图的大部分知识在《离散数学》中都已经学习了,所以我主要放一些不知道的知识
常用概念
- 有很少边或弧(如 e < n log n,e指边数,n指顶点数)的图称为稀疏图,反之称为稠密图。
- 完全图:每个顶点的边数为n-1,与其他任何一个点都有边相连
- 有向图的入度和出度
- Havel定理判断是否可图化
- 邻接矩阵
有向图
邻接表


权


这种方法无法存储平行边



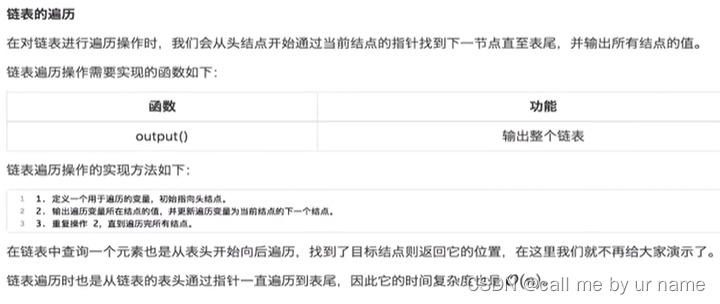
链表在之前学c语言时学过

树
- 路径
无向图 - 回路

[NOI2000] 单词查找树
在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里。为了提高查找和定位的速度,通常都要画出与单词列表所对应的单词查找树,其特点如下:
- 根节点不包含字母,除根节点外每一个节点都仅包含一个大写英文字母;
- 从根节点到某一节点,路径上经过的字母依次连起来所构成的字母序列,称为该节点对应的单词。单词列表中的每个词,都是该单词查找树某个节点所对应的单词;
- 在满足上述条件下,该单词查找树的节点数最少。
例:图一的单词列表对应图二的单词查找树

对一个确定的单词列表,请统计对应的单词查找树的节点数(包括根节点)
输入格式
一个单词列表,每一行仅包含一个单词。每个单词仅由大写的英文字符组成,长度不超过 63 63 63 个字符。文件总长度不超过 32K,至少有一行数据。
输出格式
仅包含一个整数。该整数为单词列表对应的单词查找树的节点数。
样例输入 #1
A
AN
ASP
AS
ASC
ASCII
BAS
BASIC
样例输出 #1
13
思路
- 出现不同的字母时,需要增加一个结点
- 当字符串的前面的字符次序与之前出现过的字符次序相同时,可以借用之前的结点
- 所以,将字符串排序,这样就可以得到两个字符串公共部分后的首个不同字符,并增加相应的结点数
- 这道题比较简单
#include<bits/stdc++.h>
using namespace std;
string s[100000];
int ans=0,len=1,flag;
int main(){
while(cin>>s[len]) ++len;
sort(s+1,s+len+1);
for(int i=1;i<=len;++i){
if(i==1) ans+=s[1].length();
else {
flag=0;
while(s[i-1][flag]==s[i][flag]&&flag<s[i-1].length()) ++flag;
ans+=s[i].length()-flag;
}
}
printf("%d",ans+1);
}
这一部分的知识点,我倒是没有找到很切合的题目来做离散数学课上给的实验作业应该算是比较切合的练习了💀
![[引擎开发] 现代图形API - dx12篇](https://img-blog.csdnimg.cn/a203677ff6e4424da620784472d88681.png)