这种搜索引擎的实现常常用的就是倒排的技术
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。
索引库(Index): 若干个文档的合集.
词条:原始文档数据按照一定的算法进行分词,得到的每一个词.例如:我是中国人.其中就有中国,中国人等等.未来可以通过这些分词后的词条,来索引到文档.
所以可以这么回答面试官:所谓的倒排索引,就是将原始的文档进行编号,创建文档索引,形成文档列表.然后对文档进行分词,得到词条.再对词条进行编号,并以词条创建索引.然后记录下包含该词条的所有文档编号.(单个分词映射到对应的若干个文档,所有分词和文档映射关系组合起来的就是倒排列表,辅助理解,不用说出). 未来搜索时,就可以通过对搜索关键字的分词,然后找到索引库中对应的文档,这就是倒排索引的原理.
以上转自: 面试时被问到倒排索引是什么该如何快速明了的回答
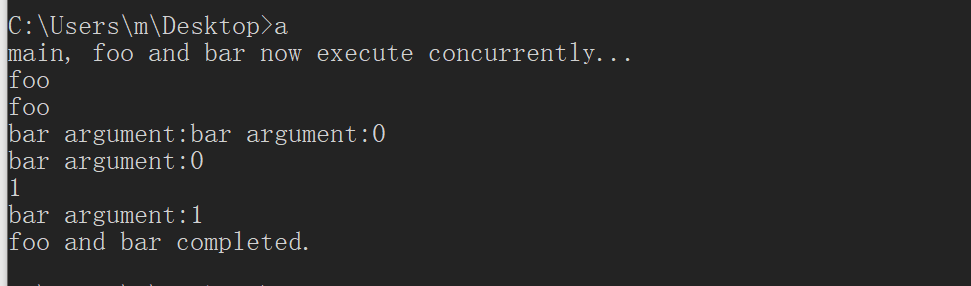
我用图来解释一下倒排表的实现过程:
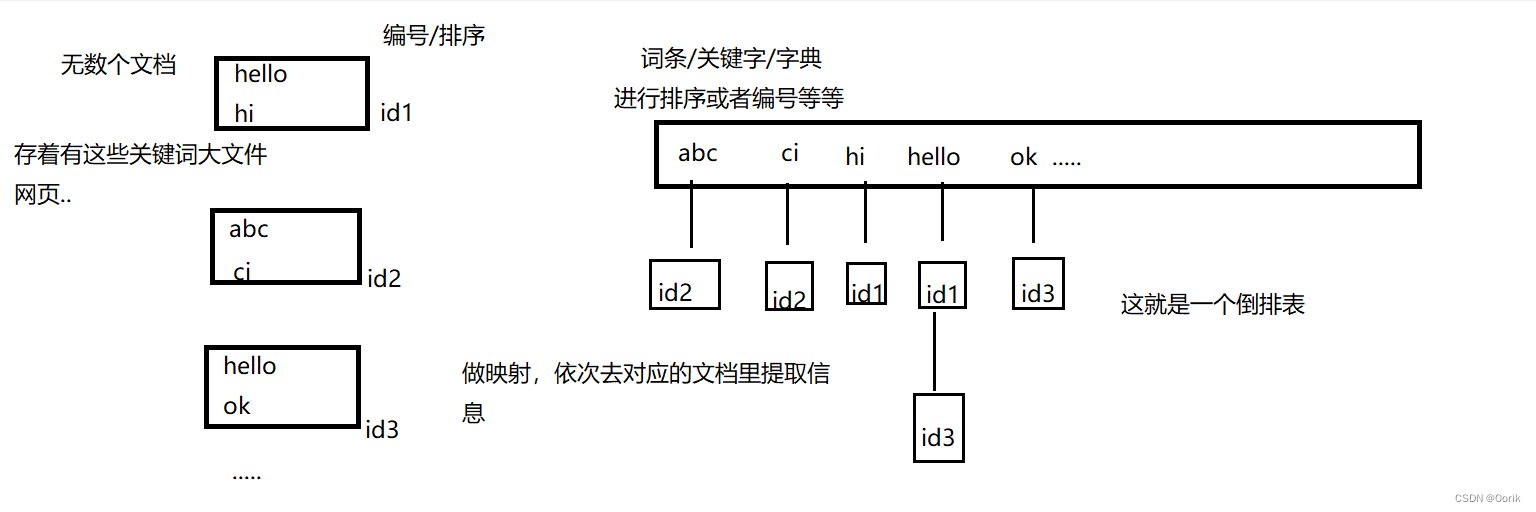
倒排索引是目前搜索引擎公司对搜索引擎最常用的存储方式,也是搜索引擎的核心内容,在搜索引擎的实际应用中,有时需要按照关键字的某些值查找记录,所以是按照关键字建立索引,这个索引就被称为倒排索引。
首先要明确,索引这东西,一般是用于提高查询效率的。举个最简单的例子,已知有5个文本文件,需要我们去查某个单词位于哪个文本文件中,最直观的做法就是挨个加载每个文本文件中的单词到内存中,然后用for循环遍历一遍数组,直到找到这个单词。这种做法就是正向索引的思路。
百度搜索的话这个文档件的个数可想而知
举个例子:
D1:Hello, conan!
D2:Hello, hattori!
第一步,找到所有的单词
Hello、conan、hattori
第二步,找到包含这些单词的文本位置
Hello(D1,D2)
conan(D1)
hattori(D2)
我们将单词作为Hash表的Key,将所在的文本位置作为Hash表的Value保存起来。
当我们要查询某个单词的所在位置时,只需要根据这张Hash表就可以迅速的找到目标文档。
结合之前的说的正向索引,不难发现。正向索引是通过文档去查找单词,反向索引则是通过单词去查找文档。
倒排索引的优点还包括在处理复杂的多关键字查询时,可在倒排表中先完成查询的并、交等逻辑运算,得到结果后再对记录进行存取,这样把对文档的查询转换为地址集合的运算,从而提高查找速度。