1 问题来源
近期在本地 Windows 系统上跑深度学习人群计数模型时,由于笔记本 NVIDIA 显卡 NVIDIA GeForce GTX 1650 的专用 GPU 内存只有 4 GB,无法设置较大的 batchsize 进行训练,导致模型训练时间过长,且易发生内存溢出,故考虑租用 GPU 服务器进行模型训练作业。由于 GPU 服务器对配置要求较高,价格过于可观,故考虑白嫖,若短期可以解决的训练任务,可以去参加腾讯云的新用户 1 元体验七天活动,或者购买按照时间计费的服务器。
由于之前都是使用 Windows 的 Anaconda 进行虚拟环境的管理与模型训练,购买 GPU 服务器(Linux 系统)后一时间不知道如何操作,故记录于此。
2 解决方法
2.1 登录服务器
由于 GPU 服务器需要进行远程登录才可以使用,故考虑使用 Xshell 与 Xftp 进行命令行操作与文件传输作业。
Xshell 与 Xftp 均可在 NETSARANG 官网进行下载,其中企业版需要付费使用,家庭/学校版可以免费使用。网址为:NetSarang Homepage CN - NetSarang Website
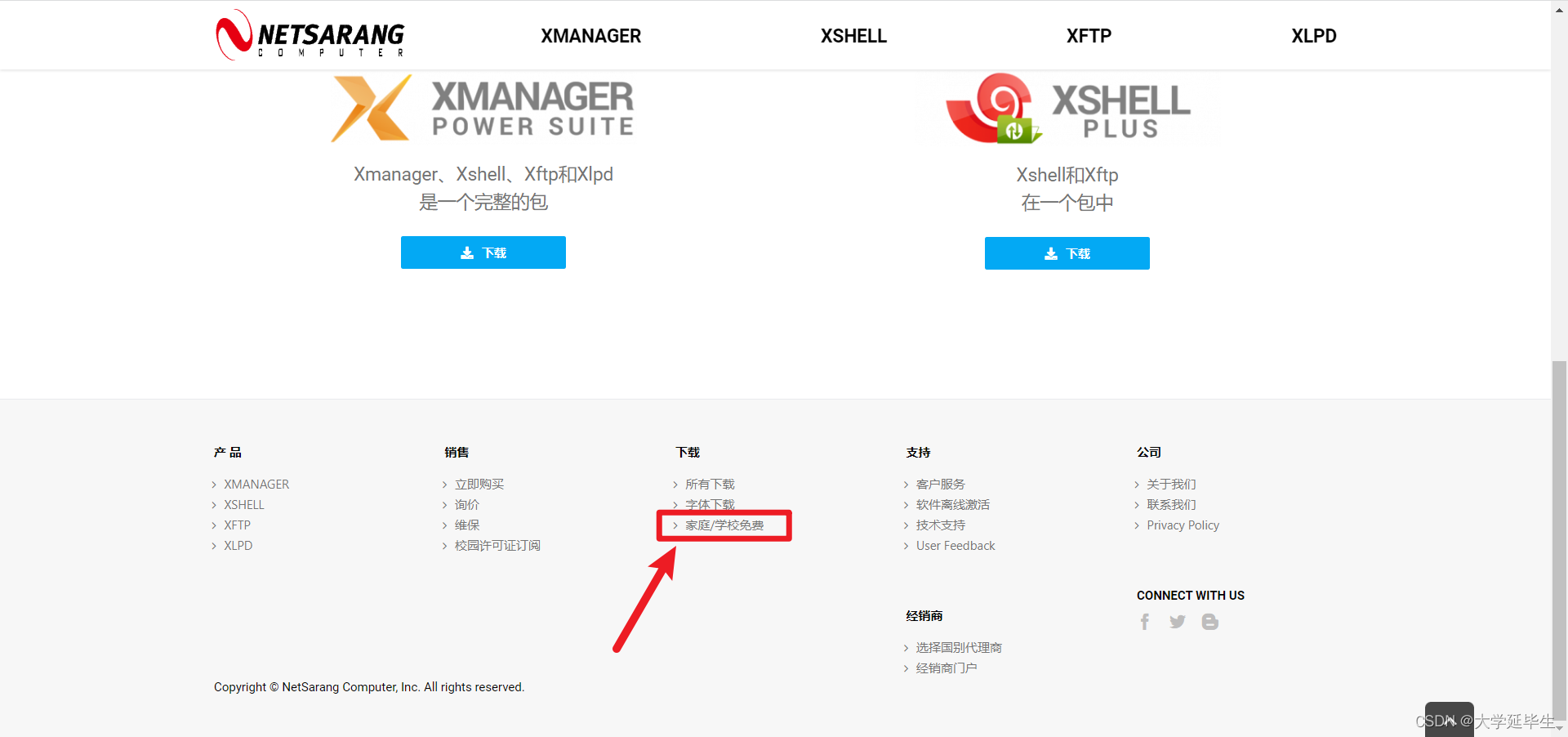
然后拖动到页面底部,点击下载专栏中的 “家庭/学校免费”,如下图所示。
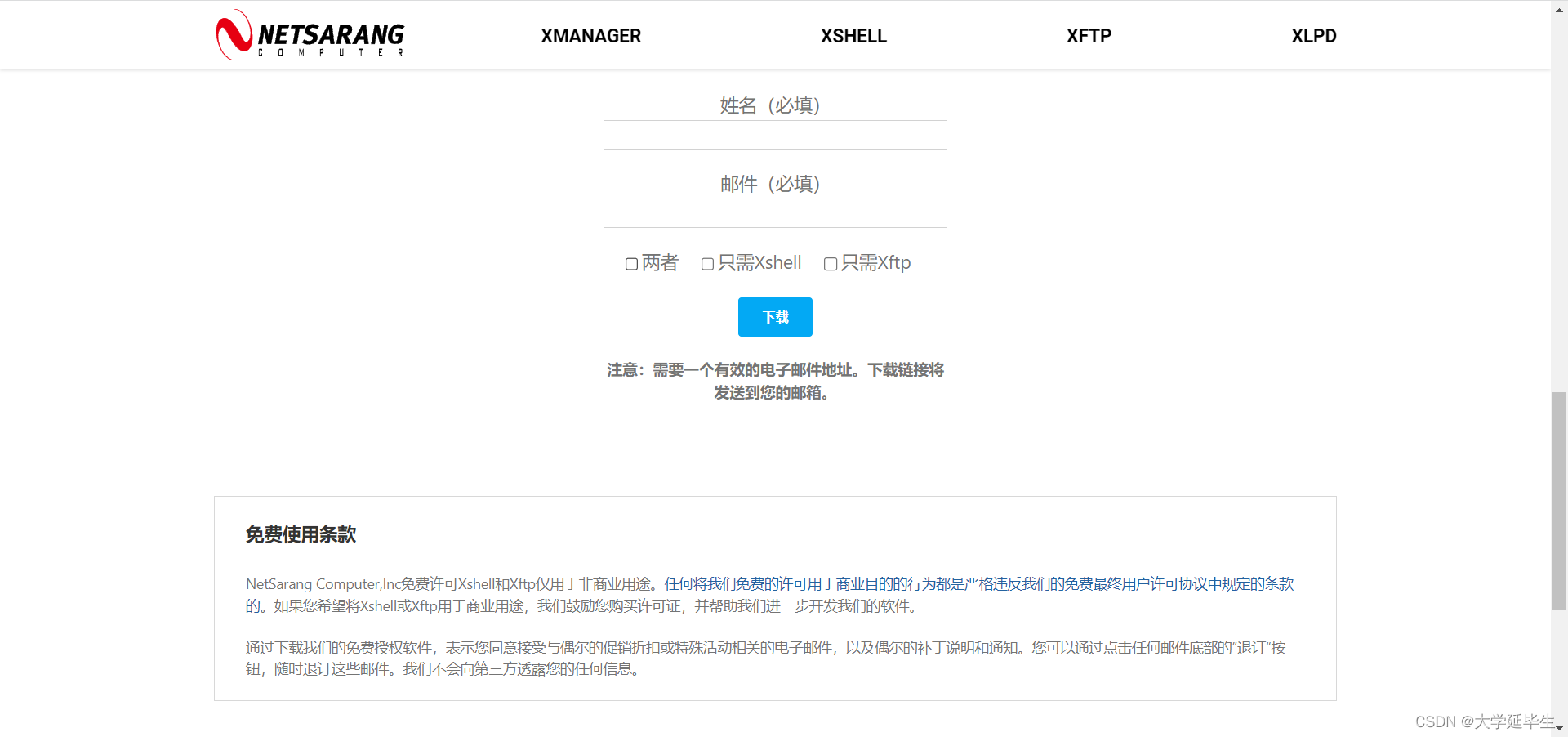
填写必要信息后,下载链接将免费发放到邮箱,如下图所示。
2.2 管理虚拟环境
使用上一步下载好的 Xshell 登录 GPU 服务器,并使用 Xftp 进行文件传输。
登录 GPU 服务器后,通过命令行安装 miniconda3,步骤如下:
① 下载 miniconda3 安装包:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh② 安装下载好的安装包(安装过程按照提示添加环境变量即可):
sh Miniconda3-latest-Linux-x86_64.sh ③ 在 miniconda 安装目录(一般是 /root/miniconda3 )的 bin 文件夹下执行激活测试:
source activate④ 测试是否安装成功。
conda env list若显示 conda 自带的 bash 虚拟环境且无报错,则证明 miniconda 安装完成,使用它可以管理虚拟环境。
2.3 创建虚拟环境
创建虚拟环境的命令:
conda create -n [env_name] [package_name] [python=2.7 or 3.6 et al] 激活虚拟环境:
source activate [env_name]退出虚拟环境:
source deactivate [env_name]删除虚拟环境:
conda remove -n [env_name] --all2.4 配置镜像源
以清华镜像源为例:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
查看成功安装的工具包:
conda list查看所有虚拟环境:
conda env list2.5 cuda、cudnn 的安装(以 pytorch 为例)
这里可以参考我之前的一篇文章:关于本机 CUDA 运行版与驱动版不匹配的解决方案_cuda驱动版本和运行版本不匹配怎么办_大学延毕生的博客-CSDN博客关于本机 CUDA 运行版与驱动版不匹配的解决方案https://blog.csdn.net/m0_59705760/article/details/125757532
3 总结
执行完上述所有操作后,便可以在 GPU 服务器(Linux 操作系统)上跑深度学习模型了,若服务器配置客观,则速度将得到显著的提升。