文章目录
- 1.数据仓库环境准备
- 1.1 导入依赖
- 1.2 创建相关包
- 2.数据仓库运行环境
- 2.1 Hbase环境
- 2.2 模拟数据
- 3.数仓开发之ODS层
- 3.1 mysql配置修改
- 3.2 FlinkCDC的程序
- 3.3 结果检测
1.数据仓库环境准备
1.1 导入依赖
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<flink.version>1.13.0</flink.version>
<scala.version>2.12</scala.version>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
<!--如果保存检查点到hdfs上,需要引入此依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<!--Flink默认使用的是slf4j记录日志,相当于一个日志的接口,我们这里使用log4j作为具体的日志实现-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<exclude>org.apache.hadoop:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. -->
<!-- 打包时不复制META-INF下的签名文件,避免报非法签名文件的SecurityExceptions异常-->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<!-- The service transformer is needed to merge META-INF/services files -->
<!-- connector和format依赖的工厂类打包时会相互覆盖,需要使用ServicesResourceTransformer解决-->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
1.2 创建相关包

log.properties
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n
log4j.rootLogger=error,stdout
2.数据仓库运行环境
需要搭建Flink, HBase, Mysql, Redis, ClickHouse 环境
2.1 Hbase环境
pom
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<!-- 注意:为了开启hbase的namespace和phoenix的schema的映射,在程序中需要加这个配置文件,另外在linux服务上,也需要在hbase以及phoenix的hbase-site.xml配置文件中,加上以上两个配置,并使用xsync进行同步(本节1中文档已有说明)。-->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration>
2.2 模拟数据
通常企业在开始搭建数仓时,业务系统中会存在历史数据,一般是业务数据库存在历史数据,而用户行为日志无历史数据。假定数仓上线的日期为2023-01-21,为模拟真实场景,需准备以下数据。
1)用户行为日志
用户行为日志,一般是没有历史数据的,故日志只需要准备2023-01-21一天的数据。具体操作如下:
(1)启动 Kafka。
(2)启动一个命令行 Kafka 消费者,消费 topic_log 主题的数据。
(3)修改两个日志服务器(hadoop102、hadoop103)中的
/opt/module/applog/application.yml配置文件,将mock.date参数改为2023-01-21。
(4)执行日志生成脚本lg.sh。
(5)观察命令行 Kafka 消费者是否消费到数据。

2)业务数据
实时计算不考虑历史的事实数据,但要考虑历史维度数据。因此要对维度相关的业务表做一次全量同步。
(1)维度数据首日全量同步
①修改Maxwell配置文件中的mock_date参数
[atguigu@hadoop102 maxwell]$ vim /opt/module/maxwell/config.properties
mock_date=2023-01-21
②启动业务数据采集通道,包括Maxwell、Kafka
③编写业务数据首日全量脚本
与维度相关的业务表如下
activity_info
activity_rule
activity_sku
base_category1
base_category2
base_category3
base_province
base_region
base_trademark
coupon_info
coupon_range
financial_sku_cost
sku_info
spu_info
user_info
切换到 /home/atguigu/bin 目录,创建 mysql_to_kafka.sh 文件
[atguigu@hadoop102 maxwell]$ cd ~/bin
[atguigu@hadoop102 bin]$ vim mysql_to_kafka_init.sh
#!/bin/bash
# 该脚本的作用是初始化所有的业务数据,只需执行一次
MAXWELL_HOME=/opt/module/maxwell
import_data() {
$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}
case $1 in
"activity_info")
import_data activity_info
;;
"activity_rule")
import_data activity_rule
;;
"activity_sku")
import_data activity_sku
;;
"base_category1")
import_data base_category1
;;
"base_category2")
import_data base_category2
;;
"base_category3")
import_data base_category3
;;
"base_province")
import_data base_province
;;
"base_region")
import_data base_region
;;
"base_trademark")
import_data base_trademark
;;
"coupon_info")
import_data coupon_info
;;
"coupon_range")
import_data coupon_range
;;
"financial_sku_cost")
import_data financial_sku_cost
;;
"sku_info")
import_data sku_info
;;
"spu_info")
import_data spu_info
;;
"user_info")
import_data user_info
;;
"all")
import_data activity_info
import_data activity_rule
import_data activity_sku
import_data base_category1
import_data base_category2
import_data base_category3
import_data base_province
import_data base_region
import_data base_trademark
import_data coupon_info
import_data coupon_range
import_data financial_sku_cost
import_data sku_info
import_data spu_info
import_data user_info
;;
esac
增加执行权限
[atguigu@hadoop102 bin]$ chmod +x mysql_to_kafka_init.sh
④启动 Kafka 消费者,观察数据是否写入 Kafka
[atguigu@hadoop102 bin]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_db
(2)业务数据生成
业务数据生成之前要将 application. properties 文件中的 mock.date 参数修改为业务时间,首日应设置为 2023-01-21。
同时要保证 Maxwell 配置文件 config.properties 中的 mock.date 参数和 application. properties 中 mock.date 参数的值保持一致。
3.数仓开发之ODS层
采集到 Kafka 的 topic_log 和 ods_base_db主题的数据即为实时数仓的 ODS 层,这一层的作用是对数据做原样展示和备份。
采用FlinkCDC去采集ODS数据
3.1 mysql配置修改
修改mysql配置
vim /etc/my.cnf
 、
、
加上binlog-do-db=gmall-210325-flink, 表示监视gmall-210325-flink库的全部表
3.2 FlinkCDC的程序
public class Flink_CDCWithCustomerSchema {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("localhost")
.username("root")
.password("root")
.databaseList("gmall-210325-flink")
.tableList("")
.deserializer(new CustomerDeserialization())
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = environment.addSource(sourceFunction);
streamSource.addSink(MyKafkaUtil.getKafkaProducer("ods_base_db"));
environment.execute();
}
}
自定义序列化格式
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
// 格式 Json
// database, tableName, type, before, after
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
JSONObject result = new JSONObject();
String topic = sourceRecord.topic();
String[] split = topic.split(".");
String database = split[1];
String tableName = split[2];
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null){
Schema schema = value.schema();
List<Field> fields = schema.fields();
for (int i = 0; i < fields.size(); i++) {
Field field = fields.get(i);
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null){
Schema schema = value.schema();
List<Field> fields = schema.fields();
for (int i = 0; i < fields.size(); i++) {
Field field = fields.get(i);
Object afterValue = before.get(field);
afterJson.put(field.name(), afterValue);
}
}
// 操作字段
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("create".equals(type)){
type = "insert";
}
System.out.println(operation);
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
Kafka工具类
public class MyKafkaUtil {
public static String KAFKA_SERVER =
"hadoop102:9092,hadoop103:9092,hadoop104:9092";
public static String default_topic = "DWD_DEFAULT_TOPIC";
private static Properties properties = new Properties();
static {
properties.setProperty("bootstrap.servers", KAFKA_SERVER);
}
public static FlinkKafkaProducer<String> getKafkaProducer(String topic) {
return new FlinkKafkaProducer<String>(topic, new SimpleStringSchema(), properties);
}
}
开启Kafka和Zookeeper
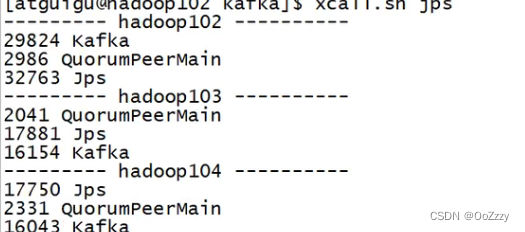
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap.server hadoop102:9092 --topic ods_base_db
3.3 结果检测
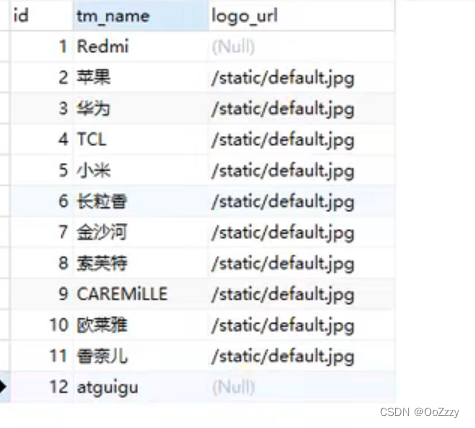
在表中z_user_info中加入 [12, atguigu] 这条数据。
因为在CDC中设计的是监视的为database中所有的表
java程序:

Kafka程序:








![[引擎开发] 现代图形API - dx12篇](https://img-blog.csdnimg.cn/a203677ff6e4424da620784472d88681.png)