目录
📔前言📔:
📙一、顺序存储结构📙:
📘二、堆📘:
1.堆的概念及结构:
2.堆的性质:
3.堆的实现(本文重点):
①.堆的初始化:
②.堆的插入(含向上调整算法):
③.堆的删除(含向下调整算法):
④.取堆顶数据:
⑤.堆中数据个数:
⑥.堆的判空:
⑦.堆的销毁:
4.堆实现全部代码:
①.Heap.h:
②.Heap.c:
③.test.c:
📕总结📕:
🛰️博客主页:✈️銮同学的干货分享基地
🛰️欢迎关注:👍点赞🙌收藏✍️留言
🛰️系列专栏:🎈 数据结构
🎈【进阶】C语言学习
🎈 C语言学习
🛰️代码仓库:🎉数据结构仓库
🎉VS2022_C语言仓库
家人们更新不易,你们的👍点赞👍和⭐关注⭐真的对我真重要,各位路过的友友麻烦多多点赞关注,欢迎你们的私信提问,感谢你们的转发!
关注我,关注我,关注我,你们将会看到更多的优质内容!!
🏡🏡 本文重点 🏡🏡:
🚅 顺序存储结构 🚃 堆 🚏🚏
📔前言📔:
上节课中我们完整、宏观的认识了树与二叉树,以及两种常见的存储结构的相关概念与整体结构,而今天我们就将来研究两种存储结构中的一种——顺序存储结构的实现。
📙一、顺序存储结构📙:
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来进行存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆完全不同,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
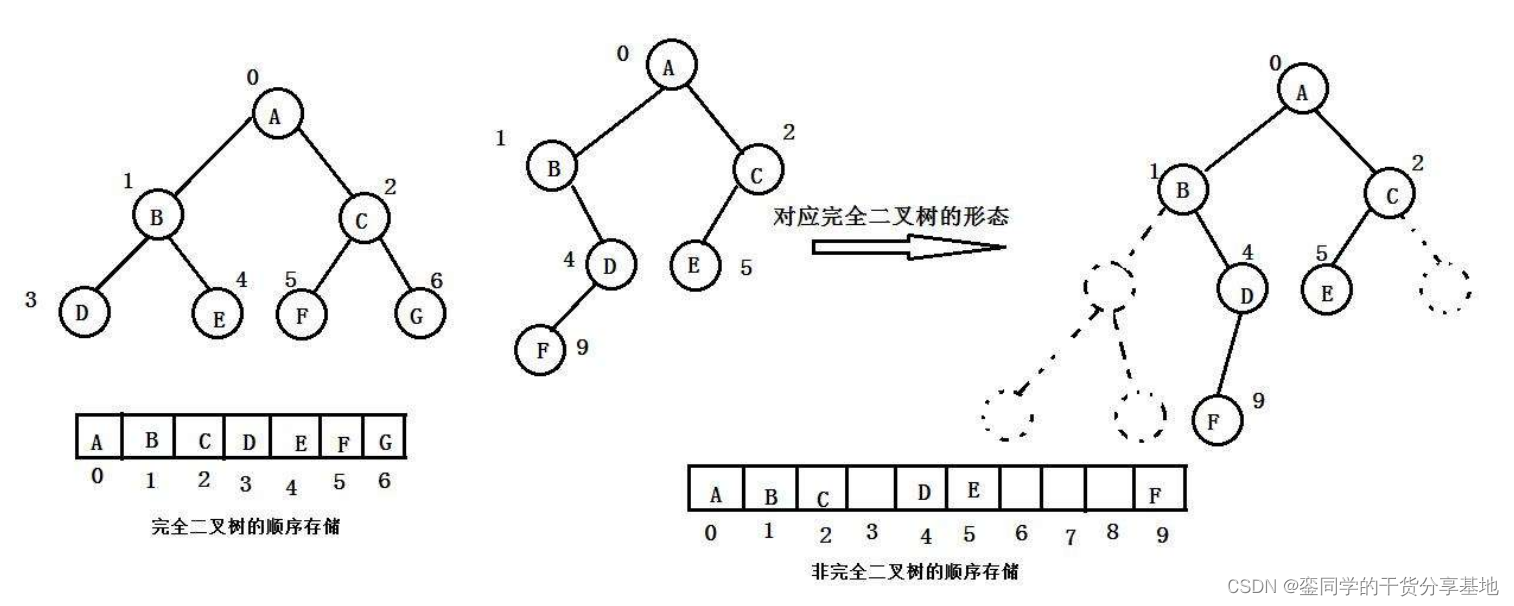
于是今天我们关于顺序存储结构的研究与讲解,就以堆的形式进行。
📘二、堆📘:
1.堆的概念及结构:
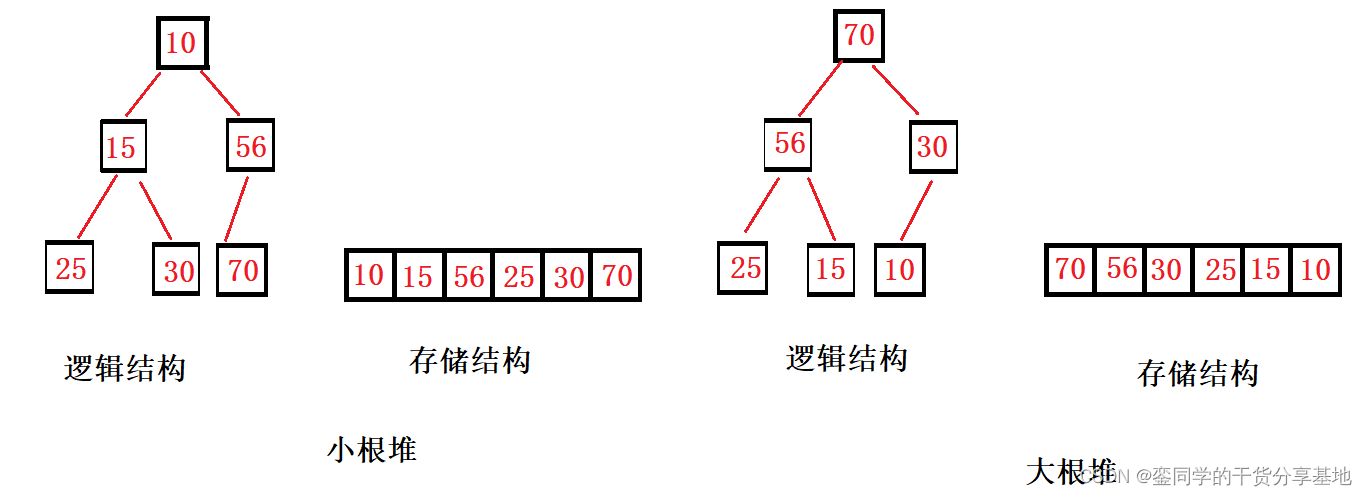
堆分为小根堆和大根堆,根节点始终小于子节点称为小根堆,相反根节点始终大于子节点则称为大根堆。换句话说,将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
2.堆的性质:
- 堆中某个节点的值总是不大或不小于其父节点的值。
- 堆总是一棵完全二叉树。
3.堆的实现(本文重点):
关于堆的实现我们使用标准模块化开发格式进行研究:
- Heap.h:存放函数声明、包含其他头文件、定义宏。
- Heap.c:书写函数定义,书写函数实现。
- test.c:书写程序整体执行逻辑。
①.堆的初始化:
- 堆的初始化与队列相同,首先判断传入指针非空后,将其置空,并将数据置零即可。
void HInit(HP* p) { if (p == NULL) { printf("Init Error!\n"); return; } p->a = NULL; p->size = p->capacity = 0; }
②.堆的插入(含向上调整算法):
因为堆的存储在物理层面上数组,但是在逻辑层面上二叉树。并且由于只有小根堆和大根堆,所以在插入数据之后要想保证其仍然是堆,就需要进行适当的调整。插入时从尾部插入,而是否为堆取决于子节点和父节点的关系,所以插入的数据要与其父节点进行比较,若为小根堆则子节点要比父节点要大,否则就需要交换子节点和父节点,大根堆则相反。而这种调整方式就叫做向上调整算法。
- 执行操作前需进行非空判断,防止堆空指针进行操作。
- 插入前判断空间是否足以用于此次扩容,若不足则进行扩容,直至满足插入条件后堪称插入操作,这个接口的功能实现也与队列的处理方式基本相同。
- 与队列的不同点在于,为了保证插入后仍然是堆,需要在插入后使用向上调整算法进行适当的调整。
//向上调整算法: void AdJustUp(int* a,int n,int child) { if (a == NULL) { printf("AdJustUp Error!\n"); return; } int parent = (child - 1) / 2; while (child > 0) { //大根堆节点交换(判断小根堆秩序将">"换为"<"即可): if (a[child] > a[parent]) { HDataTapy tmp = a[child]; a[child] = a[parent]; a[parent] = tmp; //重复向上走: child = parent; parent = (child - 1) / 2; } else { break; } } } //堆插入: void HPush(HP* p, HDataTapy x) { if (p == NULL) { printf("Push Error!\n"); return; } if (p->size == p->capacity) { //插入前扩容: size_t newCapacity = (p->capacity == 0) ? 4 : (p->capacity * 2); HDataTapy* tmp = realloc(p->a, sizeof(HDataTapy) * newCapacity); //判断扩容结果: if (tmp == NULL) { printf("Capacuty Get Error!\n"); return; } //增容成功后的处理: else { p->a = tmp; p->capacity = newCapacity; } } //插入数据: p->a[p->size] = x; p->size++; //向上调整: AdJustUp(p->a, p->size, p->size - 1); }
- 验证堆插入接口功能实现:
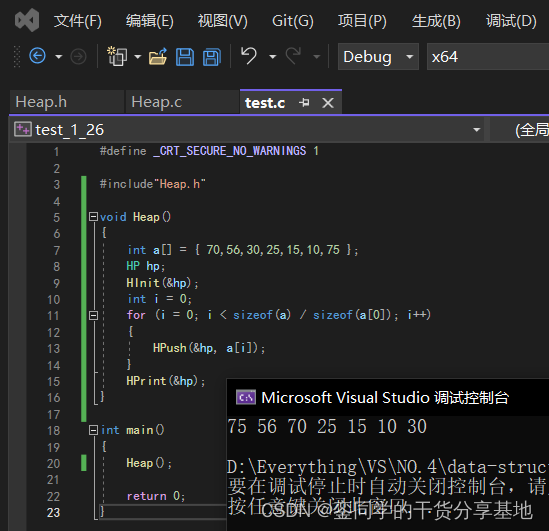
③.堆的删除(含向下调整算法):
堆删除的实质是删除堆顶元素,如果我们直接删除堆顶的元素,再将数据挪动,就会破坏堆的结构,所以这种方法并不可取;于是我们这里采用将堆顶的数据与最后一个数据交换,再删除最后一个数据的方法,这样就实现了堆顶数据的删除。接着我们再调整一下堆顶数据的位置即可。
在这里,我们选择的调整方法是:将根节点与它的孩子中的较小值交换,然后再将交换后的节点作为父节点继续与它的子节点交换,直到该节点小于它的子节点,或者成为叶节点。要注意的是,使用这个方法有一个前提:根节点的两个子树也得是堆才行。而这种方法就叫做向下调整算法。
- 执行操作前需进行非空判断,防止对空指针进行操作。
- 删除过程同样与队列近乎一致,不同点是在删除过后为了保证删除堆顶数据后仍为堆,于是需要使用向下调整算法堆删除后的结果进行适当的处理。
//向下调整算法: void AdJustDown(int* a, int n, int parent) { int child = 2 * parent + 1; while (child < n) { //选出两孩子中的较小孩子(需要考虑边界,防止越界访问): if (child + 1 < n && a[child + 1] > a[child]) { ++child; } //向下调整: if (a[child] > a[parent]) { int* tmp = a[child]; a[child] = a[parent]; a[parent] = tmp; parent = child; child = parent * 2 + 1; } else { break; } } } //堆顶数据删除: void HPop(HP* p) { if (p == NULL) { printf("Pop Error!\n"); return; } //堆数据判空: if (HEmpty(&p) == 1) { printf("Is Null !\n"); return; } HDataTapy* tmp = p->a[0]; p->a[0] = p->a[p->size - 1]; p->a[p->size - 1] = tmp; p->size--; AdJustDown(p->a, p->size - 1, 0); }
- 测试删除接口功能实现:
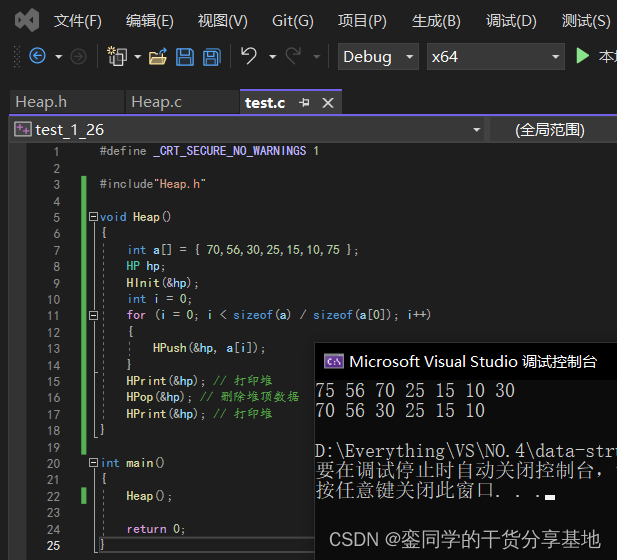
④.取堆顶数据:
- 取堆顶数据操作与队列完全相同,这里不再作过多阐述。
HDataType HTop(HP* p) { if (p == NULL) { printf("Top Get Error!\n"); return; } //堆数据判空: if (HEmpty(&p) == 1) { printf("Is Null !\n"); exit; } return p->a[0]; }
- 测试取堆顶数据接口功能实现:
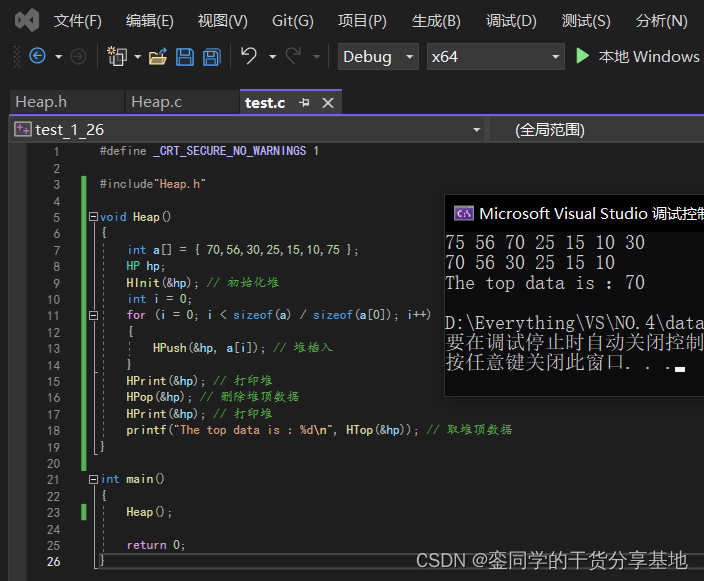
⑤.堆中数据个数:
- 查看堆中的数据个数操作很简单,在判断传入指针非空后,直接返回 p->size 的值,即堆中保存的数据数量即可。
int HSize(HP* p) { if (p == NULL) { printf("Size Get Error!\n"); return; } return p->size; }
- 测试数据个数获取接口功能实现:
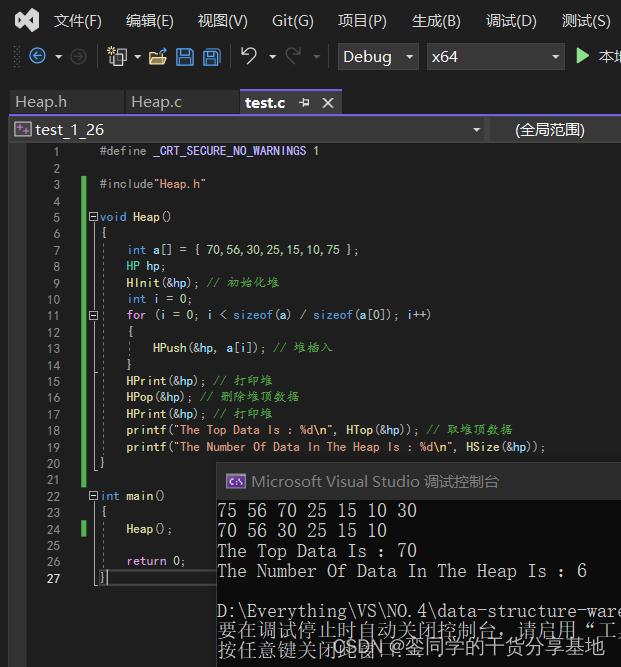
⑥.堆的判空:
- 堆的判空操作与队列完全相同,这里不再作过多阐述。
//堆数据判空: bool HEmpty(HP* p) { if (p == NULL) { printf("Empty Error!\n"); exit; } return p->size == 0; }
⑦.堆的销毁:
- 堆的销毁与队列完全相同,这里不再作过多阐述。
void HDestroy(HP* p) { if (p == NULL) { printf("Destroy Error!\n"); return; } free(p->a); p->a = NULL; p->size = p->capacity = 0; }
- 测试销毁接口功能实现:
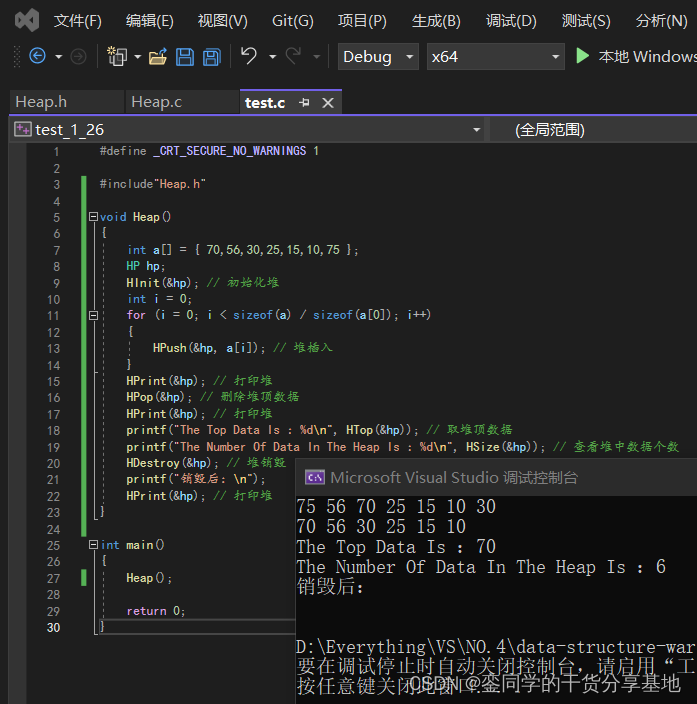
4.堆实现全部代码:
①.Heap.h:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int HDataType;
typedef struct Heap
{
HDataType* a;
int size;
int capacity;
}HP;
void HInit(HP* p); // 堆的初始化
void HPrint(HP* p); // 打印堆
void HPush(HP* p, HDataType x); // 堆插入
void HPop(HP* p); // 堆顶数据删除
HDataType HTop(HP* p); // 取堆顶数据
int HSize(HP* p); // 堆中数据个数
bool HEmpty(HP* p); // 堆数据判空
void HDestroy(HP* p); // 堆销毁②.Heap.c:
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
//堆的初始化:
void HInit(HP* p)
{
if (p == NULL)
{
printf("Init Error!\n");
exit;
}
p->a = NULL;
p->size = p->capacity = 0;
}
//打印堆:
void HPrint(HP* p)
{
if(p==NULL)
{
printf("Printf Error!\n");
return;
}
int i = 0;
for (i = 0; i < p->size; ++i)
{
printf("%d ", p->a[i]);
}
printf("\n");
}
//向上调整算法:
void AdJustUp(int* a,int n,int child)
{
if (a == NULL)
{
printf("AdJustUp Error!\n");
return;
}
int parent = (child - 1) / 2;
while (child > 0)
{
//大根堆节点交换(判断小根堆秩序将">"换为"<"即可):
if (a[child] > a[parent])
{
HDataType tmp = a[child];
a[child] = a[parent];
a[parent] = tmp;
//重复向上走:
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//堆插入:
void HPush(HP* p, HDataType x)
{
if (p == NULL)
{
printf("Push Error!\n");
return;
}
if (p->size == p->capacity)
{
//插入前扩容:
size_t newCapacity = (p->capacity == 0) ? 4 : (p->capacity * 2);
HDataType* tmp = realloc(p->a, sizeof(HDataType) * newCapacity);
//判断扩容结果:
if (tmp == NULL)
{
printf("Capacuty Get Error!\n");
return;
}
//增容成功后的处理:
else
{
p->a = tmp;
p->capacity = newCapacity;
}
}
//插入数据:
p->a[p->size] = x;
p->size++;
//向上调整:
AdJustUp(p->a, p->size, p->size - 1);
}
//向下调整算法:
void AdJustDown(int* a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)
{
//选出两孩子中的较小孩子(需要考虑边界,防止越界访问):
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
//向下调整:
if (a[child] > a[parent])
{
int* tmp = a[child];
a[child] = a[parent];
a[parent] = tmp;
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆顶数据删除:
void HPop(HP* p)
{
if (p == NULL)
{
printf("Pop Error!\n");
return;
}
//堆数据判空:
if (HEmpty(&p) == 1)
{
printf("Is Null !\n");
return;
}
HDataType* tmp = p->a[0];
p->a[0] = p->a[p->size - 1];
p->a[p->size - 1] = tmp;
p->size--;
AdJustDown(p->a, p->size - 1, 0);
}
//取堆顶数据:
HDataType HTop(HP* p)
{
if (p == NULL)
{
printf("Top Get Error!\n");
return;
}
//堆数据判空:
if (HEmpty(&p) == 1)
{
printf("Is Null !\n");
exit;
}
return p->a[0];
}
//堆中数据个数:
int HSize(HP* p)
{
if (p == NULL)
{
printf("Size Get Error!\n");
return;
}
return p->size;
}
//堆数据判空:
bool HEmpty(HP* p)
{
if (p == NULL)
{
printf("Empty Error!\n");
exit;
}
return p->size == 0;
}
//堆销毁:
void HDestroy(HP* p)
{
if (p == NULL)
{
printf("Destroy Error!\n");
return;
}
free(p->a);
p->a = NULL;
p->size = p->capacity = 0;
}③.test.c:
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
void Heap()
{
int a[] = { 70,56,30,25,15,10,75 };
HP hp;
HInit(&hp); // 初始化堆
int i = 0;
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
HPush(&hp, a[i]); // 堆插入
}
HPrint(&hp); // 打印堆
HPop(&hp); // 删除堆顶数据
HPrint(&hp); // 打印堆
printf("The Top Data Is :%d\n", HTop(&hp)); // 取堆顶数据
printf("The Number Of Data In The Heap Is :%d\n", HSize(&hp)); // 查看堆中数据个数
HDestroy(&hp); // 堆销毁
printf("销毁后:\n");
HPrint(&hp); // 打印堆
}
int main()
{
Heap();
return 0;
}📕总结📕:
今天我们完整地认识、了解、学习了二叉树顺序存储结构的相关知识,并且对二叉树顺序存储的实例——堆的各接口功能进行了研究与实现。至此,关于二叉树的顺序存储的知识我们就全部学习完毕了,希望各位小伙伴们仍能多多翻阅,多多动手练习,不断巩固基础磨练自己的编程技术。下节课中我们将要学习链式存储结构的相关知识,各位小伙们下去以后,若有多余的精力,可以提前进行预习,以便于接下来更好的理解二叉树的链式存储结构的各种功能接口的实现。
🔥🔥当我们远离了言语与是非,我们的一切存在也就真实地显露了其本来的价值🔥🔥
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!