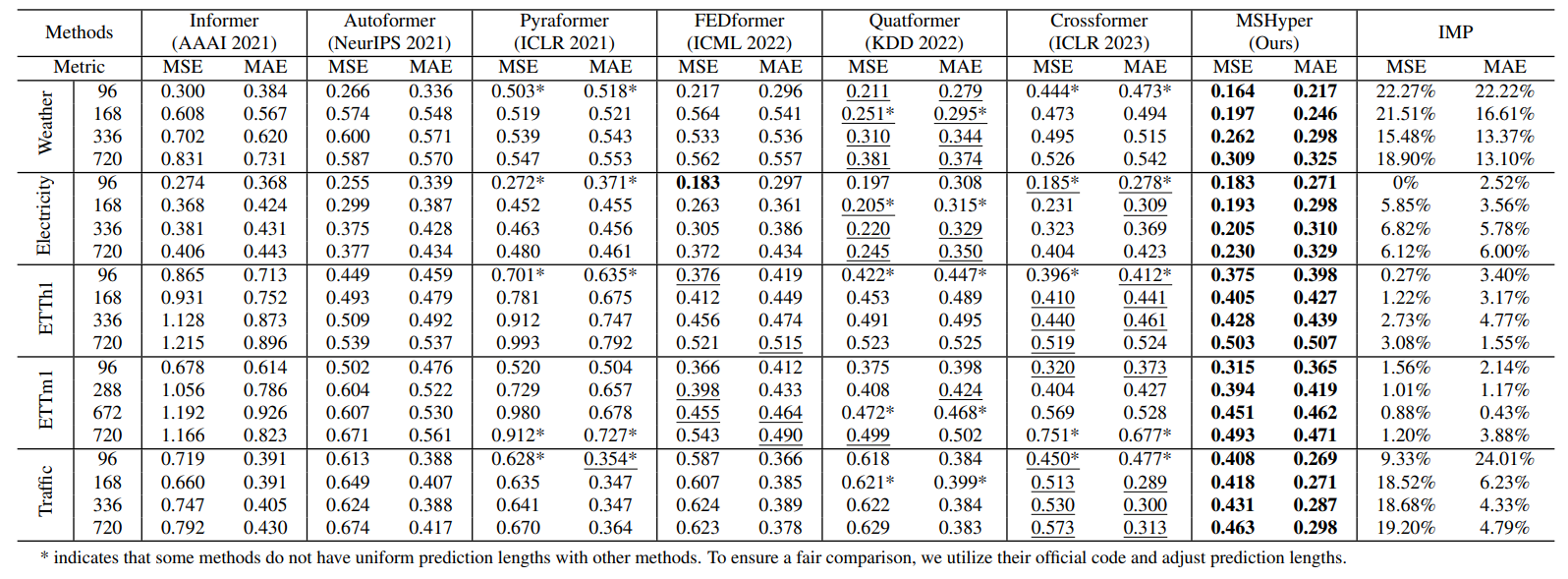
论文:MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
⭐⭐⭐⭐
arXiv:2312.11242, 北航 & Tencent
Code: MAC-SQL | GitHub
文章目录
- 一、论文速读
- 二、MAC-SQL
- 2.1 Selector agent
- 2.2 Decomposer agent
- 2.3 Refiner agent
- 三、指令微调的 SQL-Llama
- 四、实验
- 五、总结
一、论文速读
本文提出了一个使用多个 agents 进行互相合作的框架 MAC-SQL 来解决 Text2SQL 任务。
MAC-SQL 主要由 3 种 agents 组成:
- Selector:通过去除掉 inference 时无关的信息来把一个大的数据库分解为更小的数据库
- Decomposer:通过 prompt 的方法来把一个复杂的 question 分解为渐进性的几个可以被独立解决的 sub-questions
- Refiner:用于检测和自动改正 SQL 的错误
原论文对三者的描述:
Specifically, the Decomposer disassembles complex questions into simpler sub-questions and addresses them sequentially through chain-of-thought reasoning. If required, the Selector decomposes a large database into smaller sub-databases to minimize interference from irrelevant information. Meanwhile, the Refiner utilizes an external tool for SQL execution, acquires feedback, and refines any incorrect SQL queries.
下面是基于三个 agents 来实现 MAC-SQL 的算法流程:

二、MAC-SQL
2.1 Selector agent
The Selector agent is designed to automatically decompose a large database into smaller sub-databases to minimize interference from irrelevant information.
由于现实世界种的数据库特别大,包含了许多 tables 和 columns,一次 LLM 的 API Call 可能无法处理这些多的 schemas,因此需要使用 Selector 来去除掉无关信息并得到的一个较小的 schema。
如下是一个使用 Selector 的 prompt 示例:

可以看到,Selector 的 prompt 包含四部分:task desc、instruction、demonstrations 和一个 text example,期望的输出是一个 JSON,里面枚举了所有选择后的 tables,并将它们分成 3 类:
- “keep_all”
- “drop_all”
- 一个相关的 column list
这个 JSON 中的 schema 输入给 Decomposer agent。
2.2 Decomposer agent
The primary purpose of the Decomposer is to systematically decompose complex questions into progressively refined sub-questions, which can then be solved individually.
当面对复杂问题时,生成的 SQL 经常会有缺陷,因此一个自然的想法就是像 CoT 一样将其分解为 sub-questions 再解决。
图示:
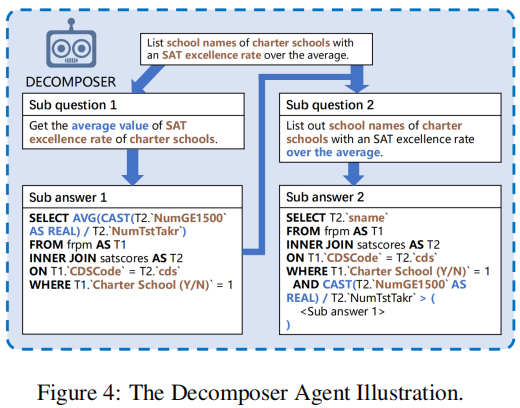
可以看到,最后一个 sub-question 就是原来的 user question 了,所以最后一步生成的 SQL 就是 Decomposer 输出的 SQL。
具体来说,Decomposer 可以用 CoT 或者 least-to-most 两种 prompt 策略来实现。
2.3 Refiner agent
The primary function of the Refiner is to detect and automatically rectify SQL errors.
对于一个 SQL,Refiner 首先从下面三个角度来诊断:
- 句法正确性
- 可执行性
- DB 检索后是否为非空结果
如果检查通过,这个 SQL 被输出为最终答案,否则,就执行 correction 操作。之后,修正后的 SQL 仍需重新诊断,重复这个过程直至检查通过或者达到最大重复次数。
具体的 correction 过程包括基于原始 SQL 和错误反馈信息或修改引导信号进行推理,生成修改后的结果。
图示:
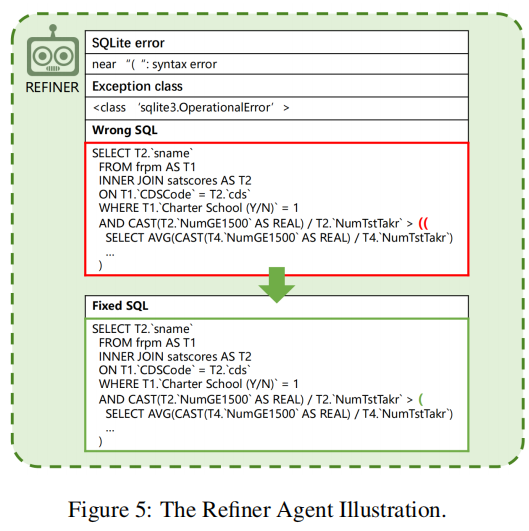
最后论文还指出,单靠一个 refiner agent 提供的帮助也是有限的,不可避免还存在一些错误的问题,这需要再系统层面进行更多的优化。
三、指令微调的 SQL-Llama
本文基于 Code Llama 7B,使用前面介绍的 3 个 agents 的指令数据进行微调,得到了 SQL-Llama,让 model 在 database simplification、question decomposition、SQL generation 和 SQL correction 方面的能力得到增强。
用于微调的数据是基于三个 agents 在 BIRD 和 Spider 数据集上得到的。
这个过程的关键挑战是:model 的训练过程需要平衡它的 complexity 和 performance。也就是需要在维持其较高的 performance 时有效处理 db 相关任务的复杂度。
四、实验
论文在 BIRD 数据集上做的测试,baseline 只选择了 LLM-based 的方案,并没有选择非 LLM 的 baseline。实验结果如下图所示:
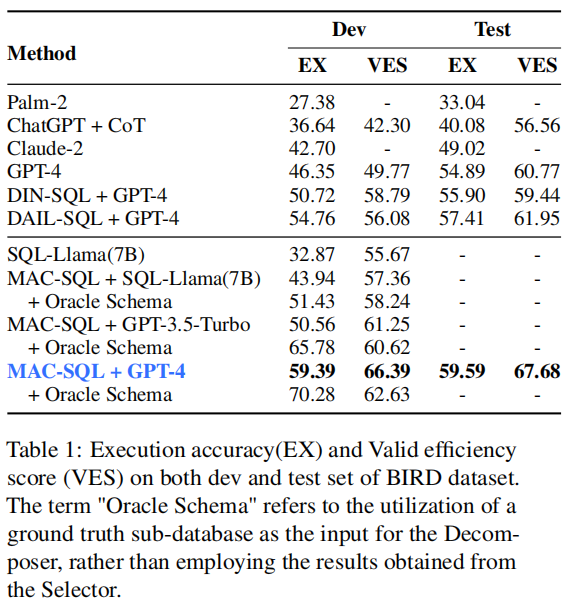
论文还做了消融实验,证明了三个 agents 在提高 acc 方面都发挥了重要的作用。
另外论文还发现,ICL 中增加 demonstrations 的数量可以让效果更好。
论文最后还给出了 error cases 的统计分析,可以参考原论文。
五、总结
本论文利用多个 agents 合作的思路来解决 Text2SQL 任务,同时提供了一个开源的 SQL-Llama 模型,在 BIRD 数据集上实现了 SOTA 效果。