] < arr[end])
{
return mid;
}
else
{
return end;
}
}
}
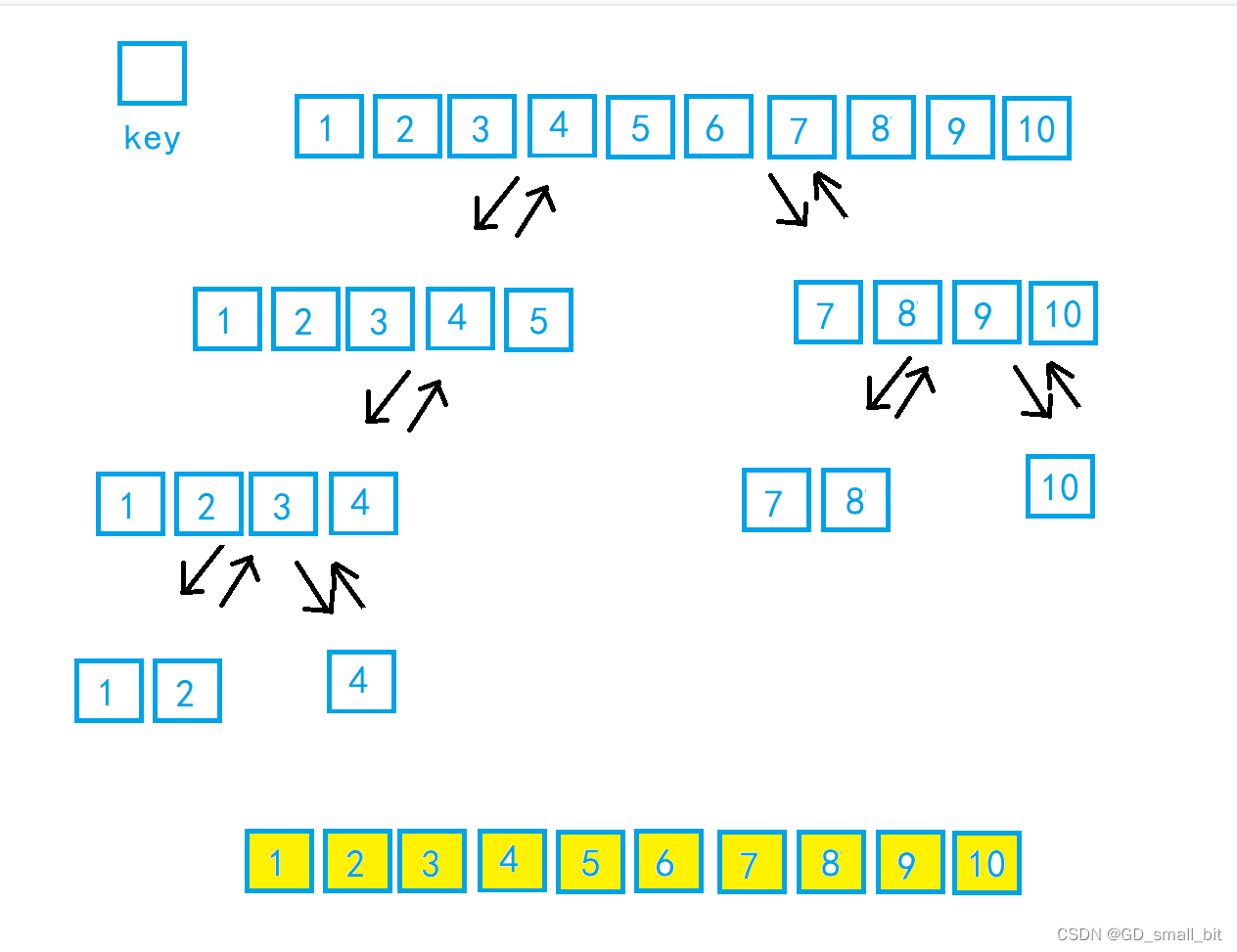
2.4.2 小区间优化
我以一个等边三角形来表示每一层的递归调用次数。
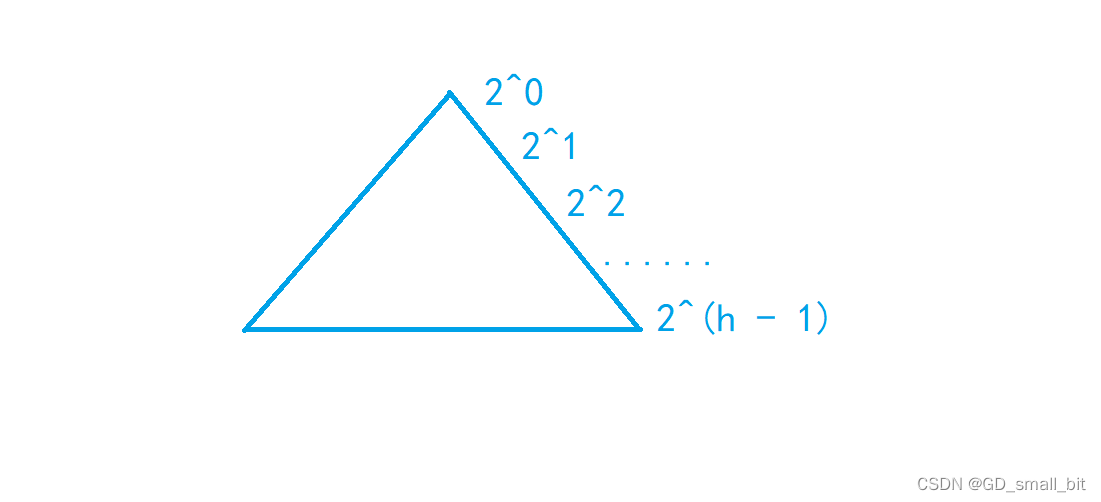
如下图,当在最后几层的递归调用中,数组需要排序的已经没有多少了(可以看上面动图),此时,如果我们省取最后几层的递归调用的话,就可以节省大把的排序的程序运行时间,即使只是省取最后一层递归调用的话,也可以省去2^(h - 1)次,可想这个优化的力度有多大。
那么我们省去了最后第几层递归调用的话,数组的有些元素还没有排序,我们应该怎么办呢?这时,我们可以采用插入排序。小区间优化的代码实现我在下面快排的各个版本中进行应用。
2.4.3 含三数取中优化和小区间优化的hoare版本的代码
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Insertsort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if(arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
int GetMidIndex(int* arr, int begin, int end)
{
int mid = (begin + end) / 2; //选最左边、最中间、最右边的值
//int mid = begin + rand()%(end - begin); //选最左边、随机位置、最右边的值
if (arr[mid] < arr[begin])
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[end] > arr[begin])
{
return begin;
}
else
{
return end;
}
}
else //arr[mid] > arr[begin]
{
if (arr[begin] > arr[end])
{
return begin;
}
else if (arr[mid] < arr[end])
{
return mid;
}
else
{
return end;
}
}
}
void QuickSort(int* arr, int begin, int end)
{
if (end - begin + 1 < 15) //闭区间[begin,right],相减后要加1
{
Insertsort(arr + begin,end - begin + 1);
}
else
{
int mid = GetMidIndex(arr, begin, end);
swap(&arr[mid],&arr[begin]);
int keyi = begin;
int left = begin, right = end;
while (left < right)
{
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
swap(&arr[left],&arr[right]);
}
swap(&arr[keyi], &arr[left]);
keyi = left;
QuickSort(arr, begin, keyi - 1);
QuickSort(arr, keyi + 1, end);
}
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:
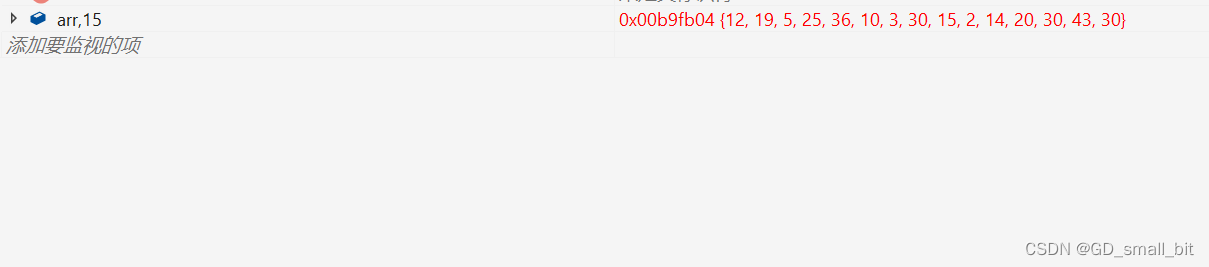
排序后:
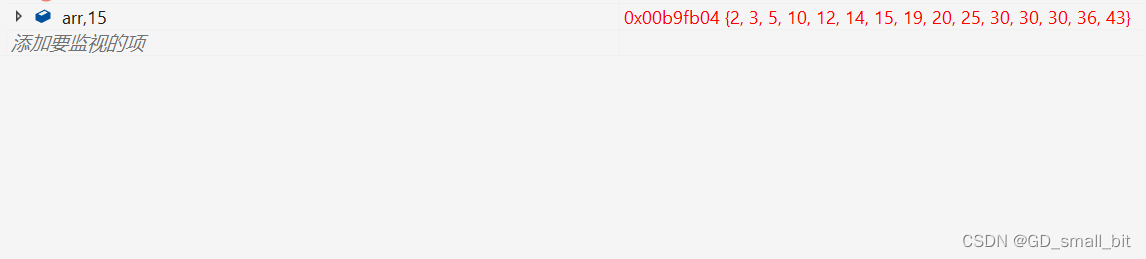
2.4.4 含三数取中优化和小区间优化的挖坑法版本的代码
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Insertsort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if(arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
int GetMidIndex(int* arr, int begin, int end)
{
int mid = (begin + end) / 2; //选最左边、最中间、最右边的值
//int mid = begin + rand()%(end - begin); //选最左边、随机位置、最右边的值
if (arr[mid] < arr[begin])
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[end] > arr[begin])
{
return begin;
}
else
{
return end;
}
}
else //arr[mid] > arr[begin]
{
if (arr[begin] > arr[end])
{
return begin;
}
else if (arr[mid] < arr[end])
{
return mid;
}
else
{
return end;
}
}
}
void QuickSort(int* arr, int begin, int end)
{
if (end - begin + 1 < 15) //闭区间[begin,right],相减后要加1
{
Insertsort(arr + begin,end - begin + 1);
}
else
{
int mid = GetMidIndex(arr, begin, end);
swap(&arr[begin],&arr[mid]);
int hole = begin, key = arr[hole];
int left = begin, right = end;
while (left < right)
{
while (left < right && arr[right] >= key)
{
right--;
}
arr[hole] = arr[right];
hole = right;
while(left < right && arr[left] <= key)
{
left++;
}
arr[hole] = arr[left];
hole = left;
}
arr[hole] = key;
QuickSort(arr, begin, hole - 1);
QuickSort(arr, hole + 1,end);
}
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:

排序后:
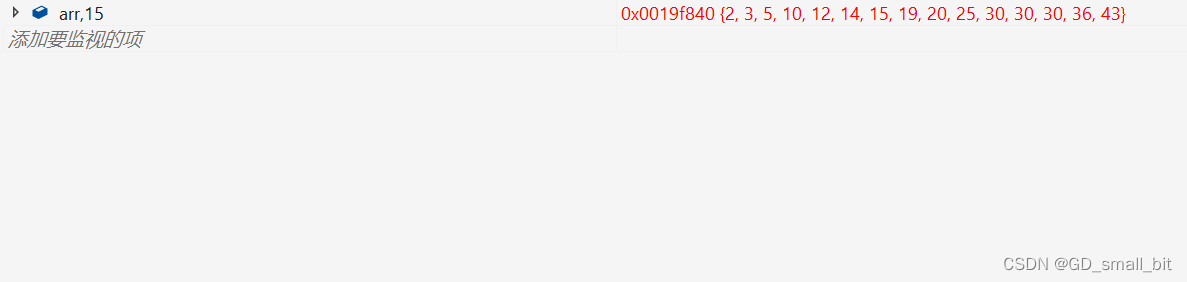
2.4.5 含三数取中优化和小区间优化的前后指针版本的代码
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Insertsort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if(arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
int GetMidIndex(int* arr, int begin, int end)
{
int mid = (begin + end) / 2; //选最左边、最中间、最右边的值
//int mid = begin + rand()%(end - begin); //选最左边、随机位置、最右边的值
if (arr[mid] < arr[begin])
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[end] > arr[begin])
{
return begin;
}
else
{
return end;
}
}
else //arr[mid] > arr[begin]
{
if (arr[begin] > arr[end])
{
return begin;
}
else if (arr[mid] < arr[end])
{
return mid;
}
else
{
return end;
}
}
}
void QuickSort(int* arr, int begin, int end)
{
if (end - begin + 1 < 15) //闭区间[begin,right],相减后要加1
{
Insertsort(arr + begin,end - begin + 1);
}
else
{
int mid = GetMidIndex(arr,begin,end);
swap(&arr[begin],&arr[mid]);
int keyi = begin;
int prev = begin, cur = begin + 1;
while (cur <= end)
{
if (arr[cur] < arr[keyi] && ++prev != cur)
{
swap(&arr[prev],&arr[cur]);
}
cur++;
}
swap(&arr[keyi],&arr[prev]);
keyi = prev;
QuickSort(arr,begin,keyi - 1);
QuickSort(arr,keyi + 1,end);
}
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:
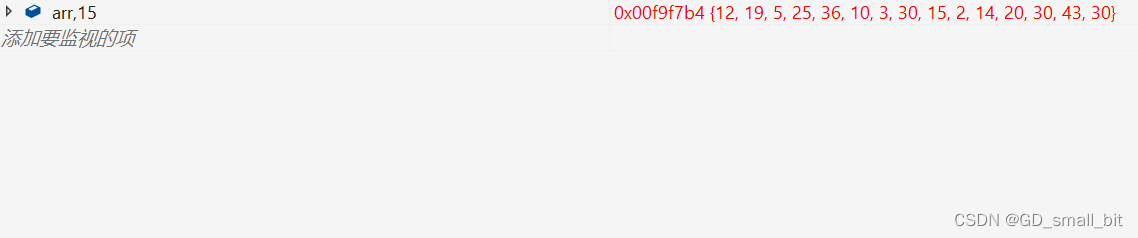
排序后:
2.5 快速排序非递归版本
在快速排序的非递归版本中,我们需要利用栈的性质来辅助排序,如下:
由于在C语言中,并没有栈,所以还需要自己写一个栈的代码,代码较多,我直接发在代码库,直接前往代码库进行观看,快速排序的三个版本的非递归都在那里。
快速排序非递归版本
2.6 快速排序优化之三目并排
在三数取中的优化下,快速排序对于有序或者接近有序的特殊情况也不会降低太大的效率,但是在排序存在大量重复数据的数组下,还是存在问题。如何证明呢?
在力扣就有一个排序题,在这条排序题中就有一个测试用例是对一个含有大量重复数据的数组进行排序,我先用三数取中和小区间优化的hoare版本进行测试,看看能不能通过测试用例。下面是该题目的传送门。
排序数组
如下图,调用三数取中和小区间优化的hoare版本,三数取中和小区间优化的hoare版本的代码我就不截图出来,可以去文章上面查看。

运行结果:
通过全部测试用例,只不过总时间超过,那么我们可以对代码进行修改,再拉低一下速度,观察最后一个测试用例。但是,总时间不通过还是因为最后一个测试用例,不信看到后面。
修改如下:添加了方框里的内容
在未加入小区间优化时,上面方框的代码是用来控制递归的,让程序检测到数组的元素已经不用排序了时,就不再递归调用了,而现在有了小区间优化,在剩下几个元素时,就直接调用插入排序,而不再递归下去,那么这串代码就可以省去了。
运行结果和测试用例:

现在,我们可以清楚的发现,在最后一个测试用例中,含有大量的重复数据,导致排序效率大大降低。三目并排就是应对这种情况的。
那么三目并排是如何进行排序的呢?首先定义一个key,key的取值可以采用三数取中进行优化取值,然后left指向第一个元素,cur指向第二个元素,right指向最后一个元素,cur指向的值如果小于key时,交换cur指向的值和left指向的值,并且cur和left分别往后走一步;如果cur指向的值等于key时,cur往后走一步;如果cur指向的值大于key时,交换cur指向的值和right指向的值,right往前走一步,直到cur的位置在right的位置的后面,该趟排序结束,此时,相同的元素就集中在中间了,递归调用左右数组。
下面是动图:
动图前的准备:


下面是代码:
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Insertsort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
int GetMidIndex(int* arr, int begin, int end)
{
int mid = (begin + end) / 2; //选最左边、最中间、最右边的值
//int mid = begin + rand()%(end - begin); //选最左边、随机位置、最右边的值
if (arr[mid] < arr[begin])
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[end] > arr[begin])
{
return begin;
}
else
{
return end;
}
}
else //arr[mid] > arr[begin]
{
if (arr[begin] > arr[end])
{
return begin;
}
else if (arr[mid] < arr[end])
{
return mid;
}
else
{
return end;
}
}
}
void QuickSort(int* arr, int begin, int end)
{
if (end - begin + 1 < 15)
{
Insertsort(arr + begin, end - begin + 1);
}
else
{
int Mid = GetMidIndex(arr,begin,end);
swap(&arr[begin],&arr[Mid]);
int key = arr[begin];
int left = begin, cur = begin + 1, right = end;
while (cur <= right)
{
if (arr[cur] < key)
{
swap(&arr[left],&arr[cur]);
left++;
cur++;
}
else if (arr[cur] > key)
{
swap(&arr[cur],&arr[right]);
right--;
}
else
{
cur++;
}
}
//[begin,left-1][left,right][right+1,end]
QuickSort(arr,begin,left - 1);
QuickSort(arr,right + 1,end);
}
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
return 0;
}
排序前:
排序后:
将代码修改后,搬到那道题目试试。修改如下:
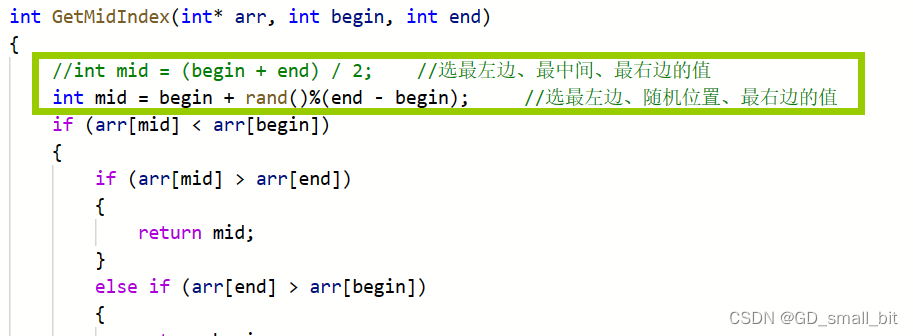
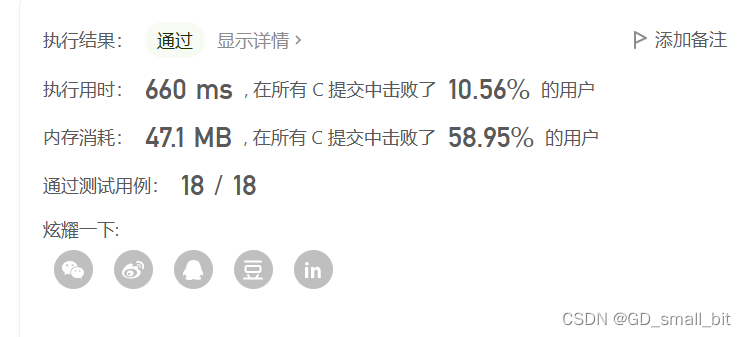
2.7 对于快速排序在秋招中的建议
快速排序的知识点还是多的,但是我还是建议要掌握全部的知识,为秋招做好准备,并且在我们的面试过程中,如果考到写一个快速排序,那么最先搬出的一定是不加三数取中优化和小区间优化的三个快排版本之一,至于要哪个版本,看个人喜好,以此来减少我们手写快速排序的时间,当面试官继续询问快排的优化时,再慢慢搬出各种的快排优化。
快速排序的时间复杂度
如果没有三数取中的优化下,快速排序的时间复杂度是:O(N^2),如果有三数取中的优化下,快速排序的时间复杂度是:O(N*logN)。(2.4 三数取中优化和小区间优化有讲过)
快速排序的空间复杂度
如果是递归的话,快速排序的空间复杂度是:O(logN)。因为快速排序中的开辟的空间是常量级的,并且递归调用的深度是:logN,所以递归的快速排序的空间复杂度是:O(1) * logN = O(logN)。(2.4 三数取中优化和小区间优化有讲过递归的高度)
如果是非递归的话,需要开辟栈,空间复杂度依然是:O(logN),因为压栈大小是logN。
快速排序的稳定性
不稳定。因为key最后都会替换到中间,这样可能会影响相同数字的顺序。
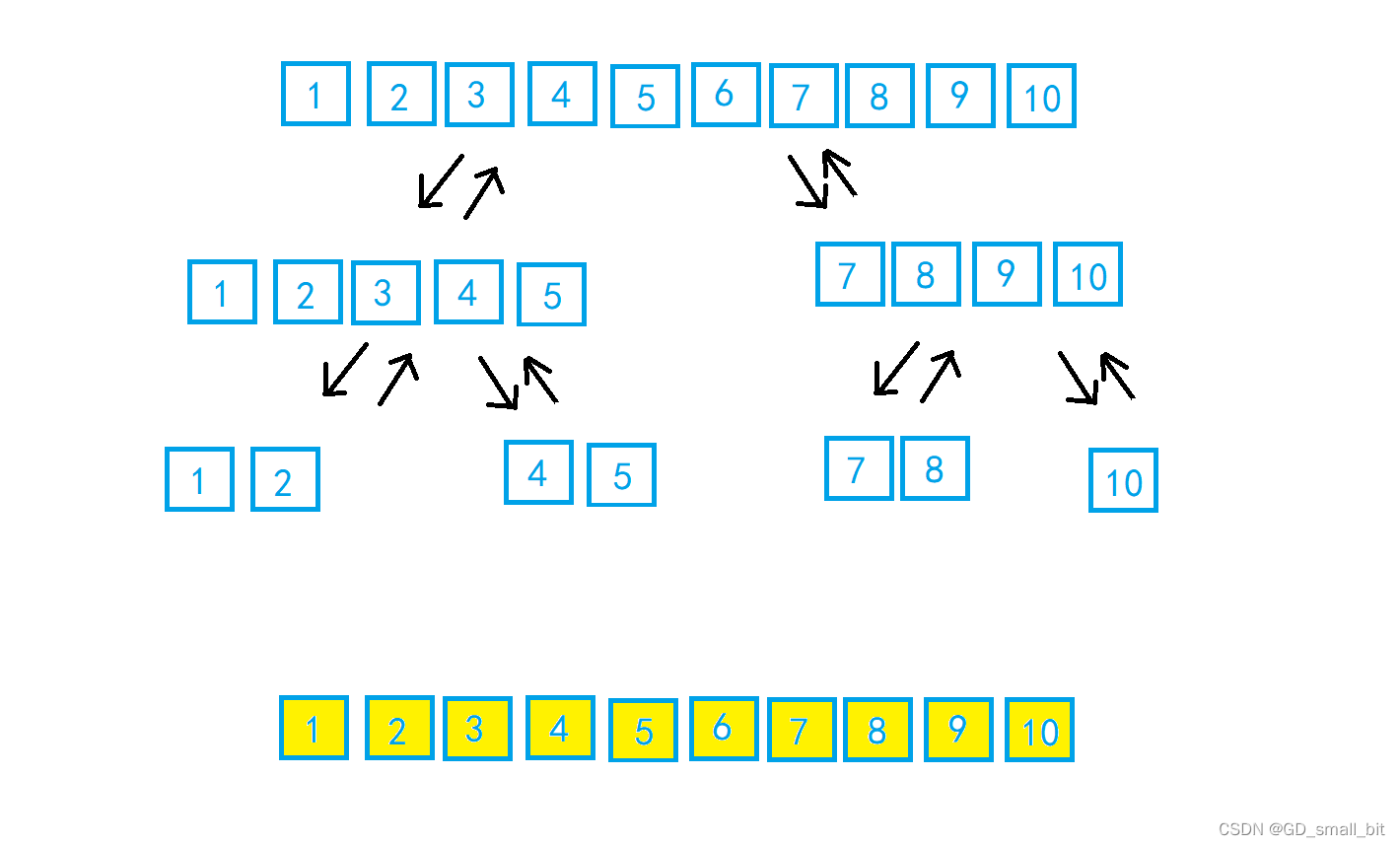
归并排序
递归版本
归并排序的底层思想就是对两个有序数组进行排序,如下面
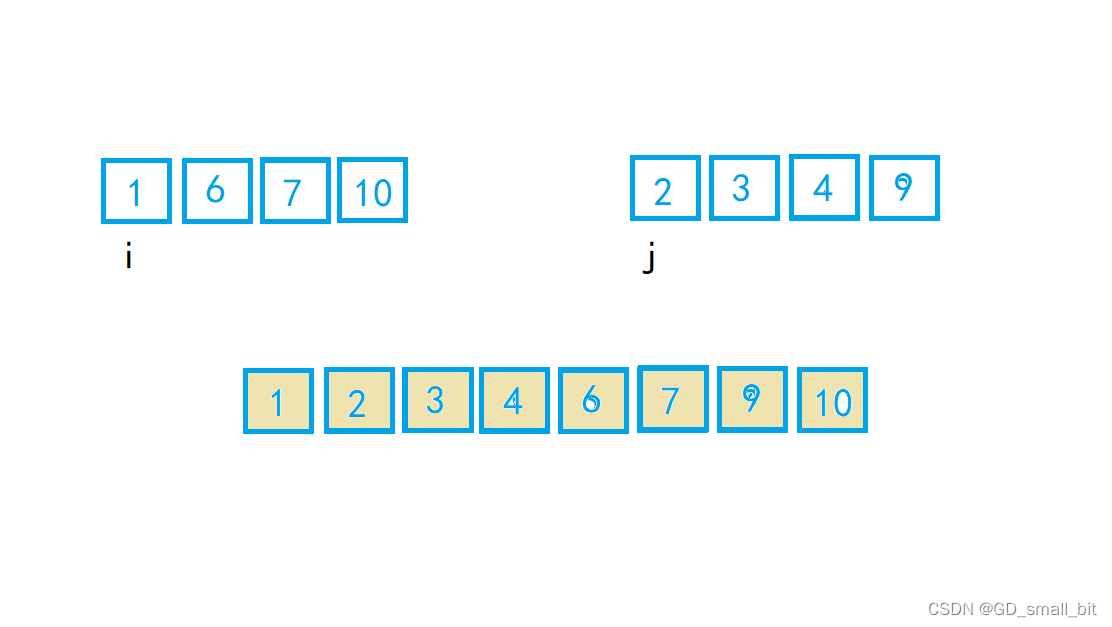
同时遍历两个数组,如果要排序升序的情况下,就将小的元素先进行尾插,直到两个数组都遍历完,排序降序的话,就将大的元素先进行尾插,直到两个数组都遍历完。
下面是动图:

结果图:

下面是代码:
#include<stdlib.h>
#include<string.h>
void _MergeSort(int* arr, int begin, int end, int* tmp)
{
if (begin >= end)
{
return;
}
//[begin,Mid][Mid + 1,end]
int Mid = (begin + end) / 2;
_MergeSort(arr,begin,Mid,tmp);
_MergeSort(arr,Mid + 1,end,tmp);
int begin1 = begin, end1 = Mid;
int begin2 = Mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] > arr[begin2])
{
tmp[i++] = arr[begin2++];
}
else
{
tmp[i++] = arr[begin1++];
}
}
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
memcpy(arr + begin,tmp + begin,sizeof(int) * (end - begin + 1));
}
void MergeSort(int* arr,int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
exit(1);
}
_MergeSort(arr,0,n - 1,tmp);
free(tmp);
tmp = NULL;
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
MergeSort(arr,sizeof(arr) / sizeof(arr[0]));
return 0;
}
排序前:

排序前:
非递归版本
归并排序的非递归版本有两种版本,不过并没有多大的区别,一个版本是边归并边将元素从tmp拷贝回原数组(即两两归并完就往原数组拷贝),一个版本是整体归并完再全部拷贝回原数组(注意这里的整体归并完代表的是一次RangeN走完)。
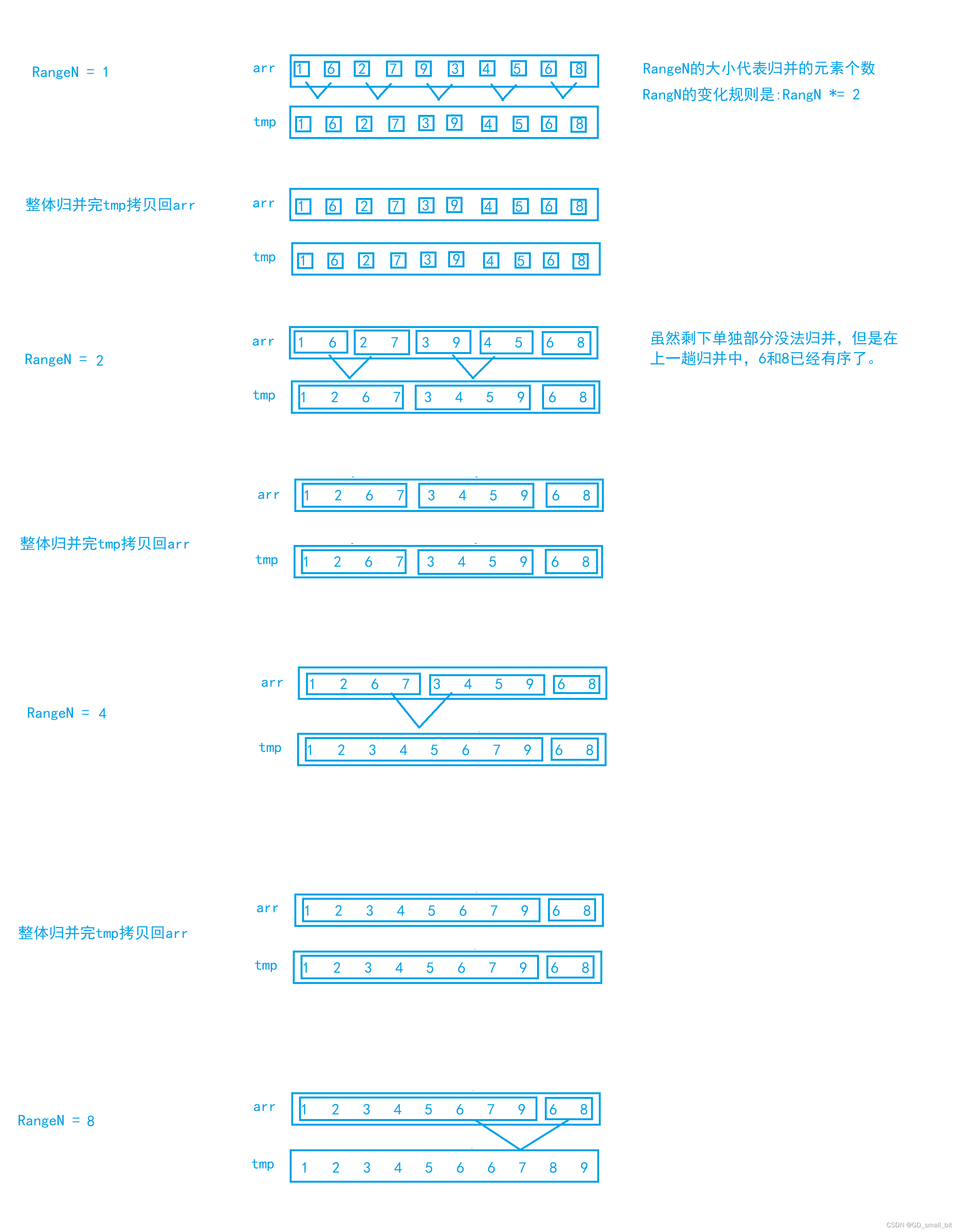
在归并排序的非递归版本中,我们需要进行调整,调整什么呢?我们观察上图RangeN = 8的情况,如果我们严格按照取8个元素,而最后只剩下6和8的两个元素,不够取,那么就会导致越界,这时就要进行调整了,下面是需要调整的三种情况。
具体调整方法看代码。
整体归并完再拷贝版本的代码:
#include<stdlib.h>
#include<string.h>
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
exit(1);
}
int RangeN = 1;
while (RangeN < n)
{
for (int i = 0; i < n; i += 2 * RangeN)//来到下一个两两归并的起始位置
{
int begin1 = i, end1 = i + RangeN - 1;
int begin2 = i + RangeN, end2 = i + 2 * RangeN - 1;
int j = i;
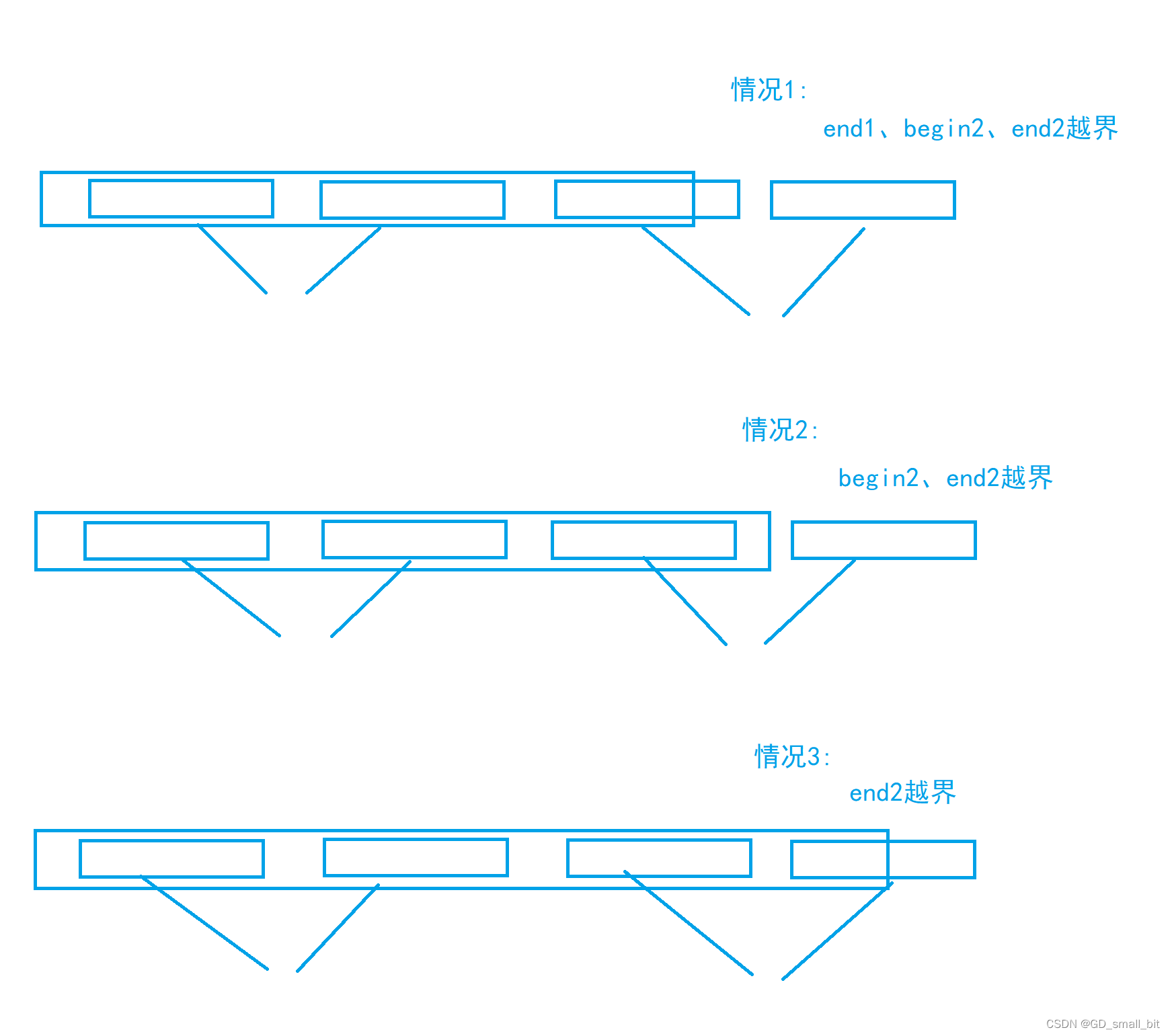
if (end1 >= n)//调整end1、begin2、end2越界的情况
{
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
else if(begin2 >= n)//调整begin2、end2越界的情况
{
begin2 = n;
end2 = n - 1;
}
else if(end2 >= n)//调整end2越界的情况
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[j++] = arr[begin1++];
}
else
{
tmp[j++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = arr[begin2++];
}
}
memcpy(arr,tmp,sizeof(int) * n);
RangeN *= 2;
}
free(tmp);
tmp = NULL;
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
MergeSortNonR(arr, sizeof(arr) / sizeof(arr[0]));
return 0;
}
排序前:
排序后:
边归并边拷贝版本的代码:
#include<stdlib.h>
#include<string.h>
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
exit(1);
}
int RangeN = 1;
while (RangeN < n)
{
for (int i = 0; i < n; i += 2 * RangeN)//来到下一个两两归并的起始位置
{
int begin1 = i, end1 = i + RangeN - 1;
int begin2 = i + RangeN, end2 = i + 2 * RangeN - 1;
int j = i;
if (end1 >= n)//调整end1、begin2、end2越界的情况
{
break;//不是在外面拷贝,直接跳出去,下同。
}
else if(begin2 >= n)//调整begin2、end2越界的情况
{
break;
}
else if(end2 >= n)//调整end2越界的情况
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[j++] = arr[begin1++];
}
else
{
tmp[j++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = arr[begin2++];
}
memcpy(arr + i, tmp + i, sizeof(int) * (end2 - i + 1));//i不能改为begin1.因为begin1在前面时变化了
}
RangeN *= 2;
}
free(tmp);
tmp = NULL;
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
MergeSortNonR(arr, sizeof(arr) / sizeof(arr[0]));
return 0;
}
拷贝前:
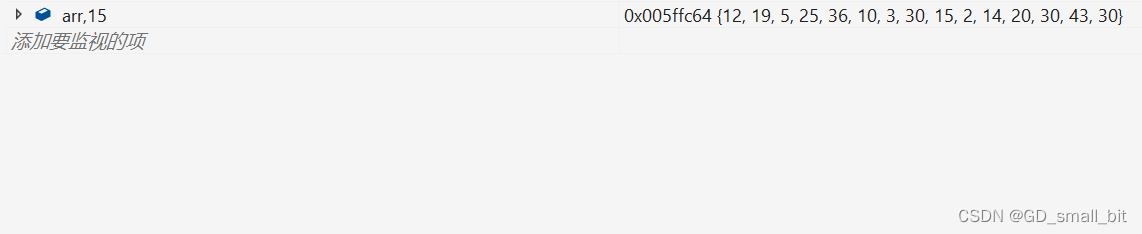
拷贝后:

归并排序的时间复杂度分析
归并排序的时间复杂度计算和快速排序差不多,递归深度是logN,每层是遍历N次,所以时间复杂度是:O(N*logN)。
归并排序的空间复杂度分析
因为动态开辟了数组tmp,所以归并排序的空间复杂度是:O(N)。
归并排序的稳定性
稳定,因为可以控制元素大小相同时,在归并的过程中不进行交换顺序。
基数排序
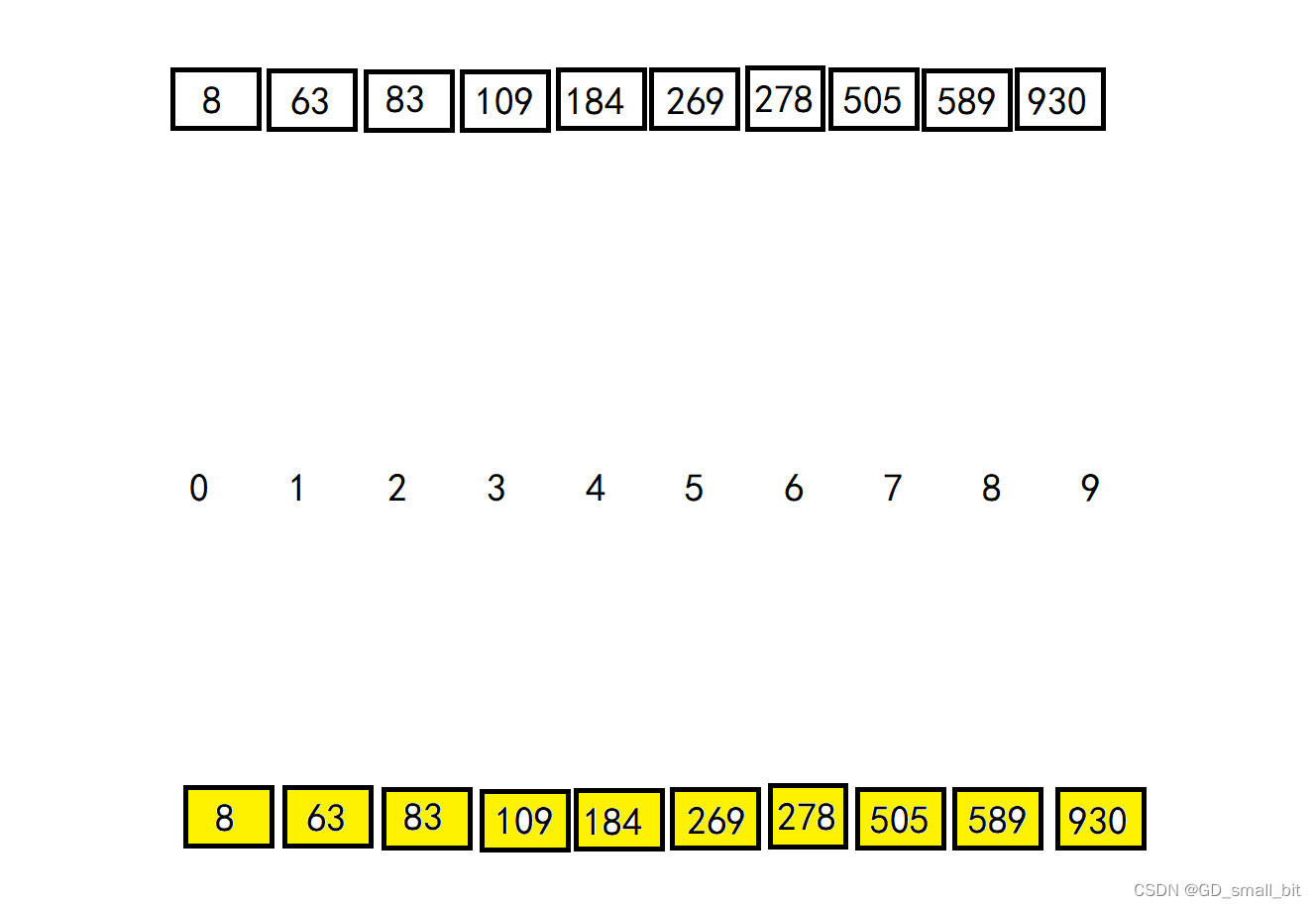
基数排序的核心是分发数据和回收数据,如何分发数据呢,可以按照某一位的数字进行分发,比如最低位的数字是1,那么就分发给下标是1的位置。当数组的所有元素都按照某一位的数据进行分发后,进行回收数据。循环下去,直到所有位数都分发过了,那么该数组就有序了。
MSD:由数值的最左边(高位)开始分发。
LSD:排序方式由数值的最后边(低位)开始。
结果图:
因为回收数据时,要保证先进先出,那么就可以利用队列来进行存储数据,同样由于C语言并没有队列,所以依然要手写队列代码,我直接发在代码库,可以直接前往代码库进行观看。
基数排序
排序前:
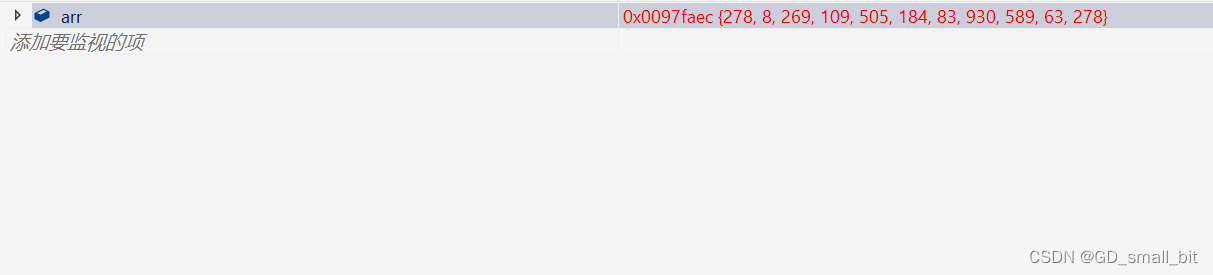
排序后:
基数排序的时间复杂度
基数排序的时间复杂度是:O(N*M),其中的N为数据个数,M为最大的数据位数。
基数排序的空间复杂度
基数排序的空间复杂度:O(M)。
基数排序的稳定性
稳定。相同大小的数据在进入同一队列,先进先出的性质保证相同数字的顺序。
计数排序
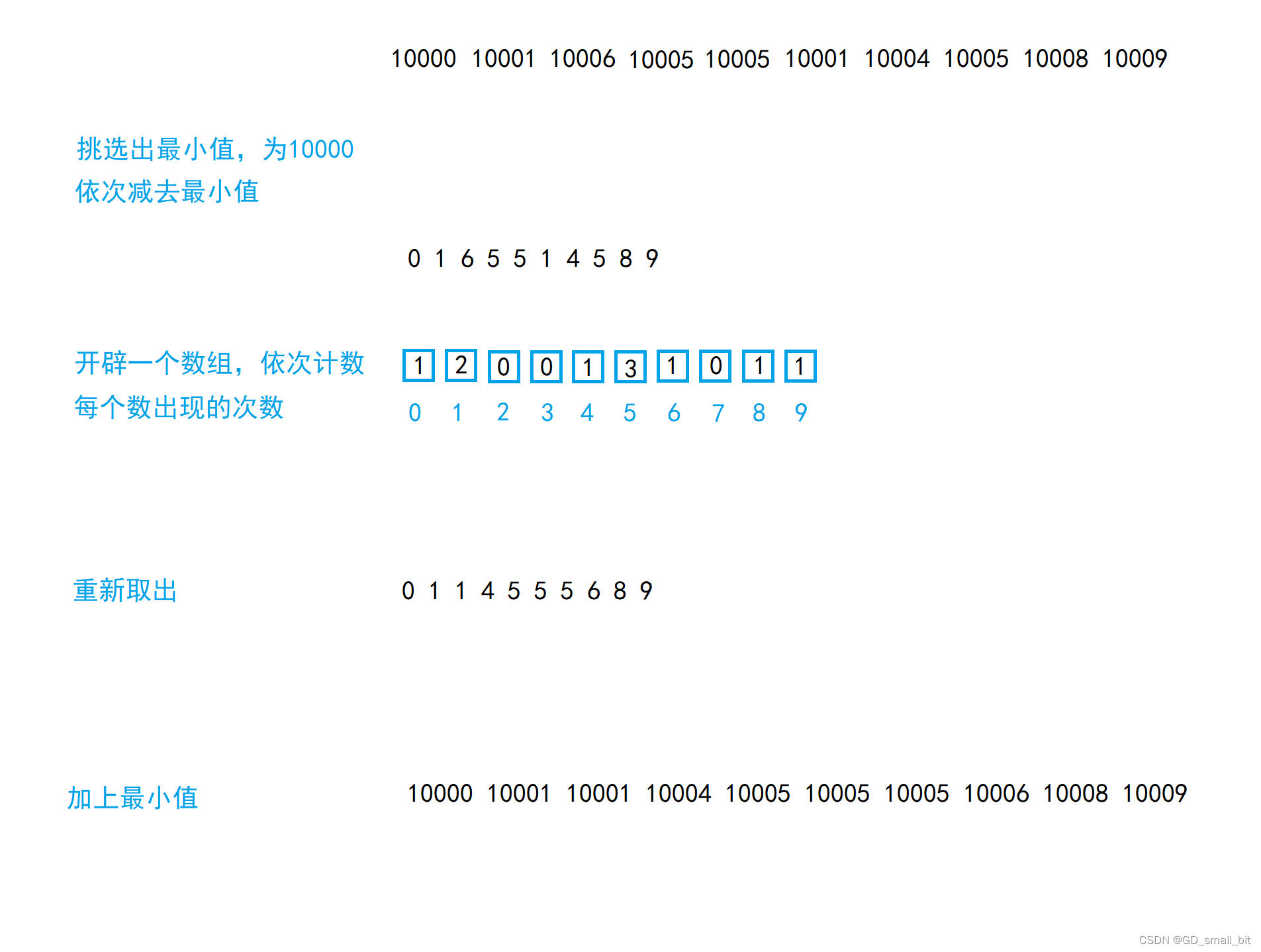
计数排序的原理:
1.统计出每个数据出现的次数。
2.根据统计的结果将序列回收到原来的序列中。
下面是代码:
void CountSort(int* arr, int n)
{
int Max = arr[0],Min = arr[0];
for (int i = 0; i < n; i++)
{
if (arr[i] > Max)
{
Max = arr[i];
}
if (arr[i] < Min)
{
Min = arr[i];
}
}
int Range = Max - Min + 1;
int* CountA = (int*)calloc(sizeof(int),Range);//用calloc开辟空间,有带初始化
if (CountA == NULL)
{
perror("malloc fail");
exit(1);
}
//1.统计次数
for (int i = 0; i < n; i++)
{
CountA[arr[i] - Min]++;
}
//2.排序
int k = 0;
for (int i = 0; i < Range; i++)
{
while(CountA[i]--)
{
arr[k++] = i + Min;
}
}
free(CountA);
CountA = NULL;
}
int main()
{
int arr[] = { 12,19,5,25,36,10,3,30,15,2,14,20,30,43,30 };
CountSort(arr,sizeof(arr) / sizeof(arr[0]));
return 0;
}
排序前:

排序后:
计数排序适合范围集中的数据,只适合整形。
计数排序的时间复杂度分析
在计数排序中,遍历两次数组,为2n;并且还遍历一次CountA,次数为Range,由大O渐进表示法可得,计数排序的时间复杂度是:O(N+Range)。
计数排序的空间复杂度分析
在计数排序中,开辟了一个数组,个数为Range,所以计数排序的空间复杂度是O(Range)。
计数排序的稳定性
计数排序的稳定性高。因为相同数字按照原来顺序依次归入同一下标,并不会被打乱。
总结:
计数排序:
时间复杂度是:O(N+Range)
空间复杂度是:O(Range)
稳定性:稳定
文件外排序
当需要排序的数据量过大时,我们不能一次把全部的数据从文件拿到内存时,我们就需要考虑采用文件外排序的方法了,如何进行呢?我们先可以将数据切分为几个部分,依次拿出一部分来到内存进行快速排序,并存到一个新的文件里,此时我们就有了几个完成排序的文件,那么,我们就对这几个文件进行归并,最后,就得到了一个完整的排序完的数据。
我们先往一个文件存入大量的随机数。
#include<stdio.h>
#include<time.h>
int main()
{
srand(time(NULL));
FILE* pf = fopen("SortData.txt", "w");
if (pf == NULL)
{
perror("fopen fail");
exit(1);
}
int n = 100;
while (n--)
{
int num = rand() % 10000;
fprintf(pf,"%d\n",num);
}
return 0;
}
下面是排序的代码:
#include<stdio.h>
#include<string.h>
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void _MergeSortFile(const char* File1, const char* File2, const char* Myfile)
{
FILE* fout1 = fopen(File1, "r");
if (fout1 == NULL)
{
perror("fopen fail");
exit(1);
}
FILE* fout2 = fopen(File2, "r");
if (fout2 == NULL)
{
perror("fopen fail");
exit(1);
}
FILE* fout3 = fopen(Myfile, "w");
if (fout3 == NULL)
{
perror("fopen fail");
exit(1);
}
int num1, num2;
int ret1 = fscanf(fout1, "%d", &num1);
int ret2 = fscanf(fout2, "%d", &num2);
while (ret1 != EOF && ret2 != EOF)
{
if (num1 < num2)
{
fprintf(fout3, "%d\n", num1);
ret1 = fscanf(fout1, "%d", &num1);
}
else
{
fprintf(fout3, "%d\n", num2);
ret2 = fscanf(fout2, "%d", &num2);
}
}
while (ret1 != EOF)
{
fprintf(fout3, "%d\n", num1);
ret1 = fscanf(fout1, "%d", &num1);
}
while (ret2 != EOF)
{
fprintf(fout3, "%d\n", num2);
ret2 = fscanf(fout2, "%d", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fout3);
}
void QuickSort(int* arr, int begin, int end)
{
if (begin >= end)
{
return;
}
int keyi = begin;
int left = begin, right = end;
while (left < right)
{
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
swap(&arr[left], &arr[right]);
}
swap(&arr[keyi], &arr[left]);
keyi = left;
QuickSort(arr, begin, keyi - 1);
QuickSort(arr, keyi + 1, end);
}
void MergeSortFilea(const char* file)
{
FILE* pf = fopen(file, "r");
if (pf == NULL)
{
perror("fopen fail");
exit(1);
}
int num = 0;
int arr[10];//总共100个,分为10组,每组10个
int i = 0;
int n = 10;
char SubFile[20];//为文件取名做准备
int file1 = 1;
memset(arr, 0, sizeof(int) * 10);
while (fscanf(pf, "%d", &num) != EOF)
{
if (i < n - 1)//读取数据
{
arr[i++] = num;
}
else
{
arr[i] = num;//读取最后一个数据
QuickSort(arr, 0, n - 1);
sprintf(SubFile, "%d", file1++);
FILE* Pf1 = fopen(SubFile, "w");
if (pf == NULL)
{
perror("fopen fail");
exit(1);
}
for (int i = 0; i < n; ++i)
{
fprintf(Pf1, "%d\n", arr[i]);
}
fclose(Pf1);
i = 0;
memset(arr, 0, sizeof(int) * 10);
}
}
char Myfile[100] = "12";
char File1[100] = "1";
char File2[100] = "2";
for (int i = 2; i < n; i++)
{
_MergeSortFile(File1, File2, Myfile);
strcpy(File1, Myfile);
sprintf(File2, "%d", i + 1);
sprintf(Myfile, "%s%d", Myfile, i + 1);
}
fclose(pf);
}
int main()
{
MergeSortFilea("SortData.txt");
return 0;
}
文件123456789就是最终排序结果。

下面是代码库:文件外排序
测试排序的代码
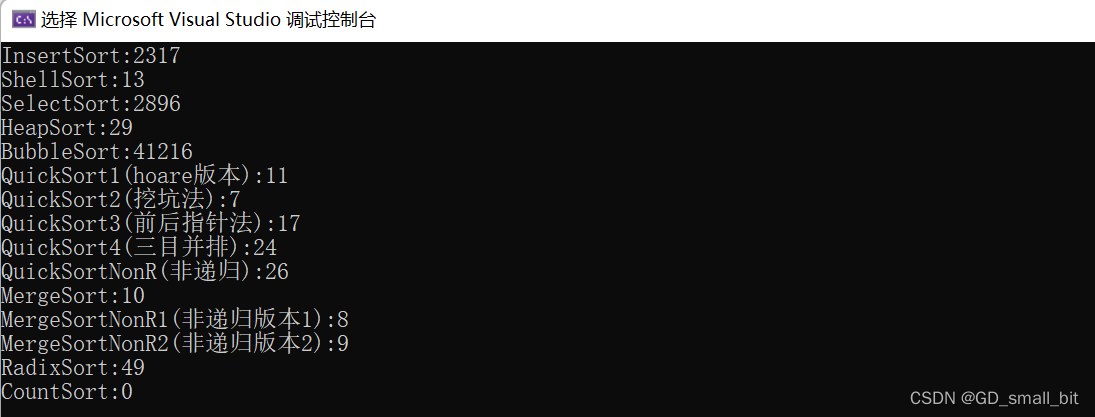
在上面的文章中,我已经介绍了好几种的排序方法,那么我们在平时的处理数据中,应该选择哪种排序方法呢?我们可以通过测试这几种排序方法的速度,来进行选择。在测试的过程中,我们可以采用clock函数,记录下排序开始,排序结束,相减便可以得到排序用去的时间了。
下面是代码库:
排序代码总结
排序10万个数字的运行结果:
校招考核范围
校招考核的是除了文件外排序和基数排序的所有内容,排序的内容较多,建议停下来慢慢研究,有大的好处。
今天的讲解就到这里,下期再见。