基于WIN10的64位系统演示
一、写在前面
我们来继续这篇文章:
《BMC Public Health》杂志的2022年一篇题目为《ARIMA and ARIMA-ERNN models for prediction of pertussis incidence in mainland China from 2004 to 2021》文章的模拟数据做案例。
这文章做的是用:使用单纯ARIMA模型和ARIMA-ERNN组合模型预测中国大陆百日咳发病率。

文章是用单纯的ARIMA模型作为对照,更新了ARIMA-ERNN模型。本期,我们试一试ARIMA-ERNN组合模型能否展示出更优秀的性能。
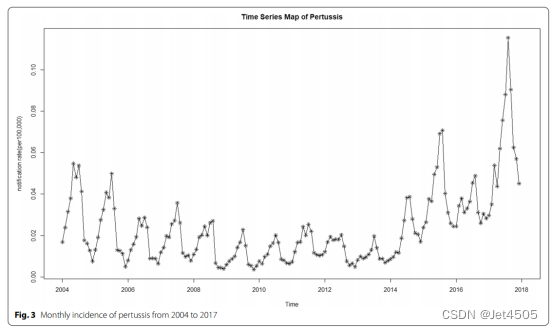
数据不是原始数据哈,是我使用GPT-4根据文章的散点图提取出来近似数据,只弄到了2004-2017年的。
二、闲聊和复现:
(1)ARIMA-ERNN组合模型的构建策略
又涉及到组合模型的构建。不过这个策略跟上一期提到的ARIMA-NARNN组合模型所使用的的建模策略不一样,来看看GPT-4的总结:

不懂大家看懂了没,反正我是有个疑问:
“所以是一个ARIMA的预测值作为输入,然后对应一个实际值作为输出,训练ERNN模型”
GPT-4肯定了我的回答:

是直接用n个ARIMA的预测值作为输入,实际值作为输出,去构建神经网络,有点像ARIMA-GRNN的策略。
所以说,组合模型,玩的就是花。
(2)组合模型构建
那就帮用pytorch写一个代码呗:
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
# Load data
data_path = 'ERNN.csv'
data = pd.read_csv(data_path, parse_dates=True, index_col=0)
# Ensure column accuracy (second column is actual values, third column is ARIMA predictions)
actuals = data.iloc[:, 0]
predictions = data.iloc[:, 1]
# Use 36 consecutive ARIMA prediction values as input
n = 36
inputs = [predictions.shift(-i) for i in range(n)]
inputs = pd.concat(inputs, axis=1)[:-n] # Remove the last n rows as they are incomplete
targets = actuals[n:] # Remove the first n targets to align data
# Split data into training and testing sets, last 12 as test set
train_inputs = inputs[:-12]
train_targets = targets[:-12]
test_inputs = inputs[-12:]
test_targets = targets[-12:]
# Convert to PyTorch tensors
train_inputs = torch.tensor(train_inputs.values).float()
train_targets = torch.tensor(train_targets.values).float().unsqueeze(1)
test_inputs = torch.tensor(test_inputs.values).float()
test_targets = torch.tensor(test_targets.values).float().unsqueeze(1)
# Create DataLoaders
train_dataset = TensorDataset(train_inputs, train_targets)
test_dataset = TensorDataset(test_inputs, test_targets)
batch_size = 12 # One data point at a time
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
# Define ERNN model
import torch
import torch.nn as nn
# Define ERNN model using ReLU
class ERNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(ERNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.tanh = nn.Tanh()
def forward(self, input, hidden):
if input.size(0) != hidden.size(0):
hidden = self.initHidden(input.size(0))
combined = torch.cat((input, hidden), 1)
hidden = self.tanh(self.i2h(combined))
output = self.i2o(combined)
return output, hidden
def initHidden(self, batch_size):
return torch.zeros(batch_size, self.hidden_size)
# Initialize model
model = ERNN(input_size=n, hidden_size=24, output_size=1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.004, momentum=0.9) # 使用带动量的SGD模拟traingdx
# 训练模型
def train_model(model, criterion, optimizer, train_loader, epochs):
model.train()
for epoch in range(epochs):
total_loss = 0
for inputs, targets in train_loader:
optimizer.zero_grad()
current_batch_size = inputs.size(0) # 获取当前批次的大小
hidden = model.initHidden(current_batch_size) # 使用当前批次大小初始化隐藏状态
outputs, hidden = model(inputs, hidden)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 1000 == 0: # 每1000次迭代输出一次损失
print(f'Epoch {epoch}: Loss = {total_loss / len(train_loader)}')
train_model(model, criterion, optimizer, train_loader, epochs=200000) # 训练10000次迭代
# Evaluate model
def evaluate_model(model, loader):
model.eval()
predictions, actuals = [], []
with torch.no_grad():
for inputs, targets in loader:
current_batch_size = inputs.size(0) # 获取当前批次的大小
hidden = model.initHidden(current_batch_size) # 使用当前批次大小初始化隐藏状态
outputs, hidden = model(inputs, hidden)
predictions.extend(outputs.detach().numpy())
actuals.extend(targets.numpy())
mse = mean_squared_error(actuals, predictions)
mae = mean_absolute_error(actuals, predictions)
mape = mean_absolute_percentage_error(actuals, predictions)
return mse, mae, mape
# Evaluate on both training and testing data
train_mse, train_mae, train_mape = evaluate_model(model, train_loader)
test_mse, test_mae, test_mape = evaluate_model(model, test_loader)
# Print evaluation metrics for both training and testing datasets
print(f"Training MSE: {train_mse}, MAE: {train_mae}, MAPE: {train_mape}")
print(f"Test MSE: {test_mse}, MAE: {test_mae}, MAPE: {test_mape}")又是可怕的调参,首先看看文章的参数:
“在确定隐藏层神经元数量(N)时,使用了以下经验公式:
N = √(n + m )+ a
其中m是输入层的神经元数量,n是输出层的神经元数量,a是一个常数(范围在1到10之间)。根据这个计算,ERNN的隐藏层有3到12个神经元。我们对ERNN的隐含层使用了Tan-Sigmoid函数,对输出层使用了Purelin函数,训练函数用的是traingdx,网络权重学习函数用的是Learngdm,模型性能评估使用了MSE。网络的参数设置如下:迭代步数为10,000步,学习率为0.01,学习目标(学习误差)为0.004。然后我们使用了一个2-9-1结构的ERNN来预测百日咳的发病率。ARIMA-ERNN模型的MSE为0.00077,优于ARIMA模型的0.00937。”
我试了试,一言难尽。
然后自己调了一下参数,目前最好就这样了,过拟合了:
Training MSE: 1.5360685210907832e-05, MAE: 0.003031895263120532, MAPE: 0.21757353842258453
Test MSE: 0.001023554359562695, MAE: 0.026323571801185608, MAPE: 0.37139490246772766
各位大佬有更好的结果麻烦分享一下参数,跪谢~
本代码可以调的参数有:
①输入特征数量 (n):
这个参数决定了每个输入样本中使用的连续ARIMA预测值的数量。您可以尝试使用不同数量的输入特征来看是否能改善模型的表现。
②批大小 (batch_size):
这影响到模型训练的速度及收敛性。较大的批大小可以提高内存利用率和训练速度,但可能影响模型的最终性能和稳定性。反之,较小的批大小可能使训练过程更稳定、收敛更精细,但训练速度会减慢。
③隐藏层大小 (hidden_size):
这决定了隐藏层中神经元的数量。增加隐藏层的大小可以提高模型的学习能力,但也可能导致过拟合。相应地,减少隐藏层大小可能减少过拟合的风险,但可能限制模型的能力。
④学习率 (lr):
学习率是优化算法中最重要的参数之一。如果学习率设置得太高,模型可能无法收敛;如果设置得太低,模型训练可能过于缓慢,甚至在到达最佳点之前停止训练。
⑤动量 (momentum):
动量帮助加速SGD在正确方向上的收敛,还可以减少优化过程中的震荡。调整这个参数可以影响学习过程的平滑性和速度。
⑥激活函数:
模型中使用的是 Tanh 激活函数。可以考虑使用 ReLU 或其变体(如 LeakyReLU, ELU 等)以期改善模型性能,尤其是在处理非线性问题时。
⑦优化器:
虽然使用的是带动量的SGD,但您也可以尝试使用其他优化器,如 Adam、RMSprop 等,这些优化器可能在不同的应用场景中表现更好。
⑧迭代次数 (epochs):
增加或减少训练迭代次数可以影响模型的学习程度。太少的迭代次数可能导致模型欠拟合,而太多的迭代次数可能导致过拟合或不必要的计算资源消耗。
三、后话
又学习了一种潜在的ARIMA组合模型的策略,同样的,把ERNN换成别的模型,就又是一片新天地了。
四、数据
不提供,自行根据下图提取吧。
实在没有GPT-4,那就这个:
https://apps.automeris.io/wpd/index.zh_CN.html