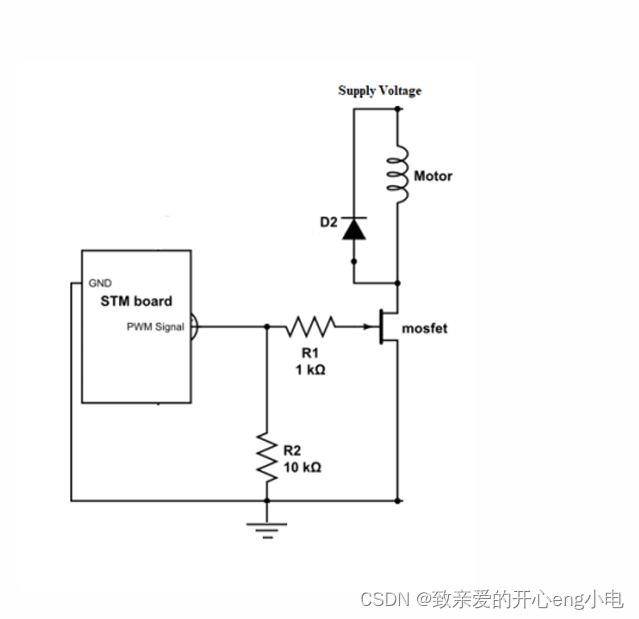
论文:C3: Zero-shot Text-to-SQL with ChatGPT
⭐⭐⭐⭐
arXiv:2307.07306,浙大
Code:C3SQL | GitHub
一、论文速读
使用 ChatGPT 来解决 Text2SQL 任务时,few-shots ICL 的 setting 需要输入大量的 tokens,这有点昂贵且可能实际不可行。因此,本文尝试在 zero-shot 的 setting 下来解决 Text2SQL 问题。
本文提出了 C3 来基于 ChatGPT zero-shot 去做 Text2SQL,实现了 1000 tokens per query 下优于 fine-tuning-based methods。
二、C3
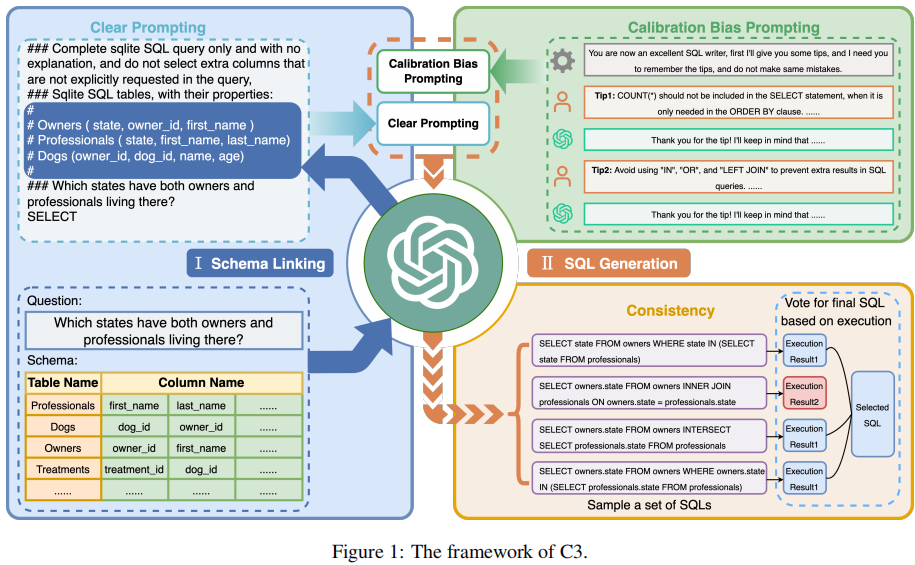
C3 由三个关键组件构成:Clear Prompts(CP)、Calibration with Hints(CH)、Consistency Output(CO),分别对应着模型输入、模型偏差和模型输出。
2.1 Clear Prompts 组件
Clear Prompts(CP)组件的目标是为 ChatGPT 解决 Text2SQL 任务构建一个有效的 prompt。它由两部分组成:Clear Layout 和 Clear Context。
2.1.1 Clear Layout
在 Text2SQL 中,有两种 prompt layout 的 styles:
- 类型 1:Complicated Layout:这种类型的 prompt 直接将 instruction、question 和 context 拼接起来,看起来较为杂乱,如下图的 (a) 所示
- 类型 2:Clear Layout:这种类型的 prompt 使用一个明显的分隔符将 instruction、question 和 context 分开,看起来更加清晰,如下图的 (b) 所示

论文指出,从直觉和实验上,都证明了 clear layout 能产生更好的表现。因此本文主要使用改进后的 clear layout。
但是,论文发现直接使用上图的 (b) 作为 prompt 会在生成的 SQL 中产生冗余的 columns,为了解决这个问题,论文在 instruction 部分后面加了一句:and do not select extra columns that are not explicitly requested in the query。
2.1.2 Clear Context
论文指出,在 prompt context 中包含整个 db schema 会导致两个问题:
- 在 prompt 引入过多的不相关 schema items 会让 ChatGPT 生成 SQL 时增加不相关 items 的 likelihood。
- 使用完整的 db schema 会让文本长度过大,导致不必要的 API tokens 开销
为此,论文提出需要先进行 schema linking 以召回相关的 tables 和 columns,并只将相关的信息放入 prompt context 中。
本文提出了一个 ChatGPT-based zero-shot 的 schema linking 的方法,分成两步:
- Table Recall:使用一个 prompt 让 ChatGPT 召回相关 tables
- Column Recall:基于 table recall 的结果,使用 prompt 让 ChatGPT 进一步召回相关 columns
Table Recall 的 prompt 示例如下:

Column Recall 的 prompt 示例如下:

2.2 Calibration with Hints 组件
论文通过分析生成的 SQL query,发现了几个由于 ChatGPT 固有的 biases 造成的 errors:
- Bias 1:ChatGPT 在 output 中倾向于保守,SELECT 语句中经常出现与问题相关但不是必需的列。而且在涉及到数量问题时尤为明显。比如下图的左边第一个问题,
COUNT(*)仅用于排序,但 ChatGPT 在 SELECT 中也将其输出了。 - Bias 2:ChatGPT 编写 SQL 时倾向于使用 LEFT JOIN、OR、IN,但经常无法正确使用它们。这种 bias 通常会导致执行结果中出现额外的值。

为了校准这些 bias,论文使用一个单独的组件来实施校准策略:Calibration with Hints(CH)。
论文通过将用于修正 Bias 的先验知识注入到与 ChatGPt 的历史对话中。在对话 history 中,我们让 ChatGPT 认为自己是一个优秀的 SQL 编写器,并引导它去遵循我们提出的 debias hints:
- Hint 1:针对第一个 bias,这里设计了一个 tip 去指导 ChatGPT 只选择必要的 columns
- Hint 2:针对第二个 bias,这里设计了一个 tip 来防止 ChatGPT 滥用一些 SQL 关键字。如下图所示,prompt 中直接要求 ChatGPT 尽量避免使用 LEFT JOIN、IN、OR,而使用 JOIN 和 INSERSECT,而且在适当时使用 DISTINCT 或 LIMIT,来避免重复的执行结果。
如下是一个示例:

2.3 Consistency Output 组件
由于 LLM 固有的随机性,ChatGPT 的输出是不稳定的。这里将 Text2SQL 也视为 reasoning 问题,于是使用 self-consistency 思想来提高效果。
论文提出了一个 execution-based self-consistency for Text2SQL 方法,封装为这里的 Consistency Output(CO)组件,用于选择 LLM 生成的 SQL。
这里的思想是,让 LLM 通过多个推理路径来生成多个 SQL answers,然后移除掉其中 execution error 的 SQL,并对剩余的 SQL 进行投票,从而选出最终的答案。
2.4 总结
C3 的整体框架如下:
三、实验
论文在 Spider 数据集上使用 Execution Accuracy(EX)作为指标来测试。
整体上的实验发现,C3 在 Spider 测试集上优于所有传统的基于微调的方法,在 Spider 排行榜上排名第二。与 top-1 方法的 few-shots settings 的 DIN-SQL 相比,只使用了约 10% 的 token 数量,而且这里使用的 GPT-3.5 在成本上也低于 DIN-SQL 使用的 GPT-4。所以,C3 方法更加预算友好。
此外,论文还做了不少的消融实验,总结了 error cases 的分析,具体可参考原论文。
四、总结
本文提出的 C3 基于 ChatGPT 实现了 zero-shot Text2SQL,并取得了 zero-shot 的最好性能。
C3 从模型输入、模型偏差和模型输出三个角度为基于 GPT 的 Text2SQL 提供了系统的处理方法。这些方法值得后面的研究来参考。