本文将从性能优化的角度去阐述像dx12这样的现代图形API的一些设计理念。
当我们深入优化渲染管线的时候,我们会发现存在的几个瓶颈主要是这样的:
① 线程存在不合理的等待
② CPU向GPU编码传输数据非常耗时
③ CPU频繁地切换渲染上下文非常耗时
因此有时候我们去说一个游戏的优化好,我们可能会说它的GPU占用率高,或者说是drawcall数量少,这和上面的内容都是相关联的。
在传统的图形API中,我们依然可以针对这些问题去做一些优化,只不过这些优化是更加上层的,比如说从资产的层面去减少绘制数量,减少材质种类,或者说从代码层面做一些静态动态合并,绘制排序的操作。而在实际的渲染提交层我们能做的事情并不多,换句话来说有很多事情是不可能去达成的。而现代图形API开放了更多底层的控制接口,这就让很多不可能的事情变成了可以实现的事情。
图形API的迭代
在传统图形API中,我们绘制一个物件,可能涉及到的代码如下:
UpateResource(); // 更新相关的资源
SetRenderState(); // 设置渲染状态,比如深度比较,混合状态等
SetShader(); // 使用哪个shader,加载并编译
SetShaderInput(); // 设置shader参数,比如输入的系数、纹理等,输出的位置
Drawcall(); // 提交绘制整个流程有如下的一些特点:
① CPU发出指令后,GPU会立即执行;同步的内容由API来控制
② 每次提交前都需要在CPU端单独的去绑定相关资源、更新当前的渲染状态
③ 整个渲染调用只能在单线程上进行
④ 只能直接申请资源,分配的位置等不可控
而现代图形API,包括dx12,vulkan和metal,基本上都引入了如下的概念
① 渲染命令非即时提交,而是录制后提交 -> 为多线程渲染提供可能
② 使用PSO(PipelineStateObject)快速切换渲染状态 -> 每个指令需要显式地绑定对应地PSO,可以减少上下文切换的消耗
③ 提供可控的内存分配堆 ->更精细的内存控制,为虚拟内存提供可能
④ 间接索引的绑定设计,可在GPU端通过动态索引读取资源 -> 减少绑定带来的消耗
⑤ 需要手动指定资源的同步,通过设置资源前后的状态来实现 -> 更精确地同步控制
⑥ 支持间接绘制 -> 为GPU驱动提供了可能
工作提交
设计理念
我们先工作提交设计理念开始谈起。
传统的CPU准备渲染数据的工作流是即时制的,整个流程是比较简单的,也就是CPU准备渲染数据,然后把渲染数据提交给GPU,GPU接收到数据后,开始执行渲染绘制的操作,然后如此反复。在这个过程中,当CPU准备数据的时候,GPU会等待CPU的数据,而在GPU执行渲染的时候,CPU也需要等待GPU绘制完成。这就意味着硬件利用率的下降。
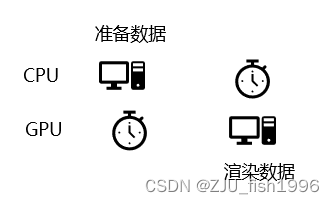
从优化的角度考虑,我们期望能够尽可能减少这种等待,因此当我们在说减少drawcall的时候,说的就是减少CPU准备渲染数据的时间,渲染数据能够越早地被提交到GPU,GPU就能更快地开始工作。
传统的即时制工作流类似于两个人口口相传的工作形式,也就是CPU告诉GPU要做什么,GPU做完了反馈给CPU,CPU再准备接下来的工作;而现代图形API引入了录制(record)的理念,这意味着CPU给GPU的工作不再是直接传递的,而是被记录到工作清单中,GPU根据这份清单记录的内容开始工作。
这意味着CPU端可以同时记录多份工作列表,可以控制什么时候把工作列表提交给GPU(为多线程渲染提供了可能),GPU端不同模块可以分别取接收自己的任务然后开始处理(为异步计算提供了可能)
现代硬件
现代硬件的特点是CPU有多个线程(多核架构),这意味着我们可以使用多个线程来准备渲染数据,加速渲染提交的时间,减少GPU的等待。

GPU包含多个通道,分别是Graphics Engine,Compute Engine和Copy Engine。其中,图形引擎有一个,而计算引擎有多个,复制引擎有两个。这些通道是可以并行处理任务的,这意味着如果想要提升GPU的利用率,我们应该尽早开始执行复制和提交一些可异步计算的内容。
基础概念

dx12中,我们使用CommandList来记录每一项工作,使用CommandAllocator来进行CommandList的分配,使用CommandQueue来执行一条或多条CommandList。
我们可以通过device(虚拟设备)来创建CommandQueue, CommandAllocator和CommandList,创建CommandList时,需要绑定对应的Command Alloactor。它们都包含了Direct/Compute/Copy三种类型,这和GPU通道是相对应的。
pDevice->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(pCommandAllocator)));
pDevice->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, pCommandAllocator, pPipelineState, IID_PPV_ARGS(&pCommandList)));
pDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&pCommandQueue)));Command Queue
CommandQueue用于串行化执行CommandList,并管理commandList的同步状态,我们可以通过Signal和Wait来确定某个工作单位是否完成,并注册一些回调函数。
pCommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);ExecuteCommandLists本身有一定的开销,包括pipeline的刷新等,所以我们应该避免频繁提交较小的CommandList。
Command Allocator
CommandAllocator用于给CommandList分配内存,多个不同的CommandList可以关联到同一个CommandAllocator,但同时只能有一个CommandList录制,并且我们不能从多线程去访问Allocator,这意味着当我们多线程录制的时候,需要维护多个Allocator。
一旦创建了CommandAllocator,我们将无法缩小其内存占用,只能通过调用Reset使其可以重新分配i虚拟的命令,此时分配点会移动到初始位置。该过程通常在每帧执行一次:
m_commandAllocator->Reset();
Command List
在CommandList中,我们可以像D3D11DeviceContext那样,执行一些渲染指令,如SetVertexBuffers,DrawIntances等,只不过这些指令是录制的,而非即时执行的,并且是单线程执行的。
特别的,对于渲染状态而言,在dx11时代是由设备的上下文维护的,而现在则是和CommandList强绑定的,这意味着我们在创建CommandList的时候需要为其指定独立的PipelineState,而不是直接从设备的上下文中获取(状态非继承)。除了PipelineState外,CommandList还需要维护资源的同步状态。
调用Close结束录制,完成提交后调用Reset以支持重新录制。
m_commandList->Close();
m_commandList->Reset(m_commandAllocator.Get(), m_pipelineState.Get());
Bundle
我们可以把一组固定的渲染命令绑定为一个bundle进行提交,这样可以节省一些CPU的开销,比如一些比较固定的后处理。
Pipeline State Object
dx12使用PSO来描述pipeline的大部分渲染状态。
和dx11中运行时设置的状态量相比,PSO是可以提前编译缓存下来的,称为PSO Cache,如在程序初始化的时候。它包含的最主要内容是Shader Code, 除此之外还有一些Shader相关的状态,比如根签名、图元类型、顶点格式、混合状态、深度模板状态、渲染目标格式和数量等。
此外,CommandList可以直接设置视口、绑定的资源、裁剪矩阵、混合因子等,这些不属于PSO状态。
相比起原有的上下文状态量设置,PSO的优点是:
① 在创建CommandList时就指定PSO,不需要等到发起drawcall的时候才知道最终的渲染状态
② 直接一次性绑定了所有状态量,驱动不需要跟踪状态的变化,省去了这部分的开销;此外,硬件的某些特性依赖于多个状态输入,一次性绑定也解决了与硬件状态不对应的问题

资源屏障
资源的同步原本是驱动的工作,现在这一工作转移到了应用层。
资源同步是通过Resource Barrier来实现的(资源屏障),也就是在使用一个资源的时候,我们主动地设置这个资源转换前后的状态,驱动层再根据设置的状态来做一些线程调度,控制哪些任务需要等待上一个任务完成,而不去主动跟踪这个状态。当我们添加了屏障的时候,就意味着可能产生等待。

资源屏障的类型包括了转换屏障,失真屏障和UAV屏障。
Aliasing屏障我们会在虚拟内存映射中使用到,用于描述当前资源的有效性;UAV屏障主要用于多个cs访问相同UAV时,这些cs能否并行执行(UAVOverlap),还是需要等待。
其中转换屏障是最常用的,如下是一些非常常见的例子:
① 一个纹理在上一个pass用作Render Target输出,下一个pass用作着色器的输入(SRV),这个时候它将从可写变成只读,所以我们要添加一个转换屏障:
StateBefore = D3D12_RESOURCE_STATE_RENDER_TARGET;
StateAfter = D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE;② 上传一段数据作为顶点缓冲区:
StateBefore = D3D12_RESOURCE_STATE_COPY_DEST;
StateAfter = D3D12_RESOURCE_STATE_VERTEX_AND_CONSTANT_BUFFER;③ 把准备好的渲染目标显示
StateBefore = D3D12_RESOURCE_STATE_RENDER_TARGET;
StateAfter = D3D12_RESOURCE_STATE_PRESENT;由于资源屏障本身是会带来消耗的,它会阻塞指令的执行,所以我们通常只在有必要同步的时候才会创建屏障,并且最好等到使用资源前才开始设置。
在如下情况下,资源状态会发生隐式转换,如:
① GPU访问数据后,会从Common状态变成Shader可读状态
② GPU完成ExecuteCommandList后,资源变成COMMON状态
我们可以利用资源的promoteh和decay消除不必要的屏障。
此外,我们还可以通过给屏障设置如下flag,通过拆分屏障来优化一些等待:
D3D12_RESOURCE_BARRIER_FLAG_BEGIN/END这可能是因为我们要去做一些其它的GPU工作,但和这个资源无关。 当我们设置了BEGIN的flag后,这个资源屏障会处于等待状态,还不会开始执行。等我们要访问到这个资源前,我们再去将flag设置为end,此时资源屏障停止等待,开始工作。
Swap Chain
屏幕绘制通常会使用双缓冲机制,用于确保显示的时候可以准备下一帧的绘制数据。当前正在显示的缓冲区称为front buffer,而我们正在绘制的缓冲区称为back buffer。
当我们在back buffer上完成绘制时,将使用swap chain来交换前后缓冲区。准备好的back buffer成为front buffer开始显示,而不再使用的front buffer成为back buffer以供下一帧绘制数据的准备。
性能优化:多线程渲染
在我们讨论多线程渲染之前,我们首先需要理清一些概念,那就是究竟是什么任务在并行。
在渲染中有一个pass的概念,我们可以把它理解为一个总的渲染任务,比如阴影的绘制是一个pass,场景的绘制是一个pass,单个的后处理是一个pass;每个pass可以包含多个drawcall,但是这些drawcall最终都会输出到同样的渲染目标上。
从CPU端考虑,可能存在的并行就包括了不同pass的并行,以及相同pass内不同drawcall的并行。前者意味着我们可以同时编码不同的pass,而对于后者来说,当单一pass的任务数量非常多的时候我们能够加速单个pass编码的效率。
从GPU端考虑,我们考虑不同GPU任务之间的重叠执行,也就是Async Compute和Graphics pass的配对执行。由于GPU的资源是有限的,我们尽可能让瓶颈不一样的任务配对到一起。
此外,还需要考虑到不同pass之间可能会存在等待关系,比如说某个pass的输入依赖于上一个pass的输出,这在常规的渲染中是很常见的。因此在应用并行的时候,我们还应该保证渲染的执行顺序在GPU上也是一致的。
总的来说,设计多线程渲染的时候,我们需要考虑的事情非常多,包括pass之间的并行和pass内的并行,pass的重叠,以及pass之间的依赖关系等。另外,需要知道device和CommandQueue都是自由线程调用的,而CommandList只能单线程调用。
要在d3d12中实现多线程渲染,我们设置一个主渲染线程,多个工作线程。其中主渲染线程把任务分配给子工作线程去处理,而子工作线程必要时通知主渲染线程当前的状态。最后,在所有工作结束后,主渲染线程提交CommandList。
主渲染线程:
void MainRenderThread()
{
for WorkThread in WorkThreadList
WorkThread.Start(); // 发起工作
// prepare pre command list
WaitForWorkThread(WorkThread1);
pCommandQueue->ExecuteCommandList(WorkThread1);
WaitForWorkThread(WorkThread2);
pCommandQueue->ExecuteCommandList(WorkThread2);
// prepare post command list
pSwapChain->Present(); // 绘制
}工作线程:
void RenderWorkThread()
{
WaitForWorkThreadStart(WorkThread1);
// prepare command list 1
Finish(WorkThead1); // 通知渲染任务完成
}性能优化:异步计算
GPU端有多个Compute Engine,这意味着我们可以实现两种意义上的异步,一个是计算任务和图形任务的并行(如果不存在依赖关系),另一个是不同计算任务之间的并行。
异步计算能够占用多少线程,取决于graphics任务剩余多少没有利用的Shader Core,可以理解为整体的GPU资源,包括带宽,ALU等是有限的,我们可以利用一些比较空闲的资源来提升GPU的利用率。
这里所说的Shader Core是一个硬件单元,它包含了16/32个计算核心,L1缓冲,纹理读取单元,寄存器,指令缓存等。通常来说,GPU执行指令是以线程组为最小单位的,我们把它称为一个线程束(warp),一个线程束可能对应了硬件上的一个或多个Shader Core,warp内通常包含32个线程。
在计算着色器里,我们指定的一个线程组,就对应一个warp,我们使用的线程组内的共享变量,实际上就是L1 Memory。

性能优化:PSO Caching
由于PSO的创建比较耗时,所以在项目开发中,我们通常会去预加载并且缓存PSO。
为了方便查询当前绘制使用到的PSO,通常会去维护一个HashMap来记录所有可用的PSO,并且为每个资源分配一个ID,考虑到程序的状态量比较复杂,生成ID的算法也会考量到PSO的单项属性并做HashCombine,我们需要确保ID在尽可能地紧凑,并且占用较小的内存字节数。
PSO创建中,其中比较耗时的一步是读取shader code并编译为二进制,如果这一步在运行时做会带来卡顿;因此我们会提前处理好这些数据,并且对于shader code相同仅其它状态不同的PSO,我们可以复用已经编译好的shader。
为了做PSO Cache,需要预先知道有哪些可能存在的PSO,如果通过排列组合可能会导致一些不必要的PSO生成,因此我们需要去做一个PSO的收集工作,手动运行项目并记录整个流程中使用到的PSO是一种常见的做法。
另一方面,我们应该尽可能控制PSO的数量:
① 减少所需的shader种类
② 避免一些冗余的PSO,比如关闭了深度测试又设置了不同的深度比较状态,此时会产生多个PSO,但是代表的含义是一致的
资源绑定
资源绑定,也就是将资源对象绑定到着色器上的过程。
dx11的绑定是基于固定的slot进行绑定的,所有传入着色器的资源都需要分配一个固定的slot id进行绑定。而dx12的绑定则更为灵活,资源绑定的形式和数量可以是非限定的。
设计理念
dx12将绑定设计的更加轻量级。
从资源来看,与原本的强类型资源不同,它认为所有的资源都是显存中分配的Buffer或Texture。为了描述这段Buffer/Texture在实际渲染流程中的类型,dx12使用“描述符”作为绑定单元来引用对应的资源,描述符类似于指向对象的指针,不包含实际的分配内容,同一个资源在不同管道中可对应不同的描述符。
对于着色器而言,输入的资源排列通过“根签名”来描述。根签名和dx11中资源Slot的功能有些类似,它描述了有哪些资源会绑定到着色器上,类似于函数的形参。不一样的地方在于,除了部分常量是直接存储在根签名中,根签名主要是直接或间接地记录了描述符对象。
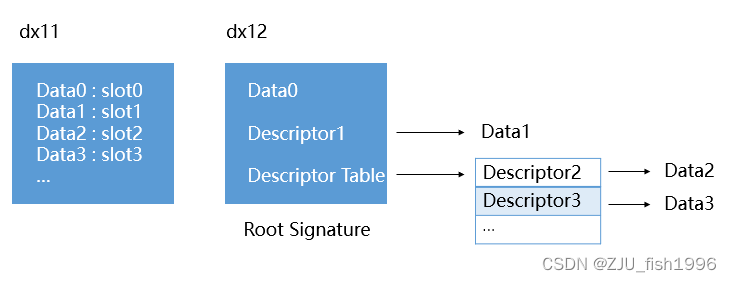
从上图我们可以很好的理解dx12的绑定设计,和dx11直接固定的绑定模式相比,dx12除了绑定参数,还可以绑定资源的引用(描述符),或者资源引用数组的引用(描述符表)。这种分离式间接绑定的机制让绑定描述(根签名)以及资源引用数组(描述符表)变得更轻量。
这种轻量体现在两个方面,一个是内存占用本身变小了,二是更新频率降低了,因为当我们改变指针指向对象的内容时,不需要改动指针本身。
绑定槽(slot)依然是存在的,只不过间接索引使得绑定槽的数量可以变得更少了。
在这种轻量资源绑定模式下,API得以把资源的一些其它属性也分离开来,交由用户来管理,包括:
① 资源的转换关系(如可写到只读)
② 资源的生命周期 (释放后描述符不再引用)
③ 资源在CPU到GPU的映射(上传,更新与回读)
④ 资源的常驻状态(虚拟内存)
基础概念
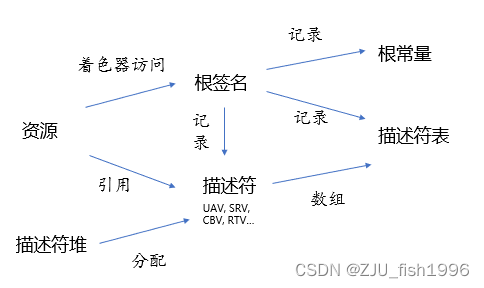
Root Signature
对于着色器而言,根签名类似于函数签名,它描述了shader使用资源的类型。根签名可以绑定如下几种类型的对象:
(1) 描述符表(Descriptor Table)
-- D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE
(2) 描述符(Root Descriptor)
--D3D12_ROOT_PARAMETER_TYPE_CBV, D3D12_ROOT_PARAMETER_TYPE_SRV, D3D12_ROOT_PARAMETER_TYPE_UAV
(只能绑定CBV, buffer/structuredbuffer的UAV/SRV,不能绑定texture等)
(3) 根常量(Root Parameter) -- D3D12_ROOT_PARAMETER_TYPE_32BIT_CONSTANTS
(在shader中显示为常量缓冲区,单个常量为32位的)
使用更多的内联的描述符和根常量会导致根签名占用空间变大,而使用更多的描述符表会带来更多的间接绑定。
特别的,我们在根签名记录的采样器是静态采样器,而在描述符堆里记录的是动态采样器。
我们可以基于设备进行根签名的创建:
pDevice->CreateRootSignature( pSerializedRootSig->GetBufferPointer(),pSerializedRootSig->GetBufferSize(), __uuidof(ID3D12RootSignature), &pRootSignature)根签名实际上会描述为字符串,因此我们创建根签名的时候可能是序列化读取的:

在CommandList中设置对应的根签名:
pCmdList->SetGraphicsRootSignature(pRootSig);此外,我们也可以直接向PSO中传入根签名,通过在创建PSO的时候,在D3D12_GRAPHICS_PIPLINE_STATE_DESC中输入ID3D12RootSignature(可选),这样编译器可以尽早验证布局的兼容性。如果未在PSO中设置根签名,那么将会使用CommandList中设置的。
我们应该尽可能确保根签名较小,并且避免根签名的频繁更改。为了让根签名尽可能小,可以通过尽可能使用描述符堆,而使用尽可能少的根常量来实现;为了避免根签名的反复修改,我们可以让多组PSO共享相同根签名,仅单独设置对应的绑定内容。
为了避免创建过大的根签名,dx12将根签名的大小限制为64 * 32位。描述符表和根常量都是32位的,根描述符是64位的。根签名过大会使得高速缓存无法容纳从而导致访问性能的下降,所以如果不得以使用了较大的根签名,可以把高频访问修改的数据放在前面。
Descriptor
描述符是GPU资源属性的描述,它用于shader中资源的绑定。由于不存储资源内容,它的内存占用很小,并且描述符不属于管道状态对象(PSO)
描述符包含了多种类型:
RTV(render target view) :渲染目标视图,可写入的纹理
DSV(depth stencil view):深度模板视图,可写入深度和模板
SRV(shader resource view):着色资源视图,可读的资源
CBV(constant buffer view) :常量缓冲区视图,可读的常量
UAV(unordered access view):乱序访问视图,可乱序写入的缓冲区(用于计算着色器)
Sampler:采样器
其中,RTV, DSV, SRV, SBV, UAV和Sampler都可以从设备上直接创建:
ID3D12Device::CreateShaderResourceView
ID3D12Device::CreateConstantBufferView
ID3D12Deivce::CreateSampler
ID3D12Device::CreateUnorderedAccessView
ID3D12Device::CreateRenderTargetView
ID3D12Device::CreateDepthStencilView而像SOV(streaming output view) ,IBV(index buffer view),VBV(vertex buffer view),它们无法位于Descriptor Heap中,只能调用CommandList接口直接设置:
ID3D12GraphicsCommandList::IASetIndexBuffer
ID3D12GraphicsCommandList::IASetVertexBuffer
ID3D12GraphicsCommandList::SOSetTargets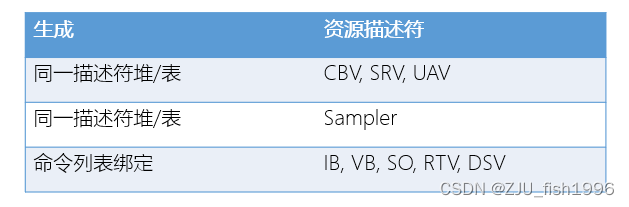
Descriptor Heap
描述符堆用于连续分配描述符。
CBV, UAV, SRV可以位于相同的描述符堆中,而采样器只能位于独立的描述符堆中。考虑到描述符堆的切换比较耗时,并且我们最多只能绑定一个CBV/SRV/UAV堆和一个采样器堆,我们在应用程序中通常只维护这两个描述符堆。
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV
D3D12_DESCRIPTOR_HEAP_TYPE_SAMPLER
D3D12_DESCRIPTOR_HEAP_TYPE_RTV
D3D12_DESCRIPTOR_HEAP_TYPE_DSV在可见性上,所有descriptor heap对CPU都是可见的。而对于GPU而言,RTV/DSV总是不可见的(我们只能通过FragColor等间接的写入当前像素位置),CBV/SRV/UAV/Sampler可以人为地指定可见性,如果指定为shader可见的,则会直接在GPU堆上创建描述符;
反之,如果不可见,则使用CPU内存,可用于暂存描述符,必要时可以复制到GPU可见堆(CopyDescriptors)。这是源于单个可见的描述符堆是由硬件大小限制的,而非可见描述符堆则不受限制。
D3D12_DESCRIPTOR_HEAP_FLAG_NONE
D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE我们可以调用device的接口直接创建描述符堆,并通过CPU/GPU句柄来访问描述符堆中的位置:
m_device->CreateDescriptorHeap(&srvUavHeapDesc, IID_PPV_ARGS(&m_srvUavHeap));需要注意的是,描述符并不是由描述符堆直接创建的,如前所述是从设备上创建的,但是在创建的时候需要我们指定描述符堆的句柄。
通过CommandList的接口来设置引用的描述符堆(只能设置sampler, CBV_SRV_UAV)
m_commandList->SetDescriptorHeaps(_countof(ppHeaps), ppHeaps);Descriptor Table
描述符的数组,也是我们在根签名中可以绑定的对象。

和描述符堆不同,描述符表并不包含实际的内存分配,只是描述符堆的一个区域描述。
通过描述符表,在根签名中我们只需要一次绑定,就能绑定表内的所有资源,考虑到绑定本身是非常耗时的,这能极大地降低CPU端的绑定消耗,我们认为描述符表的绑定修改开销是较低的。此外,由于描述符表可以记录很多的数据,这意味着shader可以读取的资源也更多了。
性能优化:动态索引
资源绑定的改动,在另一层面上有一个非常重大的意义,这意味着我们可以在shader中动态地从描述符表中索引数据了(自SM5.1起):
Texture2D<float4> textures[] : register(t0);
color = textures[1].Sample(sampler, uv);作为对比,在原有的API中,相同的逻辑,我们只能这样实现:
Texture2D<float4> textures0: register(t0);
Texture2D<float4> textures1: register(t1);
color = textures1.Sample(sampler, uv);这意味着我们可以在shader动态索引纹理、缓冲区等数据了,利用这个特性,我们可以应用到像地形这样的融合材质中,取代TextureArray技术;也可以合并相似材质物件的提交。
显存管理
资源的管理涉及到了以下几个模块,一个是描述资源的显存分配,另外一个是描述资源在CPU和GPU之间的传输,还有一个是资源的生命周期维护。相比起原有的API,dx12对显存管理的重构使得如下操作成为可能:
① 提升资源分配的效率
② 减少显存的整体消耗
③ 提升显存的利用率
④ 显式管理资源更新时的同步
GPU内存模型
在GPU的内存模型有两种不同的形式,一种是离散的GPU,这意味着相同的数据在CPU和GPU上有两份拷贝,另一种是通用内存体系结构(UMA),也就是相同的数据在CPU和GPU中只有一份拷贝。
UMA由于通用的设计,在数据传输上较为简单,我们只需要在创建纹理的时候标记这个纹理是仅GPU访问的,还是CPU也可访问的。对于仅GPU访问的,硬件可做一些特别的优化。
而离散GPU由于分离的存储,设计上会更加复杂。所以dx12的设计会去考虑分离GPU的架构,也就是涉及到了CPU和GPU间数据的交互和传输,同时,也避免了对UMA架构带来额外的开销。
显存管理
显存分配
堆(Heap)是连续分配的显存块,我们认为资源是从堆上创建的;我们创建堆时,实际上也就分配了对应的物理页面。
在dx11中,堆的概念是隐藏的,也就是当我们分配资源的时候,会从一个隐式堆中分配,并能直接获取到对应的物理页面;而在dx12中,依然保留了隐式堆的概念,但同时开放了自定义堆,也就是我们可以手动申请一段连续的显存,并从这段显存上创建各种资源,资源只是指向了特定堆的某个位置,并不和物理页面强绑定。
由于堆的分配是比较耗时的,所以我们通常会从预分配的比较大的显存中进行一些子分配(Sub-allocate)。通过子分配,我们可以:
① 减少申请堆的次数 ② 减少总体使用的显存(显存可重用) ③ 减少显存碎片
在分配子资源的时候,我们需要遵循对齐规律:
① 线性资源对齐512字节 ② 常量读取对齐256字节 ③ 索引对齐索引数据类型的倍数
如果我们的应用程序分配了过多的显存,操作系统会冻结当前进程,交换页使得其它进程也可使用显存,新的分配可能会失败,我们可调用如下接口查询显存使用情况:
IDXGIAdapters3::QueryVideoMemoryInfo资源类型
在dx12中,我们认为GPU资源有两种类型:Buffer和Texture(1D/2D/3D),它们在内存布局上存在差异,缓冲区是线性布局的,而纹理可能是行主序的线性布局,也可以是Swizzle布局。 此外,硬件可能会针对纹理结构做一些访问上的优化。
从显存分配的角度来看,我们又可以把资源分为如下三种类型:
① Commited Resource (已提交的资源)
② Placed Resourse(定位的资源)
③ Reserved Resource(保留的资源)

其中,已经提交的资源是兼容了原有API的概念,简单来说,它是通过系统隐式默认堆分配的,我们无法对其有更为底层的操作,如获取到默认堆,或者修改虚拟地址的映射。它的创建开销较大,通常用于每帧使用的高频资源。
定位资源和保留资源是dx12引入的新概念。
定位资源的设计思路和描述符类似,它并不直接对应物理页面的创建,只是指向显式堆的指针,这意味着它非常轻量级,可以快速创建和销毁,并且支持资源重叠(共享显存,同时只有一个处于激活状态)。但是,我们如果想要重映射地址,只能销毁并重新创建;并且如果我们想要将资源设置为常驻或非常驻的,只能以整体为单位来进行。
如果我们希望资源只有部分Tile处于常驻状态,其余部分不映射到显存,我们可以使用Reserved资源。它具有唯一的虚拟地址空间,并且可支持动态地部分映射到显式堆。
我们可从设备上直接创建这三种类型的资源:
ID3D12Device::CreateCommittedResource
ID3D12Device::CreatePlacedResource
ID3D12Device::CreateReservedResource 数据更新
从堆的功能来看,我们可以分为三种类型:
① 默认堆(Default Heap)。仅GPU访问的显存。
② 上传堆(Upload Heap)。用于CPU上传数据到GPU,对CPU写入做了优化。
③ 回读堆(Readback Heap)。用于从GPU回读数据到CPU。
我们常用的资源从更新频率来看包含以下几种:
① GPU资源。只会在GPU中填充或者访问的纹理,比如渲染目标,我们可以直接在默认堆上创建。如果想要从CPU端访问这些数据,需要借助于回读堆。
② 静态资源。像是输入的美术纹理资产,这些数据通常依赖于CPU去填充,但一般只会填充一次,多帧内不会动态修改。所以我们会借助上传堆来把数据从CPU拷贝到GPU中。
③ 动态资源。每帧都可能发生变化的一些资源,这通常会发生在常量缓冲区,顶点缓冲区等,这就会涉及到资源的更新。

如果我们想要动态地更新或初始化数据,我们使用上传堆。上传堆是CPU和GPU沟通的桥梁,是一段共享内存,我们通常在CPU端写入上传堆,在GPU端读取上传堆。
要想将数据从内存到显存,我们需要两步拷贝,一个是从CPU内存到上传堆,另一个是从上传堆到GPU默认堆。
首先我们需要创建一个上传堆,我们可以通过两个接口创建,因为它们都会实际的去分配显存,只需要把类型指定为D3D12_HEAP_TYPE_UPLOAD:
ID3D12Device::CreateCommittedResource
ID3D12Device::CreateHeap接下来,我们通过Map拿到上传堆的CPU句柄,并手动把数据拷贝到上传堆:
m_spUploadBuffer->Map( 0, &readRange, &pData );
memcpy(pData, pData, byteSize);最后,对于缓冲区/纹理资源,我们可以主动调用如下函数将数据从上传堆写入默认堆:
ID3D12GraphicsCommandList::CopyTextureRegion
ID3D12GraphicsCommandList::CopyBufferRegion在dx11中,Map和Unmap是一组配对使用的函数,Map允许我们获取GPU资源的CPU指针,它会阻塞,直到资源可在CPU访问;调用Unmap后,数据被同步到GPU。
而在dx12中,我们可以对上传堆做Map,不能对默认堆做Map,这个调用是即时的,返回的地址一直有效可以缓存下来,我们不需要即时调用Unmap,仅在资源释放后调用Unmap,可让内存地址空间可以被系统回收。调用Map时资源的有效性需要我们添加屏障来保证。
资源驻留
在创建了资源之后,我们就能拿到对应的GPU虚拟地址,我们可用这个虚拟地址做一些绑定,但这不一定代表资源映射到对应的物理内存。
当我们可在GPU上访问到资源时,我们认为资源是驻留的(Resident),反之,我们认为其是非驻留的(Evict)
ID3D12Device::MakeResident
ID3D12Device::Evict以上过程作用于实际分配了显存的Committed Resource和Heap,在这个过程中,虚拟地址不会发生变化。其中,MakeResident是一个阻塞函数,会在完成时才返回。
性能优化:虚拟纹理
dx12对于显存管理的改动其中一个优势,就是让虚拟内存管理成为了可能。
比如对于一些非常大的贴图,我们在运行时可能只会访问其中一部分的内容。原本的情况下,我们可能需要手动去切分这张大贴图,从上层做一些加载、拼接、卸载的逻辑。
而保留的资源让我们可以利用硬件提供的方法来完成相同的事情,它提供的映射到显式堆的方法(UpdateTileMappings),相比起直接申请销毁、创建显存的操作消耗更低,因而变得更高效。
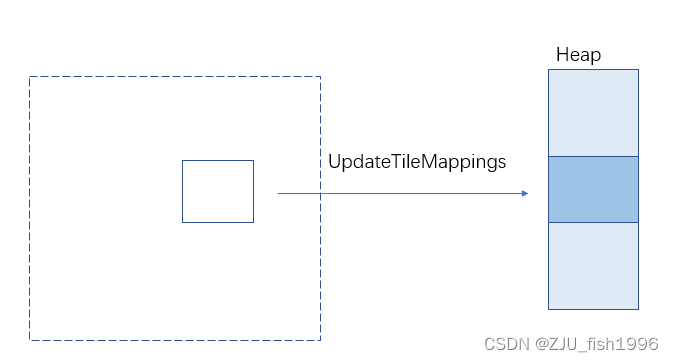
我们可以在大型贴图,比如地形中使用虚拟纹理。我们也可以将一些流式纹理手动Pack到大贴图上,利用保留资源来进行更廉价的分配和映射。
总结
dx12引入了非常多全新的概念,在了解了这些概念的含义后,我们还应该认识到,所有的设计都基本是为了性能来考量的。
之所以将渲染提交设计成可录制的指令,是为了方便多线程的录制;之所以独立出了管道状态对象,是为了避免维护状态上下文带来的消耗;之所以将资源绑定设计为像指针一样的描述符或描述符表,一是为了让绑定变得更加轻量(更少的绑定数量),二是可以支持动态的资源访问(bindless);之所以将设计出指向堆的定位资源/保留资源,是为了让资源分配变得更轻量,并将显存以堆的形式开放给用户管理,同时使得虚拟内存成为可能。
从性能优化的角度来看现代图形API,我们会发现它的设计虽然理解门槛会更高,但是它确实给我们提供了更多可能的控制手段;而传统图形API虽然上手更简单,但是当我们想要深入优化管线的时候,需要去理解驱动在底层“偷偷做了什么”,这件事情的理解成本不一定比现代图形API的上手要低。
当我们理解了驱动做的事情后,可能还会发现我们无法在上层通过合理地代码组织来干涉驱动做的事情,这个时候我们就会去期望底层API为我们提供更高的自由度,让我们更好地利用硬件的一些特性,这便是现代图形API设计的一个初衷。当我们更深刻的认识到传统图形API的局限性后,也许会对现代图形API的设计理念有一个更深刻的认知。